Amazon Web Services ブログ
グラフデータベースってどんなもの?Amazon Neptune を使って グラフデータベースのクエリを体験しよう(準備編)
みなさんこんにちは。ソリューションアーキテクト(SA)の上原です。
私は普段SAとして製造業のお客様をサポートさせて頂く傍ら、フルマネージドなグラフデータベースである Amazon Neptune を技術領域として活動しています。
いきなりグラフデータベースと言われてピンと来ない方もいるかもしれませんが、グラフデータベースの活用は様々な領域で進んでいます。例えば、公共領域では 法人情報検索ツール、ヘルスケア領域では薬物間相互作用のチェック、マーケティング領域ではカスタマーインサイト分析、製造業ではトレーサビリティなどで利用されています。
アプリケーションから大量のリレーションシップを持つ大規模なデータセットを利用する場合、リレーショナルデータベースでは、複数の結合が必要になりクエリが複雑化する、期待するレスポンスが得られないといった課題があります。しかし、フルマネージドなグラフデータベースである Neptune は、リレーションシップの格納とナビゲートを目的として構築されたデータベースで、 ナレッジグラフ、 ID グラフや 不正検出といった代表的なグラフアプリケーションを構築することができます。
このブログでは、グラフデータベースでどんなことができるのか具体的なクエリを見てみたいという方向けに、Neptune のハンズオンをご紹介します。また、クエリを試すために必要となるサンプルデータを含む環境を準備するための手順をご案内します。
前提条件
本ハンズオンの実施には、以下が必要です。
-
- AWSアカウント – 作成されていない方は、こちらからアカウントを作成してください。
- AWS Region – 本ブログでは
us-east-1を利用します。
※ ハンズオンで提供される AWS CloudFormation テンプレートは、東京リージョンを含む15のリージョンで利用可能です。 - IAM ユーザ – 本ブログでは
AdministratorAccess権限をもつ IAM ユーザ を利用します。
※ ハンズオンで提供される CloudFormation テンプレートでは、Neptune クラスターや、前提となるネットワークの構成、クエリ実行環境となる Neptune グラフノートブック 等の作成 及び クラスターへのデータロード、クラスターへのアクセスやデータロードに必要な AWS Identity and Access Management (IAM) ロールの作成等が実行されます。必要な権限を持つ IAM ユーザまたは IAM ロールを作成し、ハンズオンを実施してください。
ハンズオン環境
ハンズオン手順の中で実行する CloudFormation テンプレートによって作成される全体アーキテクチャは以下です。
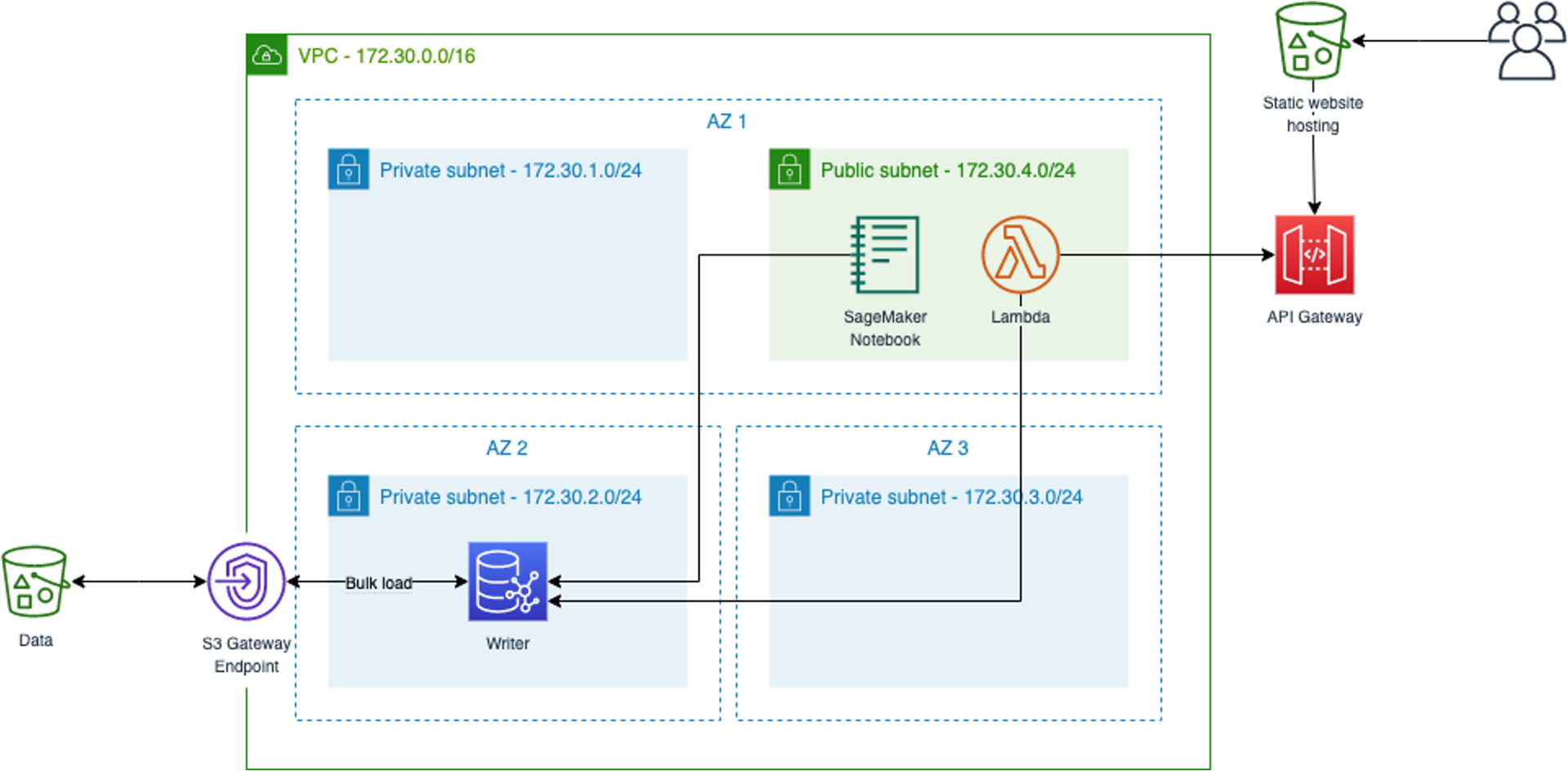
公開しているハンズオンでは、Neptune を利用するWebアプリケーションの作成までを範囲としていますが、このブログではグラフノートブックから Neptune へのクエリ部分にフォーカスして手順をご紹介します。
グラフノートブックは Amazon SageMakerノートブック サービスによってホストされるため、構成図では SageMaker Notebook と記載します。
ハンズオン環境の作成
ハンズオン環境の作成手順は公開されているハンズオンの Appendix に記載されています。ハンズオンの内容は更新される場合があります。最新の手順は原文をご確認ください。
CloudFormation テンプレートの実行
下記より CloudFormation テンプレート をダウンロードします。
https://neptune-workshop-assets.s3.amazonaws.com/neptune-immersion-day.yaml
CloudFormationコンソールにて、スタックの作成 > 新しいリソースを使用(標準)の順に選択します。

テンプレートの指定にて、テンプレートファイルのアップロードを選択し、ダウンロードしたファイルを指定します。
次へ を選択します。

スタックの詳細にて、任意のスタックの名前を入力し、次へ を選択します。
スタックオプションの構成にて、すべてデフォルト値のまま、次へ を選択します。
注意:タグを追加しないでください。タグキーが重複して作成され、テンプレートのデプロイが失敗します。
レビューにて注意事項にチェックをし、スタックの作成 を選択します。
注意:このテンプレートでは非同期に2つのデータセットのバルクロードを実行します。データのロードは15〜20分程度かかります。

スタックの作成完了を確認
CloudFormation スタックのステータスが CREATE_COMPLETE になっていることを確認します。

データロードの完了を確認
CloudWatch コンソールを開き、画面左側のサイドバーから メトリクス > すべてのメトリクス を選択します。
表示されたメトリクスから Neptune > クラスターのメトリクス > VolumeBytesUsed を選択します。



該当のメトリクスが 〜15.5GB になっていることを確認します。

注意:このテンプレートをデプロイしてワークショップを実施するには、1 時間あたり約 3 USD の費用がかかります。終了したら、必ず全てのリソースを削除してください。
ハンズオン(ノートブックの実行)
データモデル
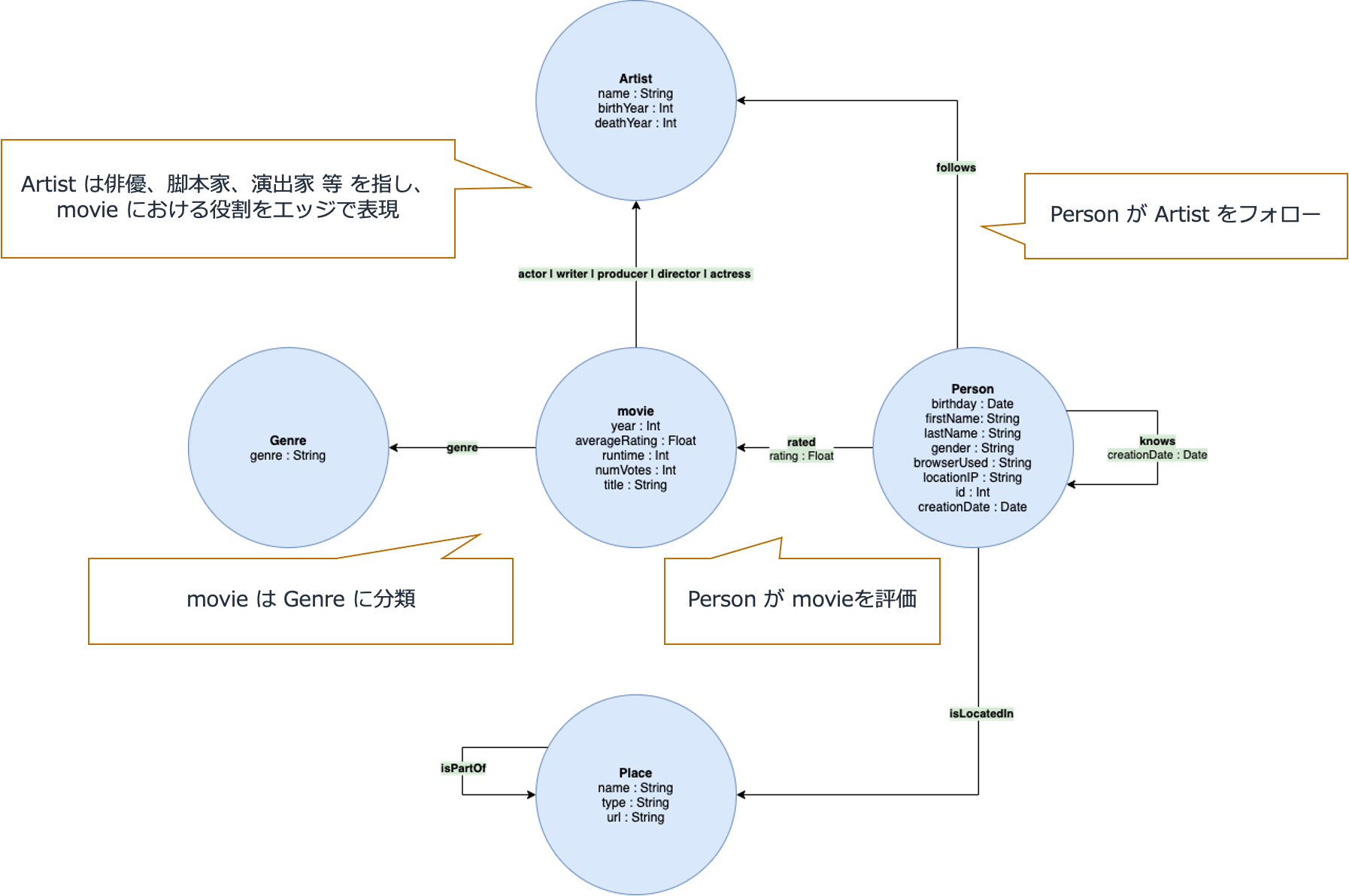
本ハンズオンでは IMDb(インターネットムービーデータベース)データセットの修正バージョンを使用します。 このデータの一部を、頂点、エッジ、およびプロパティとして表す次のグラフデータモデルに変換しました。
頂点(Vertex)は、下図では丸で表現されており、IDのある実態を指します。属性やメタデータを表すプロパティ(例:name)とロール名やタグを表すラベル(例:Artist)を付与することが可能です。頂点はノードと表記することもあります。
エッジ(edge)は、下図では矢印で表現されており、頂点間の関連や構造を形作ります。関連の強さやメタデータを表すプロパティ(例:rating)とエッジの意味を表すラベル(例:rated)を付与することが可能です。
グラフノートブックにアクセス
グラフノートブックにより、Neptune データベースへのクエリ環境をすばやく簡単に準備できます。ライブコードとナレーションテキストを含む、完全マネージド型のインタラクティブな開発環境です。
以降の手順では、事前に用意されたサンプルのノートブックにアクセスしクエリを実行します。
Neptune コンソール を開き、画面左側のサイドバーから ノートブック を選択します。
表示されたノートブックのチェックボックスを選択し、右上の アクション > Open Jupyter を選択します。

表示された Jupyter 画面にて Neptune > 00-Workshop-Notebooks-START-HERE > Gremlin を選択します。

ノートブックについて
以降の手順では、上記一覧に表示されたノートブックを開き、表示されたセルを順に実行します。
実行したいセルを選択し、上部の Run ボタンをクリックすることで実行できます。
次のセルに移動する前に、必ずセルが完了するのを待ってください。セル実行の完了は、各セルの左側の In [] 内に表示される整数で示されます。[*] という表示の場合、セルはまだ実行中です。これまでに Jupyter Notebook を使用したことがない場合は、上部の ヘルプメニュー の ユーザーインターフェイスツアー を参照して、簡単にウォークスルーしてください。
<例>

サンプルノートブックでは、NeptuneWorkbench を利用します。NeptuneWorkbench は、Neptuneとその機能を簡単に操作できるようにするカスタム Jupyter マジックコマンドのセットです。
データのロード
ワークショップを開始するために、サンプルデータセットを Neptune クラスターにロードします。使用する Neptune クラスターは、CloudFormation により既に作成されています。 Neptune は、S3バケットから直接データをロードできる Bulk Load API を提供します。このAPIを簡単に呼び出すためにマジックコマンド %load とウィジェットを使用します。
1.ノートブックの一覧から 00-Setup.ipynb をクリックします。
2.次のセルでは、2つのバルクロード API 呼び出しを発行します。1つはサンプルデータセットのすべての頂点とエッジをロードし、もう1つはロードのステータスをチェックします。

3.上記セルを実行すると、バルクロードジョブを発行するために必要なフィールドが %load ウィジェットに事前入力されます。ウィジェットが表示されたら、Submit ボタンをクリックしてロードを開始します。
※ このバルクロードジョブは、実行時にエラーが発生するように設定されています。
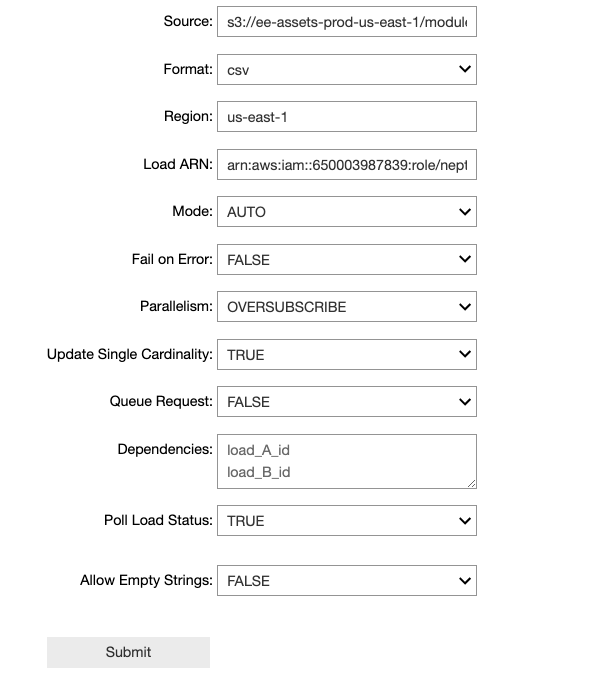
4.数十秒待つと、下記のように LOAD_FAILED というステータスが返されます。

5.次のセルでは、%load_status を使用してバルクロードジョブの詳細を確認し、エラーの原因を特定します。

6.上記のコマンドが LOAD_COMPLETED:5 および LOAD_FAILED:2 のステータスを返したことを確認してください。LOAD_NOT_STARTED が返された場合は、上記ステータスが表示されるまでセルブロックを再実行します。

7.出力結果をスクロールすると、一連のエラーが下部に表示されていることがわかります。これらのエラーは、ソース頂点または宛先頂点のいずれかが欠落しているグラフにエッジを作成しようとしていることを示しています。必要に応じてこれらの頂点がグラフにあることを確認してから、これらのエッジファイルをリロードすることで、これらのエラーに対処できます。
※ ハンズオンでは該当エラーに対処する必要はありません。

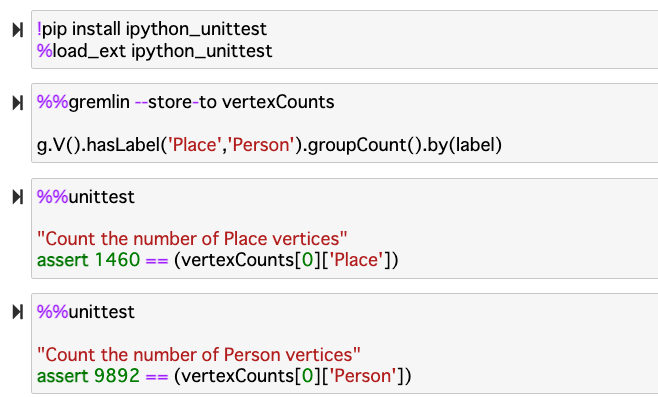
8.データを Neptune にロードしたので、ロードされた2つの頂点タイプのカウントが正しいことを確認してみましょう。 次のコマンドを順に実行して、すべてのデータをロードしたことを確認します。
ラベルごとに頂点の数を集計し、ラベル Place の頂点が1460個、ラベル Person の頂点が9892個 であれば OKと表示されます。
まとめ
このブログでは、グラフデータベースの具体的なクエリを試すことができる Neptune のハンズオンをご紹介しました。また、ここまでの手順でクエリを試すための環境が整いました。ぜひこの環境を利用してご自身の興味に合わせて色々なクエリをお試しください。
続編となる Gremlin 編ブログでは、サンプルノートブックを利用して Gremlin を用いた基本的な探索や更新について解説していきます。
Neptune を利用してアプリケーションを開発するには、Neptune のユーザガイドを参照してください。