Amazon Web Services ブログ
Amazon Kendra を使用して、よくある質問ボットをよりスマートに
製品やサービスを選択をするとき、私たちは質問が浮かんできます。職場の IT ヘルプデスクに最後に行ったときのことを思い出してください。 「IT ヘルプデスクはいつ開くか?」とか、「自分のノートパソコンを修理に出している間、代わりをものを使えるか?」などと考えたのではないでしょうか。 このような質問に対し迅速で正確な応答ができれば、顧客の満足度が向上します。サポートスタッフはこれらの質問に簡単に答えることができますが、効率的とは言えないでしょう。このような繰り返しの作業は、自動化に適しています。お客様は即座に応答を受け取り、サポートスタッフは問題の解決に集中できるからです。
このようなボットとの会話を可能にするには、各質問を個別のインテントとしてモデル化します。サンプルの発話はユーザーの質問を自然言語形式で取り込むように設計されており、ボットが応答して回答します。これは、質問が 2 つや 3 つの場合にはよいですが、質問の数が増えるとインテントの数も増え、ボットの定義が絶えず変化します。こうなると、ほとんどの応答が単なる静的テキストとなり、少々効率が悪くなる可能性があります。もう一つの方法は、質問のリストをデータベースに取り込み、データベースにクエリを実行して各質問に回答することです。これは、QnABot ボットが行うことと似ています。この設計では、すべての質問にインテントを追加する必要はありません。ただし、自然言語の入力がデータベースのエントリと異なる場合、検索は言語の変化に対応できるくらいスマートである必要があります。たとえば、「画面の修理にはどのくらい時間がかかりますか?」と「画面を修理する時間はどの程度ですか?」という質問に対して、同じ答えを提供する必要があります。
最近の Amazon Kendra のリリースでは、自然言語の質問を使って、よくある質問、ドキュメント内の回答、ドキュメント全体へのリンクなど、探している回答を取得できるようになりました。Amazon Kendra では、構造化されていないデータから特定の回答を抽出できます。Amazon Kendra をコンテンツにポイントするだけで、Amazon Kendra がコンテンツにインデックスを付けて回答します。Amazon Kendra コンソールまたは API を使用して、よくある質問やドキュメントにインデックスを付け、検索インデックスを作成できます。Amazon Kendra はインデックスを使って検索クエリに最も近い一致を見つけ、対応する回答を返します。
この投稿では、Amazon Lex チャットボットを Amazon Kendra と統合し、エンドユーザーが Slack などのメッセージングプラットフォームから Amazon Kendra にクエリできるようにする方法をご紹介します。 次の図は、このアイデアを示しています。

Amazon Lex チャットボットの構築
この記事では、ボットをモデリングするために、次のような会話を使用します。
ユーザー: IT ヘルプデスクはどこにありますか?
エージェント: 37 階の 201 号室 (エレベーターを降りて、右手 2 つ目の部屋) です。
ユーザー: 営業時間は?
エージェント: 午前 11 時から午後 2 時です。
ユーザー: 正午に訪ねてもいいですか?
エージェント: 大丈夫です。ご用件は何でしょうか?
ユーザー: ノートパソコンの画面にひびが入ってしまいました。
エージェント: 確認のために、従業員 ID の下 4 桁をいただけますか?
ユーザー: 1234 です。
エージェント: かしこまりました。故障部分を拝見しますので、おいでください。
ユーザー: 画面の修理は、どのくらい時間がかかりますか?
エージェント: ノートパソコンの画面の修理には、通常 4 時間かかります。
ユーザー: 画面の修理に何か必要なものはありますか?
エージェント: 従業員バッジ、ノートパソコン、VPN FOB をご用意ください。
ユーザー: ラノートパソコンを修理に出している間、ドキュメントにアクセスするにはどうすればよいですか?
エージェント: Amazon Workdocs を使ってドキュメントにアクセスできます。
ユーザー: タブレットから Amazon WorkDocs にアクセスできますか?
エージェント: こちらはドキュメントからの抜粋です。お役に立つかもしれません。(ドキュメントからの関連テキストを表示)
ユーザー: WorkDocs をもう一度使用するにはどうすればよいですか?
エージェント: いくつかドキュメントを見つけました。(関連するサポート文書のリストを表示)
ユーザー: 近くにコーヒーショップはありますか?
エージェント: 3 階にあります。毎日午前 8 時から午後 4 時まで営業しています。
まず最初に、インテント を持った Amazon Lexボットを構築し、予定を予約し、予定の状態を確認しますMakeAppointment インテントは、日付、時刻、従業員 ID、問題の性質など、予定を作成するために必要な情報を引き出します。CheckAppointmentStatus インテントは、予定の状態を提供します。 ユーザーが Lex ボットでこれらのインテントを使って回答できないような質問をした場合、ビルトインのフォールバックインテントを使用して Amazon Kendra に接続し、適切な回答を検索します。
Amazon Lex ボットサンプルのデプロイ
ボットのサンプルを作成するには、次の手順を実行します。 これで、help_desk_bot という Amazon Lex ボットと、help_desk_bot_handler という AWS Lambda 関数が作成されます。
- こちらから Amazon Lex のコードを、こちらから Lambda のコードをダウンロードしてください。
- AWS Lambda コンソールで、[関数を作成する] をクリックします。
- 関数名
help_desk_bot_handlerを入力します。 - 最新の Python ランタイム (Python 3.8 など) を選択します。
- アクセス許可については、[基本的な Lambda アクセス許可で新しいロールを作成する] を選択します。後でこのロールを更新し、Lambda 関数が Amazon Kendra にアクセスできるようにします。
- [関数を作成する] をクリックします。
- 新しいLambda関数が使用可能になったら、「関数コード」セクションで Upload a .zip file を、関数パッケージの場合はダウンロードした
help_desk_bot_lambda_handler.zipファイルを選択します。 - [保存する] をクリックします。
- Amazon Lex コンソールで、[アクション、インポート] をクリックします。
- ダウンロードした
help_desk_bot.zipファイルを選択し、[インポートする] をクリックします。 - Amazon Lex コンソールで、Lex ボット
help_desk_botを選択します。 - フォールバックインテント [help_desk_fallback] を含む各インテントについて、AWS Lambda 関数 (「フルフィルメント」セクションにある) を、ドロップダウンリストで
help_desk_bot_handler関数を選択します。 - 各インテントで、[Lambda 関数へのアクセス許可を追加する] ように求められます。[OK] をクリックします。

- すべてのインテントを更新したら、[構築する] をクリックします。
この時点で、Amazon Kendra にまだ接続されていない動作中の Amazon Lex ボットが作成されています。
Amazon Kendra インデックスの作成
これで、ドキュメントとよくある質問の Kendra インデックスを作成する準備ができました。Kendra インデックスを作成するには、以下の手順を実行します。
- Amazon Kendraコンソールで、[Amazon Kendra を起動する] をクリックします。
- 既存の Kendra インデックスがある場合は、[インデックスを作成する] をクリックします。
- 「it-helpdesk」などのインデックス名と、 「IT ヘルプデスクのドキュメントとよくある質問」などのオプションの説明を入力します。
- IAM ロールの場合、[新しいロールを作成する] を選択して、Amazon Kendra が CloudWatch Logs にアクセスできるようにするロールを作成します。
- [ロール名]に「cloudwatch logs」などの名前を入力します。
- [作成する] をクリックします。

Amazon Kendra が新しいインデックスを作成している間に、コンテンツを S3 バケットにアップロードします。
- Amazon S3 コンソールで、「kendra-it-helpdesk-docs-<account#>」などの新しいバケットを作成します。
- デフォルト設定を維持して、[バケットを作成する] をクリックします。
- 次のサンプルファイルをダウンロードし、S3 バケットにアップロードします。
新しい Kendra インデックスを作成したら、コンテンツを追加できます。
- Amazon Kendraコンソールで、[よくある質問]、[よくある質問を追加する] の順にクリックします。
- [よくある質問名] に、「it-helpdesk-faq」などの名前を入力します。
- [説明] に、「IT ヘルプデスク Lex ボット用よくある質問」などの説明をオプションで入力します。
- [S3] では、S3 を参照してバケットを見つけ、「help-desk-faq.csv」ファイルを選択します。
- [IAM ロール] で [新しいロールを作成する] をクリックして、Amazon Kendra が S3 バケットにアクセスできるようにします。
- [ロール名] で「s3-access」などの名前を入力し、[追加する] をクリックします。

- Amazon Kendra がよくある質問を作成している間、そのページに留まります。
- Amazon Kendra コンソールで [データソース] を選択し、S3 オプションで [コネクタを追加する] をクリックします。
- [データソース名] に「it-helpdesk-documents」などの名前を入力します。
- [説明] に「Kendra がインデックスを作成するための IT ヘルプデスクドキュメント」などの値を入力します。
- [次へ] をクリックします。
- [データソースの場所を入力する] で [S3 を参照する] をクリックし、S3 バケットを選択します。
- [IAM ロール] で [新しいロールを作成する] をクリックして、Amazon Kendra が S3 バケットにアクセスできるようにします。
- [ロール名]に「access-data-source」などの名前を入力します。
- [同期実行スケジュールを設定する] で、[オンデマンドで実行する] などのオプションを選択します。
- [次へ] 、[作成する] の順にクリックします。

- Kendra がデータソースを作成している間、そのページに留まります。
- データソースを作成したら、同期する必要があります。[今すぐ同期する] をクリックします。 新しいドキュメントを追加するときに、オンデマンドまたは特定のスケジュールでこれを実行できます。

データソースを同期したら、Kendra Search コンソールでいくつかの検索を試してみましょう。 例:
- ヘルプデスクはいつ開きますか?
- ヘルプデスクはいつ閉まりますか?
- ヘルプデスクはどこにありますか?
- 電話で WorkDocs にアクセスできますか?
Kendra インデックスが機能するようになったので、Amazon Lex ボットコードを Kendra インデックス ID で更新する必要があります。
- Amazon Kendra コンソールで、新しいインデックスに移動します。
- [インデックス ID] をコピーします。
- AWS Lambda コンソールで、
help_desk_bot_handler関数を選択します。 - [環境変数] で [編集する] をクリックし、[環境変数を追加] します。
- [キー] で「KENDRA_INDEX」と入力します。
- [値] で、コピーした Kendra インデックス ID を貼り付けます。
- [保存する] をクリックします。
最後に、Lambda 関数が Amazon Kendra にクエリを実行できるようにします。
help_desk_bot_handler関数の AWS Lambda コンソールで、[アクセス許可] タブをクリックします。
- [ロール名] の下に一覧表示されている IAM ロールをクリックします。
- [インラインポリシーを追加する] をクリックします。
- [サービス] ので「Kendra」を選択します。
- [読み込む] で「クエリする」をクリックします。
- [リソース] で [ARN を追加する] をクリックします。
- [リージョン] で [任意] をクリックします。
- [インデックス ID] で Kendra インデックス ID を貼り付けます。
- [追加する] をクリックします。
- [ポリシーを確認する] をクリックします。
- [名前] に「queryKendra」などを入力します。
- [ポリシーを作成する] をクリックします。
これで、Amazon Lex ボットは Amazon Kendra クエリを実行できるようになりました。 Amazon Lex コンソールでテストできます。
Slack チャネルへのデプロイ
最後に、ボットを Slack チャネルに接続します。
ボットとの Slack チャネルの関連付けを作成するには、次の手順を実行します。
- Amazon Lex コンソールで、[設定] をクリックします。Slack と統合するには、ボットのバージョンを公開する必要があります。
- [公開する] をクリックし、[エイリアスを作成する] フィールドに「test」などのエイリアス名を入力します。[公開する] をクリックします。
- エイリアスが公開されたら、[チャネル] をクリックします。
- [チャネル] の下で [Slack] をクリックします。
- 「slack_HelpDeskBot」などのチャネル名を入力します。
- [KMS キー] ドロップダウンで「aws/lex」を選択します。
- [「テスト」エイリアス] を選択します。
- Slack アプリケーションのクライエント ID、クライエントシークレット、検証トークンを提供します。
- [有効化する] をクリックして、OAuth URL とポストバック URL を生成します。
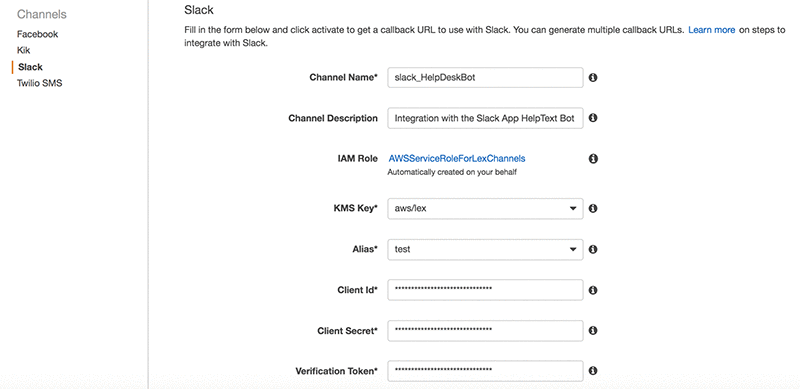
Slack アプリケーションのポータルで OAuth URL とポストバック URL を使って、統合を完了します。SlackアプリケーションのセットアップとAmazon Lexとの統合の詳細については、「Amazon Lex ボットと Slack との統合」をご参照ください。
Lambda 関数を使用して、Amazon Kendra から回答を取得する
ユーザーが質問をすると、ユーザーの入力が設定済みのどの Lex インテントとも一致しない場合、Lex ボットのフォールバックインテントがトリガーされます。フォールバックインテントのフルフィルメントコードを使用して、Kendra インデックスをクエリし、Amazon Kendra が次のような特定の回答を表示します。(1) よくある質問からの直接の回答 (2) インデックス付きドキュメントからの関連する抜粋、およびドキュメントへのリンク、または (3) ユーザーが選択できる関連ドキュメントのリスト。
以下は、このブログ投稿の Lambda 統合 Python コードで、Lex/Kendra の統合に使用できます。
Amazon Lex を使用すれば、Slack などの使い慣れたインターフェイスで操作できる、便利な自然言語のチャットエクスペリエンスを実現できます。 Amazon Lex では、トランザクション機能 (ヘルプデスクでのスケジューリングされた予定など) を含む、インテントを介した特定の種類の対話を編集できます。Amazon Lex を Amazon Kendra に統合することで、このエクスペリエンスを自然言語機能を追加し、よくある質問やドキュメントの既存のコンテンツに基づいてユーザーからの質問に回答できるようにすることが可能となります。 Amazon Kendra では、よくある質問からの直接的な回答、関連するドキュメントの抜粋、関連するドキュメントへのリンクを表示できます。

まとめ
この投稿では、Amazon Lex と Amazon Kendra を統合し、Slack などのメッセージングプラットフォームを介して受信したクエリに応答する方法をご紹介しました。Amazon Kendra では、自然言語を使用して直感的に検索することができ、また正確な回答を返すため、ユーザーは膨大な量のコンテンツ内に保存されている情報を見つけることができます。Amazon Kendra との統合によって、ボットの設計が簡素化し、自動会話にシームレスに適合する自然言語で回答できます。これらの手法をボットに組み込む方法の詳細については、Amazon Kendra のドキュメントをご参照ください。
著者について
 Brian Yost は、AWS プロフェッショナルサービスのシニアコンサルタントです。余暇には、マウンテンバイク、自家製ビール醸造、テクノロジーのティンカリングを楽しんでいます。
Brian Yost は、AWS プロフェッショナルサービスのシニアコンサルタントです。余暇には、マウンテンバイク、自家製ビール醸造、テクノロジーのティンカリングを楽しんでいます。
 Amazon Lex チームのプロダクトマネージャーの Harshal Pimpalkhute は、人がマシンを (うまく) 使えるようにするための方法について取り組んでいます。
Amazon Lex チームのプロダクトマネージャーの Harshal Pimpalkhute は、人がマシンを (うまく) 使えるようにするための方法について取り組んでいます。
 ソリューションアーキテクトの Niranjan Hira は、お客様が適切なビルディングブロックを組み立ててビジネス上の課題に対処する方法を常に考えています。暇があれば、物を壊して元に戻すことができるかどうかを試すことに熱中しています。
ソリューションアーキテクトの Niranjan Hira は、お客様が適切なビルディングブロックを組み立ててビジネス上の課題に対処する方法を常に考えています。暇があれば、物を壊して元に戻すことができるかどうかを試すことに熱中しています。