Amazon Web Services ブログ
Ubuntu 18 DLAMI、P3dn インスタンスの EFA、Amazon FSx for Lustre を使用した大規模なマルチ GPU 分散深層学習トレーニング
AWS Deep Learning AMI (Ubuntu 18.04) は、EC2 Accelerated Computing インスタンスタイプの深層学習用に最適化されており、複数のノードにスケールアウトして分散ワークロードをより効率的かつ簡単に実行できます。同 AMI は、分散型深層学習のトレーニング向けにビルド済み Elastic Fabric Adapter (EFA)、Nvidia GPU スタック、および多くの深層学習フレームワーク (TensorFlow、MXNet、PyTorch、Chainer、Keras) を備えています。深層学習ソフトウェアとドライバーのインストールや機械学習 (ML) インフラストラクチャの構築に時間を費やす必要はありません。代わりに、より短時間で大規模なジョブのトレーニングに集中し、ML モデルでより速く反復することができます。
この記事では、AWS High Performance Computing (HPC) アーキテクチャで大規模な高性能、ネットワーク依存、低レイテンシー、高度に結合された ML 分散トレーニングを簡単に実行できることを示します。HPC アーキテクチャには、Ubuntu 18 DLAMI、P3dn インスタンス上の Elastic Fabric Adapter (EFA)、および Amazon FSx for Lustre が含まれます。また、マルチノード GPU クラスターで PyTorch フレームワークを使用して Bidirectional Encoder Representations from Transformers モデルを実行する方法について説明します。さらに、この記事では、AWS ParallelCluster を通して深層学習クラスターのデプロイと管理を自動化するためのガイダンスを示します。
BERT について
BERT は、さまざまな自然言語処理 (NLP) タスクで最先端の結果を得る言語表現を事前トレーニングする方法です。大規模なテキストコーパス (Wikipedia など) で汎用言語理解モデルをトレーニングし、そのモデルを下流の NLP タスク (質問への回答など) に使用できます。BERT は、NLP を事前トレーニングするための最初の教師なしの深層双方向システムです。
教師なしとは、BERT がプレーンテキストコーパスのみを使用してトレーニングされたことを意味します。これは、大量のプレーンテキストデータが多くの言語でウェブ上で公開されているため重要です。次の表は、この記事が BERT 手順に使用する設定をまとめたものです。これは、200 MB の調整されたバケットサイズでバックワードパスと通信をオーバーラップします。
| モデル | 非表示のレイヤー | 非表示のユニットサイズ | 注意ヘッド | フィードフォワードフィルターサイズ | 最大シーケンス長 | パラメータ |
| ベルトラージ | 24 エンコーダ | 1024 | 16 | 1024 x 4 | 512 | 350 M |
BERT トレーニングのための AWS 上の HPC について
BERT 手順は、Ubuntu18 DLAMI、P3dn インスタンスの EFA、および Ubuntu18 向け FSx for Luster を含む AWS HPC アーキテクチャサービスで実行されます。
AWS Deep Learning AMI (Ubuntu 18.04)
この DLAMI は、Python 2 と Python 3 の両方で Anaconda プラットフォームを使用して、フレームワークを簡単に切り替えられます。AWS Deep Learning AMI は、Nvidia CUDA 9、9.2、10、10.1、および Apache MXNet、PyTorch、TensorFlow を含むいくつもの深層学習フレームワークで事前にビルドされています。この記事では、次の DLAMI 機能を使用します。
- PyTorch フレームワーク – PyTorch は、強力な GPU アクセラレーションを備えたテンソル計算 (NumPy など) と、テープベースのオートグラッドシステム上に構築されたディープニューラルネットワークの 2 つの高レベル機能を提供する Python パッケージです。使用している PyTorch ブランチとタグは v1.2 です。
pytorch環境をアクティブ化するには、source activate pytorch_p36を実行します。 - NVIDIAstack – NVIDIA ドライバー 418.87.01、CUDA 10.1 / cuDNN 7.6.2 / NCCL 2.4.8。
マスターノードは c5n.18xlarge で設定され、ワーカーまたはトレーニングノードは P3dn インスタンスで設定されます。
Elastic Fabric Adapter
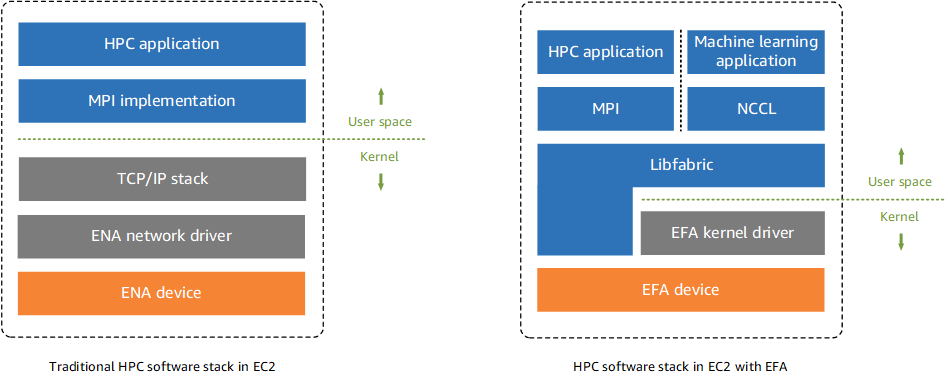
Elastic Fabric Adapter (EFA) は、Amazon EC2 インスタンスにアタッチして、ML アプリケーション用の HPC を高速化できるネットワークデバイスです。EFA は、クラウドベースの HPC システムで従来使用されてきた TCP トランスポートよりも一貫して低いレイテンシーと高いスループットを実現します。これは、ML アプリケーション用の HPC のスケーリングに重要なノード間通信のパフォーマンスを向上させます。EFA は Libfabric 1.8.1 と統合し、HPC アプリケーション向けに Open MPI 4.0.2 および Intel MPI 2019 Update 6 をサポートし、ML アプリケーション向けに Nvidia Collective Communications Library (NCCL) をサポートします。EFA の OS バイパス機能は、HPC および ML アプリケーションがネットワークインターフェイスハードウェアと直接通信して、低レイテンシーで信頼性の高いトランスポート機能を実現できるようにするアクセスモデルです。次の図は、このユースケースの P3dn インスタンス上の EFA デバイスを示しています。
Amazon FSx for Lustre
Lustre は、高性能のワークロード用に設計されたオープンソースの並列ファイルシステムです。このようなワークロードには、HPC、ML、分析、メディア処理が含まれます。並列ファイルシステムは、大量のデータを処理するための高いスループットを提供し、一貫して低いレイテンシーで操作を実行します。これは、何千ものコンピューティングインスタンスが同時に対話できる複数のネットワークサーバーにかけてデータを保存することで実現します。Luster ファイルシステムは、POSIX 準拠のファイルシステムインターフェイスを提供します。Amazon FSx for Lustre は、高性能なフルマネージド Luster ファイルシステムを提供し、ファイルベースのアプリケーションが数百ギガバイト/秒のデータ、数百万の IOPS、サブミリ秒のレイテンシーでデータにアクセスできるようにします。Amazon FSx は、Amazon Simple Storage Service (Amazon S3) とネイティブに連携します。Amazon FSx 上のファイルとして Amazon S3 オブジェクトにアクセスし、結果を Amazon S3 に書き戻すことができます。この記事では、Luster バージョン 2.10.8 を使用しています。
P3dn インスタンス
Amazon EC2 P3dn.24xlarge GPU インスタンスは、分散型 ML および HPC アプリケーション用に最適化されています。P3dn.24xlarge インスタンスは 100 Gbps のネットワーク帯域幅を備えており、新しい EFA ネットワークインターフェイスにより、非常にスケーラブルなノード間通信が可能になります。EFA は、Amazon Linux と Ubuntu オペレーティングシステムの両方で使用でき、LibFabric と統合されています。AWS は、EFA が NCCL をサポートできるように NVIDIA と連携しました。これにより、マルチ GPU およびマルチノード通信プリミティブを最適化し、NVLink 相互接続で高スループットを実現するのに役立ちます。これらの拡張機能を使用すると、ML トレーニングをスケーリングして数千の GPU を使用できるため、トレーニング結果より速く得ることができます。EFA オペレーティングシステムは、ネットワークメカニズムと、Nitro コントローラーに組み込まれている基盤となる Scalable Reliable Protocol をバイパスします。Nitro コントローラーは、インスタンス間の通信向けに低レイテンシー、低ジッターのチャネルを可能にします。次の表は、この記事で使用されている P3dn.24xlarge インスタンスの機能を示しています。
| 機能 | 値 |
| GPU | 8x 32 GB NVIDIA Tesla V100 |
| GPU 相互接続 | NVLink – 300 GB/s |
| GPU メモリ | 256 GB |
| プロセッサ | Intel Skylake 8175 (AVX 512 付き) |
| vCPU | 96 |
| RAM | 768 GB |
| ネットワーク帯域幅 | 100 Gbps + EFA |
AWS ParallelCluster
AWS でサポートされているオープンソースのクラスター管理ツールである AWS ParallelCluster を使用して、HPC クラスターのデプロイと管理を自動化できます。安全で反復可能な方法でリソースをプロビジョニングできるため、手動のアクションやカスタムスクリプトを必要とせずに HPC インフラストラクチャを構築および再構築できます。AWS ParallelCluster は、シンプルなテキストファイルを使用して、HPC アプリケーションに必要なすべてのリソースを自動化された安全な方法でモデル化し、動的にプロビジョニングします。AWS ParallelCluster は AWS Batch、SGE、Torque、および Slurm ジョブスケジューラをサポートしていて、簡単にジョブを送信できます。
分散 BERT トレーニング環境のセットアップ
分散 BERT トレーニング環境をセットアップするには、次の手順を実行します。
- 1 つのパブリックサブネット、1 つのプライベートサブネット、および 1 つのクラスタープレースメントグループで VPC を構築します。EFA には、セキュリティグループ自体へのすべての送受信トラフィックを許可するセキュリティグループも必要です。
- セキュリティグループの [Inbound] と [Outbound] タブで、以下を実行します。
- [Edit] を選択します。
- [Type] では、[All traffic] を選択します。
- [Source] では、[Custom] を選択します。
- コピーしたセキュリティグループ ID をフィールドに入力します。
- [Save] をクリックします。
- Ubuntu18 DLAMI を使用して EFA 対応の P3dn.24xlarge インスタンスを起動します。P3dn インスタンスは、AWS マネジメントコンソール、AWS Command Line Interface (AWS CLI)、または SDK ツールキットで起動できます。BERT トレーニングを実行するには、ML クラスターのすべての P3dn インスタンスが同じアベイラビリティーゾーン、サブネット、および配置グループにある必要があります。
- 現在インストールされている EFA インストーラーのバージョンを確認するには、次のコードを入力します。
- インスタンスが EFA デバイスにアクセスできることを確認するには、次のコードを入力します。
ib_uverbs ドライバーがインスタンスでアンロードされるため、EFA デバイスが見つからない場合があります。これを確認して EFA デバイスの検索を再試行するには、次のコードを参照してください。
- パスワードなしの SSH をセットアップします。アプリケーションをクラスター内のすべてのインスタンスで実行できるようにするには、マスターノードからメンバーノードへのパスワードなしの SSH アクセスを有効にする必要があります。マスターノードは、アプリケーションを実行するインスタンスです。パスワードなしの SSH を設定したら、SSH のパスワード認証を無効にします。SSH 設定ファイル
/etc/ssh/sshd_configを開き、次のディレクティブを検索して、以下のように変更します。完了したら、ファイルを保存して SSH サービスを再起動します。Ubuntu または Debian サーバーで、次のコマンドを実行します。
- FSx for Lustre をセットアップします。Ubuntu 18.04 には、サポートするパッチを含む特定の 2.10 Luster ブランチが必要です。
- Ubuntu18 向けに FSx for Luster クライアントをインストールするには、次のコードを入力します。
- FSx for Lustre ファイルシステムをマウントするには、次のコードを入力します。
- BERT トレーニングデータを Luster ファイルシステムにアップロードします。EC2 インスタンスで BERT トレーニングデータを生成する手順については、GitHub のデータの取得をご覧ください。
- Luster ファイルシステムのトレーニング出力ログファイルディレクトリを設定します。
- Luster ファイルシステムのチェックポイントディレクトリを設定します。
- Install FairSEQ.Fairseq(-py) は、翻訳、要約、言語モデリング、およびその他のテキスト生成タスクのカスタムモデルをトレーニングできるシーケンスモデリングツールキットです。Fairsq インストールの前提条件は、Ubuntu18 DLAMI で設定されています。次のコードを参照してください。
ソースから fairseq をインストールしてローカルで開発するには、次のコードを入力します。
- コンソールからこの P3dn インスタンスのイメージを作成し、AMI ID を記録します。
- BERT トレーニング用のマスターノード (c5n インスタンス) を起動します。
- BERT training AMI を使用して、8 ノードの P3dn.24xlarge インスタンスクラスターを起動します。すべての P3dn インスタンスは、同じアベイラビリティーゾーン、サブネット、および配置クラスターグループにある必要があります。
- すべての P3dn インスタンスで EFA が有効になっていることをテストします。
- AWS ParallelCluster をインストールして設定します。この記事では、AWS ParallelCluster バージョン 2.6.0 を使用しています。詳細については、GitHub リポジトリをご覧ください。AWS ParrallelCluster を起動する主な手順は次のとおりです。
- 次のコードで AWS ParallelCluster をインストールします。
- 次のコードで AWS ParallelCluster を設定します。
GitHub から設定ファイルテンプレートをダウンロードします。このユースケースでは Slurm Scheduler を選択できます。
- 次のコードで HPC クラスターを起動します。
AWS ParallelCluster を初めて使用する場合は、手順 1〜10 に従って、クラスターがマルチノードの深層学習トレーニングジョブを起動するための正しい設定になっていることを確認します。マルチノードトレーニングが正常に完了したら、AWS ParallelCluster の使用を開始して、HPC クラスターの自動化とデプロイを高速化できます。AWS ParallelCluster を使用している間は、これらの手順を手動で実行する必要はありません。設定は AWS ParallelCluster 設定ファイルの一部だからです。ソフトウェアスタックを標準化して、一貫したパフォーマンスを得られるようにするために、BERT training AMI を作成することをお勧めします。
BERT トレーニングを実行する
BERT と PyTorch ライブラリを使用してモデルをすばやく効率的にトレーニングし、AWS HPC インフラストラクチャの文章翻訳で最先端のパフォーマンスを得ることができます。Fairseq は、モデルのトレーニングと評価のために複数のコマンドラインツールを提供します。この記事では、fairseq-train ツールを使用して、1 つまたは複数の GPU と roberta_large アーキテクチャで新しいモデルをトレーニングします。RoBERTa は BERT の事前トレーニング手順を反復し、次のアクションを実行します。
- モデルをより長く、より多くのデータでより大きなバッチでトレーニング
- 次の文の予測目的を削除
- より長いシーケンスのトレーニング
- トレーニングデータに適用されるマスキングパターンを動的に変更する
BERT トレーニングのセットアップが完了したら、すべての GPU インスタンスでトレーニングジョブを実行するマスターノードから BERT トレーニングスクリプトを起動します。トレーニングプロセス中に BERT クラスター内の各 GPU のパフォーマンスを確認するには、nvidia-smi コマンドを実行します。この記事では、次のトレーニングスクリプトを使用して、NLP での転移学習の実用的なアプリケーションを説明し、さまざまな NLP タスクに最小限の労力で高性能モデルを作成します。
BERT トレーニング結果は、FSx for Luster ファイルシステムの BERT トレーニングログにキャプチャされます。GPU の数が増えると、トレーニングパフォーマンスは直線的に向上します。同じデータセットを使用して、トレーニング中の GPU 数の増加に伴い、1 秒あたりの単語数 (wps) は直線的に増加しました。
クリーンアップ
追加料金が発生しないようにするには、トレーニングの完了後にマスターノード、ワーカーノード、FSX クラスターをシャットダウンします。Amazon S3 に保存されているすべてのモデルアーティファクトを削除します。
まとめ
深層学習トレーニング用に ML インフラストラクチャを設定することはかなりの労力を要する可能性があり、多くの場合、環境のセットアップはインフラストラクチャチームに依存する必要があります。それにより生産的な時間を失うことになります。また、深層学習テクニカルライブラリとパッケージは急速に変化しており、これらすべてのパッケージの相互運用性をテストする必要があります。Ubuntu18 DLAMI を使用すると、インフラストラクチャのセットアップやソフトウェアのインストールについて心配する必要はありません。この DLAMI には、すべての主要な ML フレームワークに必要な深層学習ライブラリとパッケージがあらかじめ組み込まれているため、モデルのトレーニング、チューニング、および推論に集中できます。
著者について
 Purna Sanyal は、AWS ストラテジックアカウントのシニアソリューションアーキテクトです。彼は、お客様に技術的ソートリーダーシップ、アーキテクチャガイダンス、および POC を提供し、お客様の戦略的ニーズおよびより多くの AWS のサービスの採用の両方を満たしています。彼の主な重点分野は、クラウド移行、HPC、分析、機械学習です。
Purna Sanyal は、AWS ストラテジックアカウントのシニアソリューションアーキテクトです。彼は、お客様に技術的ソートリーダーシップ、アーキテクチャガイダンス、および POC を提供し、お客様の戦略的ニーズおよびより多くの AWS のサービスの採用の両方を満たしています。彼の主な重点分野は、クラウド移行、HPC、分析、機械学習です。