Amazon Web Services ブログ
LLAPを使用してAmazon EMRでのApache Hiveクエリをターボチャージ!
Apache Hiveは、SQLを使用してHadoopクラスタに格納された大規模なデータセットを分析するための最も一般的なツールの1つです。データアナリストやデータサイエンティストは、大きなデータのクエリ、要約、探索、および分析にHiveを使用します。
Hive LLAP(Low Latency Analytical Processing)の導入により、Hiveが単なるバッチ処理ツールであるという考え方が変わりました。 LLAPは、インテリジェントなインメモリキャッシュを使用して長期実行デーモンを使用し、バッチ指向のレイテンシを覆し、1秒未満のクエリ応答時間を提供します。
この記事では、Hive LLAPのアーキテクチャと、クエリパフォーマンスを向上させるための一般的な使用例など、Hive LLAPの概要を示します。 Amazon EMRクラスタにHive LLAPをインストールして設定し、LLAPデーモンでクエリを実行する方法を学習します。
Hive LLAPとは何か?
Hive LLAPは、Apache Hive 2.0で導入されました。これは、非常に高速なクエリ処理を提供します。これは、Apache Sliderを使用してHadoop YARNクラスタにデプロイされる永続デーモンを使用します。これらのデーモンは長時間実行されており、データノードのI/O、メモリ内キャッシュ、クエリ処理、きめ細かなアクセス制御などの機能を提供します。また、デーモンは常にクラスタ内で実行されているため、新しいHiveセッションごとに新しいYARNコンテナを起動するためのオーバーヘッドが大幅に削減されるため、起動時間が長くかかりません。
Hiveがハイブリッド実行モードで構成されている場合、小さく短いクエリはLLAPデーモンで直接実行されます。アプリケーションに属するYARNコンテナで重いクエリ(Reduceステージでの大きなシャッフルなど)が実行されます。リソース(CPU、メモリなど)は、YARNを使用して従来の方法で取得されます。リソースが取得されると、実行エンジンはどのリソースをLLAPに割り当てるかを決定したり、Apache Tezプロセッサを別々のYARNコンテナで起動したりすることができます。また、小さなデータセットを非常に高速にクエリするために、LLAPデーモン上のすべての処理ワークロードを実行するようにHiveを設定することもできます。
LLAPデーモンはYARN管理下で起動され、ノードがこれらのデーモンの計算リソースで過負荷にならないようにします。スケジューリングキューを使用して、他のYARNアプリケーションを実行するのに十分な計算能力があることを確認できます。
なぜHive LLAPを使うのか?
市場に入手可能な多くのオプション(Presto、Spark SQLなど)がありますが、Amazon S3とHDFSに格納されているデータに対してインタラクティブなSQLを実行するために、HiveとLLAPを使用することが良い選択になる理由はいくつかあります。
- Hiveエコシステムに多額の投資をしており、JDBC/ODBC接続を介してHiveに接続する外部BIツールを持つ人にとっては、険しい学習曲線なしに既存のアーキテクチャにLLAPをプラグインできます。
- 既存のHive SQLやHiveServer2などの他のHiveツール、およびHive用のJDBCドライバと互換性があります。
- HiveServer2を使用した認証と認可(SQL標準ベースの認可)によるセキュリティ機能のネイティブサポートを備えています。
- LLAPデーモンは、処理中の列とレコードに対して、きめ細かなアクセス制御を実行できます。
- Hiveのベクトル化機能を使用してクエリを高速化することができ、ベクトル化が有効な場合、HiveはParquetファイル形式をよりよくサポートします。
- クエリ結果のために複数の小さなファイルをマージする、結合やグループ化のためのReducerの数を自動的に決定するなど、多数のHive最適化を利用できます。
- オプションでモジュール式なので、クラスタのコンピューティングとリソースの要件に応じてオンまたはオフにすることができます。これにより、LLAP専用のクラスタを別途用意せずに、他のYARNアプリケーションを同時に実行することができます。
Hive LLAPをAmazon EMRにどのようにインストールするのか?
EMRクラスタにLLAPをインストールして設定するには、次のブートストラップアクション(BA)を使用します。
このBAは、Apache Sliderをクラスタにダウンロードしてインストールし、LLAPを構成してEMR Hiveと連携するようにします。 LLAPが機能するには、EMRクラスタにHive、Tez、Apache Zookeeperがインストールされている必要があります。
以下の引数をBAに渡すことができます。
| 引数 | 定義 | デフォルト値 |
| --instances | LLAPデーモンのインスタンスの数 | クラスタのCore/Taskノードの数 |
| --cache | インスタンス毎のキャッシュサイズ | ノードの物理メモリの20% |
| --executors | インスタンス毎のエグゼキューターの数 | ノードのCPUコアの数 |
| --iothreads | インスタンス毎のI/Oスレッドの数 | ノードのCPUコアの数 |
| --size | インスタンス毎のコンテナの数 | ノードの物理メモリの50% |
| --xmx | ワーキングメモリのサイズ | コンテナのサイズの50% |
| --log-level | LLAPインスタンスのログレベル | INFO |
LLAPの例
このセクションでは、Hive for Amazon EMRのTPC-DSテストベンチを使用して、LLAPを使用してより高速なHiveクエリを試す方法について説明します。
次のAWSコマンドラインインターフェイス(AWS CLI)コマンドを使用して、ブートストラップアクションを使用して1 + 3ノードm4.xlarge EMR 5.6.0クラスタを起動し、LLAPをインストールします。
クラスタの起動後、SSHを使用してマスターノードにログインし、次の操作を行います。
-
- hive-tpcdsフォルダを開きます。
-
- テストベンチ設定を使用してHive CLIを起動し、必要なテーブルを作成し、サンプルクエリを実行します。このサンプルクエリは、Amazon S3に格納されている40GBのデータセットで実行されます。データセットは、Hive用のTPC-DSテストベンチのデータ生成ツールを使用して生成され、次のような出力が得られます。

-
- このスクリーンショットは、クエリーがLLAPモードで約47秒で終了したことを示しています。これをLLAPのない実行時間と比較するために、Tezコンテナのみを使用して同じワークロードを実行することができます。
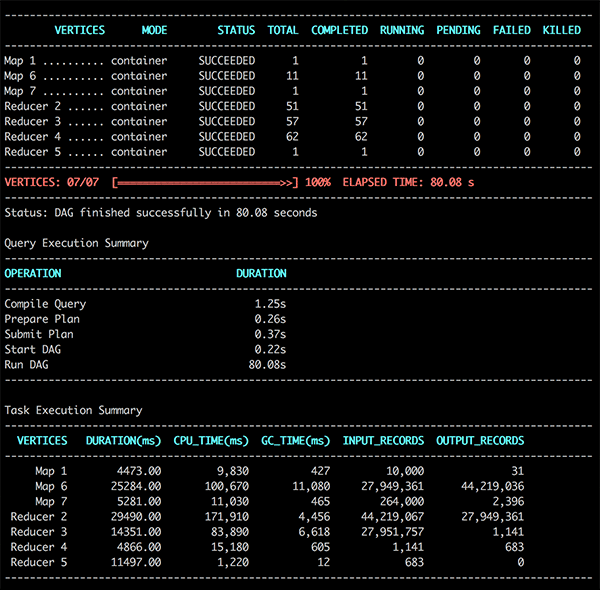
このクエリは約80秒で終了しました。
LLAPデーモンでクエリを実行するのとは対照的に、YARNコンテナのみを使用した場合、クエリの実行時間の差は約1.7倍になります。また、クエリが再実行されるたびに、LLAPデーモンによるメモリ内キャッシングによって実行時間が大幅に短縮されることがわかります。
結論
この記事では、Hiveのクエリパフォーマンスを向上させる方法としてHive LLAPを紹介しました。そのアーキテクチャに触れ、コンポーネントのいくつかのユースケースを説明しました。 Amazon EMRクラスタでHive LLAPをインストールして設定する方法と、LLAPデーモンでクエリを実行する方法を示しました。
Amazon EMRでのHive LLAPの使用に関してご質問がある場合、またはユースケースを共有したい場合は、ぜひコメントをお寄せください。
追加の読み物
AWSでHive外部テーブルを自動的に分割する方法を学びます。
原文:Turbocharge your Apache Hive Queries on Amazon EMR using LLAP(翻訳:半場光晴)