Amazon Web Services ブログ
初めてのPerformance Insights入門 – その3
テクニカルソリューションアーキテクトの笹川です。
前回は初めてのPerformance Insights入門 – その2 と題してPerformance Insightsと拡張モニタリングを使ってデータベースのパフォーマンスチューニングを行ってみました。パフォーマンスチューニングをする際に何を手がかりにどう確認していくのか、少しでもイメージを掴んで頂けていたら幸いです。今回も引き続き、色々なシナリオを検討しながらPerformance Insightsを使ってパフォーマンスチューニングを行ってみたいと思います。
検証環境と注意事項
本記事では下記の環境で検証を行なっていきます。
- RDS MySQL8.0.23
- db.m3.medium (1vCPU, メモリ3.75GiB)
- プロビジョンドIOPS (3000IOPS)
- マルチAZ設定有
尚、前回同様待機イベントはDBエンジン毎に異なり、バージョン間でも差異があります。また、Aurora MySQLとRDS MySQLでも異なる場合があるので今回の検証の結果がそのままAurora MySQLでも出力される訳ではないのでご注意下さい。インスタンスタイプも結果に大きく影響してくるため、その点もご注意下さい。
テストデータは第一回でご紹介したこちらを引き続き使用していきます。既にデータがインポート済みの前提で進めますので、データのインポート方法について知りたい方は第一回の記事をご覧ください。また、今回はシナリオ毎に追加でテーブルを用意し、セレクトだけではなくインサートやアップデートのパターンも含めて検証を行なっていきます。事前に下記SQLを実行してテスト用のテーブルを作成して検証を行ないます。
また、今回も前回同様OSとデータベース、それぞれのモニタリングでどこまで負荷の状況を確認できるか確かめながら検証を進めたい為、OSのモニタリングを拡張モニタリングで行い、データベースのモニタリングをPerformance Insightsで行いながらクエリのパフォーンスチューニングを行なっていきます。
シナリオ1 – CPU使用率はまだ余裕があり、ロードアベレージが少し高い
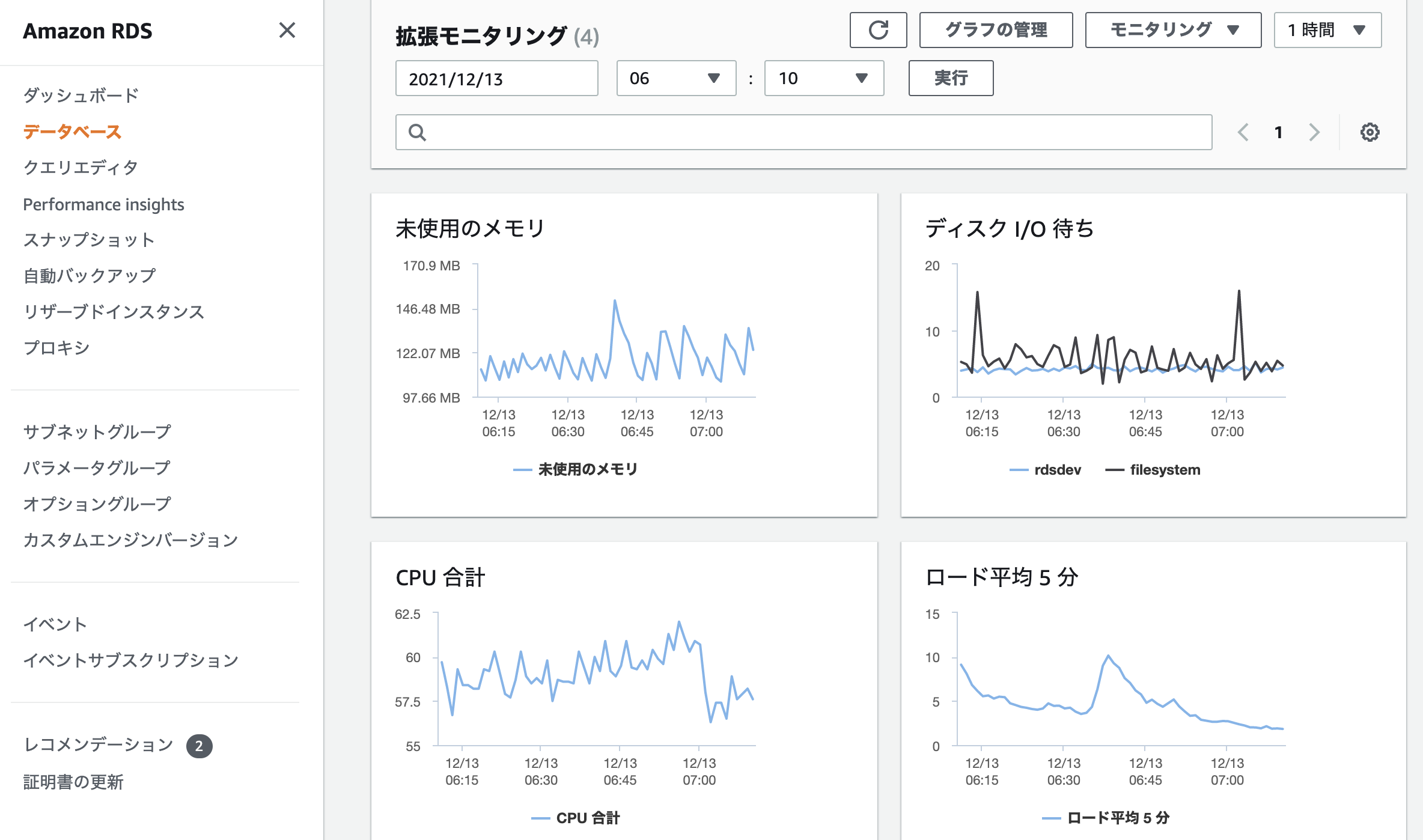
グラフの管理から未使用のメモリ、ディスクI/O待ち、CPU合計、ロード平均5分の4つの項目に絞って拡張モニタリングを表示しています。OSの状態を確認すると、CPUはまだ余裕があり、未使用のメモリは増減しています。ディスクI/O待ちも大きくは発生していません。一方、ロードアベレージが1を超えている少し気になる状態であり、プロセスが何らかの原因により待ちが発生しているかも、と推測はできるのですが、これだけでは原因を突き止めるのが難しそうです。Performance InsightsでDBの詳細な状態を確認し、問題が起きているのか探ってみましょう。
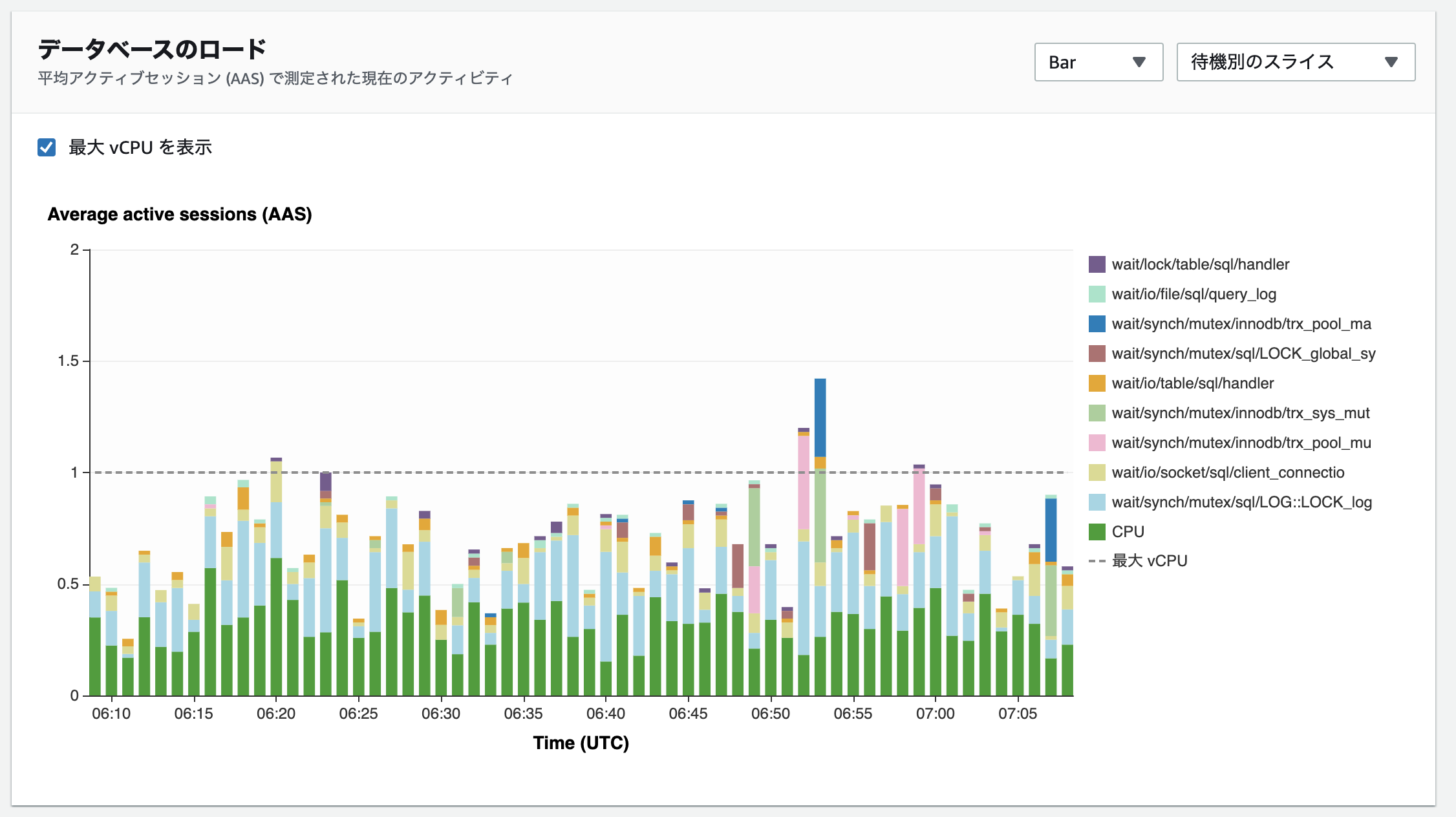

様々な種類の待機イベントが表示されています。どの待機イベントが影響しているのか整理してみましょう。実行されているクエリは第一回から使用しているemployeesテーブルへのクエリ、そして今回新しく追加したpitestテーブルへのインサート処理となっています。その中で一番大きい割合を占めている待機イベントはCPUです。その次に多くの割合を占めているのはwait/synch/mutex/sql/LOG::LOCK_logになっています。Auroraのマニュアルに最近追加された待機イベントの一覧から、MySQL内部でログの書き込み時にロック待ちが発生していると考えてみます。MySQLでログを書き込む仕組みとして、まず一般クエリログが考えられます。一般クエリログはMySQL上で実行された全てのクエリのログを保存してくれる仕組みで、監査目的にログを出しておくことがあります。一般クエリログが大量に書き込まれることでwait/synch/mutex/sql/LOG::LOCK_logの待機イベントが発生していると推測し検証を行ってみましょう。下記で一般クエリログがONになっているか確認します。
general_logが1になっているので一般クエリログがONになっていることが確認できます。また、log_outputの設定がFILEになっていることも確認できます。log_outputの設定により、一般クエリログをファイルに出力するか、テーブルに出力するかを選択することができ、現在はファイルに出力する設定になっていることが確認できます。出力形式の違いについてはこちらに説明がありますのでご参照ください。
ここではgeneral_logを0にして一般クエリログをOFFにし、再度同じパターンのクエリを流して結果がどう変わるか検証してみましょう。RDSではgeneral_logは前回ご紹介したパラメータグループにより変更できます。

拡張モニタリングから確認すると、早速違いがあることがわかります。CPUの消費が下がり、ロードアベレージも多少改善されました。一般クエリログをOFFにしたことにより、ログ書き込みによるロック待ちが解消されプロセスの待ちが減ったと考えられます。Performance Insightsで待機イベントの状態も確認しましょう。


Performance Insightsを確認すると、wait/synch/mutex/sql/LOG::LOCK_logが表示されなくなっていることがわかります。それに伴いAASも最大1.5近くまであったのが、最大でも0.9程度まで下がっています。待機イベントの数値もemployeesテーブルのセレクトは0.37から0.16、pitestテーブルへのインサートも0.16から0.08と改善されています。ログ書き込みによるロック待ちが解消されたことにより、全体として改善されたことがわかりました。このように一般クエリログを出力させないことでパフォーマンスが改善されることがあります。ログ出力により負荷が発生している場合は要件を検討の上、一般クエリログの設定を見直すことを検討してみてください。例えば先程ご紹介したようにlog_outputをTABLEに変更してテーブルにログを出力する方法も考えられます。監査目的で一般クエリログを出力していた場合は、代わりに監査ログを有効にすることもできます。こちらで要件を満たせるかも検討してみてください。
シナリオ2 – CPU使用率はまだ余裕があり、ロードアベレージが少し高い – その2

今回もグラフの管理から未使用のメモリ、ディスクI/O待ち、CPU合計、ロード平均5分の4つの項目に絞って拡張モニタリングを表示しています。OSの状態を確認すると一つ前のシナリオと大体同じ状態です。CPUはまだ余裕があり、未使用のメモリは段々と減少しています。ディスクI/O待ちも大きくは発生していません。ロードアベレージが2程度の為(今回の検証環境はdb.m3.medium (1vCPU))、プロセスが何らかの原因により待ちが発生していそうです。こちらもPerformance InsightsでDBの詳細な状態を確認し、問題が起きているのか探ってみましょう。
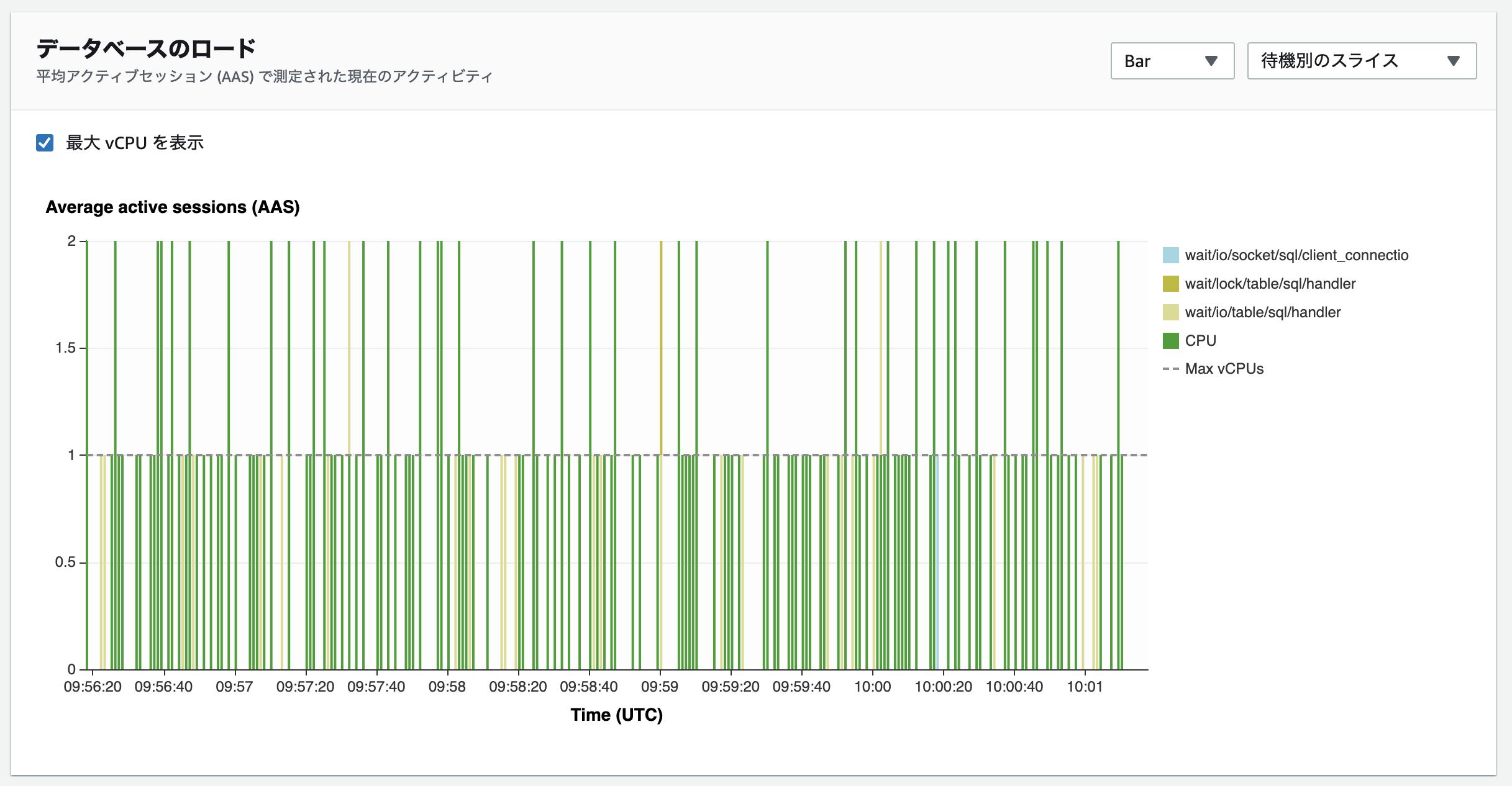
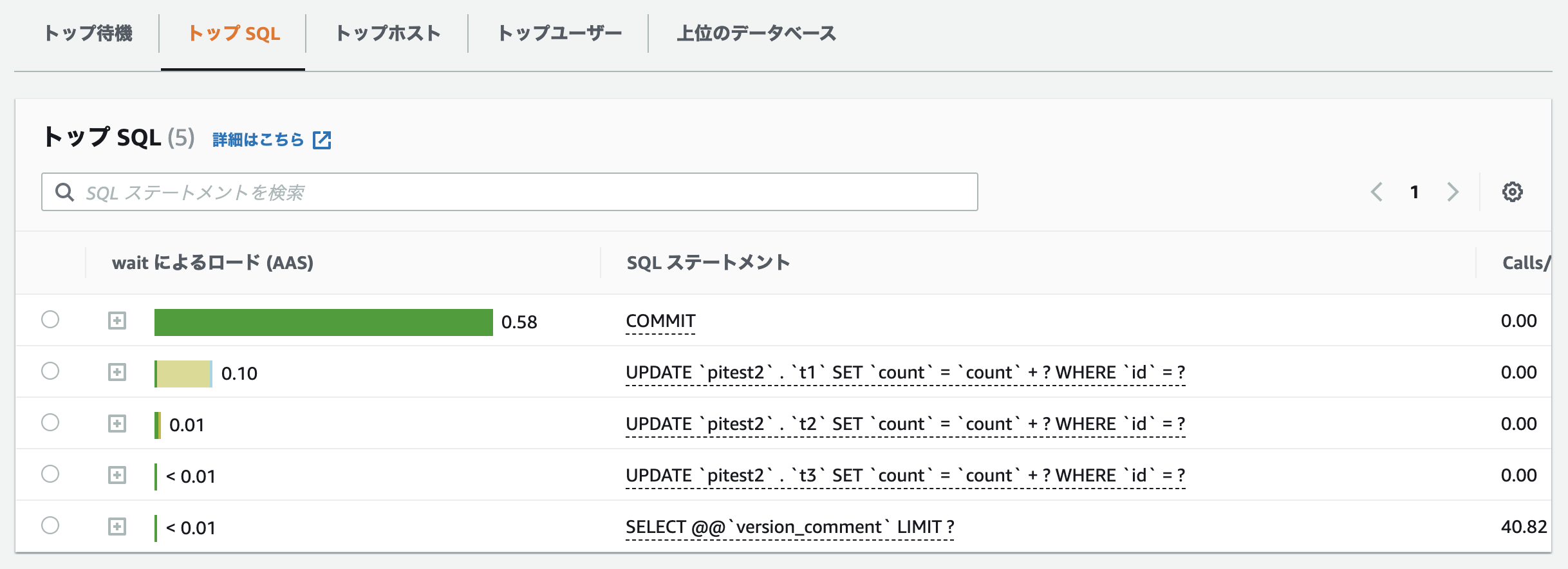
Performance Insightsを確認すると、CPU待機イベントはほとんどCOMMITにより発生しています。続くクエリはテスト用に用意したt1, t2, t3テーブルに対するアップデート処理が行われています。全体としては大きな問題は無さそうですが、t1テーブルのみwait/io/table/sql/handlerがやや大きく発生しているようです。なぜこの状態になっているか考えてみましょう。
今回のシナリオでは下記の更新クエリを2並列で流し続けています。
一つのトランザクション内でt1, t2, t3テーブルそれぞれに対してidを絞り、countカラムに対してインクリメントを行なっています。1トランザクション内で複数テーブルにまたがった更新処理を行っている為、ロック待ちが長くなり並列で動いているクエリに待ちが発生し、wait/io/table/sql/handlerとして待機イベントが発生、特にt1テーブルに対する待ちが大きくなっていたようです。このことからMySQLではトランザクションによるロック待ちの場合でもwait/io/table/sql/handlerが発生することがわかりました(MySQL8.0.23現在)。第一回でもご紹介したように、wait/io/table/sql/handlerは書き込み待ちでも読み込み待ちでも発生するとご説明致しましたが、トランザクションによるロック待ちでも現れる為、wait/io/table/sql/handlerが発生している原因を突き止めることはデータベース内部で起こっている事象を理解することに役立ちそうです。
この待機イベントを改善するにはどうすれば良いか検討します。複数テーブルにまたがって処理を行うことでロック待ちが長くなり待機イベントが発生している為、ここでは試しに更新するテーブルを一つに変更して2並列で流し、結果がどう変わるか検証してみましょう。

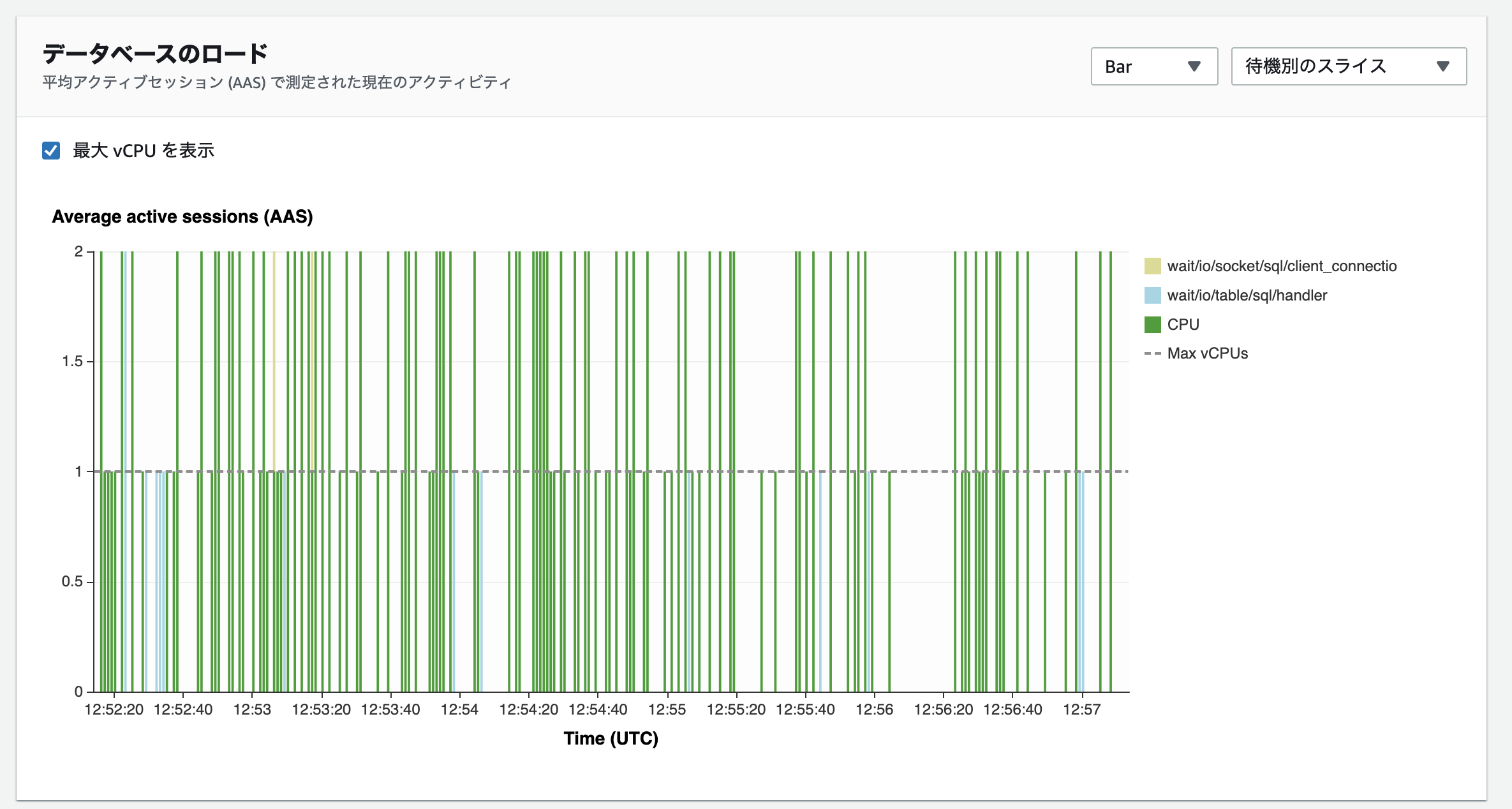

拡張モニタリングの結果では、ロードアベレージはそこまで変わらずCPUの消費が70から60に減っています。Performance Insightsを確認すると、t1テーブルへのアップデート操作に対する待機イベントの数値が0.10から0.05へ多少改善されています。wait/io/table/sql/handlerによる待機が減り、それに伴い拡張モニタリングに表示されていたCPU合計の消費も多少下がったと考えられます。トランザクション内の処理を整理することで多少待機イベントが改善されることがわかりました。wait/io/table/sql/handlerにより遅延していそうだけど原因がわからないという場合は、このようにトランザクションの処理を整理してロック待ちを減らすことを検討するのも改善の可能性があります。今回のように、単純に更新をするテーブルを減らすというのは中々難しいかもしれませんが、例えば非正規化などを行いトランザクションで処理するテーブルを一つにまとめるなどの方法も考えられます。また、どうしてもトランザクションの処理を減らすことができない場合は、where句で絞り込む行の対象を変更する方法も考えられます。MySQLではインデックスが作られているカラムに対して行ロックをかけることができます。今回の例では、それぞれのクエリのwhere句で指定しているidを別々にすることにより、並列でクエリを流してもロック待ちをせずにアップデートをかけることができるようになります。場合によってはそういった工夫も効果がある可能性がある為、状況に応じて様々なパターンを検証してみてください。
尚、こちらの資料を参考にMySQLのsysスキーマを使用して現在ロック待ちが発生しているクエリを確認することができます。今回の例ではこのような結果を得ることができました。
また、 Performance Schemaのtable_lock_waits_summary_by_tableを使ってテーブル毎のロック状況のサマリを取得することができます。今回の例ではCOUNT_WRITEの数字がかなり大きくなっているので、t1テーブルに関しては書き込み待ちが大量に発生していると考えられます。より詳細な情報が必要な場合は、sysスキーマやPerformance Schema自体を活用することも検討してみて下さい。
まとめ
前回に引き続き拡張モニタリングとPerformance Insightsを使ってパフォーマンスチューニングをしてみましたが、いかがでしたでしょうか。今回はOSのメトリクスからだけでは問題が発生しているのか判断が難しいシナリオで検証してみました。こういったパターンでは、Performance Insightsが効果的に使えることがより具体的にイメージできたのではないでしょうか。今までご紹介した例を参考に、是非Performance Insightsをパフォーマンスチューニングにお役立て下さい。