Amazon Web Services ブログ

週刊生成AI with AWS – 2026/3/9 週
今回の週刊生成AI with AWSでは、三菱電機が AWS 上で開発した AI 商談支援サービス「Memory Tech」やサミットが Kiro で PoC を 12 時間で実現した事例など、生成 AI を実際のビジネスで活用するお客様事例に加え、Amazon Bedrock AgentCore Memory のストリーミング通知、Amazon Bedrock の新しいオブザーバビリティメトリクス、Kiro のエンタープライズガバナンス機能といったサービスアップデートも充実した一週間でした。製造業での Agentic AI 活用特集やフィジカル AI 開発支援プログラムのキックオフレポートなど、業界を問わず生成 AI の実践的な活用のヒントが詰まっていますので、ぜひブログ本編でチェックしてみてください。

Amazon Connect アップデート まとめ – 2026年2月
みなさん、こんにちは。Amazon Connect ソリューションアーキテクトの坂田です。 2026年2月に発 […]

Amazon S3 汎用バケットのアカウントリージョナル名前空間の紹介
2026 年 3 月 12 日、Amazon Simple Storage Service (Amazon S […]

AWS 上の Microsoft および VMware ワークロード: AWS re:Invent 2025 完全プレイリスト
AWS re:Invent 2025 の Microsoft および VMware ワークロード移行に関するセッションプレイリストを紹介します。AWS Transform によるエージェンティック AI での自動化、Amazon EVS でのネイティブ VMware 実行、CSL や Thomson Reuters などの顧客成功事例を含みます。

週刊AWS – 2026/3/9週
Amazon Route 53 Global Resolver が一般提供開始、Amazon Bedrock が First Token Latency と Quota Consumption の可観測性をサポート、Amazon Bedrock AgentCore Runtime がステートフル MCP サーバー機能をサポート開始、Amazon S3 が汎用バケット向けアカウントリージョナル名前空間を導入、Amazon EC2 Hpc8a / R8a インスタンスがアジアパシフィック (東京) で利用可能に、新しい SAM Kiro power でサーバーレスアプリケーション開発を加速

ブロックレベルレプリケーションを使用した Amazon RDS for SQL Server Web Edition の高可用性実装
この投稿では、SQL Server Web Edition の マルチ AZ RDS インスタンスをセットアップし、フェイルオーバーテストを通じてその高可用性機能を検証する方法を紹介します。

【寄稿】「12時間で PoC が完成」― サミット株式会社の情報システム部門が AI コーディングアシスタント Kiro で実現した、圧倒的スピードの内製開発
こんにちは。AWS シニアソリューションアーキテクトの崔 祐碩です。首都圏を中心に 125 店舗のスーパーマー […]

AWS CloudShell で RDS / Aurora のリザーブドインスタンスを一括購入するサンプルスクリプト
Amazon Relational Database Service(以下、RDS)や Amazon Auro […]
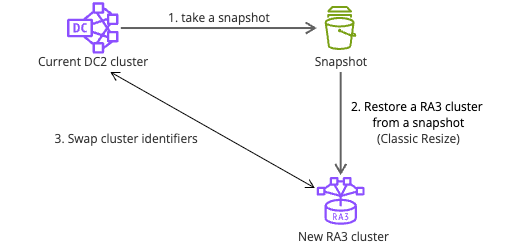
Amazon Redshift DC2 インスタンスからの移行アプローチ:お客様事例
本記事では、小売業の大手企業が Amazon Redshift DC2 から RA3 インスタンスへ移行した事例を紹介します。Blue-Green デプロイメントアプローチで安全に移行し、ETL クエリパフォーマンスの向上とストレージ容量の拡大を実現しました。マテリアライズドビューや AutoMV などの RA3 固有の機能を活用し、コスト効率を維持しながら全体的なクエリパフォーマンスを最適化した方法を解説します。

AWS Weekly Roundup: Amazon Connect Health、Bedrock AgentCore ポリシー、GameDay Europe など (2026 年 3 月 9 日)
Fiti (スワヒリ語のスラングで「最高」) AWS Student Community Kenya! 202 […]