Amazon Web Services ブログ
Amazon SageMaker マルチモデルエンドポイントを使用して推論コストを削減する
ビジネスでは、コホートやセグメントに基づくモデルではなく、ユーザーごとの機械学習 (ML) モデルをますます発展させています。個々のユーザーデータに基づき、数百から数十万のあらゆる場所からのカスタムモデルをトレーニングしています。たとえば、音楽ストリーミングサービスでは、各リスナーの再生履歴に基づくカスタムモデルをトレーニングし、音楽のおすすめをパーソナライズしています。タクシーサービスでは、各年の交通パターンに基づくカスタムモデルをトレーニングし、乗客の待ち時間を予測しています。
ユースケースごとにカスタム ML モデルを構築すると、推論の精度が向上するという利点がありますが、モデルのデプロイコストが大幅に増大するという欠点もあり、本番環境で多くのモデルを管理するのが困難となっています。このような課題は、同時にすべてのモデルにアクセスはしないがいつでも利用可能にしておく必要がある場合により顕著になります。Amazon SageMaker マルチモデルエンドポイントは、このような弱点に対応し、複数の ML モデルをデプロイする、スケーラブルでコスト効率の高いソリューションをビジネスに提供します。
Amazon SageMaker はモジュラー型のエンドツーエンドサービスで、大規模な ML モデルの構築、トレーニング、デプロイを容易にします。ML モデルはトレーニング後、完全マネージド型でリアルタイムの推論を低レイテンシーで実行可能な Amazon SageMaker エンドポイントにデプロイできます。単一のエンドポイントに複数のモデルをデプロイし、マルチモデルエンドポイントを使用する単一のサービングコンテナにより稼働させることが可能になります。エンドポイントと、その基盤となるコンピューティングインスタンスの利用率増加により、大規模な ML のデプロイ管理が容易になり、モデルのデプロイコストが低下します。
本記事では Amazon SageMaker マルチモデルエンドポイントを紹介し、この新機能を導入して XGBoost を使用することで、個々の市場セグメントの利用料金を予測する方法を説明します。本記事では、マルチモデルエンドポイントで 10 個のモデルを実行する場合と、個別のエンドポイント 10 個を使用する場合との比較を行いました。この結果、以下の図に示すように、月あたり 3,000 USD を節約できました。

マルチモデルエンドポイントは、数百から数千のモデルに規模を変えて容易に対応できます。また本記事では、エンドポイントの設定とモニタリングの考慮事項も検討し、1,000 個のモデルでコストを 90% 以上節減した例についてハイライトします。
Amazon SageMaker マルチモデルエンドポイントの概要
Amazon SageMaker により、冗長性の高い複数のアベイラビリティーゾーンで、自動スケーリングの Amazon ML インスタンスにモデルを 1 クリックでデプロイすることが可能になります。インスタンスのタイプと、希望する最大数および最小数を指定すれば、Amazon SageMaker が残りを引き受けます。インスタンスを立ち上げ、モデルをデプロイし、安全な HTTPS エンドポイントを設定します。低レイテンシー、高スループットの推論を実行するため、アプリケーションはこのエンドポイントへの API 呼び出しを含む必要があります。このアーキテクチャーにより、モデルの変更でアプリケーションのコード変更が不要になるため、アプリケーションに新しいモデルを数分で統合できます。Amazon SageMaker は完全マネージド型で、あなたに代わって本番環境のコンピューティングインフラストラクチャを管理し、健全性チェックの実行、セキュリティパッチの適用、その他の定例のメンテナンス実行をすべて、モニタリングとログ記録を担う組み込みの Amazon CloudWatch で行います。
Amazon SageMaker マルチモデルエンドポイントは、1 つのエンドポイントに複数のトレーニング済みモデルをデプロイし、単一のサービングコンテナを使用して稼働させることを可能にします。マルチモデルエンドポイントは完全マネージド型で可用性が高く、トラフィックをリアルタイムで稼働させることができます。エンドポイントを呼び出す際には、ターゲットのモデル名を指定することで、特定のモデルに簡単にアクセスできます。この機能は、共有サービングコンテナで稼働する類似のモデルが多数あり、同時にすべてのモデルにアクセスする必要がない場合に最適です。たとえば法律関係のアプリケーションでは、広範な規定上の管轄を完全にカバーする必要がありますが、それにはめったに使用されないモデルが多数含まれることになります。1 つのマルチモデルエンドポイントでは、使用頻度の低いモデルに対応し、コストの最適化と大量のモデルの管理を効率よく行うことができます。
Amazon SageMaker でマルチモデルエンドポイントを作成するには、マルチモデルのオプションを選択し、推論サービングコンテナイメージのパスを提供して、Amazon S3 にトレーニングモデルのアーティファクトが保存されているプレフィックスを提供します。S3 ではモデルのどの階層でも定義できます。マルチモデルエンドポイントを呼び出す場合、新しい TargetModel ヘッダーに特定のモデルの相対パスを提供します。マルチモデルエンドポイントにモデルを追加するには、新しいトレーニング済モデルのアーティファクトを S3 に追加して呼び出します。すでに使用中のモデルを更新するには、S3 に新しい名前のモデルを追加して、新しいモデル名でエンドポイントの呼び出しを開始します。マルチモデルエンドポイントでデプロイされたモデルの使用を中止するには、モデルの呼び出しを停止し、S3 からモデルを削除します。
Amazon SageMaker マルチモデルエンドポイントでは、エンドポイントの作成時、S3 のコンテナにすべてのモデルをダウンロードせずに、呼び出された時に S3 から動的にモデルをロードします。このため、モデルの最初の呼び出しでは、低いレイテンシーで完了する後の推論より、推論のレイテンシーが高くなる場合があります。モデルがすでにコンテナにロードされ、呼び出されている場合、ダウンロードの手順をスキップすると、モデルは低レイテンシーの推論に戻ります。たとえば、1 日に数回しか使用されないモデルがあったとします。このモデルは必要に応じて自動でロードされますが、頻繁にアクセスされるモデルは最も低いレイテンシーでメモリーに保持されます。以下の図では、S3 からマルチモデルエンドポイントに動的にロードされるモデルを示しています。

Amazon SageMaker マルチモデルエンドポイントを使用して利用料金を予測する
本記事では、利用料金のドメインに基づいた、マルチモデルエンドポイントのユースケースの例を説明します。詳細については、GitHub の作業全体のノートブックをご覧ください。ここでは人工的に生成されたデータを使用し、任意の数のモデルで実験を行うことができます。各都市には、ランダムに生成された特徴を持ついくつかの家にトレーニング済のモデルがあります。
この説明には次の手順が含まれます。
- トレーニング済モデルをマルチモデルエンドポイントで利用可能にする
- コンテナを準備する
- マルチモデルエンドポイントを作成し、デプロイする
- マルチモデルエンドポイントを呼び出す
- 新しいモデルを動的にロードする
トレーニング済モデルをマルチモデルエンドポイントで利用可能にする
モデルの変更やモデルのトレーニングプロセスなしでマルチモデルをデプロイし、S3 に保存されるモデルのアーティファクト作成 (model.tar.gz ファイルなど) を継続できるという利点があります。
この例のノートブックでは、モデルのセットは並列でトレーニングされ、各トレーニングジョブからのモデルのアーティファクトは、S3 の特定の場所にコピーされます。モデルのセットをトレーニングおよびコピーした後、フォルダーには以下のコンテンツが入ります。
各ファイルは、元の model.tar.gz からファイル名が変更されるため、各モデルは一意の名前を持津ことになります。予測のためにリクエストを呼び出す場合、ターゲットモデルの名前を参照します。
コンテナを準備する
Amazon SageMaker マルチモデルエンドポイントを使用するには、GitHub の汎用マルチモデルサーバー機能を使用して、ドッカーコンテナを構築します。これはどのフレームワークの ML モデルにも対応する、柔軟で簡単に使用できるフレームワークです。XGBoost のサンプルノートブックでは、オープンソースの Amazon SageMaker XGBoost コンテナをベースに使用したコンテナの構築方法を示しています。
マルチモデルエンドポイントを作成する
次のステップは、ターゲットモデルが S3 のどこで見つかるか知っているマルチモデルエンドポイントを作成することです。本記事では、AWS SDK for Python の boto3 を使用してモデルのメタデータを作成しています。特定のモデルを記述するのではなく、モードを MultiModel に設定して、Amazon SageMaker にすべてのモデルのアーティファクトを含む S3 フォルダーの場所を伝えます。
また、モデルが推論に使用するフレームワークイメージを示します。本記事では、前のステップで構築した XGBoost コンテナを使用しています。同じフレームワークで構築されたモデルを、そのフレームワーク向けに設定したマルチモデルエンドポイントでホストすることができます。モデルのエンティティ作成については、次のコードをご覧ください。
モデルの定義が設置されたら、作成したモデルのエンティティ名に戻って参照するエンドポイントの設定が必要になります以下のコードを参照してください。
最後に、以下のコードを使用してエンドポイントそのものを作成します。
マルチモデルエンドポイントを呼び出す
マルチモデルエンドポイントを起動するには、ターゲットモデルに起動を指示する新しいパラメータを 1 個渡すだけで済みます。以下のコード例は、boto3 を使用した予測リクエストです。
サンプルのノートブックでは、単一のエンドポイントの背後でホスティングされる複数のターゲットモデルに対して、ランダムな起動セットが反復されます。そのエンドポイントが必要に応じてターゲットモデルを動的にロードする様子を示します。次のように出力されます。
任意のモデルに対する最初のリクエストが完了するまでの時間では、そのモデルを S3 からダウンロードしてメモリにロードするレイテンシーが増加 (コールドスタートと呼ばれる) します。これに続く呼び出しがオーバーヘッドの追加もなく終了しますが、これはモデルのロードが完了済みだからです。
既存のエンドポイントに新しいモデルを動的に追加する
新しいモデルを既存のマルチモデルエンドポイントにデプロイするのは簡単です。エンドポイントの実行中に、モデルアーティファクトの新規セットをユーザーが先に設定したのと同じ S3 ロケーションにコピーします。次にクライアントアプリケーションがそのターゲットモデルから予測リクエストできるようになり、Amazon SageMaker が残りをハンドリングします。以下のサンプルコードにより、「New York」の新しいモデルを作成しました。今すぐにでも使用可能です。
マルチモデルエンドポイントを使用すると、新しいモデルを追加する際にエンドポイントをダウンロードすることがないため、この新しいモデル用に別のエンドポイントを作成するコストが発生しません。アクセスは S3 のコピーから可能です。
大量のモデル用にマルチモデルエンドポイントをスケーリングする
Amazon SageMaker のマルチモデルエンドポイントのメリットは、モデルを集約するとさらに増します。2 個のモデルをエンドポイント 1 個でホスティングすると、コスト削減になります。数百、数千のモデルを使用するユースケースでは、コスト削減効果は絶大です。
小型の XGBoost モデル 1,000 個のケースを考えてみましょう。そのままの状態では、各モデルを提供する ml.c5.large エンドポイント (4 GiB メモリ) には、us-east-1 でインスタンスあたり毎時 0.119 USD がかかります。1,000 個のモデルすべてを提供するエンドポイント全体のコストは、1 か月あたり 171,360 USD になります。Amazon SageMaker のマルチモデルエンドポイントを使用すると、ml.r5.2xlarge インスタンス (64 GiB メモリ) を使用する単一のエンドポイントで 1,000 モデルすべてをホスティングできます。この結果、本番環境の推論コストは 99% 削減されて、1 か月あたりわずか 1,017 USD になります。以下の表に、単一モデルエンドポイントとマルチモデルエンドポイントの違いをまとめました。この例では、90 パーセンタイルのレイテンシーは 7 ミリ秒 で変わらないことに注意してください。
| 単一モデル
エンドポイント |
マルチモデル
エンドポイント |
|
| 1 か月あたりのエンドポイント料金 | 171,360 USD | 1,017 USD |
| エンドポイントのインスタンスタイプ | ml.c5.large | ml.r5.2xlarge |
| メモリ容量 (GiB) | 4 | 64 |
| 1 時間あたりのエンドポイント料金 | 0.119 USD | 0.706 USD |
| エンドポイントあたりのインスタンス数 | 2 | 2 |
| 1,000 モデルに必要なエンドポイント数 | 1,000 | 1 |
| エンドポイントの 90 パーセンタイルのレイテンシー (ミリ秒) | 7 | 7 |
Amazon CloudWatch メトリクスを使用してマルチモデルエンドポイントをモニタリングする
価格とパフォーマンスのトレードオフを行うには、マルチモデルエンドポイントをテストする必要があります。Amazon SageMaker では、マルチモデルエンドポイント向けの CloudWatch に追加メトリクスを提供しているため、ユーザーはエンドポイント使用量やキャッシュヒット率を判断して、エンドポイントを最適化できます。以下に示すのが、そのメトリクスです。
- ModelLoadingWaitTime – ターゲットモデルがダウンロードされるまで待つ呼び出しリクエストの時間間隔、または推論実行用にロードされるまでの時間間隔。
- ModelUnloadingTime – コンテナの
UnloadModelAPI 呼び出しによるモデルのアンロードにかかる時間間隔。 - ModelDownloadingTime – S3 からモデルをダウンロードするのにかかる時間間隔
- ModelLoadingTime – コンテナの
LoadModelAPI 呼び出しによるモデルのロードにかかる時間間隔。 - ModelCacheHit – モデルがロード済みのエンドポイントに送信された
InvokeEndpointリクエスト数。Average の統計値を見れば、モデルがロード済みのリクエストの割合がわかります。 - LoadedModelCount – エンドポイントのコンテナにロードされたモデル数。このメトリクスはインスタンスごとに出力されます。1 分間の
Averageの統計値を見れば、ロード済みの平均モデル数がインスタンスごとにわかります。Sumの統計値を見れば、エンドポイント内のインスタンス全体のロード済みモデルの合計がわかります。このメトリクスが追跡するモデルは固有のものである必要はありません。これは、1 個のモデルをエンドポイント内の複数のコンテナにロードできるからです。
CloudWatch チャートを使用することで、インスタンスタイプ、インスタンス数、特定のエンドポイントがホストすべきモデル数の最適な選択における現行の決定に役立ちます。たとえば、以下のチャートでは、ロード済みのモデルが増加していく様子や、それに対応してキャッシュヒット率が増えていく様子を示しています。
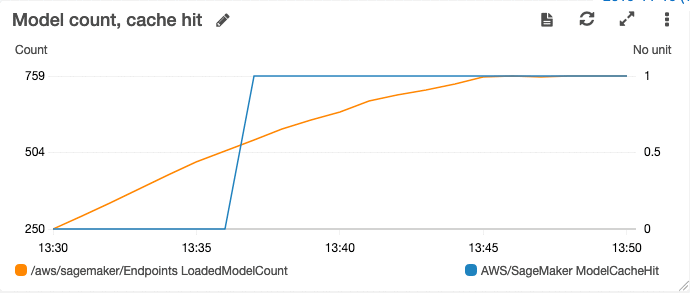
このケースでは、モデルがまったくロードされていないスタート時のキャッシュヒット率は 0 でした。ロード済みのモデル数が増えるにつれて、キャッシュヒット率は最終的に 100% まで上がりました。
エンドポイント設定をユースケースに合わせる
Amazon SageMaker エンドポイントの最適なエンドポイント設定 (特にインスタンスタイプとインスタンス数) を選択することは、ユーザーの具体的なユースケースの要件に大きく左右されます。マルチモデルエンドポイントでも、同じことが言えます。メモリに保持できるモデル数は、ユーザーのエンドポイント設定 (インスタンスタイプ、インスタンス数など)、モデルのプロフィール (モデルのサイズやレイテンシーなど)、トラフィックのパターンによって変わります。これらの要素すべてを考慮して、マルチモデルエンドポイントを構成してインスタンスを適切なサイズにする必要があり、エンドポイントの自動スケーリングも設定します。
Amazon SageMaker のマルチモデルエンドポイントでは、自動スケーリングをフルサポートしています。自動スケールイベントのトリガーに使用される呼び出し率は、エンドポイントが供給するモデル全体の予測数の総計に基づきます。
場合によっては、すべてのターゲットモデルをメモリに同時に保持できないインスタンスタイプを選択して、コストを下げることもできます。Amazon SageMaker では、メモリがなくなると新規のターゲットモデルを保持する場所をあけるために、モデルを動的にアンロードします。リクエスト頻度の低いモデルでは、動的なロードレイテンシーによって要件が維持されます。レイテンシーのニーズがもっと厳しいケースでは、さらに大型のインスタンスタイプを選ぶか、インスタンス数を増やします。事前に適切なパフォーマンスのテストや分析に時間をかければ、本番環境のデプロイで良い結果を生むことになり、かけた時間に見合うものがきわめて好ましい数字として返ってきます。
まとめ
Amazon SageMaker のマルチモデルエンドポイントは、可能な限りの最低価格でハイパフォーマンスな機械学習ソリューションの提供を支援しています。1 個の共有コンテナが提供できる単一のエンドポイントの背後に同じモデル群をバンドルすることで、推論コストが大幅に下がります。Amazon SageMaker ではまたマネージド型スポットトレーニングをご用意してトレーニングコスト面で同じように支援するとともに、深層学習ワークロード向けの Amazon Elastic Inference に対する統合サポートを提供しています。これらを追加して Amazon SageMaker がもたらす大幅な生産性向上につなげれば、ユーザーの機械学習チームの最終損益が上昇することになります。
この機会にぜひマルチモデルエンドポイントをお試しください。ご意見やご質問はコメント欄からお送りください。
著者について
機械学習スペシャリストソリューションアーキテクトである  Mark Roy は、大規模な Well-Architected 機械学習ソリューションの導入でお客様を支援しています。余暇には、Mark はバスケットボールをプレー、コーチ、フォローするのが好きです。
Mark Roy は、大規模な Well-Architected 機械学習ソリューションの導入でお客様を支援しています。余暇には、Mark はバスケットボールをプレー、コーチ、フォローするのが好きです。
 Urvashi Chowdhary は、Amazon SageMaker 担当のプリンシパルプロダクトマネージャーです。お客様に寄り添い、また、機械学習をさらに使いやすいものにしていくことに情熱を傾けています。余暇には、セーリング、パドルボード、カヤックを楽しんでいます。
Urvashi Chowdhary は、Amazon SageMaker 担当のプリンシパルプロダクトマネージャーです。お客様に寄り添い、また、機械学習をさらに使いやすいものにしていくことに情熱を傾けています。余暇には、セーリング、パドルボード、カヤックを楽しんでいます。