Amazon Web Services ブログ
Apache Flink と Amazon Kinesis Data Analytics を使用した ETL のストリーミング
ほとんどの企業は、リアルタイムで増え続ける量のデータを継続的に生成します。データは、ユーザーがモバイルゲームをプレイし、ロードバランサーがリクエストをログに記録し、顧客がウェブサイトで買い物をし、IoT センサーの温度が変化する場合に生成されます。このデータを迅速に分析することで、時間に敏感なイベントを活用し、顧客体験を向上させ、効率を高め、イノベーションを促進できます。多くの場合、これらの洞察を得る速度は、データレイク、データストア、およびその他の分析ツールにデータをロードできる速度に依存します。データの量と速度が増加するにつれて、着信データをロードするだけでなく、ほぼリアルタイムで変換および分析することも重要になります。
この記事では、洗練されたストリーミング抽出・変換・ロード (ETL) パイプラインの基礎として Apache Flink を使用する方法について説明します。Apache Flink は、データストリームを処理するためのフレームワークおよび分散処理エンジンです。AWS は、Amazon Kinesis Data Analytics を介して Apache Flink に完全マネージド型サービスを提供します。これにより、洗練されたストリーミングアプリケーションを迅速かつ簡単に、運用オーバーヘッドを抑えて、構築および実行できます。
この記事では、Apache Flink と Kinesis Data Analytics を使用して強力で柔軟なストリーミング ETL パイプラインを実装するために必要な概念について説明します。また、さまざまなソースとシンクのコード例を調べます。詳細については、GitHub リポジトリを参照してください。リポジトリには AWS CloudFormation テンプレートも含まれているため、数分で開始し、サンプルのストリーミング ETL パイプラインを調べることができます。
Apache Flink で ETL をストリーミングするためのアーキテクチャ
Apache Flink は、無限と有限のデータストリーム上のステートフルな計算のためのフレームワークおよび分散処理エンジンです。Apache Kafka、Amazon Kinesis Data Streams、Elasticsearch、Amazon Simple Storage Service (Amazon S3) のコネクタを含む、高度にカスタマイズ可能な幅広いコネクタをサポートしています。さらに、Apache Flink は、イベントを変換、集約、強化するための強力な API を提供し、1 回限りのセマンティクスをサポートします。したがって、Apache Flink は、ストリーミングアーキテクチャコアの優れた基盤です。
ストリーミング ETL パイプラインをデプロイして実行するために、アーキテクチャは Kinesis Data Analytics に依存しています。Kinesis Data Analytics を使用すると、完全マネージド環境で Flink アプリケーションを実行できます。サービスは、必要なインフラストラクチャをプロビジョニングおよび管理し、トラフィックパターンの変化に応じて Flink アプリケーションをスケーリングし、インフラストラクチャおよびアプリケーションの障害から自動的に回復します。Kinesis Data Analytics を使用して Flink アプリケーションをデプロイおよび実行することにより、ストリーミングデータを処理するための表現力豊かな Flink API とマネージドサービスの利点を組み合わせることができます。堅牢なストリーミング ETL パイプラインを構築し、プロビジョニングおよび運用インフラストラクチャの運用オーバーヘッドを削減できます。
この記事のアーキテクチャは、Kinesis Data Analytics で Apache Flink を実行する時に実現できる複数の機能を利用しています。具体的に、アーキテクチャは次をサポートします。
- プライベートネットワーク接続 – Amazon Virtual Private Cloud (Amazon VPC)、VPN 接続を使用するデータセンター、または VPC ピア接続を使用するリモートリージョンのリソースに接続します。
- 複数のソースとシンク – Kinesis データストリーム、Apache Kafka クラスター、Amazon Managed Streaming for Apache Kafka (Amazon MSK) クラスターからのデータの読み取りと書き込みです。
- データのパーティション分割 – イベントペイロードから抽出された情報に基づいて、Amazon S3 に取り込まれるデータのパーティション分割を決定します。
- 複数の Elasticsearch インデックスとカスタムドキュメント ID – 単一の入力ストリームから異なる Elasticsearch インデックスに広がり、ドキュメント ID を明示的に制御します。
- 1 回限りのセマンティクス – Apache Kafka、Amazon S3、Amazon Elasticsearch Service (Amazon ES) の間でデータを取り込んで配信する際の重複を避けます。
次の図は、このアーキテクチャを示しています。

この記事の残りの部分では、Apache Flink と Kinesis Data Analytics を使用してストリーミング ETL アーキテクチャを実装する方法について説明します。このアーキテクチャは、1 つまたは複数のソースから異なる送信先へのストリーミングデータを保持し、ニーズに合わせて拡張できます。この記事では、追加のフィルタリング、エンリッチメント、および集約変換については説明しませんが、実際のアプリケーションの自然な拡張にあたります。
この記事では、Kinesis Data Analytics を使用して Flink アプリケーションを構築、デプロイ、操作する方法を示しますが、これらの運用上の側面にさらに焦点を当てることはありません。コンパイル済みの Flink アプリケーション jar ファイルを Amazon S3 にアップロードし、サービスで追加の設定オプションを指定することで、Kinesis Data Analytics アプリケーションを作成できることを覚えておいてください。その後、完全マネージド環境で Kinesis Data Analytics アプリケーションを実行できます。詳細については、Apache Flink と Amazon Kinesis Data Analytics for Java アプリケーションを使用して、ストリーミングアプリケーションを構築、実行する、および Amazon Kinesis Data Analytics 開発者ガイドを参照してください。
AWS アカウントでストリーミング ETL パイプラインを調べる
実装の詳細と運用面を検討する前に、ストリーミング ETL パイプラインが実際に動作していることを確認する必要があります。必要なリソースを作成するには、次の AWS CloudFormation テンプレートをデプロイします。
![]()
このテンプレートは、Kinesis データストリームと Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを作成し、履歴データセットをデータストリームにリプレイします。この記事では、ニューヨーク市のタクシーとリムジン委員会から取得した公開データセットに基づいたデータを使用しています。各イベントは、ニューヨーク市で行われたタクシー旅行について説明し、旅行の開始と終了のタイムスタンプ、旅行の開始地点と終了地点の自治区に関する情報、および旅行の運賃に関するさまざまな詳細を含みます。Kinesis Data Analytics アプリケーションは、イベントを読み取り、イベントを Parquet 形式で Amazon S3 に保持し、イベント時間ごとにパーティション分割します。
以前に実行した CloudFromation テンプレートの出力セクションで ConnectToInstance の横にあるリンクをたどって、インスタンスに接続します。その後、次のコードを使用して、データストリームへの一連のタクシー旅行を再開できます。
AWS CloudFormation テンプレートの出力セクションから正しいパラメータでこのコマンドを取得できます。出力セクションでは、イベントが保持される S3 バケットと、パイプラインをモニタリングできる Amazon CloudWatch ダッシュボードも参照できます。
Apache Kafka と Elasticsearch など、残りのソースとシンクの組み合わせを有効にする方法については、GitHub リポジトリを参照してください。
Apache Flink を使用したストリーミング ETL パイプラインの構築
パイプラインの動作を確認したので、Apache Flink および Kinesis Data Analytics を使用して機能を実装する方法の技術的な面を調べることができます。
プライベートリソースの読み取りと書き込み
Kinesis Data Analytics アプリケーションは、パブリックインターネット上のリソースと VPC の一部であるプライベートサブネットのリソースにアクセスできます。デフォルトでは、Kinesis Data Analytics アプリケーションは、パブリックインターネット経由でアクセスできるリソースへのアクセスのみを有効にします。これは、Kinesis データストリームや Amazon Elasticsearch Service など、パブリックエンドポイントを提供するリソースに適しています。
リソースが VPC に対してプライベートである場合、技術的またはセキュリティ関連の理由により、Kinesis Data Analytics アプリケーションの VPC 接続を設定できます。たとえば、MSK クラスターはプライベートです。パブリックインターネットからはアクセスできません。パブリックインターネットに公開されていない、また VPN 接続を介して VPC からのみアクセス可能な、オンプレミスで独自の Apache Kafka クラスターを実行できます。リレーショナルデータベースや AWS PrivateLink を使用したエンドポイントなど、VPC にプライベートな他のリソースについても同様です。
VPC 接続を有効にするには、VPC のプライベートサブネットに接続するように Kinesis Data Analytics アプリケーションを設定します。Kinesis Data Analytics は、アプリケーションの並列性に応じて、アプリケーションの VPC 設定で提供される 1 つ以上のサブネットに Elastic Network Interface を作成します。詳細については、Amazon VPC のリソースにアクセスするための Java アプリケーション用 Kinesis Data Analytics の設定を参照してください。
次のスクリーンショットは、VPC 接続を備えた Kinesis Data Analytics アプリケーションの構成例を示しています。
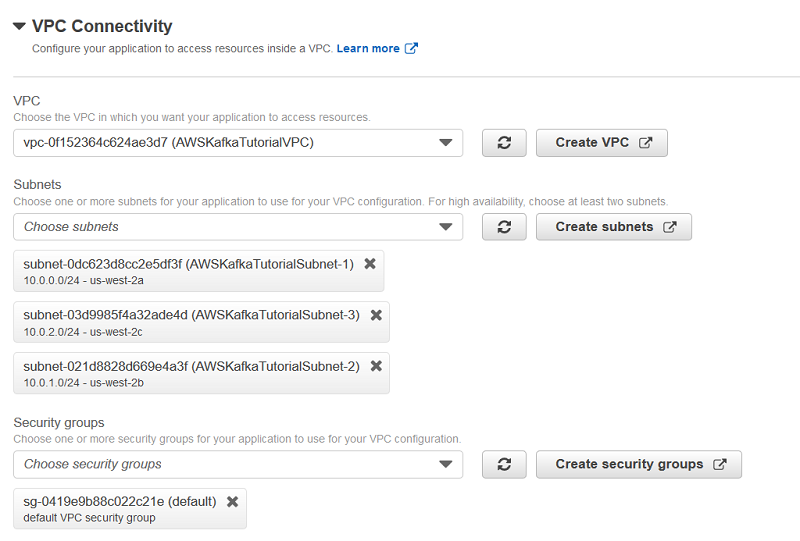
その後、アプリケーションは、構成されたサブネットからネットワーク接続されたリソースにアクセスできます。これには、これらのサブネットに直接含まれていないリソースが含まれ、VPN 接続または VPC ピアリングを介して到達できます。この構成は、それぞれのサブネット用に NAT ゲートウェイが構成されている場合、パブリックインターネット経由で利用可能なエンドポイントもサポートします。詳細については、VPC 接続の Kinesis Data Analytics for Java アプリケーションのインターネットおよびサービスアクセスを参照してください。
Kinesis および Kafka ソースの構成
Apache Flink は、Kinesis Data Streams や Apache Kafka などのさまざまなデータソースをサポートしています。詳細については、Apache Flink ウェブサイトのストリーミングコネクタを参照してください。
Kinesis データストリームに接続するには、最初にリージョンと認証情報プロバイダーを構成します。一般的なベストプラクティスとして、認証情報プロバイダーとして AUTO を選択します。その後、アプリケーションは、それぞれの Kinesis Data Analytics アプリケーションのロールからの一時的な認証情報を使用して、指定されたデータストリームからイベントを読み取ります。これにより、静的な認証情報がアプリケーションに組み込まれることを防ぎます。このコンテキストでは、データストリームからの 2 つの読み取り操作間の時間を増やすことも合理的です。デフォルトの 200 ミリ秒を 1 秒に増やすと、レイテンシーはわずかに増加しますが、複数のコンシューマーが同じデータストリームから読み取りやすくなります。次のコードを参照してください。
この構成は、ストリーム名と DeserializationSchema とともに FlinkKinesisConsumer に渡されます。この記事では、TripEventSchema を逆シリアル化に使用します。これは、Kinesis レコードを表すバイト配列を TripEvent オブジェクトに逆シリアル化する方法を指定します。次のコードを参照してください。
詳細については、GitHub の TripEventSchema.java および TripEvent.java を参照してください。Apache Flink は、データを文字列または JSON オブジェクトに逆シリアル化できる他の一般的なシリアライズを提供します。
Apache Flink は Kinesis データストリームからの読み取りに限定されません。Kinesis Data Analytics アプリケーションの VPC 設定を正しく構成すると、Apache Flink は Apache Kafka および MSK クラスターからイベントを読み取ることもできます。クラスターへの初期接続に使用するブローカーとポートのペアのコンマ区切りリストを指定します。この構成は、トピック名と DeserializationSchema とともに FlinkKafkaConsumer に渡され、Apache Kafka クラスターのそれぞれのトピックから読み取るソースを作成します。次のコードを参照してください。
結果の DataStream には、データストリームと Kafka トピックにそれぞれ取り込まれたデータから逆シリアル化された TripEvent オブジェクトが含まれます。その後、データストリームをシンクと組み合わせて使用して、イベントをそれぞれの送信先に保持できます。
データパーティション分割を使用した Amazon S3 でのデータの保持
ストリーミングデータを Amazon S3 に保持する場合、データをパーティション分割することができます。クエリに寄与できないパーティションは排除でき、読み取る必要がないため、データをパーティション分割することにより、分析ツールのクエリパフォーマンスを大幅に向上させることができます。たとえば、適切なパーティション分割戦略により、クエリで読み取るデータの量を減らすことで、Amazon Athena クエリのパフォーマンスとコストを改善できます。アプリケーションロジックとクエリパターンで使用されているのと同じ属性でデータをパーティション分割するように選択する必要があります。さらに、ストリーミングデータを処理して、パーティション分割戦略にイベントの時間 (イベント時間) を含めることは一般的です。これは、取り込み時間またはイベントが発生した時間をイベント時間ほど正確に反映しない他のサービス側のタイムスタンプを使用するのとは対照的です。
取り込み時間でパーティション化されたデータを取得し、Athena を使用してイベント時間で再パーティション分割する方法については、Amazon CloudFront アクセスログを大規模に分析するを参照してください。ただし、イベントのペイロードを使用してパーティション分割を決定することにより、Apache Flink を使用してイベント時間に基づいて受信データを直接パーティション分割できます。これにより、さらなる後処理手順を回避できます。この機能はデータのパーティション分割と呼ばれ、時間によるパーティション化に限定されません。
Apache Flink の StreamingFileSink と BucketAssigner を使用して、データのパーティション分割を実現できます。詳細については、Apache Flink ウェブサイトのストリーミングファイルシンクを参照してください。
特定のイベントが与えられると、BucketAssigner は文字列の形式で対応するパーティションプレフィックスを決定します。次のコードを参照してください。
シンクは、送信先パスとしての S3 バケットの引数と、TripEvent Java オブジェクトを文字列に変換する関数を取得します。次のコードを参照してください。
Amazon S3 に書き込むオブジェクトのサイズと、ローリングポリシーを使用してオブジェクトを作成する頻度をさらにカスタマイズできます。より多くのイベントをより少ないオブジェクトに集約するようにポリシーを設定して、レイテンシーを増加させるか、その逆を行うことができます。これにより、Amazon S3 上の多くの小規模オブジェクトを回避できます。これは、レイテンシーを増加させるための望ましいトレードオフになります。多数のオブジェクトは、Amazon S3 からデータを読み取るコンシューマーのクエリパフォーマンスに悪影響を与える可能性があります。詳細については、Apache Flink ウェブサイトの DefaultRollingPolicy を参照してください。
ローリングポリシーごとに S3 バケットに到着する出力ファイルの数は、StreamingFileSink の並列性と、Flink アプリケーション演算子間でイベントを配信する方法にも依存します。前の例では、Flink の内部 DataStream は、keyBy 演算子を使用してピックアップロケーション ID によってパーティション分割されています。ロケーション ID は、Amazon S3 に書き込まれるオブジェクトのプレフィックスの一部として BucketAssigner でも使用されます。そのため、同じノードが同じプレフィックスを持つすべてのイベントを集約および保持し、その結果、Amazon S3 で特に大きなオブジェクトが生成されます。
Apache Flink は、StreamingFileSink を使用して Amazon S3 に書き込む時に、内部でマルチパートアップロードを使用します。失敗した場合、Apache Flink は不完全なマルチパートアップロードをクリーンアップできない場合があります。不要なストレージ料金を回避するには、S3 バケットに適切なライフサイクルルールを設定して、不完全なマルチパートアップロードの自動クリーンアップを設定します。詳細については、Apache Flink ウェブサイトの S3 に関する重要な考慮事項および例 8: マルチパートアップロードを中止するライフサイクル設定を参照してください。
出力を Apache Parquet に変換する
Amazon S3 に配信する前にデータをパーティション分割することに加えて、カラムナストレージ形式で圧縮することもできます。Apache Parquet は、AWS エコシステムで十分にサポートされている一般的なカラムナ形式です。ストレージのフットプリントを削減し、クエリのパフォーマンスを大幅に向上させ、コストを削減できます。
StreamingFileSink は、ビルトイン BulkWriter ファクトリーを介して Apache Parquet およびその他のバルクエンコード形式をサポートします。次のコードを参照してください。
詳細については、Apache Flink ウェブサイトのバルクエンコード形式を参照してください。
Parquet 変換を使用する場合のイベント保持は少し異なります。Parquet 変換を有効にすると、OnCheckpointRollingPolicy を使用して StreamingFileSink を構成できます。これは、チェックポイントがトリガーされた場合にのみ、完成したパーツファイルを Amazon S3 にコミットします。Amazon S3 にデータを保持するには、Kinesis Data Analytics アプリケーションで Apache Flink チェックポイントを有効にする必要があります。チェックポイントがトリガーされたときにのみコンシューマーに表示されるため、配信レイテンシーはアプリケーションがチェックポイントを設定する頻度に依存します。
さらに、以前は Amazon S3 に書き込むデータの文字列表現を生成する必要がありました。対照的に、ParquetAvroWriters では、イベントに Apache Avro スキーマが必要です。詳細については、GitHub リポジトリを参照してください。サンプルが必要な場合は、リポジトリでスキーマを使用および拡張できます。
一般的に、保持されたデータを効果的に処理し、クエリする場合は、データを Parquet に変換することが大変望ましいです。さらに努力は必要ですが、変換の利点は、生データの保存と比較して、これらの追加の複雑さを上回ります。
複数の Elasticsearch インデックスとカスタムドキュメント ID への展開
Amazon ES は、Elasticsearch クラスターのデプロイ、セキュリティ保護、実行を簡単に行えるようにする完全マネージドサービスです。一般的なユースケースは、アプリケーションおよびネットワークログデータを Amazon S3 にストリーミングすることです。これらのログは Elasticsearch 用語のドキュメントであり、イベントごとに作成して Elasticsearch インデックスに保存できます。
Apache Flink が提供する Elasticsearch シンクは、柔軟で拡張可能です。各イベントのペイロードに基づいてインデックスを指定できます。これは、ストリームに異なるイベントタイプが含まれており、それぞれのドキュメントを異なる Elasticsearch インデックスに保存する場合に役立ちます。この機能を使用すると、単一のシンクとアプリケーションをそれぞれ使用して、複数のインデックスに書き込むことができます。新しい Elasticsearch バージョンでは、単一のインデックスに複数のタイプを含めることはできません。次のコードを参照してください。
ドキュメントを Elasticsearch に送信するときに、ドキュメント ID を明示的に設定することもできます。同じ ID のイベントが Elasticsearch に複数回取り込まれると、重複を作成せずに上書きされます。これにより、Elasticsearch への書き込みがべき等になります。このようにして、データソースが 1 回以上のセマンティクスを提供する場合でも、アーキテクチャ全体の 1 回限りのセマンティクスを取得できます。
上記で使用した AmazonElasticsearchSink は、Apache Flink に付属している Elasticsearch シンクの拡張です。シンクは IAM 認証情報でリクエストに署名するサポートを追加するため、サービスから利用できる強力な IAM ベースの認証と承認を使用できます。このため、シンクは、アプリケーションが実行されている Kinesis Data Analytics 環境から一時的な認証情報を取得します。署名バージョン 4 の方法を使用して、Elasticsearch エンドポイントに送信されるリクエストに認証情報を追加します。
1 回限りのセマンティクスの活用
べき等シンクと 1 回以上のセマンティクスを組み合わせることにより、1 回限りのセマンティクスを取得できますが、常に実行可能であるとは限りません。たとえば、Apache Kafka クラスターから別のクラスターにデータをレプリケートしたり、Apache Kafka から Amazon S3 にトランザクション CDC データを保持したりする場合、送信先での重複を許容できない可能性がありますが、これらのシンクはどちらもべき等ではありません。
Apache Flink は、1 回限りのセマンティクスをネイティブにサポートします。Kinesis Data Analytics は、チェックポイントに対して 1 回限りのモードを暗黙的に有効にします。エンドツーエンドの 1 回限りのセマンティクスを取得するには、Kinesis Data Analytics アプリケーションのチェックポイントを有効にし、StreamingFileSink などの 1 回限りのセマンティクスをサポートするコネクタを選択する必要があります。詳細については、Apache Flink ウェブサイトのデータソースとシンクの耐障害性保証を参照してください。
1 回限りのセマンティクスを使用する場合は、いくつかの副作用があります。たとえば、いくつかの理由でエンドツーエンドのレイテンシーが増加します。まず、チェックポイントがトリガーされた時にのみ出力をコミットできます。これは、Parquet 変換をオンにしたときに発生したレイテンシーの増加と同じです。デフォルトのチェックポイント間隔は 1 分ですが、短縮できます。ただし、このアプローチでは 1 秒未満の配信レイテンシーを取得することは困難です。
また、エンドツーエンドの 1 回限りのセマンティクスの詳細はとらえがたいです。Flink アプリケーションはデータストリームから 1 回だけ正確に読み取ることができますが、すでにストリームの一部が重複している可能性があるため、アプリケーション全体の 1 回以上のセマンティクスのみを取得できます。ソースおよびシンクとしての Apache Kafka には、異なる注意事項が適用されます。詳細については、Apache Flink ウェブサイトの注意事項を参照してください。
1 回限りのセマンティクスに強く依存する前に、アプリケーションスタック全体の詳細をすべて理解する必要があります。一般的に、アプリケーションが 1 回以上のセマンティクスを許容できる場合、不要な強力なセマンティクスに依存する代わりに、そのセマンティクスを使用することをお勧めします。
複数のソースとシンクを使用する
1 つの Flink アプリケーションは、複数のソースからデータを読み取り、データを複数の送信先に保持できます。これにはいくつかの理由があります。まず、データまたはデータの異なるサブセットを異なる送信先に保持できます。たとえば、同じアプリケーションを使用して、オンプレミスの Apache Kafka クラスターから MSK クラスターにすべてのイベントを複製できます。同時に、特定の貴重なイベントを Elasticsearch クラスターに配信できます。
次に、複数のシンクを使用して、アプリケーションの堅牢性を高めることができます。たとえば、フィルターを適用してストリーミングデータを強化するアプリケーションでも、生データストリームをアーカイブできます。より複雑なアプリケーションロジックで問題が発生した場合でも、Amazon S3 には生データが残っており、これを使用してシンクを埋めることができます。
ただし、いくつかのトレードオフがあります。単一のアプリケーションに多くの機能をバンドルすると、障害の影響範囲が広がります。アプリケーションの単一のコンポーネントに障害が発生した場合、アプリケーション全体に障害が発生するため、最後のチェックポイントから回復する必要があります。これにより、アプリケーションのすべての送信先へのダウンタイムと配信レイテンシーが増加します。また、単一の大規模なアプリケーションを維持しながら変更することは困難です。機能の追加と追加の Kinesis Data Analytics アプリケーションの作成の間でバランスをとる必要があります。
運用面
実稼働環境でアーキテクチャを実行すると、単一の Flink アプリケーションを継続的かつ無期限に実行するように設定されます。モニタリングと適切なアラームを実装して、パイプラインが期待どおりに機能し、処理が着信データに対応できることを確認してください。理想としては、パイプラインは、変化するスループット条件に適応し、ソースから送信先へのデータの配信に失敗した場合に通知を送信する必要があります。
一部の側面では、運用の観点から具体的な注意を傾ける必要があります。次のセクションでは、ストリーミング ETL パイプラインの堅牢性を高める方法に関するいくつかのアイデアと詳細リファレンスを提供します。
ソースのモニタリングとスケーリング
データストリームと MSK クラスターはそれぞれ、アーキテクチャ全体へのエントリポイントです。データプロデューサーを他のアーキテクチャから疎結合化します。多くの場合、直接制御できないデータプロデューサーへの影響を回避するには、アーキテクチャの入力ストリームを適切にスケーリングし、いつでもメッセージを取り込めるようにする必要があります。
Kinesis Data Streams は、シャードに基づいたスループットプロビジョニングモデルを使用します。各シャードは、特定の読み取りおよび書き込み容量を提供します。プロビジョニングされたシャードの数から、取り込みイベントと発行イベント、および 1 秒あたりのデータ量から、ストリームの最大スループットを導き出すことができます。詳細については、Kinesis Data Streams Quotas を参照してください。
Kinesis Data Streams は、CloudWatch を介してこれらの特性を報告し、ストリームのプロビジョニングが過剰か過少かを示すメトリックを公開します。IncomingBytes および IncomingRecords メトリックを使用してストリームを積極的にスケーリングするか、WriteProvisionedThroughputExceeded メトリックを使用してストリームを受動的にスケーリングできます。データ出力についても同様のメトリックが存在するため、これもモニタリングする必要があります。詳細については、Amazon CloudWatch を使用した Amazon Kinesis Data Streams のモニタリングを参照してください。
次のグラフは、サンプルアーキテクチャのデータストリームにこれらのメトリックの一部を示しています。Kinesis データストリームは、平均で毎分 280 万のイベントと 1.1 GB のデータを受信します。
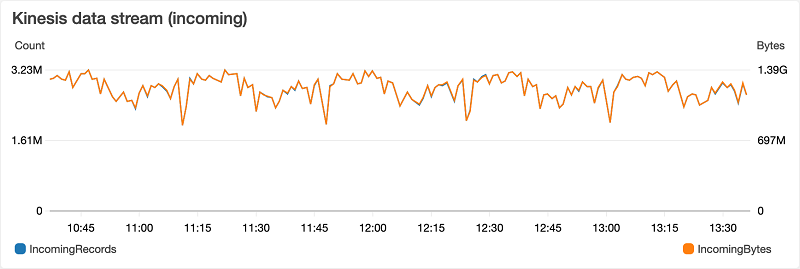
IncomingBytes および IncomingRecords メトリックを使用してストリームを積極的にスケーリングできますが、WriteProvisionedThroughputExceeded メトリックを使用してストリームを受動的にスケーリングできます。Kinesis Data Streams のスケーリングを自動化することもできます。詳細については、UpdateShardCount を使用した Amazon Kinesis Stream Capacity のスケーリングを参照してください。
Apache Kafka および Amazon MSK は、ノードベースのプロビジョニングモデルを使用します。Amazon MSK は、CloudWatch を通じて、クラスターに取り込まれたデータとイベントの量を示すメトリックなどのメトリックも公開します。詳細については、CloudWatch でモニタリングするための Amazon MSK メトリックを参照してください。
さらに、MSK クラスターの Prometheus でオープンモニタリングを有効にすることもできます。クラスターの総容量を知るのは少し難しいです。多くの場合、スケーリングのタイミングを知るためにベンチマークが必要です。モニタリングする重要なメトリックの詳細については、Confluent ウェブサイトの Kafka のモニタリングを参照してください。
Kinesis Data Analytics アプリケーションのモニタリングとスケーリング
Flink アプリケーションは、アーキテクチャのコアです。Kinesis Data Analytics はマネージド環境で実行します。ソースからデータを継続的に読み取り、データシンクにデータを保持するために遅れたり動けなくなることはありません。
アプリケーションが遅れる場合、適切にスケーリングされていないことを示します。アプリケーションの進行状況を追跡する 2 つの重要なメトリックは、millisBehindLastest (アプリケーションが Kinesis データストリームから読み取る場合) と records-lag-max (Apache Kafka および Amazon MSK から読み取る場合) です。これらのメトリックは、ソースからデータを読み取ることを示すだけでなく、データが十分に速く読み取られるかどうかも示します。これらのメトリックの値が継続的に増加している場合、アプリケーションは継続的に遅れます。これは、Kinesis Data Analytics アプリケーションをスケールアップする必要があることを示す可能性があります。詳細については、Kinesis Data Streams Connector のメトリックとアプリケーションメトリックを参照してください。
次のグラフは、この記事のサンプルアプリケーションのメトリックを示しています。チェックポイントの設定中に、最大 millisBehindLatest メトリックが最大 7 秒まで急上昇することがあります。ただし、報告されたメトリックの平均は 1 秒未満で、アプリケーションはすぐに再び最新ストリームに追いつくため、このアーキテクチャでは問題になりません。

アプリケーションの遅延はモニタリングする最も重要なメトリックの 1 つですが、Apache Flink と Kinesis Data Analytics が公開する他の関連メトリックもあります。詳細については、Apache Flink ウェブサイトの Apache Flink Applications 101 のモニタリングを参照してください。
シンクのモニタリング
シンクがシンクのタイプに応じてデータを受信し、ストレージが不足していないことを確認するには、シンクを注意深くモニタリングする必要があります。
S3 バケットの詳細メトリックを有効にして、バケットにアップロードされたリクエストとデータの数を 1 分単位で追跡できます。詳細については、Amazon CloudWatch を使用したメトリックのモニタリングを参照してください。次のグラフは、サンプルアーキテクチャの S3 バケットのこれらのメトリックを示しています。

アーキテクチャがデータを Kinesis データストリームまたは Kafka トピックに保持する場合、それはプロデューサーとして機能するため、ソースのモニタリングおよびスケーリングと同じ推奨事項が適用されます。実稼働環境でのサービス運用とモニタリングの詳細については、Amazon Elasticsearch Service のベストプラクティスを参照してください。
エラー処理
「障害は当然発生して、時間の経過とともにすべてが最終的に失敗します」ので、ある時点でアプリケーションが失敗することを予測する必要があります。たとえば、Kinesis Data Analytics が管理するインフラストラクチャの基になるノードに障害が発生するか、ネットワークの断続的なタイムアウトにより、アプリケーションがソースからの読み取りやシンクへの書き込みを行えなくなることがあります。これが発生すると、Kinesis Data Analytics はアプリケーションを再起動し、最新のチェックポイントから回復して処理を再開します。生イベントはデータストリームまたは Kafka トピックで保持されているため、アプリケーションは最後のチェックポイントと回復時のストリームで保持されたイベントを再読み取りして、標準処理を続行できます。
このタイプの障害はまれであり、アプリケーションは 1 回限りのセマンティクスを含む処理セマンティクスを犠牲にすることなく、回復できます。ただし、他の障害モードでは、さらなる注意と軽減が必要です。
イベントを解析するためのロジックを含むコンポーネントなど、アプリケーションコードのどこかに例外がスローされると、アプリケーション全体がクラッシュします。前と同様に、アプリケーションは最終的に回復しますが、特定のイベントが常にヒットするコードのバグから例外が生じた場合、無限ループになります。障害から回復した後、アプリケーションは以前に正常に処理されなかったため、イベントを再読み取りし、再度クラッシュします。プロセスは再び開始され、無期限に繰り返されます。これにより、アプリケーションの進行が効果的にブロックされます。
したがって、アプリケーションのクラッシュを防ぐために、アプリケーションコードで例外をとらえて処理する必要があります。プログラムで解決できない問題がある場合は、サイド出力を使用して、問題のある生イベントをセカンダリデータストリームにリダイレクトできます。後で検査するために配信不能キューまたは S3 バケットに保持できます。詳細については、Apache Flink ウェブサイトのサイド出力を参照してください。
アプリケーションがスタックして進行できない場合は、少なくともアプリケーションラグのメトリックに表示されます。ストリーミング ETL パイプラインがイベントをフィルタリングまたは強化する場合、障害ははるかに捉えづらく、それらが取り込まれた後に気付く場合があります。たとえば、アプリケーションのバグにより、重要なイベントを誤ってドロップしたり、意図しない方法でペイロードを破損したりする可能性があります。Kinesis データストリームはイベントを最大 7 日間保存します。技術的には可能なことですが、Apache Kafka はイベントを無期限に保存するように設定されていないこともあります。破損を迅速に特定しないと、生イベントの保持期限が切れたときに情報を失うリスクがあります。
このシナリオから保護するには、追加の変換または処理を適用する前に、生イベントを Amazon S3 に保持できます。生イベントを保持し、必要に応じてストリームに再処理するか、再生できます。機能をアプリケーションに統合するには、Amazon S3 に書き込むだけの 2 番目のシンクを追加します。または、ストリームから生イベントのみを読み取り、保持する別のアプリケーションを使用します。ただし、追加のアプリケーションを実行して料金を支払う必要があります。
選択タイミング
AWS は、ストリーミングデータを処理し、ストリーミング ETL を実行できる多くのサービスを提供します。Amazon Kinesis Data Firehose は、サポートされているさまざまな送信先にストリーミングデータを取り込み、処理し、保持できます。この記事の Kinesis Data Firehose とソリューションの機能にはかなりの重複がありますが、どちらか一方を使用する理由は色々あります。
大ざっぱなやり方ですが、要件に適合する場合は Kinesis Data Firehose を使用してください。このサービスは、シンプルさと使いやすさを考慮して構築されています。サービスを設定するだけで Kinesis Data Firehose を使用できます。Kinesis Data Firehose を使用すると、コード、サーバー、継続的な管理なしでストリーミング ETL のユースケースを使用できます。さらに、Kinesis Data Firehose には多くの組み込み機能が備わっており、その料金モデルでは、処理されたデータと配信されたデータに対してのみお支払いいただきます。Kinesis Data Firehose にデータを取り込まない場合、サービス料金は発生しません。
対照的に、この記事のソリューションでは、Flink アプリケーションを作成、ビルド、デプロイする必要があります。さらに、インフラストラクチャの障害に対して耐性があるだけでなく、アプリケーションの障害やバグに対しても耐性がある堅牢なアーキテクチャをモニタリングする方法について検討する必要があります。ただし、この複雑さが増したことにより、ユースケースで必須になるかも知れない多くの高度な機能のロックが解除されます。詳細については、Apache Flink と Amazon Kinesis Data Analytics for Java アプリケーションを使用して、ストリーミングアプリケーションを構築、実行する、および Amazon Kinesis Data Analytics 開発者ガイドを参照してください。
最新情報
この記事では、Apache Flink と Kinesis Data Analytics を使用してストリーミング ETL パイプラインを構築する方法について説明しました。運用オーバーヘッドを低く抑えながら、ストリーミング取り込みの高度なユースケースに対応する拡張可能なソリューションの構築方法に焦点を当てました。このソリューションにより、追加の ETL 手順を必要とせずに、ストリーミングデータをデータレイク、データストア、または別の分析ツールにすばやく追加、変換、ロードできます。この記事では、モニタリングとエラー処理を使用してアプリケーションを拡張する方法も検討しました。
これで、AWS でストリーミング ETL パイプラインを構築する方法を十分に理解できるはずです。消費者が貴重な情報にすばやくアクセスできるようにするストリーミング ETL パイプラインを使用することで、時間に敏感なイベントを活用できます。従来のバッチベースの ETL プロセスの大幅なレイテンシーを追加することなく、ユースケースに合わせてこの情報の形式と形状を調整できます。
著者について
 Steffen Hausmann は、AWS のスペシャリストソリューションアーキテクトです。彼は世界中の顧客と協力してストリーミングアーキテクチャを設計および構築し、ストリーミングデータの分析から価値を得ています。彼はミュンヘン大学でコンピュータサイエンスの博士号を取得しています。自由時間には、会議で集めたかわいいステッカーを使って娘をハイテクに誘い込もうとしています。彼の絶え間ない努力を Twitter (@sthmmm) でフォローできます。
Steffen Hausmann は、AWS のスペシャリストソリューションアーキテクトです。彼は世界中の顧客と協力してストリーミングアーキテクチャを設計および構築し、ストリーミングデータの分析から価値を得ています。彼はミュンヘン大学でコンピュータサイエンスの博士号を取得しています。自由時間には、会議で集めたかわいいステッカーを使って娘をハイテクに誘い込もうとしています。彼の絶え間ない努力を Twitter (@sthmmm) でフォローできます。