Amazon Web Services ブログ
Amazon Personalize を使用して StockX でパーソナライズされたユーザーエクスペリエンスを先駆けて提供
この記事は、StockX 社の Sam Bean 氏と Nick Roberts II 氏によるゲスト投稿です。彼らの言葉を借りると、「StockX はユニークなビッド/アスク市場で e コマースに革命を起こしているデトロイトのスタートアップ企業です。当社のプラットフォームはニューヨーク証券取引所をモデル化し、スニーカーやストリートウェアなどの製品を高価値の取引可能な製品として扱っています。StockX は、透明なマーケットエクスペリエンスにより、真の市場価格で信頼性の高い、人気の高い製品を手に入れられるようにしています」。
2019 年に StockX が急成長している間に、機械学習 (ML) エンジニアの小さなグループが Amazon Personalize を使用してホームページに Recommended For You 製品行を追加しました。これが最終的にトップパフォーマンスを発揮するホームページ行になりました。この記事では、カスタマイズされたユーザーエクスペリエンスを提供するために Amazon Personalize とこれまでどのように取り組んできたかをご紹介します。
当社の市場のダイナミクスから、パーソナライズされたユーザーエクスペリエンスを提供する必要があります。サイトへのトラフィックの急上昇は、主にドロップによって引き起こされます。スニーカーやストリートウェア市場では、ドロップは人気の高い限定版アイテムを事前に伝達してリリースすることを指します。顧客の製品に対する関心の多様性は急拡大していますが、ユーザーはまだまだ最新リリースから特定の人気商品を検索することがよくあります。その結果、頻繁に大規模な DDoS のようなトラフィックがプラットフォームに流入することになり、バックエンドのスケーラビリティが最優先事項になります。さらに、当社のチームは、ブラックフライデーの直前に、Recommend For You 製品行をリリースする予定でした。このような要因により、スケーリング、リアルタイムでの変更、顧客の変化に対応できる堅牢なレコメンデーションエンジンの必要性が高まりました。
当社の取り組みも 3 年が経過し、ユーザーエクスペリエンスのパーソナライゼーションを成長の中心的な目標として優先するようになりました。当社の顧客ベースは、スニーカーコレクターのみから着実に進化し、ますますカジュアルで好奇心の強いユーザーを抱えるようになりました。感謝祭の週末は、このような新しい顧客にパーソナライズされたエクスペリエンスを提供することにより、顧客維持を図る機会になりました。2019 年の年末が近づき、計画にさらなる制約が加わりましたが、Amazon Personalize により、季節性のトラフィックの急増に合わせて、拡大し続けるユーザーのために高度に精選された魅力的なエクスペリエンスを創造することができました。
初期段階
当社のチームは当初、プラットフォームのパーソナライゼーションのギャップを埋めるためにサードパーティベンダーを模索しました。ただし、既製のソリューションを購入するのは費用がかかり、他とは一線を画す当社の e コマース市場にとっては柔軟性に欠けていました。このような既製のソリューションは、多くの場合、ML プロセスのすべての側面について融通が利きませんでした。サードパーティが提供できるものよりも高い柔軟性が必要ではありましたが、この問題に完全に自前のソリューションが必要であるとまでは考えませんでした。
次に、階層型リカレントニューラルネットワーク (HRNN) である Amazon Personalize コアリコメンダーと同等のカスタムニューラルネットワークを構築することについて調査しました。当社のチームはモデルを構築する準備ができていましたが、堅牢性、スケーラビリティ、時間など、特定の交絡変数を考慮する必要がありました。当社は、質の高いサービスを構築して、顧客に説得力のある体験をしてもらい、休日のトラフィックの急増に追いつくために、時間と戦っていました。カスタムモデルの調整に必要な開発時間および推論パフォーマンスにまつわる不確実性により、ML マイクロサービスを構築するのに相応しい要件を挙げていく必要がありました。これにより、どの部分を構築し、どの部分を購入するかを特定できました。当社の要件は次のとおりです。
- データ収集 – パフォーマンスの高いレコメンダーを構築するための最初のステップは、サイトで適切なトラッキングが行われるようにすることです。アンケート、評価、設定などの顧客に関する明確な証拠があるとよいですが、生のクリックストリームからマイニングされた暗黙的な証拠は通常、より説得力のあるエクスペリエンスを生み出します。このクリックストリームデータの収集は、機能的なレコメンダーを作成するための最初のステップです。
- データの場所 – 適切な種類のデータを収集したら、次のステップは、このデータを格納する場所を見つけることです。当社の目的では、クリックストリームと製品カタログのデータを格納する場所を特定し、アクセスする必要がありました。
- データラングリングと機能エンジニアリング – すべてのデータソースとストレージの場所を発見したら、それらのどの部分が有用かを考えます。アルゴリズムを試してみるまで、アルゴリズムがデータのどこで信号を見つけるかを知ることは難しいため、これは経験的で時間のかかるプロセスです。
- モデル開発 – これは、開発ライフサイクルの中で最もデータサイエンスがものをいうステップです。ほとんどのチームは、ビジネス上の問題を解決するノートブックのプロトタイプから始めて、モデルトレーニング用のオブジェクト指向ソリューションに移ります。データの可用性により候補モデルのセットが制約されるため、このステップは前のステップと相互依存しています。
- モデルのテストと評価 – トレーニング済みのモデルが用意できたら、質的分析のための健全性チェックを手短に行い、トレーニングメトリクスを補足する必要があります。小さな視覚化アプリケーションを作成して、モデルが推奨するものの横に、ユーザーがやり取りしている製品を表示するのがお勧めです。これにより、さまざまなアルゴリズムとハイパーパラメータ設定のレコメンデーションを目視で調べて、経験的に比較することができました。
- ETL 開発 – データの顕著な特徴を特定したら、自動 ETL が必要です。これにより、生データを抽出して特徴エンジニアリングを実行し、そのデータを本番トレーニングルーチンで簡単にアクセスできる場所に配置できます。ETL の微妙なバグにより、トレーニングの最後に出力を視覚化するまで検出が困難なガベージイン、ガベージアウトの障害が発生する可能性があるため、この手順は最重要です。
- バックエンドサービスの開発 – モデル推論メカニズムをバックエンドサービスでラッピングすると、モニタリング、安定性、抽象化が向上します。これは、予想していた大量のトラフィックの流入を防ぐための隔壁として特に重要でした。Amazon Personalize の getRecommendations API をラッピングするために、AWS Lambda のサーバーレスソリューションを選択しました。
- 本番デプロイ – モデルの新しいバージョンをトレーニングしてデプロイする CI/CD などの自動化されたプロセスにより、レコメンデーションが継続的に顧客に関係するものであるようにします。このステップが必要な背景には、推奨事項が古くなり、エンゲージメントが低下することがあります。これで、ML マイクロサービスが完成しました。
自前のソリューションを構築しようとすると、8 つのステップすべてをゼロから開発する必要がありました。Amazon Personalize には自動化された機能エンジニアリングとモデル開発 (ステップ 3 と 4) が用意されています。これらのステップは間違いなく最も時間のかかるステップです。Amazon Personalize の標準 HRNN を使用することで、当社のユースケースに必要なのは、列が 5 つだけのシンプルなデータセットだけでした。これにより、Amazon 自体が使用する実証済みのモデルのトレーニングを開始できます。これら 2 つのステップを Amazon Personalize にオフロードすることで、堅牢な ETL、バックエンド、本番デプロイシステムの実装に集中できました。また、手順 5 で説明した視覚化に投資する時間も増えました。フルスタックを開発しなければならなかった場合にはこのような余裕はなかったかもしれません。ただし、これには犠牲が何も伴わなかったわけではありません。Amazon Personalize が提供するレバー以外でアルゴリズムを調整することはあきらめなければなりませんでした。
これは当然、当社のチーム内で議論に発展しました。高度なメンテナンスが必要になってもモデルを完全に制御できるようにしておく方がよいか、それともユーザーのために完全に調整できなくなっても AWS ソリューションを信頼して使うのがよいか? 当社は AWS の専門知識を信頼して、エンタープライズグレードの ML モデルを構築することにしました。当社のチームは、社内の深層学習推論エンジンのスケーリング特性に重大なリスクがあることを予見していました。負荷テストに投資しないと、大量のトラフィックのスケーリング特性を測定することは困難です。つまり、開発時間が長くなります。本番深層学習マイクロサービスは比較的新しいサービスで、このトピックに関する参考文献は豊富にあるわけではありません。そのことが問題をややこしくしました。
開発
レコメンダーのコアモデルの開発と本番推論のスケーリングを AWS に任せることを決定した後、Amazon Personalize での開発を開始しました。すると、完全にスケーラブルな ML パイプラインに統合するのがいとも簡単であることがすぐにわかりました。次の図は、ソリューションのアーキテクチャを示しています。
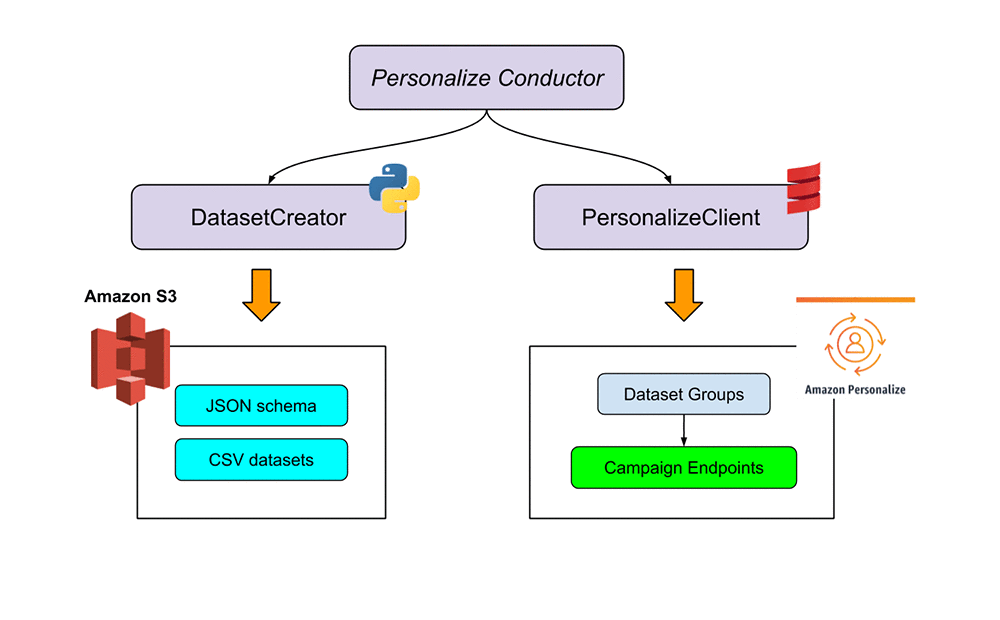
Amazon Personalize を、データセット作成と Amazon Personalize インフラストラクチャプロビジョニングに分割された 2 つのコードベースにプラグインしました。このコードベースは、Amazon Personalize を利用したリアルタイムレコメンデーションエンジンの作成、デプロイ、再トレーニングを完全に自動化します。
データセットを作成する
Amazon Personalize は、ユーザーの特性とレコメンデーションエンジンの利用法に基づき選ぶことができるさまざまなレシピを提供します。レシピには、モデルのトレーニング中にユーザー特性 (HRNN メタデータなど) を考慮する機能がありますが、他にも、個々の特性に依存せず、プラットフォームでの各ユーザーの相互作用のみを考慮するものもあります (HRNN)。選択するレシピによって、トレーニングデータセットの作成方法と、ソリューションをトレーニングするために Amazon Personalize に提供するデータセットの数が決まります。
最初に、3 つすべての HRNN バリエーション (プレーン、メタデータ、およびコールドスタート) をトレーニングおよびテストするためのインフラストラクチャを開発し、結果を比較しました。メタデータセットを追加した当初は、レコメンデーションに大きな改善は見られませんでした。また、HRNN-coldstart レシピは、追加の機能エンジニアリング開発を行わなければ、有機タイプのレコメンデーションを生成しないことを発見しました。メタデータセットの機能エンジニアリングにより多くの時間を費やすと、最終的にはパフォーマンスが向上すると思われますが、よりシンプルだけれども高品質のレコメンデーションを提供するソリューションで実行することにしました。Amazon Personalize の固有のユースケースそれぞれがにより最適なレシピを選択することにつながりました。そして HRNN が実装のシンプルさとレコメンデーション品質の理想的なバランスを実現することがわかりました。
Amazon Personalize の HRNN レシピを使用するには、任意の期間のユーザーインタラクションを含む 1 つのデータセットを提供する必要があります。このインタラクションデータセットには、コアレコメンデーションアルゴリズムに影響を与えるトレーニング機能が含まれ、定義されています。StockX のような e コマースプラットフォームの場合、関連するインタラクション機能には、製品ページビュー、検索結果のクリックや購入の完了に関連するアクションなどのメトリクスがあります。
インタラクションデータセットを作成するために、自動化された Python ETL パイプラインを作成して、クリックストリームデータソースと製品カタログをクエリし、インタラクションデータを処理して目的の機能を抽出し、Amazon Personalize の取り込み用にフォーマットされた CSV を作成しました。Amazon Personalize は、Amazon Simple Storage Service (Amazon S3) からのデータセットのインポートをネイティブでサポートしているため、この自動パイプラインの作成プロセスは簡単でした。おかげで、インタラクションに最適なレシピと最適なタイムスパンを選択する方法に焦点を当てることができました。
自動化された Amazon Personalize インフラストラクチャを作成する
次に、Amazon Personalize インフラストラクチャの作成プロセス全体を自動化しました。AWS マネジメントコンソールで排他的に Amazon Personalize サービスを手動で立ち上げることもできますが、AWS SDK for Java を使用すると、大規模なレコメンデーションサービスパイプラインで完全な自動化と再現性が実現できます。クライアントに Scala を選択して、以下を含む Amazon Personalize インフラストラクチャを作成しました。
- データセットグループ
- データセット
- ジョブのインポート
- ソリューション
- ソリューションのバージョン
- ライブキャンペーン
1 回限りのトレーニングの場合はコンソールでインフラストラクチャを構築することの方が簡単ですが、完全に自動化された反復可能なパイプラインでは、SDK を使用することが不可欠です。
デプロイの戦略化
最も重要なのは、当社の顧客の Scala が本番デプロイプロセスを調整することに責任を負い、レコメンダーモデルの再トレーニング中にダウンタイムが発生しないようにすることです。ユーザーがプラットフォームとの対話を続けるにつれて、モデルを再トレーニングして、このような新しい対話を組み込み、可能な限り最新のレコメンデーションを提供する必要があります。最新のインタラクションデータを使用してモデルを再トレーニングすることで、毎日トレーニングする場合に発生する長時間のサービス停止に対応できます。これは、この期間中はキャンペーンのエンドポイントが利用できなくなるため発生します。2 つの個別のライブキャンペーンエンドポイント (したがってソリューションバージョン) でこれを軽減することは可能ですが、コストがかかります。ライブトラフィックを提供しないキャンペーンであっても、AWS の超過料金が発生します。
このデプロイの課題を解決し、最も費用対効果の高いマイクロサービスを作成するために、中間の Lambda 関数を中心とした独自のデプロイ戦略を策定しました。この機能は、キャンペーンのエンドポイントに到達し、フロントエンドクライアントにレコメンデーションを提供する役割を果たします。特別なデータセットグループタグ (メイズ/ブルー) が Lambda 環境変数にパッケージ化され、どのキャンペーンエンドポイントが現在ライブで、本番トラフィックを提供しているかを示します。
Scala の顧客は毎晩、新しいトレーニングを開始し、ライブデータセットグループの本番用 Lambda 環境変数をチェックすることから始めます。顧客は新しいインタラクションデータセットをロードし、休止データセットグループを再構築します。その後、エンドポイントでハートビートチェックを実行して、確実に成功するようにします。次に、クライアントは Lambda 関数に、新しいエンドポイントを指すようにキャンペーン環境変数を更新するように指示します。その後、未使用の Amazon Personalize インフラストラクチャが解体されます。
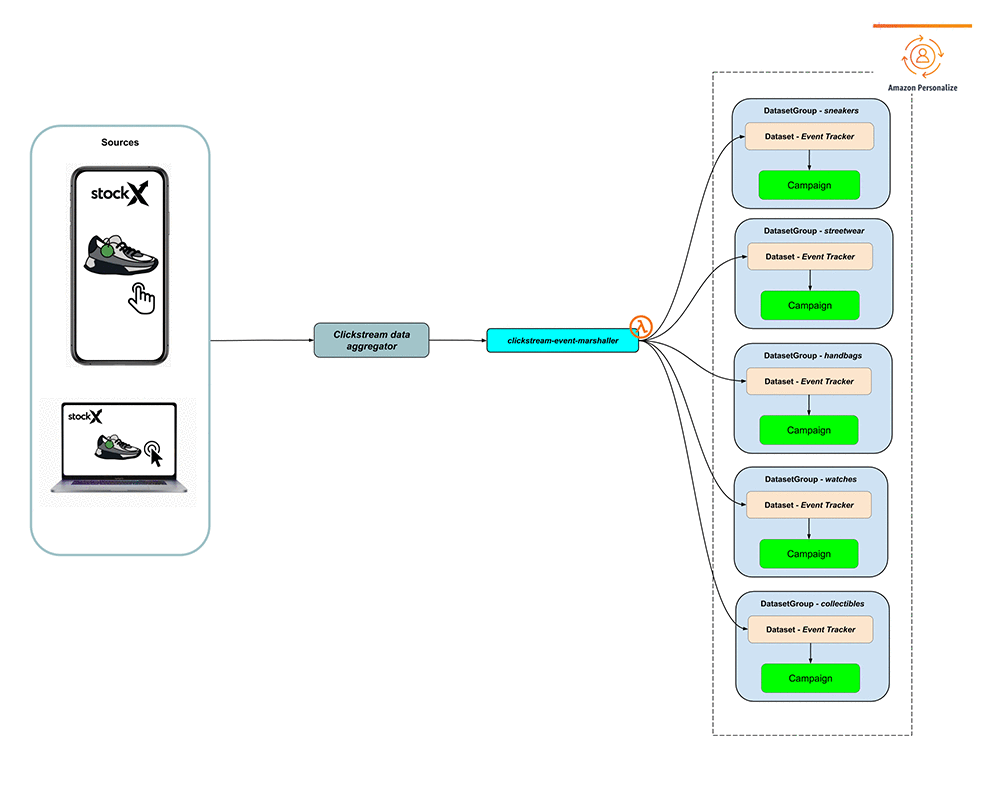
このように、マイクロサービスは、Amazon Personalize モデルを効果的に自動的に再トレーニングし、コストのかかる冗長性やサービスのダウンタイムなしでユーザーのレコメンデーションを毎日更新できます。さらに、Lambda 関数を使用すると、カスタムメトリクス追跡システムと、トレーニングの問題やキャンペーンのエンドポイントエラーを警告する障害モニタリングシステムが使えるようになります。Amazon Personalize を中心に作成されたこの堅牢なマイクロサービスデプロイ戦略により、StockX レコメンデーションエンジンは、会社の歴史の中で最も多忙な年末セールの期間中にほぼ完璧に利用することができました。次の図は、このアーキテクチャを示しています。

リアルタイム機能
トレーニングとデプロイのプロセスを体系化したところで、最後に解決しなければならない問題が 1 つありました。それは、トレーニングの実行間でユーザーの関心が変化したときにレコメンデーションをどう更新したらよいかという問題です。Amazon Personalize には、イベントインタラクションデータセットと呼ばれるシンプルなソリューションがあります。Amazon Personalize putEvents API を使用して、モデルにクリックストリームイベントを追加しました。クリックストリームソースは、イベントを Lambda 関数にリアルタイムでプッシュし、Amazon Personalize で予期される形式にマーシャリングします。このようなイベントはデータセットに追加され、レコメンデーションを数秒でシフトします。次の図は、このワークフローを示しています。
テストとデプロイ
当社のロールアウト計画は StockX の標準になりました。Recommended For You ホームページコレクションは、A/B テスト用に実装された機能フラグの背後にデプロイされました。これにより、チームは最初のカナリアテストとして機能をユーザーの 1% に安全にデプロイできました。最終的にテストを 60% のユーザーにまで拡大し、そのうち 30% は従来のエクスペリエンスを受け、30% はパーソナライズされたホームページのエクスペリエンスを享受し、残りの 40% はテストを受けませんでした。この機能を顧客ベースの大部分にダイヤルしても、エラー率やレイテンシーの増加は見られませんでした。テストは 2 週間かけて行われました。
[Recommended for You] はホームページ 2 行目にありましたが、一番上の [Most Popular] 行のクリック率を上回りました。Recommended For You コレクションは、パーセンテージで最もパフォーマンスの高い購入ファネルであり続けます。ホームページに対する顧客の全体的なエンゲージメントが 50% 増加しました。これは、ウェブページの一部をパーソナライズするだけでも、他の要素のクリックスルーを高めるのに十分効果的であることを証明しています。
パーソナライゼーションは C-Suite の戦略的目標であり続け、レコメンデーションエンジンがその最初の主要な成果となりました。戦術的な意思決定は、製品発見の経験を担当する当社の製品リードと連携して行いました。ユニコーン企業のスタートアップとして、当社はパーソナライゼーションが重要であると仮定しましたが、この A/B 実験はそれがいかに力強いものであるかを示しました。最初の結果が出始めた後、問題は、パーソナライズするかどうかではなく、StockX エクスペリエンスのあらゆる側面をどのようにパーソナライズしたらよいかという点にありました。ML チームは常に StockX で最もデータ駆動型のエンジニアリングチームの 1 つであり続けています。この実験は、テスト可能な KPI が測定可能な方法でエクスペリエンスを確実に改善できることを示すのに役立ちました。
まとめ
チームは、このプロジェクト中に ML マイクロサービスの構築について多くのことを学びました。以下は、主な提案の一部です。
- 早期に統合する – プロジェクトのライフサイクルの早い段階でデモを実施することが重要です。単純な推奨アルゴリズムでさえ、利害関係者によい印象を与えることができ、リソース配分と優先順位付けに役立ちます。
- 視覚化 – ML モデルをテストするには、視覚化ツールが不可欠です。生の製品 ID をサニティチェックとして検査することは簡単ではありません。推奨製品の画像と、推奨者の有効性を評価するためにユーザーに並べて示す暗黙の証拠が必要です。
- 複雑さの強化 – Amazon Personalize は、他の ML フレームワークと同様に、複雑さに関して大きな幅があります。より複雑なレシピから始めて、奇妙なレコメンデーションを診断するのは難しいことに気づきました。単純な HRNN レシピから始めることで、印象的な実用例をすばやく作成することができました。
- コストを見積もる – ML は高価です。エンジニアリングの決定にかかるコストを正確に見積もるようにしてください。これはクラウドインフラストラクチャのコストだけでなく、開発者の時間コストもかかわってきます。
- スケーリングを理解する – 独自の深層学習レコメンダーを構築している場合は、推論のスケーリング特性を必ず頭に入れてください。自社開発のソリューションでは、トラフィックの急増に対応できないことを知るのは辛いことです。
- 手動を排除する – ML マイクロサービスには、従来のバックエンドサービスよりも可動部分が多くあります。パイプラインのすべてを自動化する – 人の手の介入が必要な ETL またはデプロイプロセスが 1 つでもあれば、それは失敗と見なしましょう。ML エンジニアリングは現状でも十分に困難です。
Recommended for You は、当社のチームと StockX のどちらにとっても全体的に大成功でした。当社は、ML を会社のあらゆる側面に統合する可能性をすぐにつかみました。当社の成功から、主要な意思決定者が Amazon Personalize をより多くの StockX エクスペリエンスに統合し、ML の取り組みを拡大するよう求めるようになりました。もはやパーソナライゼーションが最重要課題であるといっても差し支えないでしょう。
当社のチームは、過去最大の年末バーゲンシーズンが始まる数週間前に、StockX エクスペリエンスの一部を手始めにパーソナライズを開始しました。Amazon Personalize のおかげで、マイクロサービスが全体的にほぼ完璧な可用性を実現できたことを誇りに思います。
著者について
 Sam Bean は、StockX の機械学習部門の創設メンバー兼リーダーです。彼は、難しい問題をより簡単でサーバーレスのソリューションで解決できないかと常に模索しています。Sam は、強化学習の新しいアプリケーションとほぼ毎日発生する GAN に魅了されています。一方で、彼は競技ピンボールのプレーヤーでありながら、トーナメントディレクターも務めています。
Sam Bean は、StockX の機械学習部門の創設メンバー兼リーダーです。彼は、難しい問題をより簡単でサーバーレスのソリューションで解決できないかと常に模索しています。Sam は、強化学習の新しいアプリケーションとほぼ毎日発生する GAN に魅了されています。一方で、彼は競技ピンボールのプレーヤーでありながら、トーナメントディレクターも務めています。
 Nic Roberts II は、機械学習と新興企業に情熱を傾けるデトロイトを拠点とするソフトウェア開発者で、ミシガン大学を卒業した後、2019 年に StockX に入社しました。彼は他にも、輸送業界を革新することにも関心を寄せており、以前は 2016 年の SpaceX Hyperloop Pod Competition で自律車両アルゴリズムの開発と学生の設計チームをリードしていました。余暇には、旅行、ミシガン北部でのスキーを楽しんでおり、増え続けるスニーカーコレクションをさらに充実させることに余念がありません。
Nic Roberts II は、機械学習と新興企業に情熱を傾けるデトロイトを拠点とするソフトウェア開発者で、ミシガン大学を卒業した後、2019 年に StockX に入社しました。彼は他にも、輸送業界を革新することにも関心を寄せており、以前は 2016 年の SpaceX Hyperloop Pod Competition で自律車両アルゴリズムの開発と学生の設計チームをリードしていました。余暇には、旅行、ミシガン北部でのスキーを楽しんでおり、増え続けるスニーカーコレクションをさらに充実させることに余念がありません。