Amazon Web Services ブログ
750 TB のデータを使用して Amazon Redshift で Amazon Payments 分析を実行する
Amazon Payments データエンジニアリングチームは、データの取り込み、変換、計算と保管を担当しています。チームはこれらのサービスを世界で 300 社以上のビジネス顧客が利用できるようにしています。これらの顧客には、製品マネージャー、マーケティングマネージャー、プログラムマネージャー、データサイエンティスト、ビジネスアナリスト、およびソフトウェア開発エンジニアが含まれます。彼らは、ビジネス上の決定を適切に下すために、データをスケジュールされたクエリとワンタイムクエリに使用しています。このデータは、リーダーシップチームがレビューする、週次、月次、および四半期ごとのビジネスレビューメトリクスの構築にも使用されています。
私たちは、以下を含むさまざまな消費者支払いビジネスチームをサポートしています。
- Amazon 支払い商品 (クレジットカード、ポイント付きショップ、アマゾン通貨コンバーター、国際決済商品)
- ギフトカード
- 支払いの受け取り体験
- Amazon ビジネスペイメント
また、機械学習の推薦エンジンへのフィードも行っています。このエンジンは、Amazon の支払いチェックアウトページでお客様に最適な支払い手段を提案します。
古いデータウェアハウスの課題
このセクションでは、データウェアハウスと分析のニーズでこれまで直面していた課題について説明します。支払い商品の発売とその新市場への拡大により、データ量が急激に増加しました。その後、抽出、変換、ロードプロセス (ETL) のスケーリングは厳しい課題に直面し、その結果、遅延と運用上の負担が生じました。データウェアハウスで直面していた具体的な課題は、次のとおりです。
- Upsert はスケーリングしていないので、1 回の実行あたり最大 10MN を超える更新が行えました。消費者製品カタログのデータセットには、米国市場で 6.5BN を超えるレコードがリストされており、1 日の更新が 10MN を超えることもありました。注文属性データセットについても同様の傾向が見られました。
- 6 か月分もの支払いデータを分析しなければならなかった場合、データの集計に時間がかかるか、または集計が完了しませんでした。多くの場合、ビジネスオーナーは特定の属性に基づいてデータを集約したいと考えていました。たとえば、成功した取引の数や特定の種類のカードごとの金額などです。
- 共有クラスター、つまり共有ストレージとコンピューティングは、リソースクランチを引き起こし、その全ユーザーに影響を与えました。各チームにはデータウェアハウスでそれぞれ最大 100TB が割り当てられました。各チームは自分のテーブルを持ち寄り、中央データウェアハウスのテーブルに結合することができます。クラスター上の不正なクエリは、同じクラスター上の他のすべてのクエリに影響を与えました。これらの不正なクエリの所有者を特定するのは困難でした。
- 本番テーブルは 30,000 以上あり、それらすべてを同じクラスターでホストすることはほとんど不可能になりました。
- 大きなテーブルでインデックスが破損すると、テーブルを再構築して埋め戻すのが大変です。
- データベース管理者はパッチを適用し、更新する必要がありました。
Amazon Redshift を新しい支払いデータウェアハウスとして使用する
私たちは、高速で信頼性が高く、将来のデータの増加に見合う規模がある、分析のニーズに適したさまざまなオプションを検討し始めました。これまでに説明したすべての問題を考慮して、中央データウェアハウスはコンピューティング層とストレージ層を分離する方向に進み、彼らはストレージを担当することにしました。そして機密性の高い重要なデータでも格納できるように暗号化されている Amazon S3 にデータレイクを構築しました。各消費者チームは、分析ニーズに合った独自の計算能力を実現するためのガイドラインを得ました。支払いチームは以下の利点に目を付け出しました。
- 便利な分析。
- S3 や他の AWS のサービスとの統合。
- 手ごろな価格のストレージと計算レート。
- ETL 処理に使えること。
私たちは、次の機能があることを評価して Amazon Redshift を選択しました。
- 一括アップロードが高速である。最大 700MN のデータを 30 分以内に挿入できる。
- データの Upsert が極めて高速である。
- データの列数が少ない数百万ものデータセットに対する集計クエリは、数分で終了するのに比べて数秒で戻る。
- データベースを維持するために DBA 時間を割り当てる必要がない。データエンジニアは、簡単にバックアップを実行し、新しいクラスターにスナップショットを再作成し、クラスタの問題が発生した場合にアラームを設定し、新しいノードを追加できます。
- S3 にデータを保存する機能がある。このデータは、Spectrum を介して複数の独立した Amazon Redshift クラスターからアクセスでき、ユーザーは、Spectrum テーブルを Amazon Redshift 上でローカルに作成された他のテーブルと結合することもできます。S3 にデータを保存する際、Spectrum レイヤーに処理をオフロードします。
- Amazon Redshift のベストプラクティスを使用して、配布キー、ソートキー、および圧縮に関してテーブルを設計できる。その結果、クエリのパフォーマンスは SLA の期待値を上回りました。
- 効果的な圧縮が行える点。これにより、適切な圧縮を選択することで 40〜50 パーセント以上のスペースを節約でき、より高速なクエリと効率的なストレージオプションが使用できるようになります。
データとストレージのソース
私たちは、安全なプロトコルを通じて、PostgreSQL、Amazon DynamoDB ライブストリーム、中央データウェアハウスのデータレイク、銀行パートナーのデータなど、さまざまなソースから得たデータを消費しています。PostgreSQL データベースからのデータはリレーショナル形式ですが、DynamoDB にはキー/値のペアがあります。キー/値データをリレーショナル形式に変換し、Amazon Redshift と S3 に格納します。最も頻繁にアクセスするデータは、Amazon Redshift に保持します。アクセス頻度の低い大規模なデータセットは、S3 に格納し、Amazon Redshift Spectrum を通じてアクセスします。
中央データレイクは、注文、出荷、払い戻しなど、さまざまなチームからの 30,000 以上のテーブルをホストしています。一方、支払いチームは、ソーステーブルとしてこのデータレイクから約 200 のテーブルが必要です。その後、支払い商品に固有のデータマートを構築しました。これは、スケジュールされたものとワンタイムのデータおよびレポーティングニーズの両方に応えるものです。50 TB 未満のすべての中小サイズのテーブルは、データを物理的に格納しているデータレイクから直接 Amazon Redshift にロードされます。50 TB を超えるテーブルは、Amazon Redshift にローカルに格納されません。代わりに、EMR-Hive を使用してデータレイクから取り出し、フォーマットを tsv から ORC/Parquet に変換して S3 に格納します。S3 データ上に Amazon Redshift Spectrum テーブルを作成します。フォーマットを変換すると各分析集約クエリの実行時間を短縮できますが、S3 に保存しておくと Amazon Redshift クラスター全体をデータで埋めるのではなく、それを使用して効率的なコンピューティングが行えます。
データアーキテクチャ
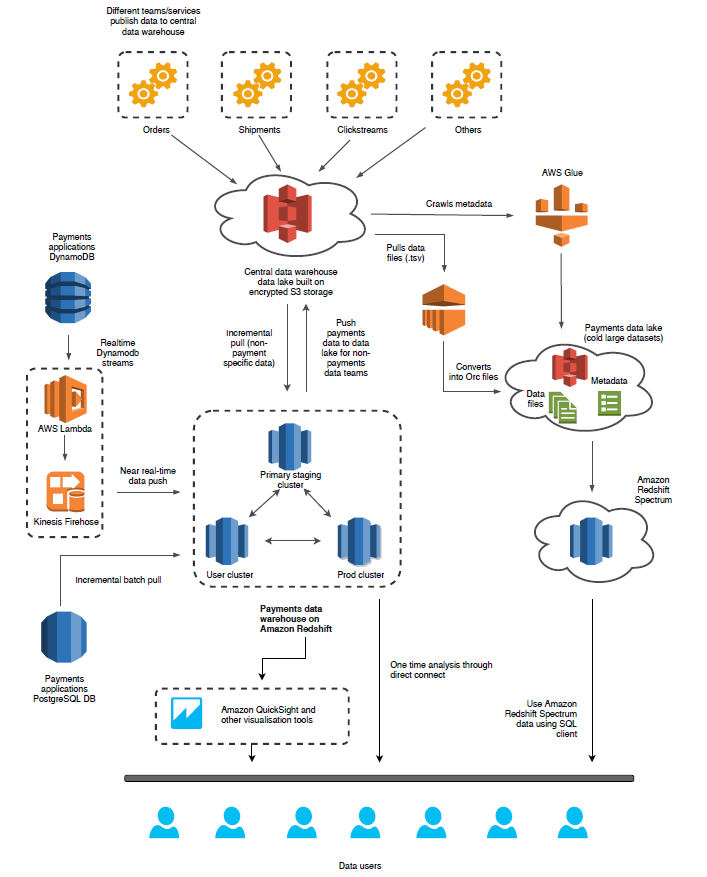
さまざまなコンポーネント
- 中央データウェアハウスのデータレイク (Andes) – 他のチームとデータを共有したい Amazon のほとんどすべてのシステムは、データをこのデータレイクに公開しています。これは、データファイルとともにメタデータがアタッチされた、Amazon S3 上に構築された暗号化ストレージです。すべてのデータセットにワンタイムダンプがあり、また増分デルタファイルがあります。チームは、次の手段によってデータを消費しようと思います。
- データを独自の Amazon Redshift クラスターに物理的にコピーすることで。最も頻繁にアクセスする小規模および中規模のテーブルに効率的です。
- Amazon Redshift Spectrum を使用してデータレイクに格納されているデータセットに対して分析クエリを実行することで。これは、一般的に 50 TB を超える大規模なコールドデータへのアクセスに役立ちます。これにより、すべてのスペースがこれらの大規模データファイルによって消費される可能性があるため、Amazon Redshift クラスターのスケールアップを回避できます。
- AWS Glue カタログを使用してチームの S3 バケットのメタデータを更新し、Amazon EMR を使用してデータを取得し、変換を適用し、フォーマットを変更し、最終データを Amazon Redshift Spectrum を用いてさらに消費することができる S3 バケットに格納することで。データセットが大きく、消費される前に変換が必要な場合は効率的です。
- Amazon Redshift クラスター – Amazon Redshift は中心的なアーキテクチャーを持ち、すべてのトゥルースソースの単一地点にするのに最も適していますが、私たちは主に 3 つのクラスターを管理しています。これは、レポートの SLA が一貫しており、またユーザーによるクエリ体験と (リソース集約型の) 中央データレイクの取り込みプロセスが分離しているためです。これらが別々のクラスターである必要がある理由は、クラスターごとに異なり、次の理由があります。
- ステージングクラスター:
- 私たちのデータソースは動的で、トランジット状態にあり、たとえば Oracle から Postgres や DynamoDB へ、リレーショナルソースから非リレーショナルソースへと移行しています。
- 中央のデータレイクからデータを引き出して Amazon Redshift に格納するメカニズムも進化しており、現況はリソース集約型になっています。
- データマート内のテーブル名は中央テーブルに似ていますが、データマートデータは中央データレイクのデータセットとは異なり、私たちのデータマートは支払いに固有のものです。ユーザーの Amazon Redshift クラスターにデータを転送する前に、必要な変換とフィルターを適用します。
- ユーザクラスター: 社内のビジネスユーザーは、分析のためにパブリックスキーマでテーブルを作成したいと思いました。また、アドホック分析には直接接続アクセスも必要でした。ほとんどのユーザーは SQL を知っており、ベストプラクティスを知っていますが、SQL に慣れていないユーザーがいて、クエリが最適化されず他の実行中のクエリに影響を与える場合があります。そこで、これらの不正なクエリからクラスターを保護するため、Amazon Redshift Workload Manager (WLM) 設定があります。
- Prod ETL クラスター: データユーザーがデータセットを利用できるようにするための厳密な SLA があります。システム上で実行されている不正クエリの影響を最小限に抑えるために、ユーザークラスターのレプリカを設定しました。すべての prod 変換はここで実行され、出力データはユーザーと prod の両方のクラスターにコピーされます。それにより、私たちがデータビジネスユーザーにコミットする SLA の達成を保証します。
- ほぼリアルタイムのデータの取り込み – 宣伝データ、カードの登録、ギフトカードの発行などを行う多くのアプリケーションでは、不正を検出するためにリアルタイムのデータ収集が必要です。アプリケーションデータは、DynamoDB Streams を有効にして Amazon DynamoDB に格納されます。AWS Lambda 関数と Amazon Kinesis Data Firehose を介してこれらのストリームからデータを消費します。Kinesis Firehose はデータを S3 に配信し、データを Redshift にロードするためのコピーコマンドを送信します。15 分のマイクロバッチがあり、それによりすべての接続がこれらのほぼリアルタイムのデータアプリケーションによって消費されないようにします。
- Amazon EMR 上で代替計算 – ウェブサイトのクリックストリームデータを通じてお客様の行動を追跡します。コンバージョン率 (お客様の中で、支払い商品の支払いページなどのさまざまな場所でバナーを見た後に支払い商品の購入手続に進んだ人の割合)、支払い商品の申し込み、ウェブサイトのヒット数の分析、これらの広告を表示した後のお客様の行動を追跡するファネルレポート、申請ボタンのクリック、申請フォームの記入、そして最後に申請フォームの送信に関するメトリクスはほとんどありません。1 日にほぼ 10B のウェブサイトヒットレコードを得ます。レポートを生成する前に、これらの大量で頻繁にはアクセスしないデータセット用の安価なストレージを探します。ストレージオプションとして S3 を選択し、Amazon EMR を使用して変換を適用しました。このアプローチでは、大量のコールドデータでデータベースのスペースがなくならないようにし、同時に Amazon Redshift Spectrum を使用して S3 でデータアクセスを有効にしたため、同様のクエリパフォーマンスが得られました。Amazon Redshift はカラムナデータベースであるため、選択したディメンション列が少ない場合は、あらゆる種類の集計を迅速に行えます。S3 に格納したデータについても同様のパフォーマンスが欲しいと思いました。Amazon EMR を使用し、データフォーマットを TSV から ORC または Parquet に変更することでそれを実現できました。毎日、S3 に新しいパーティションデータを作成し、新しいパーティションデータを含めるように Amazon Redshift Spectrum テーブルの定義を更新しました。これらの Spectrum テーブルへは、Amazon Redshift SQL クライアントを使用した 1 回限りの分析のため、または ETL パイプラインのスケジュール設定のために、ビジネスユーザーがアクセスしました。
- 非支払いユーザー用のデータウェアハウスのデータレイクへのデータの公開 – 支払い固有のデータセットを作成しました。たとえば、取引行動、ウォレットへの侵入などを拒否します。非支払いビジネスユーザーも、これらのデータセットを使用することに興味があることがあります。これらのデータセットを中央データウェアハウスのデータレイクに公開します。さらに、支払いアプリケーションチームが、支払い商品アプリケーションデータのソースです。データエンジニアリングチームはこれらのデータセットを消費し、必要な変換を適用して、Amazon Redshift とデータレイクを介して支払いユーザーと非支払いユーザーの両方に公開します。
スキーマ管理
すべてのプロダクションテーブルを格納する prod スキーマがあり、プラットフォームチームのみが変更を加えることができます。私たちはまたプロダクト固有のメンバーがアクセスできる、支払い商品固有のサンドボックスを用意します。あらゆる支払いデータユーザーのための一般的なパブリックスキーマがあります。このスキーマのテーブルを作成、ロード、切り捨て、削除することができます。
データベースと ETL 検索
Amazon Redshift データベースオブジェクトに関する興味深い事実をいくつか紹介します。
- データベースの数: 4
- ステージングデータベース DB1: ds2.8xlarge x 20 ノード
メモリー:1 ノードあたり 244 GiB
ストレージ:1 ノードあたり 16TB の HDD ストレージ - ユーザーデータベース DB2: ds2.8xlarge x 24 ノード
メモリー:1 ノードあたり 244 GiB
ストレージ:1 ノードあたり 16TB の HDD ストレージ - プラットフォームデータベース DB3: ds2.8xlarge x 24 ノード
メモリー:1 ノードあたり 244 GiB
ストレージ:1 ノードあたり 16TB の HDD ストレージ - レポートデータベース DB4: ds2.8xlarge x 4 ノード
メモリー:1 ノードあたり 244 GiB
ストレージ:1 ノードあたり 16TB の HDD ストレージ
- ステージングデータベース DB1: ds2.8xlarge x 20 ノード
- データベースのサイズ:
- 総メモリ: 17 TB
- 総ストレージ: 1.15 ペタバイト
- テーブル数:
- 分析 prod db: 6500
- 分析ステージング db: 390
ユーザークラスター
ここにユーザーに公開されているデータベースに関するいくつかの統計情報があります。これにはコアテーブルがあり、ユーザーは必要に応じて独自のテーブルを作成できます。ユーザーが作成したテーブルを除くすべてのテーブルをホストする同じデータベースのミラーイメージがあります。他のデータベースは、ETL プラットフォームに関する prod パイプラインを実行するために使用します。S3 にアーカイブされたクリックストリームデータセットのようなスナップショットテーブルを除き、これらのテーブルのほとんどが全履歴を持っています。


ステージングクラスター
ここにステージングデータベースに関するいくつかの統計情報があります。ステージングデータベースは、他のチームまたは中央データウェアハウスのデータレイクから送られてくるすべてのデータのランディングゾーンです。ほとんどの ELT ダウンストリームジョブで最終更新日を検索し、増分データのみを取得し、ユーザーデータベースとレプリカデータベースに格納しているため、テーブルの保持はすべてのテーブルに適用されます。
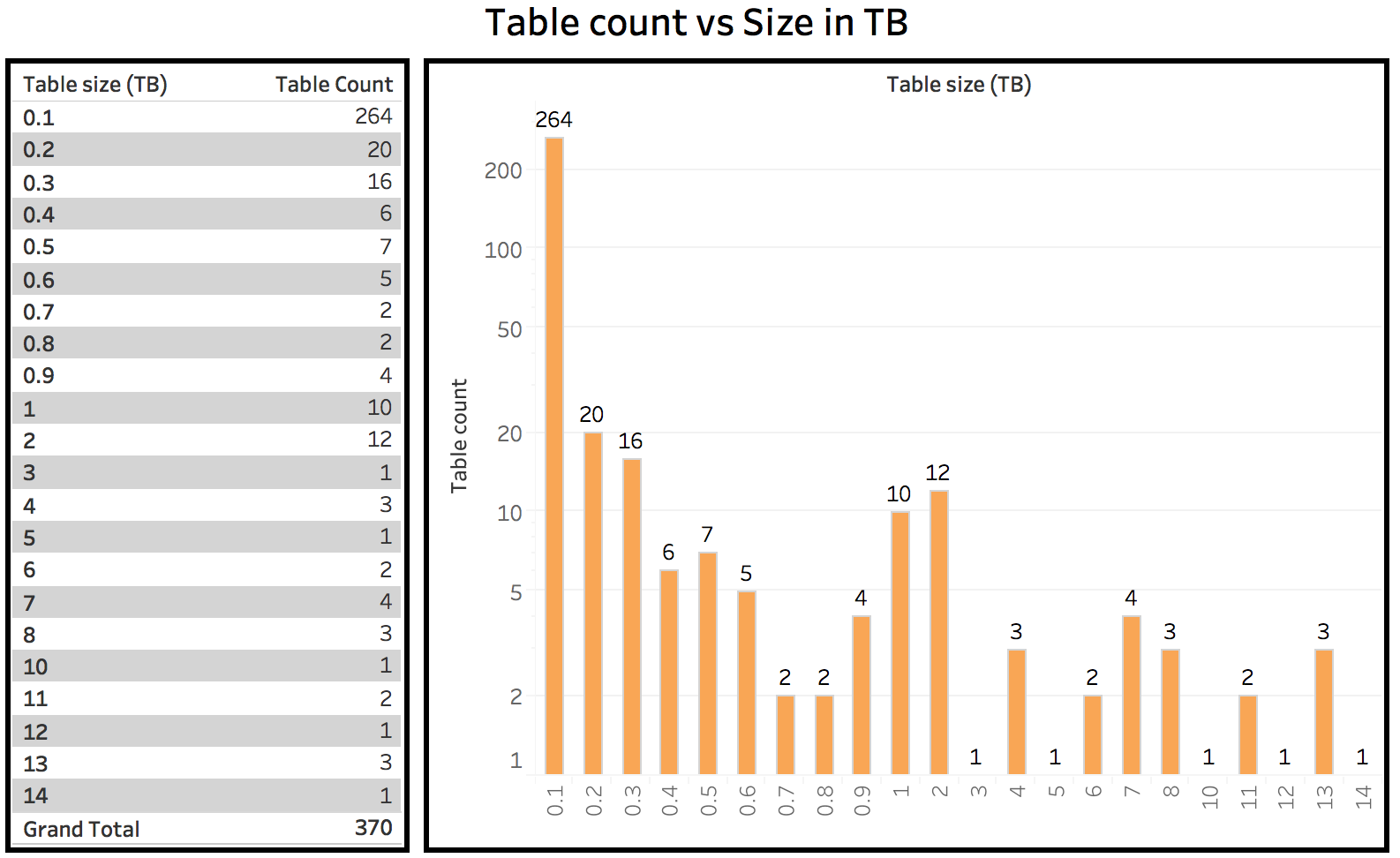
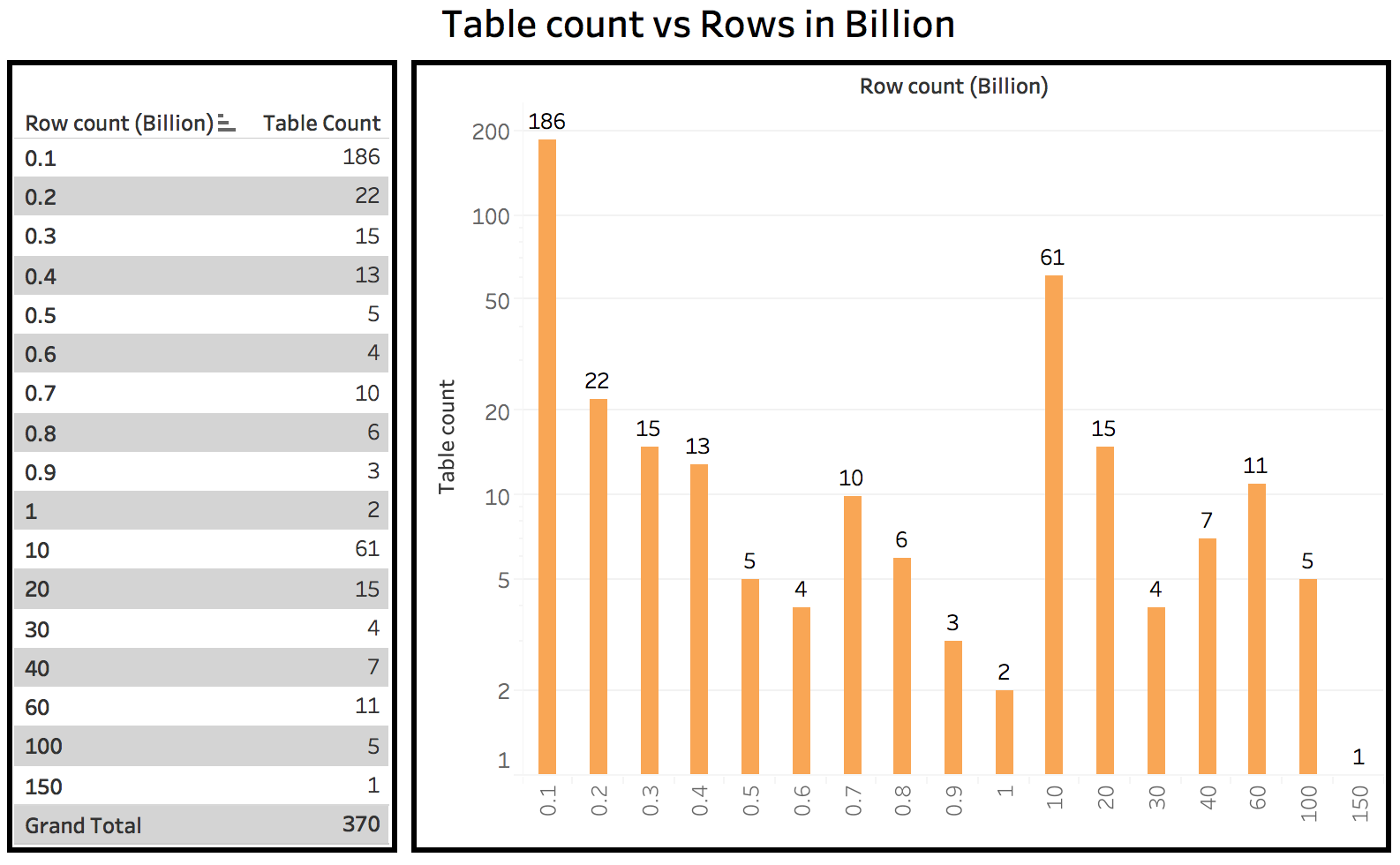
スケジュールされたデータベースへの ETL とクエリのロード
- 1 日の抽出 ETL ジョブの数: 2943
- ETL ジョブのロード数: 1655


- 1 日の合計ロード処理量: 119 BN
- 1 日の合計ロード時間: 11,415 分

- 1 日の合計データ抽出量: 166 BN
- 1 日の合計日数抽出ランタイム: 25,585 分

データベース上のスケジュールされたクエリとワンタイムクエリのロード
- さまざまなデータベースユーザーによる、データベース上の 1 日のクエリロード。

ベストプラクティス
- 正しいソートキーと分散キーを使用してテーブルを設計します。クエリのパフォーマンスは、スキャンするデータ量と、結合が同じ場所にある結合であるかどうかによって異なります。適切なソートキーを選択して不要なデータをスキャンしないようにし、適切な分散キーを選択して結合データが同じノード上に確実に存在するようにすることで、ネットワーク上でのデータの移動が少なくなるため、クエリパフォーマンスが向上します。詳細については、「Amazon Redshift Best Practices for Designing Tables」をご覧ください。
- クエリを作成する際は、「Amazon Redshift Best Practices for Designing Queries」を参照してください。
- 大きなファイルを小さなファイルに分割することでロード戦略を変更し、シリアル挿入の代わりにバルクロードを使用します。詳細については、「Amazon Redshift Best Practices for Loading Data」をご覧ください。
- 正しいランタイム、メモリ、優先度キューなどを割り当てることによって、システムの悪用を避けるために適切な WLM 設定を構成します。詳細については、「Tutorial: Configuring Workload Management (WLM) Queues to Improve Query Processing」をご覧ください。
- Amazon Redshift アドバイザーを使用して、圧縮が必要なテーブル、統計が欠落しているテーブル、圧縮されていないデータロードを特定し、ETL パイプラインをさらに微調整します。詳細については、「Working Recommendations from Amazon Redshift Advisor」をご覧ください。
- 無駄なスペースが多くあるテーブルを特定し、頻繁にバキューム処理を行います。それにより無駄なスペースが解放されるのと同時に、クエリのパフォーマンスが向上します。詳細については、「Vacuuming Tables」をご覧ください。
- DB に送信された SQL を分析し、テーブルの使用量と負荷の高い結合のパターンを特定します。データエンジニアがこれらのテーブルを事前結合し、ユーザーが単一のテーブルにアクセスするのを手助けすることで、より非正規化されたテーブルを構築するのに役立ちます。これは、高速で効率的な方法です。
結論と次のステップ
1.15 PB の総容量、最大 6500 のテーブル、4500 のスケジュールされた ETL 実行、1 日あたり 13,000 の ETL クエリ能力を持つ Amazon Redshift クラスターは、支払いチームのビジネスユーザーの ETL ニーズをほぼすべて満たしています。けれども最近のデータ量の増加により、予想以上に DB を占めるようになってきました。スケーリングの問題を気にすることなく、S3 上にシームレスなユーザーエクスペリエンスを持ったデータレイクを構築し、Amazon Redshift Spectrum を使用してそれらにアクセスすることで、より安価なストレージオプションを選択できるようにすることが次のステップでしょう。
著者について
 Bishwabandhu Newton は、Amazon コンシューマーペイメントチームのシニアデータエンジニアです。彼はデータ ウェアハウジングの経験が 12 年以上あり、Amazon.com では 9 年以上その経験があります。
Bishwabandhu Newton は、Amazon コンシューマーペイメントチームのシニアデータエンジニアです。彼はデータ ウェアハウジングの経験が 12 年以上あり、Amazon.com では 9 年以上その経験があります。
Matt Scaer は、データ ウェアハウジングの経験が 20 年以上あり、AWS と Amazon.com の両方で 11 年以上の経験を持つ、プリンシパルデータウェアハウジングスペシャリストソリューションアーキテクトです。