Amazon Web Services ブログ
Amazon SageMaker Neo と Amazon Elastic Inference を使用してパフォーマンスを向上させ、MXNet 推論のコストを削減する
本番環境でディープラーニングモデルを実行する場合、インフラストラクチャコストとモデルレイテンシーのバランスを常に考えることが重要です。re:Invent 2018 で、AWS は Amazon SageMaker Neo と Amazon Elastic Inference を導入しました。これらは、ディープラーニングのモデルの作成をより効率的にする 2 つのサービスです。
ほとんどのディープラーニングアプリケーションでは、トレーニング済みのモデルを使用した予測 (これは推論と呼ばれるプロセスです) が、2 つの要因により、アプリケーションの計算コストの 90% を占める可能性があります。まず、スタンドアロン GPU インスタンスはモデルのトレーニング用に設計されており、通常、推論のためにサイズが大きくなっています。トレーニングジョブは何百ものデータサンプルを並行してバッチ処理しますが、ほとんどの推論は単一の入力でリアルタイムに発生し、GPU コンピューティングの消費量は少量に過ぎません。ピーク負荷時でも、GPU のコンピューティングキャパシティは十分に活用されていない可能性があります。これは無駄があり、コストがかかります。次に、モデルごとに必要な GPU、CPU、メモリリソースの量が異なります。最も要求の厳しいリソースの要件を満たすのに十分な大きさの GPU インスタンスタイプを選択すると、他のリソースが十分に活用されず、コストが高くなることがよくあります。
Elastic Inference は、推論を実行するために最適な量の GPU コンピューティングを提供するサービスです。SageMaker Neo は、実行速度が最大 2 倍になる可能性のあるメモリインプリントを削減することにより、特定のインフラストラクチャデプロイのディープラーニングモデルを最適化するサービスです。
この記事では、MXNet hot dog/not hot dog 画像分類モデルを Amazon SageMaker にデプロイし、さまざまなデプロイシナリオでモデルのレイテンシーとコストを測定します。また、Amazon SageMaker と Amazon Elastic Inference を使用した導入オプションと、別の Amazon EC2 インスタンスを選択した場合に得られる可能性があるさまざまな結果を評価します。
| このブログ記事について | |
| 完了するまでの時間 | 2 時間
|
| 完了するためのコスト | ~ 10 USD (公開時、使用する条件による)
|
| 学習レベル | 中級 (200) |
| AWS のサービス | Amazon SageMaker
Amazon SageMaker Neo Amazon Elastic Inference |
Amazon Elastic Inference の利点
Amazon Elastic Inference では、開発者は推論コストを大幅に削減でき、専用の GPU インスタンスを使用する場合のコストと比較して、最大 75% 節約できます。Amazon Elastic Inference は、3 つの異なるサイズの GPU アクセラレーション (eia2.medium、eia2.large、および eia2.xlarge) も提供しています。これにより、自然言語処理やコンピュータービジョンなどのさまざまなユースケースのコストとパフォーマンスを最適化する柔軟性が生まれます。Amazon EC2 Auto Scaling グループを使用すると、Elastic Inference アクセラレータ (EIA) を簡単にスケーリングできます。
Amazon SageMaker Neo の利点
SageMaker Neo は、ディープラーニングを使用して、特定のハードウェアおよびディープラーニングフレームワークのコード最適化を見つけ、モデルを精度を損なうことなく最大 2 倍の速度で実行できるようにします。さらに、ディープラーニングネットワークのコードベースを予測に必要なコードのみに削減することで、SageMaker Neo はモデルのメモリフットプリントを最大 10 倍削減できます。SageMaker Neo は、さまざまなプラットフォーム用にモデルを最適化できるため、複数のデプロイ用のモデルの調整が簡単になります。
ノートブックを実行する
この記事では、hot dog / not hot dog データセット内の食品画像用に微調整された事前トレーニング済みの ResNet モデルを使用して、画像分類タスクを詳しく見ていきます。このノートブックでは、Amazon SageMaker を使用して、事前トレーニング済みの畳み込みニューラルネットワークモデルを微調整し、SageMaker Neo を使用してモデルを最適化し、SageMaker Neo と EIA を使用してさまざまな方法でモデルをデプロイしてレイテンシーを評価する方法を示します。
次の手順を実行します。
- EBS スペースが 10 GB 以上ある Amazon SageMaker ノートブックを起動します。
- この記事のリポジトリを GitHub リポジトリから複製します。
hot dog / not hot dogノートブックを起動します。- ターミナルの Food101 データセットをリポジトリフォルダにダウンロードして解凍します。次のコードを参照してください。
- 次のコードで
hot dog / not hot dogデータセットを作成します。 - Amazon SageMaker セッションとロールを作成し、Amazon S3 にアップロードして、モデルをトレーニングします。次のコードを参照してください。
- ロール、インスタンスタイプ、インスタンス数、ハイパーパラメータを使用して Amazon SageMaker MXNet 見積もりをインスタンス化し、モデルに適合させます。次のコードを参照してください。
- SageMaker Neo を使用してモデルを最適化します。次のコードを参照してください。
- モデルのデプロイを準備します。次のコード例は P2 用です。
- モデル推論コードを準備します。
- 推論をデプロイして時間を計ります。次のコード例は P2 用です。
複数のデプロイの評価
アプローチ
この記事では、ベースインスタンスのパフォーマンスを強化するために設計された、SageMaker Neo や EIA などの AWS 機械学習サービスを使用して、GPU および CPU インスタンスをテストすることに焦点を当てました。ResNet モデルのサイズはテスト中に変化し、最終結果は ResNet 101 を使用して報告されました。このテストでは、推論にパブリック hot dog / not hot dog データセットの 50 個のテストイメージを使用して、さまざまなデプロイタイプのレイテンシーとコストへの影響を比較しました。この記事は、推論を実行する際の標準化のために、テスト画像を 512 x 512 の寸法に再形成しました。
結果
次のテーブルは、ResNet 101 モデルを使用して、7 回の実行と 1 回の実行で 1 つのループで 50 のテストイメージを推論した後のレイテンシーとリアルタイムコストを示しています。EIA は eia2.medium で、CPU インスタンスにとどまっている間、推論に正確な量の GPU を使用するのに役立ちました。モデルの推論をノンストップで実行することを意図していたため、参照用の年間運用コストは、Amazon SageMaker エンドポイントを 1 日 24 時間、1 年 365 日実行した場合に基づいて計算しました。
| エンドポイント | 平均時間 (秒) | 標準偏差 (ミリ秒単位のループごと) | リアルタイムのオンデマンドコスト / 時間 | コスト / 100,000 枚の画像 | 年間運用コスト |
| p2.xlarge | 19.6 | 356 | 1.26 USD | 13.68 USD | 11,037.60 USD |
| Neo on p2.xlarge | 5.3 | 133 | 1.26 USD | 3.72 USD | 11,037.60 USD |
| g4dn.xlarge | 15.7 | 193 | 0.74 USD | 6.38 USD | 6,447.36 USD |
| g4dn.xlarge の Neo | 2.7 | 177 | 0.74 USD | 1.11 USD | 6,447.36 USD |
| c5.large と eia2.medium | 20.8 | 246 | 0.29 USD | 3.23 USD | 2,514.12 USD |
| c5.xlarge | 53.9 | 345 | 0.24 USD | 7.13 USD | 2,084.88 USD |
| c5.xlarge の Neo | 21.6 | 665 | 0.24 USD | 2.84 USD | 2,084.88 USD |
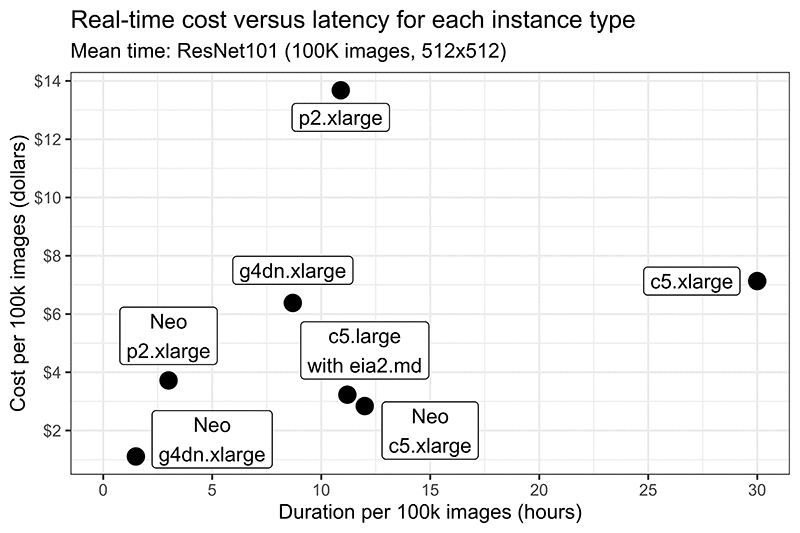
次のグラフは、100,000 枚の画像のリアルタイムコスト (USD 単位) と期間 (時間単位) を示しています。理想的には、デプロイタイプは起点 (0,0) に近いと良いでしょう。バッチ処理でスループットを最大化するユースケースの場合、レイテンシーが最も低いオプションのコストが最も低くなります (SageMaker Neo G4)。SageMaker Neo がモデルデプロイのオプションではない場合、他のデプロイ設定はレイテンシーとコストのバランスが取れています。
次のグラフは、50 のテストイメージのコストとレイテンシー、年間運用コスト (USD) と平均時間 (秒) を比較しています。GPU デプロイオプションは CPU オプションよりもコストがかかりますが、レイテンシーが低いという利点があります。SageMaker Neo を使用すると、特定のインスタンスタイプで同じコストを維持しながら、レイテンシーを短縮できます。

解釈と推奨
レイテンシーのみに基づくと、G4 の SageMaker Neo が明らかに優れており、平均レイテンシーは 2.7 秒で最低でした。P2 の SageMaker Neo はわずかに遅れをとり、平均レイテンシーは 5.3 秒で 2 番目に低い結果でした。ただし、コストも評価する場合、推奨されるオプションはエンドポイントの使用方法によって異なります。たとえば、エンドポイントが継続的にデプロイされると仮定すると、ベース P2 および P2 と SageMaker Neo のオプションの両方の年間運用コストは、このテストのすべてのデプロイ方法の中で最高でした。ただし、100,000 枚の画像で推論を実行するなど、定期的に発生するスループットを処理するためにそれを使用する場合、SageMaker Neo での P2 のコストは、実験に対して推論が発生する速度により、コスト範囲の下限に近くなります。いくつかのエンドポイント設定を評価して、エンドポイントの使用のコスト、レイテンシー、および頻度を考慮することにより、最小のコストで最適なレイテンシーを実現できます。
継続的なデプロイの場合、年間最低コストのオプションは、C5 エンドポイントと C5 エンドポイント上の対応する SageMaker Neo です。これらの平均レイテンシーは、それぞれ 53.9 秒と 21.6 秒でした。100,000 枚の画像のスループット処理の場合、関連するレイテンシーが大幅に減少したため、1 時間あたりの料金が高いにもかかわらず、SageMaker Neo でコンパイルされた G4 インスタンスが最も費用対効果が高くなりました。他の費用対効果の高いオプションは、関連するレイテンシーが減少することによる、C5 の SageMaker Neo および C5 と EIA のオプションです。C5 と EIA のオプションには、CPU コンテキストを使用してデータ前処理のみを行うという利点がさらにありますが、SageMaker Neo c5.xlarge は、CPU 容量を使用して推論とデータ前処理の両方を処理します。
これは、SageMaker Neo または EIA を使用して、このインスタンスタイプのエンドポイントレイテンシーを最適化する利点を示しています。SageMaker Neo を使用すると、レイテンシーが 60% 削減され、同じ年間コストで 100,000 枚の画像を処理するためのコストが 60% 削減されました。EIA を使用して 100,000 枚の画像を処理すると、平均レイテンシーが 61% 削減され、コストが 55% 削減されましたが、年単位では 21% のコスト増になります。テストした他のオプションと比較して、SageMaker Neo と EIA は、わずかなコストからごくわずかな追加コストで優れた効率向上を実現しました。
G4 インスタンスのデプロイは、レイテンシーとコストのバランスを提供し、SageMaker Neo と組み合わせると、スループット処理に最も費用対効果の高いオプションを提供しました。G4 の SageMaker Neo オプションの平均レイテンシーは 2.7 秒で最低でしたが、ベース G4 インスタンスの平均レイテンシーは 15.7 秒で 3 番目に低い結果でした (P2 の SageMaker Neo オプションに次いで)。G4 の SageMaker Neo およびベース G4 はどちらも年間運用コストの中間点にありましたが、G4 の SageMaker Neo は、評価したすべてのエンドポイントの中で最も低いスループットの運用コストでした。G4 で SageMaker Neo を使用すると、基本的な G4 インスタンスの約 6 倍のレイテンシーの削減が実現しました。SageMaker Neo を使用してコンパイルされたモデルでは、G4 は P2 の約 2 倍、C5 の 8 倍高速でした。インスタンスのコストを年間ベースで比較すると、G4 のコストは P2 より 42% 低く、C5 のコストは G4 より 68% 低くなっています。コストを犠牲にしながら、G4 の SageMaker Neo は C5 よりもはるかに高い推論速度を提供します。
全体として、テストでは、SageMaker Neo がレイテンシーを削減しながら、年間の稼働ベースで調査した場合、基本インスタンスと同じコストを維持できることが示されました。ただし、スループットのパフォーマンスを測定すると、コストの観点から SageMaker Neo の利点は明らかです。P2 インスタンスで SageMaker Neo を使用した場合のコストは、継続的な年間デプロイについて評価したすべてのオプションの中で最高でしたが、スループット処理のコストは、ベース P2 と比較して 73% 減少しました。
P2 インスタンスで SageMaker Neo を使用しても、レイテンシーが約 3.7 倍、19.6 秒から 5.3 秒に短縮されました。C5 と SageMaker Neo のオプションでテストした場合、レイテンシーの減少は 2.5 倍でした。それでも、可能な限り SageMaker Neo を接続することは、レイテンシーを削減するための賢明な選択であり、GPU には CPU インスタンスよりも大きなメリットがあります。
C5 インスタンスに接続された EIA は、年間コストのわずかな増加とスループット処理コストの大幅な削減でレイテンシーを改善するのに役立ちました。SageMaker Neo と同様に、EIA はレイテンシーを 53.9 秒から 20.8 秒に約 2.6 倍短縮し、コストはオンデマンド時間あたり 0.05 USD の微増に抑えられました。SageMaker Neo を使用できないシナリオでは、EIA のアタッチは、CPU インスタンスに支払う一方、必要な GPU アクセラレーションのみを使用するため、費用効果が高くなります。
まとめ
この推論研究の結果から、レイテンシー、コスト要件、および推論タスクのタイプに応じて、潜在的に使用できるソリューションがいくつかあることが分かります。コストが問題ではなく、レイテンシーが最重要である場合、G4 の SageMaker Neo デプロイが最良の選択肢です。コストが大きな懸念事項である場合は、レイテンシーを犠牲にしてもエンドポイントは継続的に使用するため、SageMaker Neo または EIA と C5 インスタンスのオプションを使用することをお勧めします。スループット処理ジョブの場合、P2 と SageMaker Neo のオプションと G4 と SageMaker Neo のオプションはどちらも効果的な低コストオプションであり、C5 インスタンスと SageMaker Neo または EIA のオプションよりもわずかに高価なだけです。最後に、GPU が必要で、SageMaker Neo も EIA も使用できない場合は、G4 インスタンスがコストとレイテンシーのバランスをとるのに適したオプションです。
全体的に見て、この評価は、SageMaker Neo または EIA を使用すると、エンドポイントのコストを最小限に抑えるか、まったく増加させずにパフォーマンスを大幅に向上させ、スループット処理に使用した場合に支出を大幅に削減できる可能性があることを示しました。これらのオプションが実現可能ではないが、レイテンシーが依然として重要な要素である場合、G4 インスタンスはスタンドアロン P2 インスタンスよりも優先され、推論速度が速くなると同時にコストも削減されます。
Amazon SageMaker コンソールを開いて、使用開始しましょう。
著者について
 Dheepan Ramanan は、AWS プロフェッショナルサービス AI/ML グローバルスペシャリティプラクティスのデータサイエンティストです。Dheepan は AWS のお客様と協力して、自然言語処理、コンピュータービジョン、および製品推奨のための機械学習モデルを構築しています。余暇には、手の込んだペンやインクで絵を描いたり、ステーキを食べたり、プードルを散歩に連れていったりするなど、アナログ活動に勤しんでいます。
Dheepan Ramanan は、AWS プロフェッショナルサービス AI/ML グローバルスペシャリティプラクティスのデータサイエンティストです。Dheepan は AWS のお客様と協力して、自然言語処理、コンピュータービジョン、および製品推奨のための機械学習モデルを構築しています。余暇には、手の込んだペンやインクで絵を描いたり、ステーキを食べたり、プードルを散歩に連れていったりするなど、アナログ活動に勤しんでいます。
 Ryan Gillespie は、AWS プロフェッショナルサービスのデータサイエンティストです。 彼はノースウェスタン大学で修士号を取得し、トロント大学で MBA を取得しました。 彼は、前職で小売および鉱業業界での経験があります。
Ryan Gillespie は、AWS プロフェッショナルサービスのデータサイエンティストです。 彼はノースウェスタン大学で修士号を取得し、トロント大学で MBA を取得しました。 彼は、前職で小売および鉱業業界での経験があります。
 Jimmy Wong は、AWS プロフェッショナルサービス AI/ML グローバルスペシャリティプラクティスのアソシエイトデータサイエンティストです。彼は、お客様向けの自然言語処理とコンピュータービジョンに関連する機械学習ソリューションの開発に力を入れています。余暇には、Nintendo Switch をプレイしたり、逃した番組を視聴したり、運動したりしています。
Jimmy Wong は、AWS プロフェッショナルサービス AI/ML グローバルスペシャリティプラクティスのアソシエイトデータサイエンティストです。彼は、お客様向けの自然言語処理とコンピュータービジョンに関連する機械学習ソリューションの開発に力を入れています。余暇には、Nintendo Switch をプレイしたり、逃した番組を視聴したり、運動したりしています。