Amazon Web Services ブログ
Amazon QuickSight で Amazon SageMaker 機械学習予測を視覚化する
AWS は、QuickSight における Amazon SageMaker 統合の一般提供を発表いたします。この一般提供により、お客様独自の Amazon SageMaker ML モデルと QuickSight を統合し、拡張データを分析したり、ビジネスインテリジェンスダッシュボードで直接使用したりできるようになりました。ビジネスアナリスト、データエンジニア、またはデータサイエンティストのいずれの方でも、わずか数クリックで ML 推論を実行することが可能です。このプロセスでは新しいデータに基づいた予測を行い、Amazon SageMaker モデルを、顧客離れの可能性の予測や営業活動優先化のためのリードスコアリング、そしてローン申請の信用リスク評価といったさまざまなユースケースに利用します。
お客様のユースケース
Change Healthcare は、米国の医療システムにおける臨床、財務、および患者エンゲージメントの結果を改善するためのデータおよび分析主導型ソリューションを提供する大手独立系医療テクノロジー企業です。
Change Healthcare の AI エンジニアリングのシニアディレクターである Jayant Thomas 氏はこう述べます。「Amazon SageMaker を過払いや無駄の削減といったさまざまな機械学習のユースケースに活用しています。Amazon QuickSight に SageMaker 統合が追加され、喜ばしく思っています。これにより SageMaker 型推論アーキテクチャのワークフローと開発サイクルが合理化されるため、BI や ML Insights、ダッシュボード公開の主なソリューションとして QuickSight が強化されているのです。」
Amazon QuickSight と Amazon SageMaker の統合
従来であれば、トレーニング済みモデルからの予測を BI ツールに移行するのはかなり大変な作業です。データを Amazon Simple Storage Service (Amazon S3) に抽出、変換、ロード (ETL) するためにコードを書き、予測を得るために推論 API を呼び出し、モデル出力を Amazon S3 からクエリ可能なソースへ ETL し、新しいデータを入手するたびにこのプロセスをオーケストレートする必要があります。しかも、すべてのモデルでそのワークフローを繰り返さなければなりません。推論エンドポイントではモデルの消費がより簡単になりますが、不使用時でも請求が発生する可能性があるというリスクがあります。最後に、Excel などサードパーティーツールを使用して分析や予測のレポートを行う場合、その結果を多くのユーザー向けに更新、共有するのは困難です。エンドツーエンドプロセスを通じてモデルから価値を得ようとするのは大変な作業で、モデル予測がビジネスにおける意思決定者の手に渡るまで何日も、あるいは何週間もかかることがあります。
QuickSight と Amazon SageMaker 機能の統合では、データの移動および推論パイプラインをすべて自動化することでこうした問題点に対応します。
お使いのデータセットで推論を実行するには、QuickSight でサポートされているデータソース(Amazon S3、Amazon Athena、Amazon Aurora、Amazon Relational Database Service (Amazon RDS)、Amazon Redshift、および SalesForce、ServiceNow、JIRA などサードパーティのアプリケーションソース)のいずれにも接続でき、予測に使用したい事前学習済み Amazon SageMaker モデルを選択いただければ、他の作業は QuickSight が行います。データ取り込みおよび推論ジョブが完了すると、視覚化の作成や予測に基づくレポートの構築、そしてビジネスステークホルダーとの共有を、すべてエンドツーエンドのワークフローで行うことができます。推論の出力は QuickSight SPICE として格納され、他のユーザーと共有することが可能です。手動での予測や 1 回限りの予測を行ったり、スケジュールに従った予測を実行したり、データ更新時には QuickSight データセット API 経由でプログラムを使用して予測をトリガーしたりすることができます。
この記事では、顧客離れのユースケースについて説明します。具体的には、利用中の携帯電話会社から顧客が離れていく可能性を予測していきます。どういった顧客が離れていくのかがわかれば、プロバイダーとしては携帯電話のアップグレードや、さらには新機能の導入といった、プロバイダーを変更しないことで得られるインセンティブをタイムリーに提供することができます。インセンティブの費用対効果は、顧客を失って新たに獲得するよりはるかに高いことが少なくありません。顧客の反応とサービス利用状況のデータを利用すれば、離れていく可能性が最も高い顧客群を見出すことが可能です。
このユースケースでは、顧客離れを予測する Amazon SageMaker モデルをトレーニングし、QuickSight を Amazon SageMaker と接続し、現在の顧客ベースに基づくモデルを使用してリスクのある顧客を特定し、QuickSight を介して予測ダッシュボードを提供する方法を見ていきます。ML の専門的な経験がなくても利用できます。チュートリアルでは、この予測データを使用してダッシュボードを構築する方法を説明します。
Amazon SageMaker の環境を設定する
Amazon SageMaker の環境を設定するには、以下の手順を実行します。
- Amazon SageMaker コンソールで、[ノートブックインスタンス] をクリックします。
- [ノートブックを作成する] を選択します。
- [ノートブックインスタンス名] に、インスタンス名を入力します (例: QS-sagemaker)。
- [ノートブックインスタンスタイプ] で [ml.t3.medium] を選択します。
- [IAM ロールの作成] で、[新しいロールの作成] をクリックします。
- [S3 バケット]で、[任意の S3 bucket] をクリックします。
通常は特定のバケットを選択する必要がありますが、ここではまだ作成していないため、ノートブックで行います。
- [ロールの作成] を選択します。
- [Git リポジトリ] を選択します。
- [リポジトリ] で、[パブリック Git リポジトリのクローンをこのノートブックインスタンスだけに作成する] を選択します。
- [Git リポジトリ URL] に、
https://github.com/aws-samples/quicksight-sagemaker-integration-blog.gitと入力します。 - 他のフィールドはすべてデフォルトのままにします。
- [ノートブックインスタンスの作成] を選択します。
これで、ノートブックインスタンスの一覧を見られるようになりました。新しいインスタンスステータスが [実行中] と表示されるまで待ちます。これには最大で 5 分間かかることがあります。ブラウザによっては、ページを更新する必要がある可能性もあります。
- インスタンスの次は [JupyterLab を開く] を選択します。
ブラウザで JupyterLab ページが開きます。
ノートブックを実行する
ノートブックを実行するには、以下の手順を実行してください。
- JupyterLab ページを開いて quicksight-sagemaker-integration を表示し、customer_churn.ipynb を選択します。IPython ノートブックが開きます。
- ノートブックの最初のセルで、お使いの S3 バケット名を設定します。構築したデータセットおよびモデルの格納には S3 バケットを作成する必要があります。「S3 バケットを作成する方法」を参照してください。 これは、ノートブックインスタンスと同じリージョンで行う必要があります。

- ノートブックの各セルの読み込みと実行を行います。
ノートブックには事前処理、モデルのトレーニング、および各手順の事後処理が含まれます。QS-inference-pipeline- で始まる名前のモデルが作成されます。これは QuickSight で推論の実行やデータセットの拡張を行いたい Amazon SageMaker モデルの名前です。
Amazon SageMaker と連動させる Amazon QuickSight の設定
QuickSight と Amazon SageMaker の統合は、Amazon QuickSight のエンタープライズエディションでのみ利用可能です。スタンダードエディションをご利用の場合でも、サブスクリプションのアップグレードは簡単に行えます。別エディションについて詳細は、Amazon QuickSight の料金を参照してください。
- 以下の手順を完了させるには QuickSight エンタープライズエディションが必要となります。詳細については、こちらを参照してください。Amazon QuickSight エンタープライズエディションのアカウントを作成する方法を教えてください。
- QuickSight にログインしたら、Amazon SageMaker で起動したリージョンと同じリージョンを選択します。
- [QuickSight の管理] を選択します。

- [セキュリティとアクセス許可] を選択します。
- [追加または削除] を選択します。

- [Amazon S3] を選択します。
- [S3 バケットの選択] をクリックします。

- 作成したバケットを選択します。

- [Amazon SageMaker] を選択します。
- [更新] を選択します。
 これらの手順の完了には管理者権限が必要です。
これらの手順の完了には管理者権限が必要です。 - QuickSight コンソールに戻るには、[QuickSight] を選択します。
QuickSight でデータセットを設定し、顧客離れの予測を行う
テストデータセットは、ノートブックを実行したときに既にバケットにアップロードされています。S3://<bucket_name>/<prefix>/rawtest/test.csv 内にアップロードされているはずです。 このファイルには、ラベル列 (Churn) の例外を除き、先程 Amazon SageMaker で使用したトレーニングデータセットと同じフォーマットで顧客詳細が記載されています。予測にはこのテストセットを使用します。ノートブックの最初のセルから <bucket_name> と <prefix> を取得できます。
- QuickSight コンソールで、[データの管理] を選択します。
- [新しいデータセット] を選択します。
- [S3] を選択します。

- テキストエディタを使用し、以下のコンテンツを含むマニフェストファイル (例:
manifest.json) をローカルで作成します (<bucket_name>と<prefix>はノートブックに以前に設定したものに置き換える)。 - このファイルをアップロードし、Amazon S3 データソースを作成します。

- [データを編集/プレビューする] を選択します。

- 先程構築した Amazon SageMaker モデルでデータを加工するには、[SageMaker で加工する] を選択します。

- [モデル] では、作成したノートブック (
QS-inference-pipeline-で始まるカスタム名つきのノートブック) を選択します。Amazon SageMaker を QuickSight データで使用する場合、QuickSight がモデルを処理する必要のあるメタデータを含む JSON スキーマファイルを事前に作成する必要があります。このファイルからはフィールドやデータタイプ、列順、出力、および予測生成で使用するためのインスタンスタイプなどモデルで必要な設定についてのメタデータが提供されます。 - GitHub repo からこの記事用のスキーマファイルをダウンロードします。
Churn_schema.jsonファイルをローカルに保存します。- Schema については、自分のファイルをアップロードします。

- [次へ] を選択すると、入力の確認ページが開きます。このページでは提供されたスキーマの各フィールドがデータセットのフィールドにどのようにマッピングされるかが示されています。これらのフィールドは、モデルが推論用入力として予期したフィールドです。フィールドのマッピングが正常に行われていない場合、ドロップダウンメニューから変更します。
- [次へ] を選択します。

出力の確認ページが開き、モデルの出力と、予測出力としてデータセットに追加するフィールド名が表示されます。フィールド名は、データセット内で表示したい名前に変更することができます。 - [データの準備] を選択します。

- 情報メッセージを読み込み、閉じます。
- [保存して視覚化] を選択します。

これにより SageMaker でジョブが開始され、データセットに対する推論の実行および新しい列の追加が行われます。Amazon SageMaker モデルでバッチ変換ジョブを実行して推論を完了し、Churn 列を含めたフルスコアデータセットを SPICE に読み込むまでには約 4 分間かかります。
SPICE は QuickSight 用のインメモリ最適化計算エンジンで、高速で 1 回限りのデータ視覚化に特化して設計されています。高度な計算の実行やデータ提供を高速で行うことができます。SPICE では分析の変更やビジュアルの更新ごとにデータを取得する必要がないため、時間節約につながります。
Amazon SageMaker 推論が完了すると、Import complete メッセージが表示されます。
顧客離れ予測のダッシュボードを作成する
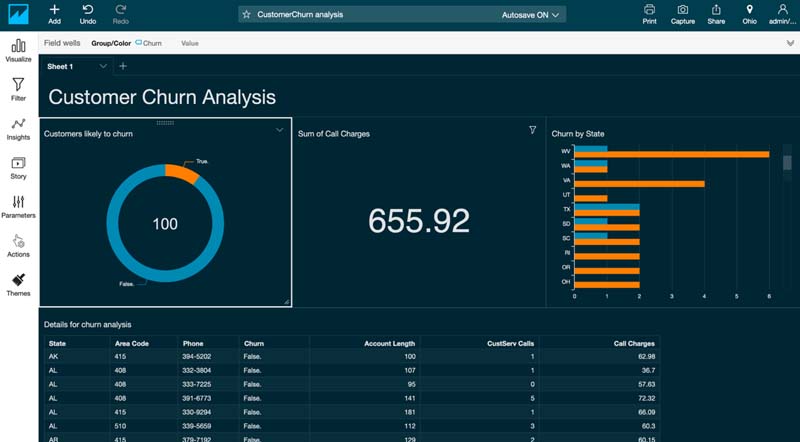
これで、予測の出力結果を利用してダッシュボードを構築し、結果を視覚化することができるようになりました。次のスクリーンショットには、このチュートリアルで作成したダッシュボードの最終版が表示されています。

顧客離れの可能性のある顧客をプロットする
まず、ドーナツチャートを作成して顧客離れの可能性のある顧客をプロットします。
- [フィールドリスト] で、[Churn] を選択します。
[ビジュアルタイプ] はデフォルトでオートグラフを採用しているため、QuickSight はこのデータを表示するには棒グラフが最適であると判断し、真偽予測の区別を提供します。

- ドーナツチャートとして表示するには、[ビジュアルタイプ] でドーナツチャートを選択します。
- タイトルを変更するには、[タイトルフィールド] を選択し、
Customers likely to churnと入力します。

- 凡例を非表示にするには、[ビジュアル] のドロップダウンメニューから、[凡例の非表示] を選択してクリックします。

顧客離れにより想定される減収を視覚化する
次に、顧客離れによってどれだけの減収が見込まれるかを表示するビジュアルを追加します。
- [フィールドリスト] を選択し、
chargeと入力します。
 charge 列が 4 列にわたって作成されます。
charge 列が 4 列にわたって作成されます。
 これらの 4 つのフィールドを追加した計算フィールドを作成することができます。
これらの 4 つのフィールドを追加した計算フィールドを作成することができます。 - [追加] をクリックします。
- [計算フィールドの追加] を選択します。

- [計算フィールド名] には
Call Chargesと入力します。 - [数式] で、以下のフィールドを選択します。
- Day Charge
- Eve Charge
- Intl Charge
- Night Charge
- [作成] を選択します。

- [追加] をクリックします。
- [ビジュアルの追加] を選択します。

- [フィールドリスト] で [Call Charges] を選択します。全顧客の通話料金合計が見られるようになりました。

また、顧客離れの可能性のある顧客に対する請求のみをフィルタリングして表示することもできます。 - [フィルタ] を選択します。
- [フィルタの作成] を選択します。
- [Churn] を選択します。

- フィルターを選択し、拡大します。

- [True] を選択します。
- [適用] を選択します。

顧客離れが起こった場合に損失が予想される料金額を表示できるようになりました。 - ビジュアルタイトルを選択し、タイトルを
Predicted loss of chargesと入力します。

顧客離れをステートで可視化する
また、顧客離れの顧客数をステートで視覚化することもできます。
- [追加] をクリックします。
- [ビジュアルの追加] を選択します。
- [フィールドリスト] で、[State] と [Churn] を選択します。
- [ビジュアルタイプ] で水平積み上げバーを選択します。
- 凡例を非表示にします。
- タイトルを
Churn by Stateに変更します。

顧客離れ分析の詳細
この最終ビジュアルには、顧客離れ分析の詳細が多数組み合わされています。
- [追加] をクリックします。
- [ビジュアルの追加] を選択します。
- [フィールドリスト] で [State]、[Area code]、[Phone]、[Account Length]、[CustServ Calls]、[Call Charges]、および [Churn] を選択します。
- [ビジュアルタイプ] 下のテーブルアイコンを選択します。
- 名前を
Details for churn analysisに変更します。

ダッシュボード表示をカスタマイズする
次のセクションでは、ダッシュボードの表示をわかりやすくする方法について説明します。最初にタイトルを追加することができます。
- [追加] をクリックします。
- [タイトルの追加] を選択します。

- [シートのタイトル] を選択し、
Customer Churn Analysisと入力します。

次に、ビジュアルをサイズ変更し、3 つが一番上の行に収まるようにします。 - サイズ変更するには、右下隅にあるハンドルを選択します。
- ビジュアルを移動するには、上部中央のハンドルを選択します。

- テーマを変更するには、[テーマ] を選択します。
- [Starter themes] を選択します。
- [Midnight] を選択します。
- [適用] を選択します。

これでデザインプロセスが完了し、ダッシュボード公開の準備が整いました。
ダッシュボードを公開する
ダッシュボードを公開するには、次の手順を実行します。
- [共有] を選択します。
- [ダッシュボードの発行] を選択します。

- [新しいダッシュボードに名前を付けて発行] に、ダッシュボード名を入力します。
- [ダッシュボードの発行] を選択します。

構築を開始するダッシュボードが整いました。

まとめ
QuickSight と Amazon SageMaker の統合により、視覚化のための ML モデルや予測の利用がより高速、簡単、そして費用対効果の高いものになります。本記事では、QuickSight と Amazon SageMaker を統合して全データ移動や推論パイプラインを、コードを書く必要なしに自動化する方法について説明しました。このソリューションにより、お客様の会社で事前構築されたモデルから予測を得るのにかかる時間が短縮されます。加えて、推論実行中の SageMaker バッチ変換ジョブのインスタンス使用時間に基づいてのみ請求が発生し、使用していないときにSageMaker エンドポイントを実行する必要がないので、費用対効果も抜群です。
是非 QuickSight のモデル推論機能をお試しいただき、ご意見やご質問があれば、コメント欄にご記入ください。
著者について
 Saeed Aghabozorgi Ph.D. は、AWS のシニア ML スペシャリストです。データを実用的な知識に変える顧客の能力を大幅に向上させる、エンタープライズレベルのソリューションの開発実績を誇ります。また、人工知能や機械学習分野の研究者でもあります。
Saeed Aghabozorgi Ph.D. は、AWS のシニア ML スペシャリストです。データを実用的な知識に変える顧客の能力を大幅に向上させる、エンタープライズレベルのソリューションの開発実績を誇ります。また、人工知能や機械学習分野の研究者でもあります。
 Raj Patel は、AWS QuickSight のソフトウェア開発マネージャーです。機械学習 (ML) インサイトチームのリーダーを務め、ML を利用してビジネスの問題を解決する機能を構築中です。オフの時間にはハイキングやスポーツ観戦、2 人の子供との時間を楽しんでいます。
Raj Patel は、AWS QuickSight のソフトウェア開発マネージャーです。機械学習 (ML) インサイトチームのリーダーを務め、ML を利用してビジネスの問題を解決する機能を構築中です。オフの時間にはハイキングやスポーツ観戦、2 人の子供との時間を楽しんでいます。
 Luis Wang は Amazon QuickSight の主席プロダクトマネージャーです。彼は AWS で 6 年以上勤務しており、Amazon EC2 をはじめとするさまざまなサービスに携わり、Amazon QuickSight を立ち上げました。Luis は現在、QuickSight の機械学習とAI のビジネスインテリジェンスと分析の応用に注力しています。好きなことはランニング、ホームコメディ鑑賞で、家族と過ごす時間を大切にしています。
Luis Wang は Amazon QuickSight の主席プロダクトマネージャーです。彼は AWS で 6 年以上勤務しており、Amazon EC2 をはじめとするさまざまなサービスに携わり、Amazon QuickSight を立ち上げました。Luis は現在、QuickSight の機械学習とAI のビジネスインテリジェンスと分析の応用に注力しています。好きなことはランニング、ホームコメディ鑑賞で、家族と過ごす時間を大切にしています。
 Arun Santhosh は、Amazon QuickSight の専門グローバルソリューションアーキテクトです。
Arun Santhosh は、Amazon QuickSight の専門グローバルソリューションアーキテクトです。