Amazon Web Services ブログ
【寄稿】オンプレミス環境のバッチジョブフローのAWS移行方法検討事例
この投稿はアクセンチュア株式会社 Technology グループ所属のエンジニア 金 敬源 氏、 マネージャー 竹内 誠一 氏に、AWS Step Functions、Amazon EventBridge および AWS Lambda を活用したプロトタイピングについて寄稿いただいたものです。
はじめに
このブログは、あるクライアントのクラウド移行検討において、バッチ移行の課題解決方法を検討・検証した経験を紹介します。取り組みの全体像は別ブログ「オンプレミス環境の基幹系JavaバッチジョブのAWS移⾏検討の一事例」でご紹介しています。
バッチのクラウドへの移行は、フェーズ1としてクラウドに移行しやすいアプリから移行に着手し、フェーズ2として最終的にすべてをクラウドに移行するという段階的な移行を想定しています。
フェーズ1はオンプレミス環境にあるジョブスケジューラ(ジョブ管理システム)を残しながら部分的にクラウドへ移行する方法を主題に検討しました。このフェーズでは既存のジョブスケジューラでクラウド上のバッチを制御する仕組みが必要となります。またフェーズ2ではオンプレミス環境に依存することなくクラウド上でバッチを実行するためのジョブスケジューラを検討しました。AWSの既存サービスだけではこのフェーズの要件を満たすことはできなかったので、複数のサービスを組みわせたカスタムジョブスケジューラを考案しました。
私たちのチームでは、それぞれのフェーズのジョブスケジューラのプロトタイプを作成し期待どおりの動作を確認しました。その内容を本ブログにてご紹介します。
【フェーズ1】オンプレミス環境にジョブ管理システムを残しバッチジョブを一部AWSへ移行する
バッチをクラウドに移行する過程では、バッチジョブフローがクラウドに移行したバッチジョブとオンプレミス環境に残っているバッチジョブにまたがってスケジュールされることになりますし、最終的に一部のバッチがオンプレミス環境に残るのであれば、この形態がクラウド移行の最終形になります。
クラウド移行後も既存のジョブスケジューラを引き続き使用しながら、オンプレミス環境とクラウドにまたがるバッチジョブフロー全体を制御する方法を検討いたしました。
既存のジョブスケジューラには複数のアプリにまたがるバッチジョブフローがあり、段階的にクラウドに移行する過程ではバッチジョブフローはオンプレミス環境とクラウドにまたがることになるので、既存のジョブスケジューラでオンプレミス環境とクラウドにまたがるバッチジョブフローを制御することが必要です。
前提として、オンプレミス環境のバッチジョブはシェルスクリプトで実装されており、これが AWS Step Functions のステートマシンに移行されるものとします。またジョブスケジューラ自体は改変しないものとします。
オンプレミス環境とクラウドにまたがるバッチジョブフロー全体を制御するための仕組みの概要
既存のジョブスケジューラがスケジュールできるのはオンプレミス環境のバッチジョブ(シェルスクリプト)ですが、オンプレミス環境のバッチジョブを介してクラウドのバッチジョブ(ステートマシン)を制御できれば、既存のジョブスケジューラでオンプレミス環境とクラウドにまたがるバッチジョブフローを制御できます。

上図に概念を示しましたが、オンプレミス環境でシェルスクリプトが起動すると直ちにステートマシンを起動し、ステートマシンが終了したらオンプレミス環境のシェルスクリプトが終了する仕組みがあれば、既存のジョブスケジューラにステートマシンを組み込みできます。
シェルスクリプトがステートマシンの終了を検知する方法としては、2つのパターンが考えられます。
- オンプレミス環境のシェルスクリプトがクラウドのステートマシンを起動した後、能動的にステートマシンの状態を監視する(ポーリング方式)
- オンプレミス環境のシェルスクリプトがクラウドのステートマシンを起動した後、クラウド側からステートマシン完了の通知が届くのを待ち受ける(コールバック方式)
実装方法はいくつも考えられますが、それぞれのパターンについて今回プロトタイプを作成して検証した方法を1つずつ紹介します。
ステートマシンの状態をシェルスクリプトから定期的に問い合わせる(ポーリングする)
概要

まず、AWS Step Functions の起動とステータス取得するために Amazon API Gateway で Step Functions を呼び出すAPIを公開します。
オンプレミス環境のシェルスクリプトは、起動すると速やかに AWS Step Functions を呼び出すAPIを通してステートマシンを起動し、その後シェルスクリプトは定期的に AWS Step Functions を呼び出すAPIに問い合わせしてステートマシンの実行ステータスを確認します。シェルスクリプトはステートマシンの終了を確認すると終了し、シェルスクリプトの終了はエージェントを通してジョブスケジューラに通知されます。

この方法を実装するための重要なポイントはシェルスクリプトから「AWS Step Functions API」をコールする仕組みです。シェルスクリプトから AWS Step Functions を操作する手段には一般には CLI、SDKと Amazon API Gateway を経由したAPI呼び出しの3つが考えられますが、シェルスクリプトを開発・維持する観点でみると、CLIはアクセスキーの管理が必要、SDKはプログラミングが必要といった点で難易度が高く、 Amazon API Gateway を経由したAPI呼び出しが最も手軽かつ機能的にも十分と判断しました。ちなみにステートマシンを起動する Amazon API Gateway を経由したAPI呼び出しはコールバックのパターンでも利用します。検証ではオンプレミス環境の代わりにEC2でシェルスクリプトを実行しました。
AWS Step Functions の起動、ステータス確認するAPIを Amazon API Gateway で実装し、AWS Step Functionsのステートマシンを起動・ステータス確認するためのAPIを作成します。
「API Gatewayを使用したAWS Step Functions APIの作成」を参考にしました。
POSTメソッド使って StartExecution、DescribeExecution を作成します。
シェルスクリプトを作成
このシェルスクリプトでは、AWS Step Functions API を利用してステートマシンを起動し、ポーリングすることでステータス確認します。起動・監視対象のステートマシンは、ARNを使って識別しています。
1.変数を設定
3.ステートマシンのステータスを取得するAPIを定期的に呼び出し
定期的に「DescribeExectution」APIを呼び出してステートマシンのステータスを取得、終了検知を行います。
結果
シェルスクリプト実行時の応答メッセージの例を以下に示します。 「execution_data」で始まる行が、ステートマシンを起動するstartExecution API への応答で、その後の「get STATUS:」で始まる行がステートマシンの実行状況を照会する describeExecution API への応答です。定期的にAPIからステートマシンのステータスを取得し、ステートマシンの終了検知後シェルスクリプトが終了しています。
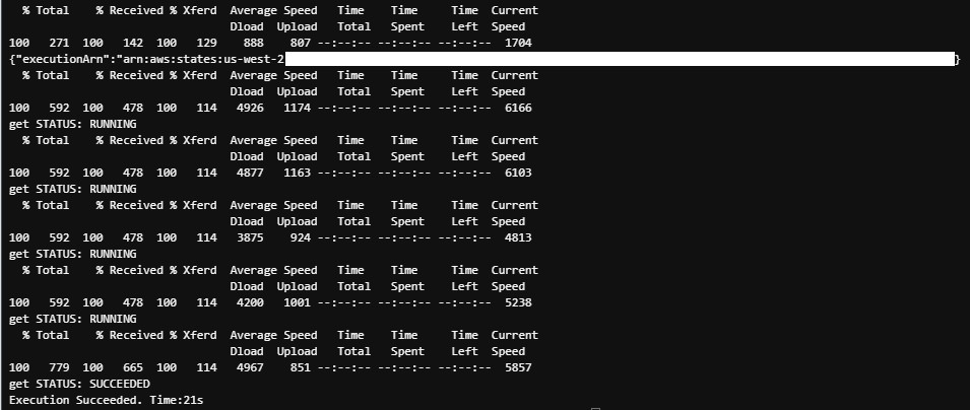
ステートマシン終了イベントをオンプレミス環境のシェルスクリプトにコールバックする
概要

オンプレミス環境のシェルスクリプトを起動すると直ちに AWS Step Functions のAPIを通してステートマシンを起動する点は一つ目と同じです。その後シェルスクリプトでWebhook(コールバック受信)用のWebサーバを立ち上げておき、ステートマシンには終了直前にこのWebサーバをコールバックさせます。Webサーバはコールバックを受信して終了し、それに伴ってシェルスクリプトも終了するようにします。1つ目のパターンと同様に、シェルスクリプトの終了はジョブスケジューラに通知されます。
1つ目との違いは、 AWS Step Functions のステータス取得用APIへ定期的に問い合わせを行う代わりに、オンプレミス環境のシェルスクリプトでWebhook(コールバック受信)用のWebサーバを立ち上げておく点です。ステートマシンに終了時にこのWebサーバをコールバックさせることで、シェルスクリプトはステートマシンの終了を検知することができます。

この方法を実装するための重要なポイントはステートマシン終了時にシェルスクリプトにコールバックする仕組みと、そのコールバックをシェルスクリプト側で受け取るための仕組み(Webhook)です。
コールバックの仕組みは、AWS Step Functionsの個々のバッチジョブの開発チームと終了通知のインフラチームの範疇を分離するためAWS Step Functions に組み込まず、Amazon EventBridge を介してLambdaを呼び出してコールバックする構成にしています。
また、Amazon EventBridge のAPI Destinationの機能で直接コールバックする方法も考えられますが、バッチ処理の仕組みは閉域網内に閉じておきたいので、API Destinationは使わず、VPC内のLambdaを呼び出しています。
コールバックを受け取る仕組みは、シェルスクリプト内でWebサーバを起動し、コールバックのHTTPSリクエストを受け取ったらWebサーバが直ちに終了するようにします。
この構成は簡単なのですが実装は少し複雑になります。このブログでは実装方法は割愛しますが、参考のため考慮すべき点について触れておきます。一般にWebサーバはHTTPSリクエストを受け取って応答を返した後次のリクエストを待機するので、HTTPSリクエストをきっかけとして終了することはありません。HTTPSリクエストの処理中にサーバを終了させることは簡単なのですが、コールバックをリクエストした側は応答を受け取る前にサーバとの通信が切断することになり、コールバックが成功したかどうかわからなくなってしまいます。HTTPSリクエストへの応答を返した後にWebサーバを終了させるためには利用するWebサーバに応じた対応が必要です。
Webhookに返すLambda関数を作成
Amazon EventBridgeで検知したAWS Step FunctionsのステータスパラメータをWebhookに送信します。
「WEBHOOK_URL」はシェルスクリプト内で起動させているWebサーバのURLとなります。
Amazon EventBridgeのルールを作成
1.Amazon EventBridgeのイベントパターンを作成
ステートマシンのステータスの変更を検知します。
2.ターゲットのLambda関数を設定
AWS Step Functionsのステータスの変更が検知されたら、「Webhookに返すLambda関数を作成」で
作成したLambda関数を呼び出すようにターゲット設定します。
結果
シェルスクリプト実行時の応答メッセージの例を以下に示します。“executionArn”で始まる行がステートマシンを起動するstartExecution APIへの応答です。「10.1.2.255」から始まる行でコールバックリクエストを取得しており、このリクエストにHTTP 200を応答してからシェルスクリプトが終了しています。

【フェーズ2】AWSサービスでカスタムジョブスケジューラを構築する
クラウド・コンピューティングにおいては、ワークロードをサービスとして実装し、APIを通してサービスを呼び出すスタイル(サービス指向)が主流です。複数のサービスを決められた順序で実行するためのクラウド・サービスもあります。AWSでは AWS Step Functions が相当します。
しかし、今回移行を検討したバッチは AWS Step Functions だけでは制御しきれないほどの複雑なフローを持っていました。詳細は別のブログ「オンプレミス環境の基幹系JavaバッチジョブのAWS移⾏検討の一事例」で説明したのでここでは割愛します。
そこで、AWS Step Functions のステートマシンを個々のバッチジョブの置き換え先としては使いますが、ステートマシンを連結してバッチジョブフローとして制御する仕組みは別途開発が必要と考えました。この仕組みをカスタムジョブスケジューラと呼ぶことにします。
カスタムジョブスケジューラ概要
カスタムジョブスケジューラは、基本的にAWSのマネージド・サービスの組み合わせでプロトタイピングすることにしました。カスタムロジックの作りこみも併用しますが、実行環境はサーバーレスのLambda関数としました。プロトタイプのアーキテクチャー概要を下図に示します。
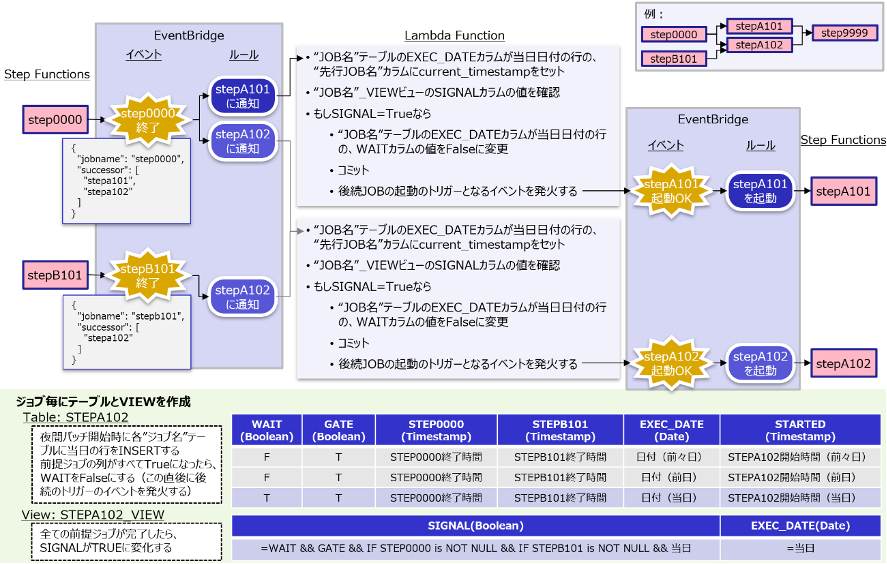
AWS Step Functions ステートマシンをバッチジョブとしてスケジュールする仕組みを考える上で、ステートマシンとステートマシンを連結する仕組みが最も重要な要素となります。連結の仕組みとしてはステートマシンから次のステートマシンを直接呼び出す方法も考えられますが、今回のプロトタイプでは、Amazon EventBridge のEventBridgeルールが一旦カスタムジョブスケジューラを呼び出し、カスタムジョブスケジューラが先行・後続の条件をチェックして後続のステートマシンを適宜呼び出す仕組みを考えることにしました。このような仕組みにした理由は別のブログ「オンプレミス環境の基幹系JavaバッチジョブのAWS移⾏検討の一事例」で説明しています。
バッチジョブフローの進行状況を保存する仕組み
カスタムジョブスケジューラはステートマシンが終了したら、その終了イベントをトリガーとしてAmazon EventBridgeルールによって呼び出されるように構成します。カスタムジョブスケジューラの役割は次のように定義しました
- 後続ジョブに、先行ジョブが終了したことを知らせる
- すべての先行ジョブが終了していたら、後続ジョブを起動する
- 後続ジョブが起動不可のフラグを立てていたら、すべての先行ジョブが終了していても起動しない
これらの役割のために、カスタムジョブスケジューラには個々のジョブの開始・終了を記憶しなければなりません。この記憶場所はRDB(具体的には Amazon Aurora for PostgreSQL)で実現することにしました。
RDBにはテーブルとViewを、ジョブ一つにつき一つずつ作成することにします。以下に例として、ジョブ名が stepa101 で step0000 という先行ジョブを持っている場合のテーブルとViewの定義を示します。
作成されたテーブルとViewを表示した例も以下に示します。
テーブル:stepa101
| wait | gate | step0000 | exec_date | started |
| t | t | – | 2021-9-29 | – |
View:stepa101_view
| signal | exec_date |
| f | 2021-9-29 |
テーブルの先行ジョブ名の列(上の例ではstep0000)には、先行ジョブの完了時刻を記録します。
Viewは、すべての先行ジョブが終了したかどうかを表示する列(signal)を持ちます。この列には次の式を持たせており、先行ジョブが未実行(テーブルの先行ジョブの列が空白)の場合はFALSEとなって、ジョブ実行条件が満たされていないことを表します。
式に含まれているwait列は、初期値TRUEを持ち、カスタムジョブスケジューラがジョブを起動した際にFALSEに更新します。これはジョブを誤って二重サブミットすることを防ぐ狙いですgate列も初期値TRUEを持ちますが、こちらはユーザーが必要に応じて手動でFALSEに更新します。スケジュール済のバッチジョブを何らかの事情で起動したくないケースで使用することを想定しています。
ジョブの実行状況に応じて後続ジョブを起動する仕組み
次に必要になるのはこのテーブルを更新しながら、条件が揃ったときに後続ジョブを起動する仕組みです。この仕組みはEventBridgeルールによって呼び出されるLambda関数で実装することにします。処理の流れは次のとおりです。
- ステートマシンが終了時に生成するイベントに、自身のジョブ名と後続ジョブ名のリストを含めておきます
- EventBridgeルールにより、Lambda関数を呼び出してイベントを渡します
- Lambda関数は後続ジョブ名のテーブルの、自身のジョブ名の列に現在時刻を記録します
- 後続ジョブ名のViewの、すべての先行ジョブの終了を表示する列(signal列)をチェックし、TRUEの場合は後続ジョブ名を含むカスタムイベントを生成します
- 後続ジョブの数だけ3,4を繰り返します
ステートマシン終了時に生成するイベントは、ステートマシンのPassステートに指定できます。以下は自身のジョブ名が step0000、後続ジョブが stepa101、stepa102 の場合の例です。
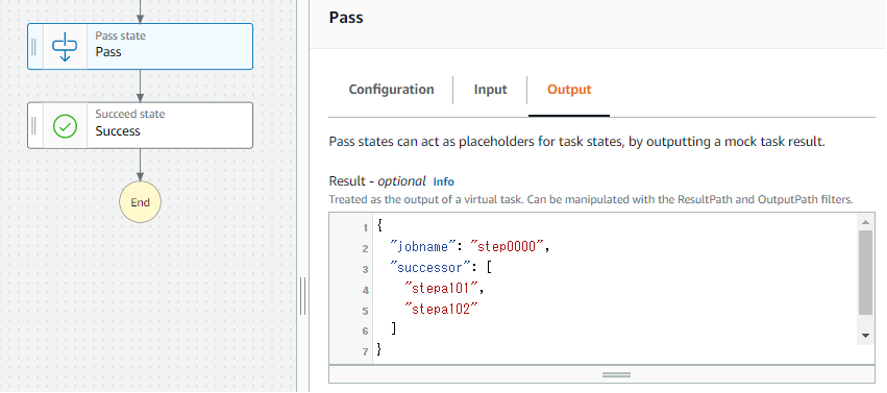
後続ジョブの起動のトリガーとなるカスタムイベントの生成は、Lambda関数の以下のコードで実行しています。ここではステートマシンから渡ってきた後続ジョブ名をイベントパターンのsourceにセットしています。このsourceの値(つまり後続ジョブ名)に関連づけられたカスタムルールが、ターゲットとして関連づけられたステートマシンを呼び出します。
カスタムルールは次のように定義して、後続ジョブ名を含むイベントパターンと後続ジョブとなるステートマシンを関連付けます。

この方式は、ジョブと1対1で機械的・定型的にカスタムルールを作ればいいので、シンプルでわかりやすいという利点があります。一方でジョブの数だけカスタムルールが必要になるという難点があり、大規模なバッチジョブネットワークではイベントバスあたり最大300ルールというQuotaに抵触するかもしれません。回避策としてはサポートチケットでルール数のQuotaを緩和してもらう、複数のイベントバスを使う(ただしアカウントあたり最大100イベントバスというQuotaが別途あります)等が考えられます。
ここまで簡単に仕組みをご紹介してきましたが、個々のステートマシンの終了イベント、これらのイベントによって起動される唯一のLambda関数、ジョブの数だけ作られるテーブルとView、ジョブの数だけ定義する Amazon EventBridge カスタムルールの組み合わせで、シンプルながらスケーラブルな仕組みが実装できることをご理解いただけたと思います。プロトタイピングではアーキテクチャー概要図に示したごく小規模のバッチジョブネットワークで動作を実証しましたが、理論的には数千、数万ジョブ規模の大規模なバッチジョブネットワークにも対応できると考えています。
今後の課題
今後の課題として、今回のプロトタイプではスコープ外とした点にも触れておきます。
1. バッチジョブの進捗状況のリアルタイムな可視性
可視化の仕組みとしては、先行―後続の関係のあるジョブ(ノード)を線で結んだネットワーク図を描画し、そのネットワーク図が進捗に応じてリアルタイムに変化していくようなダッシュボードがあると便利です。
個々のテーブルにはジョブの開始時刻や先行ジョブの完了時刻をリアルタイムに記録しているので、これらを照会することによりバッチジョブの進捗状況はリアルタイムで把握することが可能です。ネットワーク図を自動描画するツールがあれば、ジョブ名、ジョブ間の前後関係、ジョブの開始・終了時刻をマッピングして、ダッシュボードとして使うことができそうです。
2. イベント配信がベストエフォートであることの補完
AWS Step FunctionsからAmazon EventBridgeへのイベント配信のQoSはベストエフォートとされており、「ベストエフォート配信の場合、すべてのイベントをAmazon EventBridgeに送信しようとしますが、まれにイベントが配信されない場合があります。」とドキュメントに記述されています。
したがって、バッチジョブの確実な実行のためには、万一イベントが配信されなかった場合の対策をあらかじめ立てておく必要があります。例えば上記のダッシュボードを常時監視する運用が考えられます。常時監視すると言ってもダッシュボード画面に人が張り付くのは非効率なので、自動通知の仕組みを追加することになります。
バッチの遅延や失敗はイベントの未到達以外の要因でも起こり得るので、仮にイベント配信が保証されていたとしても、バッチジョブの進行状況を監視する仕組みは必須と考えます。その仕組みの下でイベント未到達のケースも含めてエラー検知とリカバリー方法を準備しておけば安心です。
3. 複雑な実行日ルールによるスケジュール
今回のプロトタイプでは、DEMO用と割り切って、実行日の取得には暫定的にSQLのCURRENT_TIMESTAMPを利用しました。この方法では深夜0時を過ぎるとバッチジョブの実行予定日と実際の実行日がずれるので実用的ではありません。本来は、日替わり処理をするまでは深夜0時を過ぎても日付が変わらない仕組みが必要です。アイデアとしては、SQLのユーザー定義関数で日付取得処理を実装してCURRENT_TIMESTAMPの代わりに使う方法が考えられますし、Amazon AuroraならLambda関数で日付取得処理を実装することも可能です。
日によって後続ジョブを実行したりしなかったりするケースは、この仕組みではステートマシンが生成するイベントのメッセージに含まれる後続ジョブ名を日によって変える必要があります。アイデアとしては、ステートマシンの中でLambda関数を呼び出し、カレンダー等にもとづいて後続ジョブ名を動的に取得してイベントのメッセージにセットする仕組みで対応できそうです。
おわりに
本ブログは、オンプレミス環境のバッチジョブフローを段階的にAWSに移行するために必要となるジョブスケジューラのアイデアを、プロトタイプを作成して検証した結果も交えながら紹介しました。
オンプレミス環境からAWSへのバッチ移行が始まった段階(フェーズ1)では、オンプレミス環境の比重がまだ大きいので、オンプレミス環境のジョブスケジューラをベースとした仕組みとし、移行の難易度やリスクの軽減を図りました。具体的には、オンプレミス環境のジョブスケジューラに従来どおりシェルスクリプトを起動・監視させ、シェルスクリプトを介してAWS上のバッチジョブフローを制御する仕組みとしました。
次の段階(フェーズ2)ではオンプレミス環境のジョブスケジューラへの依存から脱却し、AWS Step Functions と Amazon EventBridge の組み合わせで複雑なバッチジョブフローを制御するカスタムジョブスケジューラを目指しました。
今回のプロトタイピングでは小規模なバッチジョブフローが正しく実行できることの検証にとどまりましたが、複数の先行ジョブ・後続ジョブ等、従来のバッチジョブフローが持つ複雑な特徴に適合できることは確認できました。AWS Step Functions と Amazon EventBridge の利点を活かせば、更にAWS内外の様々なクラウドサービスともオンプレミス環境のバッチジョブとも連携できる、より柔軟でスケーラブルな仕組みに発展させることも可能です。
本ブログで紹介したバッチジョブフロー制御の仕組みが、バッチのクラウド移行の課題解決の参考になれば幸いです。
著者について
 |
金 敬源(KIM KOUNGWON) アクセンチュア株式会社
|
 |
竹内 誠一 アクセンチュア株式会社
|