Amazon Web Services ブログ
SimilarWeb が、Amazon Athena と Upsolver を使って毎月数百テラバイトのデータを分析する方法
これは、SimilarWeb のデータ収集およびイノベーションチームのリーダーである Yossi Wasserman 氏の寄稿です。
SimilarWeb は、同社の説明によれば、「SimilarWeb は、インテリジェンス市場の先駆者であり、デジタル世界を理解するための標準です。SimilarWeb は、すべての地域のすべての業界のウェブサイトまたはモバイルアプリに関する詳細な情報を提供します。SimilarWeb は、マーケティング担当者、アナリスト、セールスチーム、投資家、エグゼクティブなどがデジタル世界で成功するために必要な洞察を活用して、企業が意思決定を行う方法を変えています。」
SimilarWeb は、デジタル世界全体で何が起こっているのかについての洞察を提供するマーケットインテリジェンスの会社です。何千社もの顧客がこれらの洞察を活用して、マーケティング、販売促進、投資決定などの戦略を強化する重要な判断を下しています。当社のソリューションがもたらす意思決定の重要性が、こうした情報を効果的に収集して使用する当社の能力を強調しています。
特に、私が率いているチームは SimilarWeb のモバイルデータ収集の監督を担当しています。現在、毎月数百 TB の匿名データを処理しています。
欠陥のあるデータや不完全なデータに基づいて顧客の洞察を提供することはできないので、データ収集プロセスは SimilarWeb にとって重要です。データ収集チームは、新しいタイプのデータ、パートナーの統合、全体的なパフォーマンスなどを可能な限り迅速に効率よく分析することを必要としています。チームは可能な限り早期に異常を特定し、対処することが不可欠です。このプロセスをサポートするツールは、大きな利点をもたらします。
SimilarWeb のモバイルデータ収集の技術的課題
数百 TB のデータが、異なるソースから毎月 SimilarWeb にストリーミングされます。データは複雑です。 数百のフィールドがあり、その多くは深くネストされており、null 値を持つものも数多く含まれています。データをきれいにし、正規化し、照会のために準備する必要があるため、こうした複雑さから技術的な課題が生じます。
最初の選択肢は、実行に数時間かかる毎日のバッチ処理で SimilarWeb のすべてのデータを処理する、既存のオンプレミス Hadoop クラスターを使用することでした。ビジネスクリティカルな監視にとって、24 時間の遅延は受け入れられません。
そこで、Hadoop を使用して新しいプロセスを開発することを検討しました。しかしながら、それには私たちのチームが毎日の作業から離れて、抽出、変換、ロード (ETL) ジョブのコーディング、スケール、維持に集中することが必要です。また、異なるデータベースを扱う必要があるため、チームが業務に集中する妨げともなります。そのため、チームのメンバー全員が新しいレポートを作成し、不一致を調査し、自動化されたテストを追加できるようなアジャイルソリューションが必要でした。
また、コンピューティングのボトルネックを引き起こした別個を数える問題もありました。別個を数える問題とは、反復要素を含むデータストリームで別個の要素の数を数えるのが難しいという問題です。たとえば、デバイス、オペレーティングシステム、国別など、数十億もの可能なセグメントの一意のビジター数を追跡します。別個を数えることは非加算的集約であるため、一意のビジターの正確な数を計算するには、通常、多くのメモリ集約型コンピューティングノードが必要です。
Amazon Athena を選んだ理由
こうした課題を解決するために、当社は Amazon Athena を選びました。 Athena が、もたらしたもの:
- SQL を使用する高速な照会 — 私たちのチームは SQL を使用してデータを照会したいと考えていましたが、従来の SQL データベースは数百テラバイトに拡大することは困難でした。Apache Presto を使用して Amazon S3 で分散 SQL クエリを実行するため、Athena は役立ちます。
- 低メンテナンス — Athena は、IT 運用コストを必要としないサーバーレスプラットフォームです。
- 低コスト — 必要なデータベースノードの数が多いため、データウェアハウスに非常に多くのデータを保存するのは高価になります。データのわずかな部分だけを照会するので、スキャンした 1 GB あたり 0.005 USD という Athena の料金は魅力的です。
Upsolver を選んだ理由
私たちのソリューションのもう一つの部分として、Upsolver を選択しました。Upsolver は、データレイクと、ビッグデータのエンジニアではない分析ユーザーを結びつけます。そのクラウドデータレイクのプラットフォームは、組織が効率的にデータレイクを管理するのに役立ちます。Upsolver を使用すると、単一のユーザーが Athena、Amazon Redshift、Elasticsearch Service (Amazon ES) などの分析プラットフォームの取り込みから管理や準備まで、大規模なストリーミングデータをコントロールできます。
Upsolver を選択した、いくつかの理由:
- Upsolver では、Athena と S3 に毎時の統計情報を提供することができます。その結果、24 時間後ではなく 1 時間後には異常を特定することができます。
- Upsolver は、グラフィカルユーザーインターフェイス (GUI) を使用しており、大規模でも簡単に設定できます。追跡しているすべてのセグメントの個別ビジターの数を含めて、Kafka から Athena へのパイプラインを構築するのに約 1 時間しかかかりませんでした。
- Upsolver の Stream Discovery ツールは、Athena でテーブルを作成するのに役立ちました。JSON の各フィールドの値の正確な分布が分かり、必要なフィールドを見つけて必要な修正を行うのに役立ちました。
- Upsolver は、管理が簡単です。Upsolver は、IT オーバーヘッドがほとんどないサーバレスプラットフォームです。
- 当社のデータは、当社の S3 バケットでプライベートなまま存在します。当社のデータは匿名ですが、自社でコントロールできない状態は望んでいませんでした。
当社のソリューション
当社のソリューションには、SQL 解析用の Athena、イベントストレージ用の S3、データ準備用の Upsolver が含まれています。次の図は、当社のソリューションの開始から終了までを示しています。
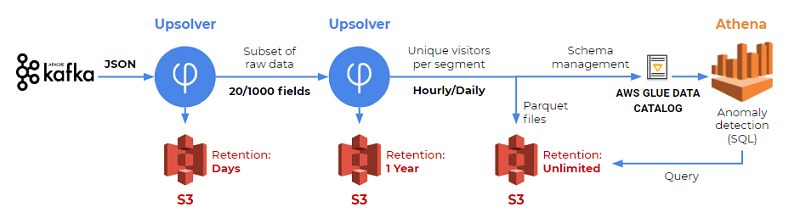
以下のセクションでは、このソリューションを段階的に見ていきます。
ステップ 1: Kafka から S3 へ、未加工データを取得する
当社のデータは、Kafka のオンプレミスにあります。Upsolver のコネクタを使用して Kafka からイベントを読み込み、S3 に保存します。これを一度だけ行う必要がありました。 以下の例は、Kafka でデータソースをどのように作成したかを示しています。

ステップ 2: S3 で縮小ストリームを作成する
数百 TB を S3 に保存することは、私たちが実行する必要があった分析では必要ありませんでした。フルストリームには約 400 フィールドが含まれていますが、20 〜 30 フィールドしか必要ありません。そこで、Upsolver を使用してストリームを縮小しました。この縮小ストリームには、元のストリームのフィールドの一部と、Upsolver で追加したいくつかの新しい計算フィールドが含まれています。出力は S3 に保存します。
また、Kafka のトピックには、ユースケースに関係のないイベントが含まれていることも知っていました。ストリームを縮小するもう 1 つの部分として、Upsolver を使用してこれらのイベントをフィルタリングしました。未加工データは 1 日だけ保存しますが、縮小ストリームは 1 年間保存します。縮小ストリームのおかげで動的でいられます — つまり、1 年間のイベントソースを使用していますが、完全に未加工データを保存するよりはるかに低コストです。
ステップ 3: Athena のテーブルの作成と管理
Athena を使用する場合、AWS Glue データカタログと Amazon S3 が必須です。Athena は、外部テーブルと呼ばれる概念を利用しています。つまり、テーブルのスキーマ定義は AWS Glue データカタログで管理され、データは S3 で管理されます。
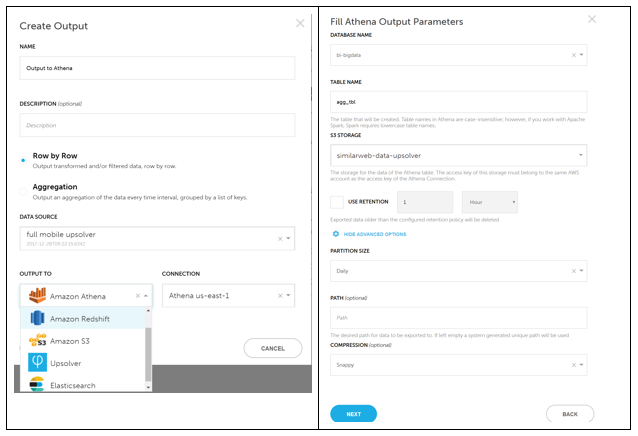
Upsolver の Create Output 機能を使用して、ネストされた JSON ソースファイルを、Parquet ファイルで支持されるフラットな出力テーブルにマッピングしました。Upsolver を実行すると、次の 2 つの異なるタイプの出力が作成されます。
- 次のスクリーンショットに示すような、S3 のフラットな Parquet ファイル。1 時間単位でさまざまなセグメントの個別ユーザー数を追跡するので、頻繁に aggregation オプションを使用しています。
- 次の例に示すような、テーブルに追加された 4 つの列。スキーマの進化とパーティション管理のため、テーブルのスキーマは時間の経過とともに変化します。毎日のパーティションを使用しているため、Upsolver は 4 つの列をテーブルに追加しました。Upsolver は、AWS Glue データカタログでこれらの変更をすべて直接管理します。

ステップ 4: Athena で SQL 解析を実行する
当社の開発者は、Athena SQL コンソールを使用して、新しいデータの異常を探します。通常、追跡したディメンションごとの異なるユーザーの数の急増や急減が、異常を示しています。追跡したディメンションの例としては、SDK のバージョン、デバイス、オペレーティングシステムがあります。
また、実稼働のデバッグのためにリアルタイムでさまざまなフィールドの追跡も行います。また、場合によっては、継続的な統合ジョブにクエリを追加します。
結論
この記事では、大量のデータを扱う際の主な課題について説明しました。 Amazon Athena と Upsolver を選択して、チームの誰もが使用できるパフォーマンスが高く、費用効果が高く、効率的なソリューションを構築する方法を紹介しました。 全体として、この新しいパイプラインは効率を改善し、取り込みから洞察までの時間を 24 時間から数分へと短縮しました。
今回のブログ投稿者について
 Yossi Wasserman 氏は、SimilarWeb のデータ収集およびイノベーションチームのリーダーです。彼は、ソフトウェアエンジニアリングの理学士を取得していおり、モバイルアプリ開発の分野で 10 年以上の経験を有しています。
Yossi Wasserman 氏は、SimilarWeb のデータ収集およびイノベーションチームのリーダーです。彼は、ソフトウェアエンジニアリングの理学士を取得していおり、モバイルアプリ開発の分野で 10 年以上の経験を有しています。