Amazon Web Services ブログ
Thomson Reuters が Amazon SageMaker を使用して自然言語処理ソリューションの研究開発を加速させた方法
この記事は、Thomson Reuters の John Duprey 氏と Filippo Pompili 氏が共同執筆した How Thomson Reuters accelerated research and development of natural language processing solutions with Amazon SageMaker を翻訳したものです。
お客様の課題
TR の研究開発チームは、迅速かつ安全に反復処理を行う必要がありました。チームメンバーはすでに、浅いアルゴリズムに特化した特徴エンジニアリングと特徴を持たないニューラルベースのソリューションの両方で、質問応答ソリューションを開発する重要な専門知識を持っていました。彼らは、TR の評判の高い 2 つの製品である Westlaw Edge (法務) と Checkpoint Edge (税務) を強化する技術開発に重要な役割を果たしました。これらのプロジェクトでは、それぞれ 15~18 か月にわたる集中的な研究開発が行われ、目覚ましいパフォーマンスレベルに達しました。MRC の場合、研究チームは、法務ドメインと税務ドメインの 2 つの TR データセットを対象に、BERT とそのバリアントのいくつかを実験することにしました。
法務関連のトレーニングコーパスは、編集レビューされた数万の質問で構成されています。それぞれの質問は、短く関連性のある、テキスト要約の形の回答候補いくつかと比較されます。これらの要約は、数十年にわたる法律上の事例から抽出された、高度にキュレートされた編集資料であり、数千万のテキスト要約から抽出された、数十万の質問と回答 (QA) ペアからなるトレーニングセットの候補となりました。税務コーパスは、米国連邦税法に関する編集的にキュレートされた 60,000 を超えるドキュメントで構成され、数千の質問と数万の QA ペアが含まれていました。
これらのデータセットに対するモデルの事前トレーニングと微調整は、最先端の処理能力がなければ不可能でした。通常、これらのコンピューティングリソースを調達するには、長いリードタイムと大きな先行投資が必要でした。製品になるかならないかわからない研究のアイデアに対して、実験のためのそれほど大きなコストを正当化することは困難でした。
AWS と Amazon SageMaker を使用する理由
TR は、このプロジェクトの機械学習 (ML) サービスとして Amazon SageMaker を選択しました。Amazon SageMaker は、ML モデルを大規模に構築、トレーニング、調整、およびデプロイするためのフルマネージド型のサービスです。TR が Amazon SageMaker を選択する決定を下した主な要因の 1 つは、従量課金制のマネージドサービスの利点でした。Amazon SageMaker を利用することで、TR は実験の数を決めることができ、トレーニングのコストを制御することができます。さらに重要なのは、トレーニングジョブが完了すると、チームが使用していた GPU インスタンスの料金が課金されなくなることです。これにより、自社でトレーニングリソースを管理してサーバーの使用率が低下する場合に比べ、大幅なコスト削減が実現しました。研究チームは、必要な数のインスタンスをスピンアップし、長期にわたる実験の終了時には、フレームワークに任せてシャットダウンすることができました。これにより、大規模なラピッドプロトタイピングが可能になりました。
さらに、Amazon SageMaker には、マネージド型スポットインスタンスを使用する機能が組み込まれているため、いくつかのケースでは、トレーニングのコストが 50% 以上削減されました。BERT のようなモデルを独自の膨大なデータセットで使用する大規模な自然言語処理 (NLP) 実験では、トレーニング時間は数週間とはいかないまでも数日単位で、使用するハードウェアは高価な GPU となります。一回の実験で数千ドルの費用がかかることもあります。Amazon SageMaker によるマネージドスポットトレーニングにより、TR はトレーニングコストを平均 40~50% 削減しました。セルフマネージドトレーニングと比較して、Amazon SageMaker には組み込みのセキュリティ機能のフルセットもあります。これにより、チームはセルフマネージドの機械学習インフラストラクチャで必要とされていた無数のコーディング時間を節約できました。
トレーニングジョブを開始した後、TR は Amazon SageMaker コンソールで簡単にモニタリングすることができました。ログ記録およびハードウェア使用率の測定機能により、チームはジョブの状態を素早く把握することができました。例えば、トレーニング損失が予想通りに進行していることを確認したり、割り当てられた GPU がどれだけうまく活用されているかを確認したりすることができます。
Amazon SageMaker は、TR が独自のインフラストラクチャをプロビジョニングしたり、一連のサーバーやセキュリティ体制、パッチ適用レベルを管理する負担を負ったりすることなく、最先端の基盤となる GPU インフラストラクチャに簡単にアクセスできるようにしました。今後、より高速で安価な GPU インスタンスが利用可能になるにつれ、TR は新しいタイプを使用するために簡単な設定変更をするだけでコストとトレーニング時間を削減できます。このプロジェクトでは、チームは P2、P3、G4 ファミリーのインスタンスをそれぞれのニーズに合わせて簡単に試すことができました。AWS はまた、TR に広範な ML サービス、費用対効果の高い料金オプション、きめ細かなセキュリティ制御、およびテクニカルサポートを提供しました。
ソリューションの概要
お客様は、法律、税務、コンプライアンス、政府、メディアといった社会を前進させる複雑な分野で事業を展開しており、規制やテクノロジーによってあらゆる業界が混乱する中、さらなる複雑さに直面しています。TR は、お客様が業務方法を改革するのを支援します。MRC を使用して、TR は、手動による特徴エンジニアリングに依存していた以前のモデルよりも優れた自然言語検索を提供できると期待しています。
TR 研究チームが開発している BERT ベースの MRC モデルは、数十 GB を超える圧縮データのテキストデータセットで実行されます。TR の深層学習フレームワークとしては、TensorFlow と PyTorch が選ばれています。チームは、時間のかかるニューラルネットワークのトレーニングジョブに GPU インスタンスを使用し、ランタイムは数十分から数日の範囲になっています。
MRC チームは、BERT の様々なバリアントを実験してきました。当初は、12 層の積層型トランスエンコーダーと 12 のアテンションヘッドを備えた 1 億個のパラメータを持つベースモデルから始め、24 層、16 のヘッド、3 億個のパラメータを持つラージモデルまで試しました。最大量の 32 GB の RAM を搭載した V100 GPU が利用できたことは、最大のモデルバリアントをトレーニングするのに役立ちました。チームは、質問応答問題をバイナリ分類タスクとして定式化しました。各 QA ペアは、内容領域専門家 (SME) のプールによって、A、C、D、F の 4 つの異なる評点のいずれかを割り当てられています。A は完璧な回答、F は完全に間違ったエラーです。各 QA ペアの評点は数値に変換され、評定者間で平均化され、バイナリ化されます。
各質問応答システムはそれぞれのドメインに特化しているため、研究チームは転移学習とドメイン適応技術を使用して、異なるサブドメイン (例: 法律は単一のドメインではない) 間でこの機能を有効にしました。TR では、言語モデルの事前トレーニングと BERT モデルの微調整の両方に Amazon SageMaker を使用しました。利用可能なオンプレミスのハードウェアと比較すると、Amazon SageMaker P3 インスタンスは、微調整ジョブのトレーニング時間を数時間から 1 時間未満に短縮しました。ドメイン固有のコーパスでの BERT の事前トレーニングは、推定数週間からわずか数日間に短縮されました。Amazon SageMaker による劇的な時間短縮とコスト削減がなければ、TR 研究チームはこのプロジェクトに必要な大規模な実験を完了できなかったでしょう。Amazon SageMaker を使用することで、TR は、ユーザーがより速く、より正確に検索できるように、アプリケーションに重要な改善をもたらすブレークスルーを実現しました。
推論のために、TR は Amazon SageMaker バッチ変換関数を使用して、膨大な量のテストサンプルに対するモデルスコアリングを行いました。モデルのパフォーマンスのテストが満足できるものだった場合、Amazon SageMaker マネージド型ホスティングはリアルタイム推論を有効にしました。TR は、研究開発努力の成果を本番環境に反映させています。本番環境では、Amazon SageMaker エンドポイントを使用して、高度に専門化されたプロフェッショナルドメインで 1 日あたり数百万件のリクエストを処理することを期待しています。
膨大な量の独自データに対する、安全で容易かつ継続的なアクセス
TR の知的財産を保護することは、ビジネスの長期的な成功にとって非常に重要です。このため、TR には、セキュリティとクラウドでの作業方法に関する明確で進化し続ける標準があり、アセットを保護するためにそれに従う必要があります。
これにより、TR の科学者にとって重要な問題がいくつか提起されます。安全で TR の標準に準拠した Amazon SageMaker ノートブックのインスタンスを作成する (またはトレーニングジョブを起動する) にはどうしたらよいでしょうか。 科学者はどのように Amazon SageMaker 内の TR のデータに安全にアクセスできますか。 TR は、科学者がこれを一貫して、安全に、最小限の労力で行うことができるようにする必要がありました。
そこで登場したのが、Secure Content Workspace です。SCW は TR の研究開発チームによって開発されたウェブベースのツールで、これらの問題に応えます。次の図は、前述した TR の研究作業のコンテキストでの SCW を示しています。
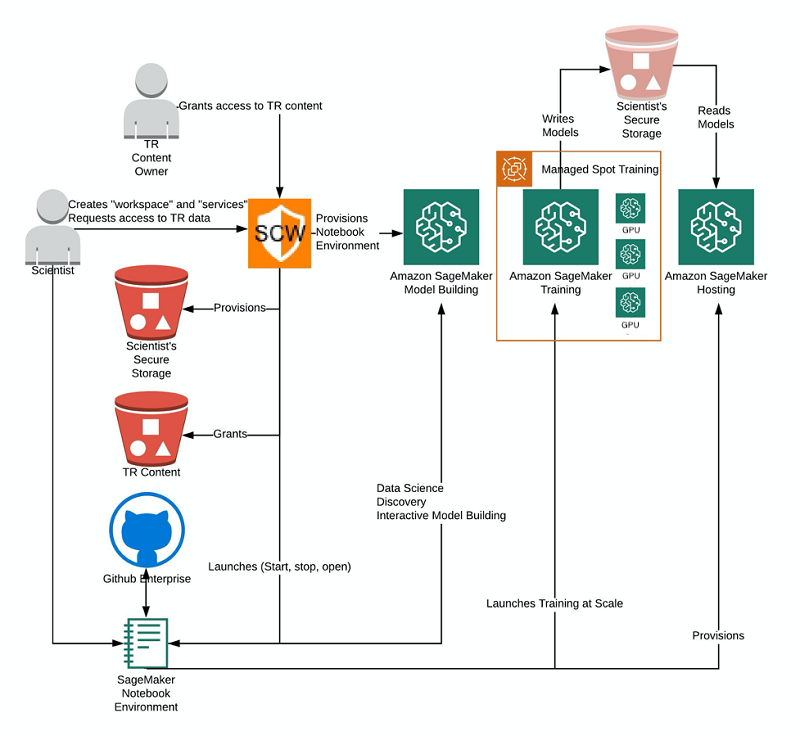
SCW により、TR のデータへの安全で制御されたアクセスが可能になります。また、Amazon SageMaker のようなサービスを、TR の標準に準拠した方法でプロビジョニングします。SCW を使用することで、科学者はセキュリティプロトコルに準拠しているという安心感を持ってクラウドで作業できます。SCW により、科学者は人工知能 (AI) で難しい問題を解決するという得意分野に集中できます。
まとめ
Thomson Reuters は、お客様の仕事を支援する最先端の AI 機能の研究開発に全面的に取り組んでいます。MRC の研究は、こうした試みの中で最新のものでした。初期の結果は、特に自然言語の質問応答において、TR の製品ライン全体での幅広い適用を示しています。過去のソリューションには広範な特徴エンジニアリングと複雑なシステムが含まれていましたが、この新しい研究は、よりシンプルな ML ソリューションが可能であることを示しています。科学界全体がこの分野で非常に活発に活動しており、TR はその一員であることを誇りに思っています。
この研究は、GPU が提供する大幅な計算能力と、それをオンデマンドでスケーリングする機能なしには実現しませんでした。Amazon SageMaker の一連の機能は、TR に、テスト用モデルを構築、トレーニング、ホストするための能力と必要なフレームワークを提供しました。TR は、MRC のように、クラウドベースの研究開発をサポートするために SCW を構築しました。SCW は、科学者の作業環境をクラウドにセットアップし、TR のすべてのセキュリティ標準と推奨事項への準拠を確実にします。そのおかげで、Amazon SageMaker などのツールを、TR のデータと共に安全に使うことができました。
今後、TR 研究チームは、Amazon SageMaker と SCW を使用して、これらの強力な深層学習アーキテクチャに基づいた、より幅広い AI/ML 機能の導入を検討しています。このような高度な機能の例には、オンザフライの回答生成、長いテキスト要約、完全にインタラクティブな、会話型の質問応答などがあります。これらの機能により、必要なすべての情報に対する最適なソリューションにユーザーを導くことができる、包括的な支援 AI システムが実現します。
著者について
 Mark Roy は、機械学習スペシャリストソリューションアーキテクトで、大規模な Well-Architected 機械学習ソリューションの導入でお客様を支援しています。余暇には、Mark はバスケットボールをプレー、コーチ、フォローするのを楽しんでいます。
Mark Roy は、機械学習スペシャリストソリューションアーキテクトで、大規模な Well-Architected 機械学習ソリューションの導入でお客様を支援しています。余暇には、Mark はバスケットボールをプレー、コーチ、フォローするのを楽しんでいます。
 Qingwei Li はアマゾン ウェブ サービスの機械学習スペシャリストです。彼がオペレーションズリサーチの博士号を取得したのは、アドバイザーの研究助成金口座を空にし、約束していたノーベル賞の取得に失敗した後のことでした。現在は、金融サービスや保険業界のお客様が AWS 上で機械学習ソリューションを構築するのを支援しています。余暇には、読書や教えることを楽しんでいます。
Qingwei Li はアマゾン ウェブ サービスの機械学習スペシャリストです。彼がオペレーションズリサーチの博士号を取得したのは、アドバイザーの研究助成金口座を空にし、約束していたノーベル賞の取得に失敗した後のことでした。現在は、金融サービスや保険業界のお客様が AWS 上で機械学習ソリューションを構築するのを支援しています。余暇には、読書や教えることを楽しんでいます。
 John Duprey 氏は、Thomson Reuters の AI およびコグニティブコンピューティングセンター (C3) のエンジニアリング担当シニアディレクターです。John 氏とエンジニアリングチームは、科学者や製品技術チームと協力して、Thomson Reuters の顧客の最も困難な問題に対する AI ベースのソリューションを開発しています。
John Duprey 氏は、Thomson Reuters の AI およびコグニティブコンピューティングセンター (C3) のエンジニアリング担当シニアディレクターです。John 氏とエンジニアリングチームは、科学者や製品技術チームと協力して、Thomson Reuters の顧客の最も困難な問題に対する AI ベースのソリューションを開発しています。
 Filippo Pompili 氏は、Thomson Reuters の AI およびコグニティブコンピューティングセンター (C3) のシニア NLP リサーチサイエンティストです。Filippo 氏は、機械による読解、情報検索、およびニューラル言語モデリングの専門知識を持っています。最先端の機械学習の発見を、Thomson Reuters の最先端の製品に導入することに積極的に取り組んでいます。
Filippo Pompili 氏は、Thomson Reuters の AI およびコグニティブコンピューティングセンター (C3) のシニア NLP リサーチサイエンティストです。Filippo 氏は、機械による読解、情報検索、およびニューラル言語モデリングの専門知識を持っています。最先端の機械学習の発見を、Thomson Reuters の最先端の製品に導入することに積極的に取り組んでいます。