Amazon Web Services ブログ
Apache MXNet、AWS Lambda、Amazon Elastic Inference を使って深層学習を提供している Curalate 社
このブログは、Curalate のコンピュータビジョン研究技師 Jesse Brizzi 氏によるゲストブログ投稿です。
Curalate では、深層学習とコンピュータビジョンを使ってユーザー生成コンテンツ (UGC、user-generated content) を発見および活用し、インフルエンサーを活性化する新たな方法を日々考案しています。そうしたアプリケーションの中には、Intelligent Product Tagging のように、画像を可能な限りすばやく処理するために深層学習モデルを必要とするものがあります。他方で、深層学習モデルは、有用な信号を生成して顧客にコンテンツを提供するために、毎月何億という画像を取り込まなければなりません。
スタートアップである Curalate は、こうしたことのすべてを、高いパフォーマンスと費用対効果を維持しながら大規模に実行できる方法を見つけなければなりませんでした。当社は、自社の深層学習モデルをホストするために、AWS が提供すべきあらゆるタイプのクラウドインフラストラクチャを長年にわたって使用してきました。その過程で、深層学習モデルを本番稼働で大規模に提供することに関して多くのことを学びました。
この記事では、Curalate が深層学習のインフラストラクチャを設計する際に考慮している重要な要素、API/サービスタイプでそれらの要素がどのように優先付けされているのか、そして最も重要なこととして、さまざまな AWS 製品が結局のところいかにしてこうした要件を満たしているのかについて、解説していきます。
問題の概要
たとえば、手元にトレーニング済みの MXNet モデルがあり、それを AWS クラウドインフラストラクチャで提供しようと考えているとします。どのように構築を行いますか。また、どのようなソリューションやアーキテクチャを選択しますか。
Curalate は、こうした問題に答えを出すことに長年取り組んでいます。当社はスタートアップとして、新しいオプションが公開されたときはいつでも、すぐにそれを導入し、試す必要がありました。また、深層学習サービスを構築する際は自社のコードをロールします。そうすることで、管理を強化し、選択したプログラミング言語で作業することが可能になります。
この記事では、もっぱら深層学習サービスのハードウェアオプションに焦点をあてます。同じくモデル提供のソリューションをお探しの方は、Amazon SageMaker に利用可能なオプションがあります。
次に、私たちがいつも自問自答している問いの一部を紹介します。
- いま設計しているのはどんな種類のサービス/API なのか?
- それはユーザーが触れるものでリアルタイムなのか? あるいは、オフラインのデータパイプライン処理サービスなのか?
- 各 AWS ハードウェア提供オプションの違いは何か?
- パフォーマンス特性
- そのモデルを使うとどれくらいの速さで入力を実行できるか?
- 開発の容易さ
- サービスロジックの設計およびコード化の難易度はどの程度か?
- 安定性
- ハードウェアがサービスの安定性に及ぼす影響はどの程度か?
- 費用
- そのハードウェアオプションの費用対効果は他のオプションに比べ、どの程度優れているか?
- パフォーマンス特性
GPU ソリューション
GPU は最も確実なソリューションに見えるかもしれません。機械学習の分野における開発は、GPU の処理能力と切っても切り離せません。真の “深層” 学習が可能なのは、まずもって GPU があるからです。
GPU は、あらゆる深層学習サービスでその役割を果たしています。その速度は、ユーザーが触れるアプリケーションを駆動し、画像データのパイプラインを維持するのに十分です。
AWS は Amazon EC2 において、費用対効果に優れた g3s.xlarge インスタンスから、強力 (かつ高額) な p3dn.24xlarge インスタンスに至るまで、数多くの GPU ソリューションを提供しています。
| インスタンスタイプ | CPU メモリ | CPU コア | GPU | GPU タイプ | GPU メモリ | オンデマンド費用 |
| g3s.xlarge | 30.5 GiB | 4 基の vCPU | 1 | Tesla M60 | 8 GiB | 0.750 USD/時間 |
| p2.xlarge | 61.0 GiB | 4 基の vCPU | 1 | Tesla K80 | 12 GiB | 0.900 USD/時間 |
| g3.4xlarge | 122.0 GiB | 16 基の vCPU | 1 | Tesla M60 | 8 GiB | 1.140 USD/時間 |
| g3.8xlarge | 244.0 GiB | 32 基の vCPU | 2 | Tesla M60 | 16 GiB | 2.280 USD/時間 |
| p3.2xlarge | 61.0 GiB | 8 基の vCPU | 1 | Tesla V100 | 16 GiB | 3.060 USD/時間 |
| g3.16xlarge | 488.0 GiB | 64 基の vCPU | 4 | Tesla M60 | 32 GiB | 4.560 USD/時間 |
| p2.8xlarge | 488.0 GiB | 32 基の vCPU | 8 | Tesla K80 | 96 GiB | 7.200 USD/時間 |
| p3.8xlarge | 244.0 GiB | 32 基の vCPU | 4 | Tesla V100 | 64 GiB | 12.240 USD/時間 |
| p2.16xlarge | 768.0 GiB | 64 基の vCPU | 16 | Tesla K80 | 192 GiB | 14.400 USD/時間 |
| p3.16xlarge | 488.0 GiB | 64 基の vCPU | 8 | Tesla V100 | 128 GiB | 24.480 USD/時間 |
| p3dn.24xlarge | 768.0 GiB | 96 基の vCPU | 8 | Tesla V100 | 256 GiB | 31.212 USD/時間 |
2019 年 8 月現在*
選択可能な GPU、CPU、メモリリソースのオプションは豊富にあります。AWS ハードウェアの全オプションの中で、GPU は、入力あたりのモデル実行時間が最速で、大規模なモデルやバッチサイズを優にサポートできる十分な容量のメモリオプションを提供しています。たとえば、Nvidia V100 GPU を使用しているインスタンスではメモリを 32 GB にすることが可能です。
一方で、GPU は最も高額なオプションでもあります。最も安価な GPU でも、オンデマンドインスタンスの費用は月に 547 USD にのぼることもありえます。サービスをスケールアップすれば、これらの費用も上がります。最も小さな GPU インスタンスでも 1 個のユニットには多数のコンピューティングリソースが詰め込まれているので、結果として費用はより高額になります。EC2 の GPU には、マイクロやミディアム、あるいはラージのオプションすらありません。
そのため、リソースのスケーリングは非効率であるおそれがあります。新しく GPU インスタンスを追加すると、プロビジョニング不足で若干の遅れが生じたり、あるいは甚だしいオーバープロビジョニングでリソースが無駄になったりするおそれがあります。サービスに冗長性を与えるのも非効率なやり方です。2 つ以上のインスタンスを実行すれば、基本費用は 1,000 USD を超えます。たいていのサービス負荷では、この 2 つのインスタンスがフル稼働するようなことはおそらくないでしょう。
深層学習を基盤とするサービスを構築するときは、実行時間にかかる費用に加え、開発費用やさまざまな問題の発生が予想されます。自社のコードをロールし、MMS のようなモデルサーバーを使用しない場合は、受信する並列リクエストすべてからの GPU へのアクセスを、自分で管理しなければなりません。これは少々困難であるおそれがあります。なぜなら、GPU には一度にわずかな数のモデルしか適合しないからです。
そうした場合でも、複数のモデルを介して入力を同時に実行すると、パフォーマンスが最適ではなくなり、安定性の問題が発生するおそれがあります。実際、Curalate では、GPU 上のどのモデルにも一度に 1 つのリクエストしか送信しません。
また、当社はコンピュータビジョンモデルを使用しています。そのため、入力された画像のダウンロードと前処理に対処しなくてはなりません。1 秒間に何百という画像を受信するときは、メモリとリソース管理についての考慮事項をコードに組み込んで、サービスが圧倒されないようにすることが重要になります。
AWS で GPU をセットアップするのは、これまでに他のアプリケーションで Elastic Load Balancing、Auto Scaling グループ、あるいは EC2 インスタンスをセットアップした経験があれば、かなり簡単です。唯一の違いは、コードと MXNet で使用するために、必要な Nvidia CUDA と cuDNN ライブラリが AMI にインストールされているか確認する必要があることです。それを除けば、AWS への実装は他のクラウドサービスまたは API と同じです。
Amazon Elastic Inference アクセラレーターのソリューション
新しい Elastic Inference アクセラレーターは、一体どのようなものなのでしょうか。 これらは、EC2 または Amazon SageMaker のインスタンスにアタッチできる、GPU を搭載した低コストなアクセラレーターです。AWS は、Elastic Inference アクセラレーターを 4 GB から 1 GB までの GPU メモリ容量で提供しています。これは非常に優れた製品です。これらを使えば、専用の GPU インスタンスを使用する際の効率の悪さやスケーリングの問題を解消できます。
| アクセラレーターのタイプ | FP32 スループット (TFLOPS) | FP16 スループット (TFLOPS) | メモリ (GB) |
| eia1.medium | 1 | 8 | 1 |
| eia1.large | 2 | 16 | 2 |
| eia1.xlarge | 4 | 32 | 4 |
アプリケーションに最適な Elastic Inference アクセラレーターと、必要とされるコンピューティングリソースに最適な EC2 インスタンスとを、正確に組み合わせることができます。このような組み合わせによって、たとえば、1 GB GPU で小さなモデルを使用している大規模なサービスを、16 基の CPU コアを使ってホストすることが可能です。また、よりきめ細かくスケールしたり、サービスの極端なオーバープロビジョニングを防ぐことも可能になります。必要に応じてスケールすることで、c5.large と eia.medium インスタンスから成るクラスターは、g3s.xlarge インスタンスのクラスターよりもはるかに効率が良くなります。
Elastic Inference アクセラレーターを MXNet で使用するときは、現時点では、AWS と MXNet が発行した Python API または Scala API の閉じたフォークを使用する必要があります。これらのフォークと他の API 言語は、いずれは MXNet のオープンソースのマスターブランチに統合されます。お使いの MXNet モデルは、GPU または CPU のコンテキストのように、Elastic Inference アクセラレーターのコンテキストにロードすることが可能です。そのため、開発の過程は、GPU を搭載した EC2 インスタンスで深層学習サービス開発する過程と似たものになります。そこには同様の開発上の課題があり、また、コードベースとインフラストラクチャは、GPU を搭載したインスタンスと全体的にほぼ同じになるはずです。
この新しい Elastic Inference アクセラレーターと、選択した API 言語の MXNet EIA フォークへのアクセスのおかげで、Curalate は、GPU の使用をゼロにまで抑えることができました。これまで EC2 GPU インスタンスを使用していた自社のすべてのサービスを、eia.medium/large アクセラレーターと c5.large/xlarge EC2 インスタンスから成るさまざまな組み合わせへと移行させました。この変更は特定のサービスニーズに基づいて行われ、コードの変更はほとんど、あるいは一切必要ありませんでした。
インフラストラクチャのセットアップには多少の難しさが伴いました。Elastic Inference アクセラレーターは誕生したばかりのサービスなので、当社のクラウド管理ツールの中には十分適合できないものもあったからです。とはいえ、AWS マネジメントコンソールを熟知していれば、セットアップ時に遭遇しうる問題に対処してでも費用を削減する価値は十分にあります。変更後は、ホストの費用を、サービスに応じて 35~65% 削減できました。
モデルとサービスの全体的な処理レイテンシーは、以前使用していた EC2 GPU インスタンスと同じかそれ以上の速さです。新世代の C5 EC2 インスタンスにアクセスできるようになったので、ネットワークと CPU のパフォーマンスが大幅に向上しました。Elastic Inference アクセラレーター自体は、ネットワークを介して接続できる他の AWS のサービスと同様です。
ローカルの GPU ハードウェアに比べ、Elastic Inference アクセラレーターを使用した場合は、問題が発生したりオーバーヘッドがさらに増えたりするおそれはあります。とはいえ、安定性の向上は非常に有益であることが実証されていますし、それらは、他の AWS のサービスに期待する安定性と同等です。
AWS Lambda ソリューション
単一の AWS Lambda 関数には GPU がなく、ごくわずかなコンピューティングリソースしか持たないので、深層学習には向かないと考える方がいるかもしれません。たしかに、Lambda 関数は、AWS で深層学習モデルを実行する際に選択できる中で、最も低速なオプションです。しかし、サーバーレスのインフラストラクチャと一緒に使用すると多くのメリットがあります。
深層学習サービスのロジックを、1 つのリクエストに対する単一の Lambda 関数に分解してみると、問題がさらにシンプルになるだけでなく、パフォーマンスも向上します。モデルが受信する並列リクエストに必要とされる、リソース処理のことはすべて忘れて構いません。代わりに、単一の Lambda 関数は、深層学習モデルに関する自身のインスタンスをロードし、受信する単一の入力に備え、モデルの出力をコンピューティングして、結果を返します。
トラフィックが十分に高ければ、Lambda インスタンスは、次のリクエストでの再利用に備えて有効であり続けます。インスタンスを有効な状態に維持することで、モデルはメモリに保存されます。つまり、次のリクエストが行わねばならないのは、新しい入力の準備とコンピューティングだけです。これで手順は大幅に簡略化され、深層学習サービスを Lambda にデプロイする作業もさらに簡単になります。
パフォーマンスに関しては、各 Lambda 関数は、最大 3 GB のメモリと 1 基または 2 基の vCPU でしか機能しません。入力あたりのレイテンシーは GPU よりも遅くなりますが、ほとんどのアプリケーションで概ね許容範囲です。
Lambda が提供するパフォーマンス上の利点は、ユーザーが Lambda 関数に対して行える同時呼び出しの数に応じて広範囲に、自動でスケールできる点にあります。各リクエストは、常に、ほぼ同じ時間が必要になります。50、100、あるいは 500 という数の並列リクエストを行える場合 (すべて同じ時間で返る)、全体的なスループットは、最大の入力バッチがある GPU インスタンスをも優に超えます。
スケーリング上のこうした特性にも、効率的なコスト削減の特性と安定性が付随しています。Lambda はサーバーレスなので、支払いは、コンピューティング時間と実際に使用したリソースに対してのみ行えばよいだけです。使用しなかったリソースに対して無駄なお金を払うよう強制されることはありません。データパイプラインの処理費用は、予測されるサービスリクエストの数に基づいて正確に見積もることができます。
安定性に関していえば、関数を実行する並列インスタンスは、スケールアップやスケールダウンの際に頻繁に循環します。したがって、ネイティブライブラリの不安定性やメモリのリークなど何らかの事情でサービスが使用できなくなるおそれは、ほとんどありません。Lambda 関数インスタンスのいずれかがダウンしても、その負荷には、引き続き実行している他の多くのインスタンスが対応できます。
以上のような利点すべてにより、当社は Lambda を使って数多くの深層学習モデルをホストしてきました。ボリュームの低い当社のデータパイプラインサービスに非常に適しています。また、新しいモデルを新しいアプリケーションのベータ版で試すときにも最適です。ベータ版はサービストラフィックの要件が低いので、新しいサービスの開発費用を低く抑えられ、モデルのホスト費用はただ同然になっています。
費用のしきい値
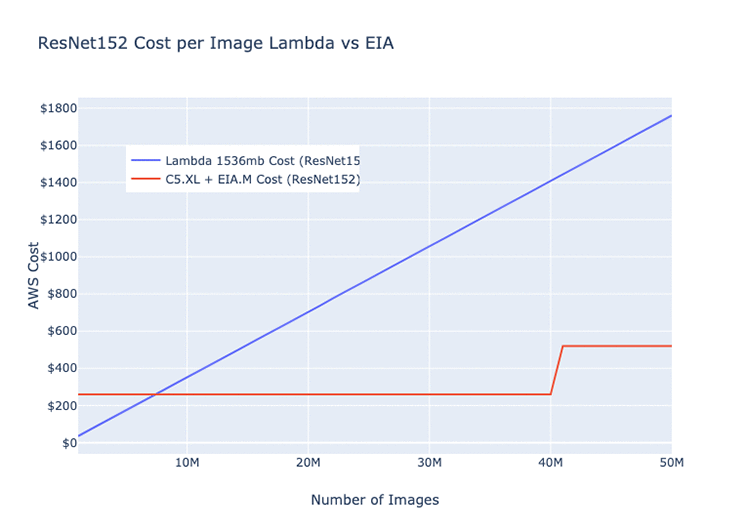
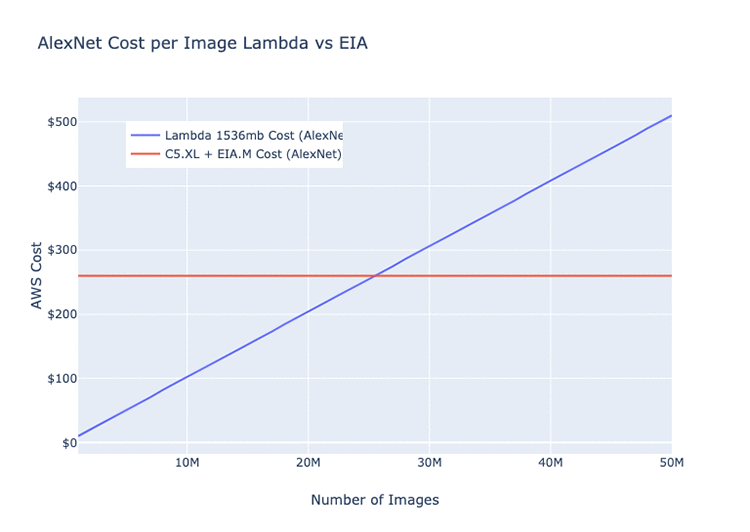
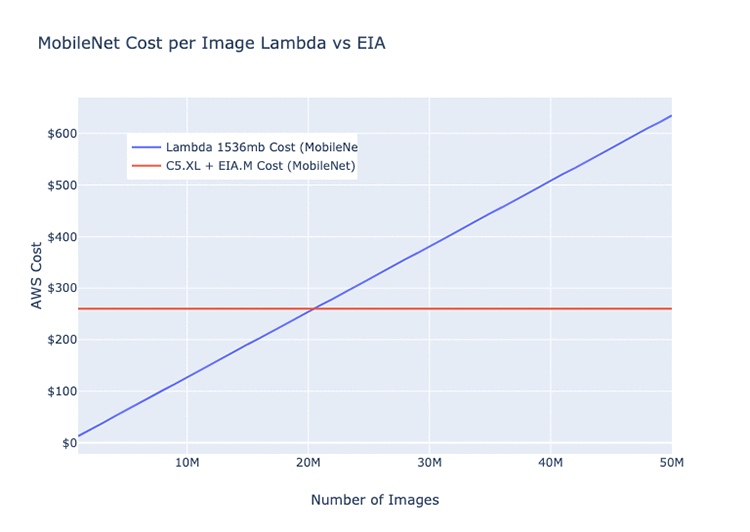
以下のグラフは、単一の Elastic Inference アクセラレーターがホストしているモデルを介した、画像の名目上の月間パフォーマンスを示したものです。平均実行時間と、Lambda における同じモデルの費用が含まれています (ResNet 152、AlexNet、MobileNet の各アーキテクチャ)。
このグラフをみると、Elastic Inference アクセラレーターよりも Lambda で実行する方が効率的である場合、および逆の場合の、大体の見当がつくはずです。以下の値はすべて、使用しているネットワークアーキテクチャによって変わります。
モデルの深度とパラメータの全体数における差異を考えると、特定のモデルアーキテクチャは、GPU か Lambda で実行したほうが、それ以外で実行するよりも効率的です。以下の 3 つの例はすべて、基本的な画像分類モデルです。EC2 インスタンスの予測される月々の費用は、c5.xlarge と eia.medium で 220.82 USD です。
例として挙げた ResNet152 モデルでは、交差しているポイントは月々 7,500,000 画像前後で、それを超えると、C5 と EIA を選択した方が費用対効果は高くなります。40,000,000 を超えると、需要に対応し、トラフィックのスパイクに対処するために、インスタンスがもう 1 つ必要になります。負荷が月全体にまんべんなく分散された場合、1 秒あたり 15 画像前後という割合になります。 できる限り安価に実行しようとしているものと仮定した場合、1 つのインスタンスがあれば、十分に余裕を持って、簡単に処理できますが、実際は、サービストラフィックが均一になることはめったにありません。
このタイプの負荷に対しては、現実的には、C5 と Elastic Inference アクセラレータークラスターが、2~6 のインスタンスのいずれかから自動的にスケールします。単一モデルにおける処理ストリームの現在の負荷に依存しますが、最大で月に 250,000,000 までの画像を処理します。
まとめ
Curalate では、AWS にある自社のすべての深層学習アプリケーションとサービスを駆動させるために、AWS Lambda と Elastic Inference アクセラレーターを組み合わせて使用しています。
当社の本番環境では、アプリケーションまたはサービスがユーザーが触れるもので、低いレイテンシーを必要とする場合、Elastic Inference アクセラレーターを備えた EC2 インスタンスを使ってそれらを駆動させています。ホスティングの費用は、GPU インスタンスに比べると、アクセラレーターを使用しているサービスに応じて 35~65 % 削減されました。
オフラインのデータパイプライン処理を行う場合は、まず、自社のモデルを Lambda 関数にデプロイします。トラフィックが特定のしきい値を下回っている場合や、何か新しいことを試そうとしているときにはこれがベストな方法です。その特定のデータパイプラインが一定のレベルに達した後で、私たちは、Elastic Inference アクセラレーターを備えた EC2 インスタンスのクラスターにモデルを戻したほうが、費用対効果がさらに上がることを発見します。これらのクラスターは、毎月、何億という深層学習モデルのリクエストのストリームを、スムーズかつ効率的に処理しています。
著者について
 Jesse Brizzi 氏は、Curalate のコンピュータビジョン研究技師です。機械学習に関する問題の解決や、それらの大規模な提供に注力しています。余暇には、パワーリフティング、ゲーム、交通機関のミーム、海外の McDonald’s のメニューを食べることなどを楽しんでいます。業務の詳細は www.jessebrizzi.com を参照してください。
Jesse Brizzi 氏は、Curalate のコンピュータビジョン研究技師です。機械学習に関する問題の解決や、それらの大規模な提供に注力しています。余暇には、パワーリフティング、ゲーム、交通機関のミーム、海外の McDonald’s のメニューを食べることなどを楽しんでいます。業務の詳細は www.jessebrizzi.com を参照してください。