Amazon Web Services ブログ
AWSデータレイクへのほぼリアルタイムなレプリケーションのためのSAP Data ServicesとSAP LT Server
はじめに
このブログでは、SAP Landscape Transformation (LT)とSAP Data Services (DS)を使用して、SAP S/4HANAやSAP Business SuiteなどのSAPアプリケーションからAmazon Simple Storage Service (Amazon S3)にデータを複製するソリューションの設定手順を紹介します。SAP Landscape Transformation Replication Serverは、ほぼリアルタイムなレプリケーションを必要とする企業にとって理想的なソリューションです。
多くのエンタープライズ企業がデータレイクを導入し、製造成果の最適利用、ビジネス成果の追跡、製品ライフサイクル管理の促進をしています。格納の最初のプロセスには、いくつかの商用オフザシェルフ (COTS)のアプリケーションと非COTSのアプリケーションからのデータの取り込みを伴います。先日のブログ、SAP on AWSと組み合わせたデータレイクの構築で解説したように、SAPデータを抽出する方法はいくつか存在します。
数万を超えるデータレイクが既にAWS上で実装されています。お客様は、Amazon S3にデータを保存し、そのデータを幅広い分析サービスと機械学習サービスを用いて分析し、イノベーションのペースを加速することで、恩恵を得ています。AWSでは、ネイティブの取り込みとデータ転送サービスの最も幅広く完全なポートフォリオに加えて、S3と連携する豊富なパートナーエコシステムの統合を提供しています。
SAP Data Servicesは、データ統合、データ品質、データプロファイリング、テキストデータ処理のために、単一のエンタープライズ級のソリューションを提供する、人気のあるETLエンジンの一つです。これにより、信頼できるデータを重要なビジネスプロセスに統合、変換、改良、配信することができます。SAP LT Serverを組み合わせると、AWSデータレイクソリューションへのほぼリアルタイムなデータのレプリケーションが可能になります。お客様は、分析サービス用にバッチ処理かほぼリアルタイムな処理かを選択できます。SAP Data Servicesは、SAPとそれ以外のアプリケーション/データベース用にすぐ使える複数のコネクターをあらかじめパッケージしています。
前提条件
この手順は、SAP Basis、SAP Data Services、SAP LT、Amazon S3、AWS Identity and Access Management (IAM)の構成についてある程度の経験を持ったSAP ETL、あるいはテクノロジーコンサルタントを対象にしています。抽出、変換、格納のための主要なソリューションコンポーネントは以下のとおりです。
SAP DMIS 2011 SP3 以降
SAP Landscape Transformation Replication Server 2.0 以降
SAP Data Services 4.2 SP1 以上
ソリューションの概要

Operational Data Provisioning (ODP) フレームワークは、サブスクライバーと呼ばれる様々なターゲットSAPアプリケーションの抽出と複製のシナリオをサポートしています。サブスクライバーは、後続処理のために、デルタキューからデータを取得します。
サブスクライバーがODPコンテキストを介してデータソースにデータを要求すると、すぐにデータがレプリケーションされます。Operational Data Queue (ODQ)は、パブリッシャーとサブスクライバーの間で異なるデータのキューを保持するために使用されます。ODPとODQの詳細は、SAPのドキュメントを参照してください。
SAP LT Replication Serverは、ODPコンテキストのプロバイダーとして機能します。詳細な手順は以下のとおりです。
AWS
- AWSアカウントを設定します
- S3バケットとバケット内にフォルダーを作成します (例: “Product”)
- このS3バケットにフルアクセスできるIAMロールを作成します
- プログラムによるアクセス権を持つIAMユーザーを作成し、IAMロールをアタッチします
- このユーザーのアクセスキーとシークレットアクセスキーをダウンロードしておきます。SAP Data Servicesで認証情報を適用するのに使用します
SAP LT
- SAPにログインします。SLT管理者のアクセス権があることを確認してください
- トランザクションLTRCに移動します
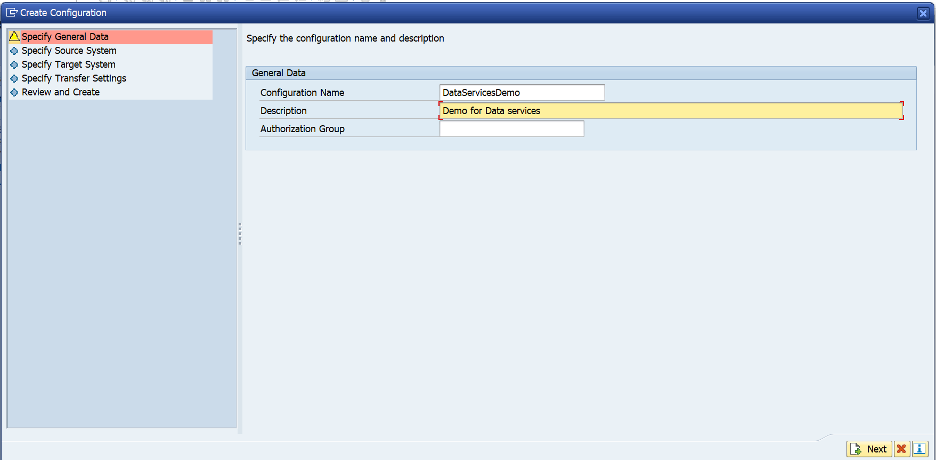
- Create Configurationのアイコンを選択します
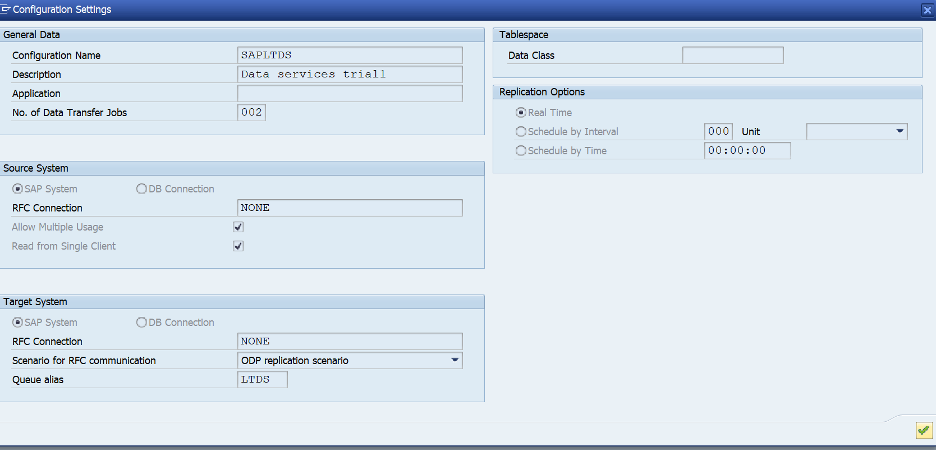
- 以下に示すように、Configuration NameとDescriptionを入力します
- RFC Connectionを選択します。Destination欄にはNONEを選択します
(SLTシステムがECCシステムと分離している場合は、ソースシステムのRFC宛先を入力してください)

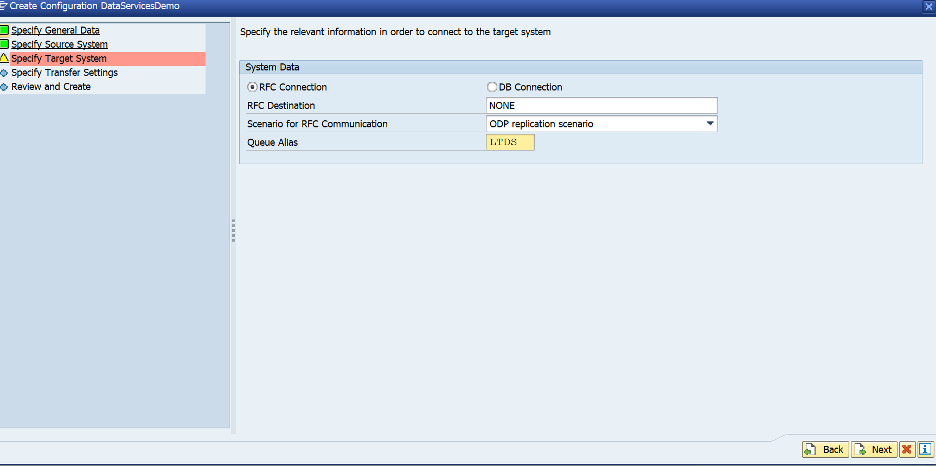
- Nextをクリックします。ターゲットには、以下に示すように、RFC DestinationでNONEを選択します
- Scenario for RFC CommunicationでODP replication scenarioを選択します
- 任意の4文字のAliasを選択します (後でData ServicesのODPコンテキストで使用することに留意してください)
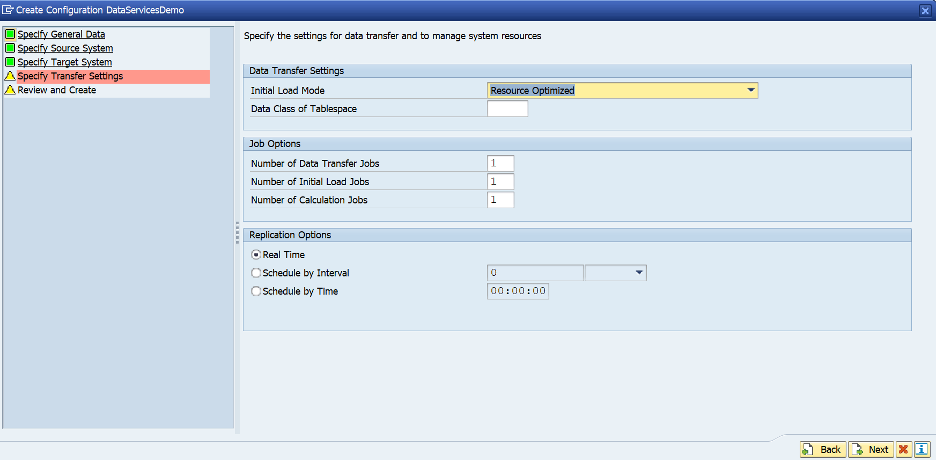
- Nextを選択します
- 確認して、Createを選択します
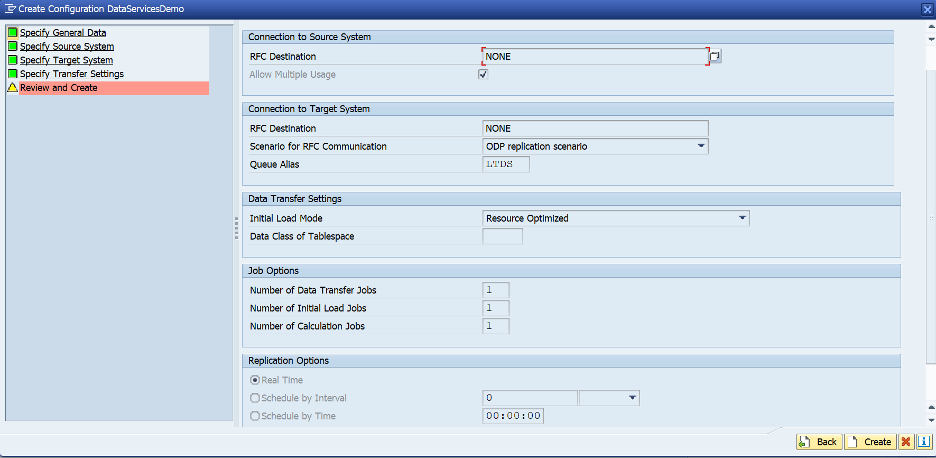
- キューは有効でなければなりません。Configuration Nameをクリックして設定を確認します
SAPソースシステムのすべてのディクショナリーテーブルは、SLTコンテキストを使用してクエリーできることに注意してください。
SAP Data Services
ソースの作成
SAP Data Services Designerを開きます。
- Project ExplorerからSAP Data Servicesのプロジェクト名を右クリックします
- New > Datastoreを選択します
- Datastore Nameを入力します (例: NPL)
- Datastore typeのフィールドで、SAP Applicationsを選択します
- Application server name欄には、SAP LTのアプリケーションサーバーのインスタンス名を入力します
- 接続に必要な認証情報を指定します。可能なら、SAP LT ServerでData Services用に個別のユーザーを作成してください
- Advancedボタンを開きます。
ODP Contextには、SLT~ALIASを入力します。ALIASは、SLTの構成で指定したキューのエイリアスです。
OKをクリックします。
新しいデータストアが、DesignerのローカルオブジェクトライブラリーのDatastoreタブに表示されます
ターゲットのデータストア
S3バケットを指すようにFile Locationのオブジェクトを構成します。
- File Formatsを選択します
- File Locationsを選択し、右クリックして新しいファイルの場所を作成します
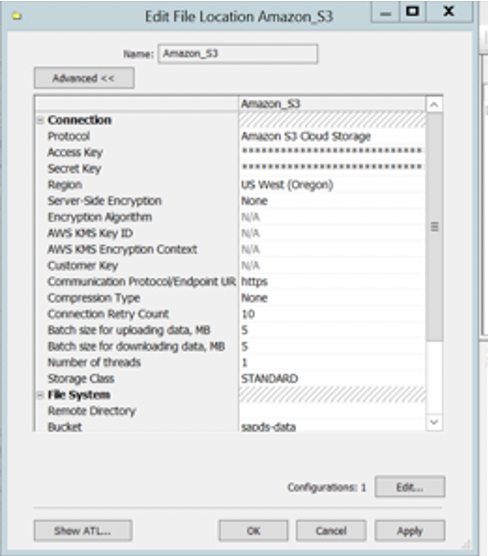
- ProtocolにAmazon S3 Cloud Storageを選択し、事前に保存したAccess KeyとSecret Keyの認証情報を入力します
- 以下のスクリーンショットに示すように、リージョンとバケット名を入力します
- 認証情報を保存してテストし、接続が機能することを確認してください
SAP Data Servicesのフロー用にインポートの作成
次の手順では、初期ロードと差分ロードのためにソースのデータストアからODPオブジェクトをインポートし、データをAmazon S3で処理するためにそれらをSAP Data Servicesで利用できるようにします。
- SAP Data Services Designerのアプリケーションから、レプリケーションロード用のソースのデータソースを展開し、ODPオブジェクトをダブルクリックします
- 右側パネルの上部にあるExternal Metadataオプションを選択します。使用可能なテーブルとODBオブジェクトを含むノードのリストが表示されます
- ODPオブジェクトのノードをクリックして、使用可能なODPオブジェクトのリストを取得します。リストの表示には時間がかかる場合があります
- Searchボタンをクリックします。ダイアログ画面から、Look inメニューでExternal dataを選択し、Object typeメニューでODPオブジェクトを選択します
- Searchダイアログで検索条件を選択して、ソースのODPオブジェクトのリストをフィルタリングします
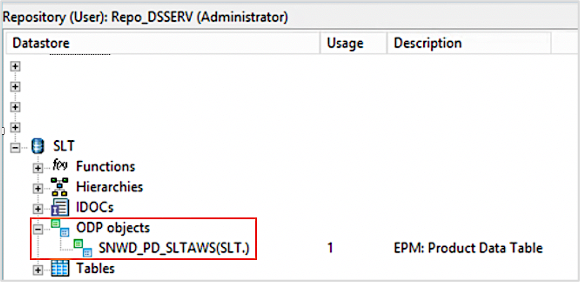
- リストからインポートするODPオブジェクトを選択します (例: SNWD_PD)
- 右クリックして、Importオプションを選択します
- 適切な値でName of Consumerを入力し、前の手順のData Sericesのプロジェクト名でName of Projectを入力します
- Extraction modeでChanged-data capture (CDC)オプションを選択します。Importをクリックして、ODPオブジェクトをData Servicesにインポートします
- データストアのオブジェクトライブラリーでODPオブジェクトを確認してください
注釈: 詳細は、SAP Data ServicesのドキュメントのImporting ODP source metadataのセクションを参照してください。
データフローとバッチジョブの作成
- SAP Data Services Designerのアプリケーションを開き、データフローのセクションに移動します
- 右クリックして、適切なプロジェクト名を持った新しいデータフローを作成します
- Finishをクリックします
- プロジェクトを右クリックして、新しいバッチジョブを作成します
- データフローをキャンバスにドラッグアンドドロップします
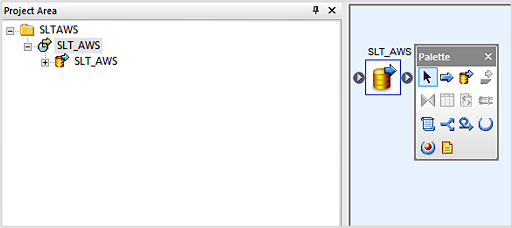
- データフローをダブルクリックして、ODPオブジェクトをデータフローのワークスペースにドラッグします
- ODPオブジェクトをダブルクリックして、初期ロードでNoを選択します
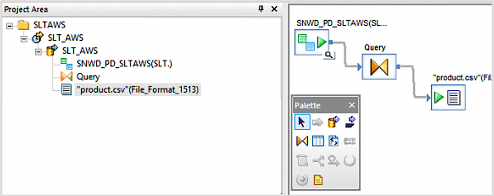
- 変換タブからクエリーオブジェクトをデータフローのワークスペースにドラッグして、ODPオブジェクトに接続します
- キャンバスからクエリーオブジェクトをダブルクリックし、スキーマアウトのセクションを右クリックして、Create File Formatオプションを選択します

- データファイルのセクションにあるファイルフォーマットエディターに移動し、Locationのセクションにターゲットのデータソースの構成時に作成したAmazon S3バケットを入力します
- ディレクトリー名としてAmazon S3バケットのフォルダー名を入力します
- File name(s)のセクションで適切なファイル名を入力し、構成を保存します
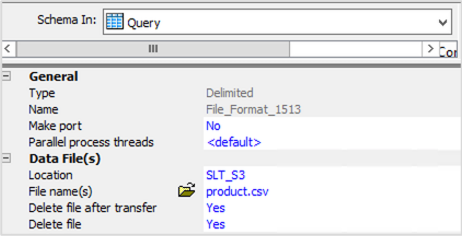
- 新しいファイルフォーマットを確認し、ファイルフォーマットをデータフローのワークスペースにドラッグして、変更を保存してください
CDC操作の場合、ファイル名に日付のタイムスタンプを埋め込むことが必要になるかもしれません。この手順に関するSAPドキュメントは、こちらから入手できます。
データフローの実行
- ジョブ名を右クリックして、データフローを実行します。レコードの初期セットがS3バケットに格納されます。
ODPオブジェクトをさらにレコードに追加します。このセッションでは、トランザクションSEPM_PDを実行して、ODPオブジェクトSNWD_PDをさらにレコードに追加しています。
ジョブを再実行して、差分ロードを行います

注釈: ジョブは、大きなテーブル用にバックグラウンドでスケジューリングできます。
結論
S3へのSAPデータの格納は、これらのデータの潜在的価値を引き出すための最初の一歩です。AWSは、S3に存在するデータを管理、強化、分析するための多くのサービスを提供しています。AWS DMSとAWS Glueを使用して、データの変更をキャプチャし、Parquet形式で統合できます。
Zalandoのようなお客様はこの取り組みをさらに進めており、 SAP HANAのフェデレーションを使用してSAPデータをAmazon Redshiftで活用し、SAP内の主要なビジネスKPIを維持しながら、分析データ用に規模の経済を獲得しています。
翻訳はPartner SA 河原が担当しました。原文はこちらです。