- AWS Builder Center
- builders.flash
生成 AI アプリケーション開発をもっと身近に、簡単に ! Amazon Bedrock をグラレコで解説
2024-05-01 | Author : 米倉 裕基 (監修 : 呉 和仁, 本橋 和貴, 前川 泰毅)
はじめに
builders.flash 読者のみなさん、こんにちは! テクニカルライターの米倉裕基と申します。
本記事では、AWS が提供する生成 AI サービス Amazon Bedrock の機能と特徴について紹介します。
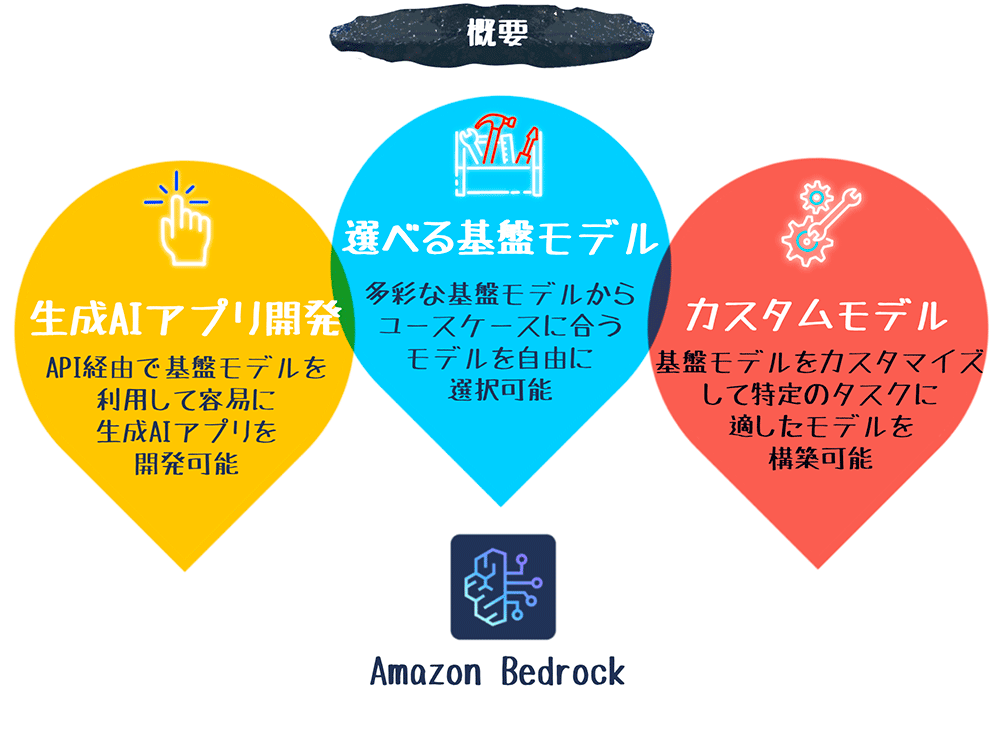
Amazon Bedrock は、Amazon をはじめ、AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI といった代表的な AI 関連企業が提供する高性能な基盤モデル (Foundation Model:FM) を、単一の API を通じて操作可能にするフルマネージド生成 AI サービスです。基盤モデルとは、大規模なデータセットで事前学習された大規模言語モデルのことで、Amazon Bedrock ではチャット機能、テキスト生成、画像生成などに最適化された多彩な基盤モデルをプリセットとして提供しています。開発者はこれらのモデルから自身のプロジェクトに最適なものを選択し、簡単にアプリケーションに生成 AI 機能を統合できます。
さらに、Amazon Bedrock が提供する事前学習済みの基盤モデルをベースに、ユーザー独自のデータを用いてトレーニングを行うことで、コストと時間を節約しながら目的の性能を実現するカスタマイズが可能です。また、複数のタスクを段階的に実行して柔軟な応答を実現したり、外部のデータセットを参照してモデルに含まれない最新情報を応答するなど、基盤モデルの機能を拡張する仕組みも備えています。
本記事では、Amazon Bedrock の主な機能と特徴を以下の項目に分けて説明します。
-
Amazon Bedrock とは
-
主要なユースケース
-
多彩な基盤モデル
-
モデルの運用と連携
-
カスタムモデルの構築
-
マルチステップタスクの設定
-
責任ある AI とセキュリティ
-
Amazon Bedrock の料金体系
それでは、項目ごとに詳しく見ていきましょう。
builders.flash メールメンバー登録
Amazon Bedrock とは
生成 AI の可能性と課題
従来の AI が特定のタスクの自動化や予測に重点を置いていたのに対し、生成 AI はテキストや画像、音声など、創造的なコンテンツを生成することを目的としています。生成 AI の高い創造性により幅広い応用が期待されている一方、この新しい技術を実際に構築しサービスとして統合するには多くの困難と課題があります。
-
大規模なデータソース:
生成 AI モデルを構築するには、膨大な量のデータソースが必要であり、これらのデータの収集や処理には多大な時間と労力がかかります。 -
高度な専門性:
独自に生成 AI モデルを構築し、アプリケーションに統合するためには、高度な専門知識が必要になります。 -
ハードウェアリソースとコスト:
高性能な GPU などの計算リソースや大規模なストレージが必要となり、これらのリソースを維持するためのコストも考慮する必要があります。
Amazon Bedrock が提供するソリューション
これらの生成 AI 開発が抱える課題を解決するために、Amazon Bedrock は以下のような生成 AI 開発のための包括的なソリューションを提供します。
-
多様な事前学習済み基盤モデル:
Amazon Bedrock は、Amazon や主要な AI 関連企業が開発した多様な事前学習済み基盤モデルを提供しています。ユーザーは自身で大規模なデータ収集やトレーニングを行わなくても、高性能な生成 AI を利用できます。 -
柔軟で使いやすい AWS マネジメントコンソールや API:
Amazon Bedrock では、基盤モデルのカスタマイズや評価、アプリケーションへの統合を、専門知識を持たなくても行えるようにしています。直感的な GUI を備えたコンソールや柔軟な API を使って、容易に生成 AI アプリケーションを開発できます。 -
フルマネージド型のサーバーレスアーキテクチャ:
Amazon Bedrock はフルマネージド型のサーバーレスサービスであり、ユーザーは高性能なコンピューティングリソースやストレージを自身で用意する必要がありません。モデル推論やトレーニングで利用したリソース分のみ従量課金で料金が発生するため、コストを削減できます。
Amazon Bedrock の概要について詳しくは、「Amazon Bedrock とは」をご覧ください。
主要なユースケース
生成 AI の一般的なユースケース
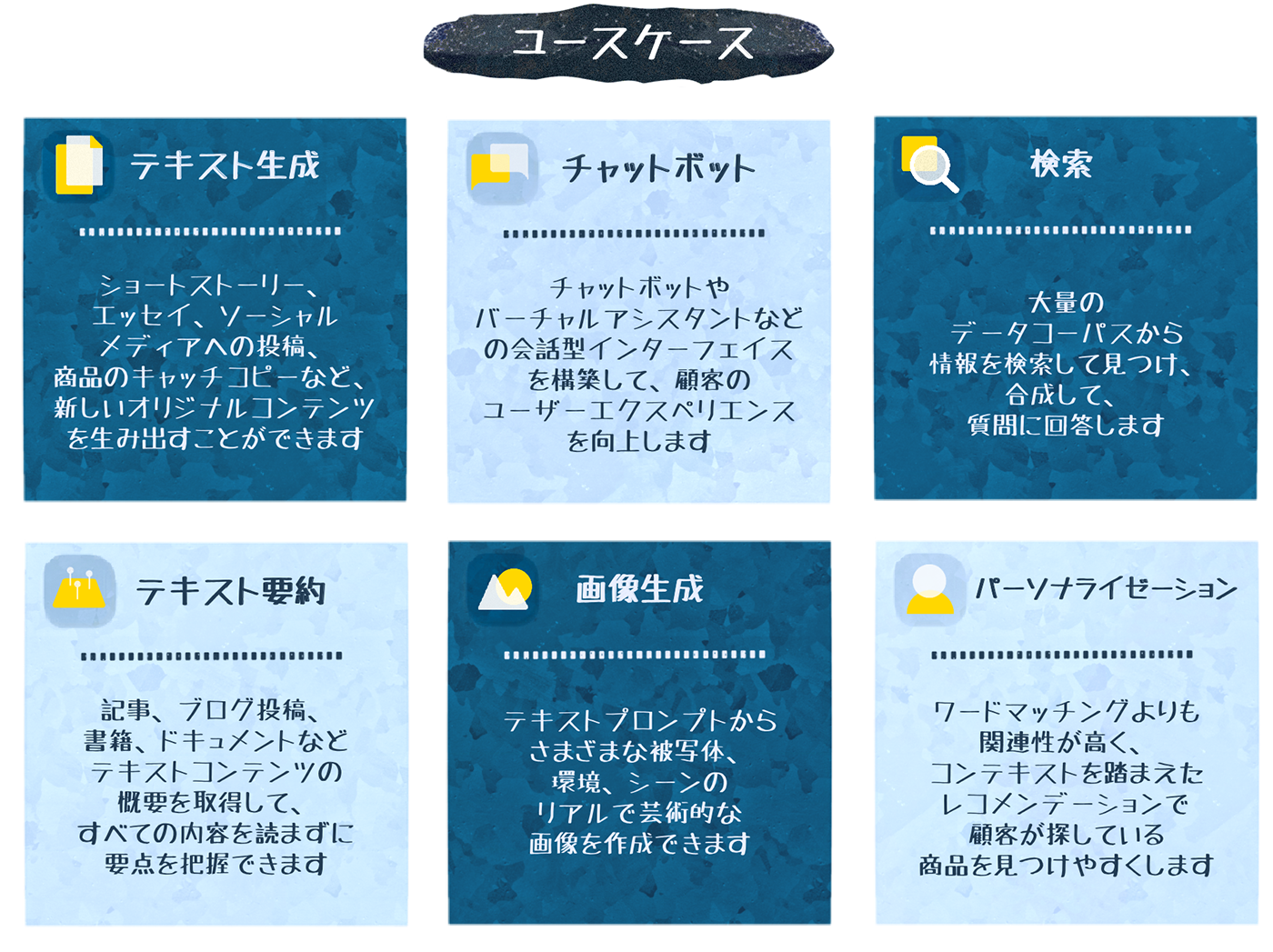
生成 AI の利用用途は、業種や業界を問わず広がりを見せており、今後も技術の進化と共に、さらなる用途の拡大が想定されます。以下は、現在主に活用されている生成 AI のユースケースの例です。
|
ユースケース |
説明 |
|
テキスト生成 |
ショートストーリー、論文、ソーシャルメディアへの投稿、ウェブページのコピーなど、オリジナルのテキストコンテンツを生成します。 |
|
チャットボット |
チャットボットやバーチャルアシスタントなどの対話インターフェイスを構築し、顧客満足度の高いサービスを提供します。 |
|
検索 |
膨大なデータから関連性の高い情報を検索・抽出し、要約・統合して、質問に的確に回答します。 |
|
テキスト要約 |
記事、ブログ、書籍、文書などのテキストの要点を把握できるように、核心を絞った概要を生成します。 |
|
画像生成 |
言語プロンプトから、さまざまな被写体、環境、シーンのリアルで芸術的な画像を生成します。 |
|
パーソナライゼーション |
ワードマッチングよりも関連性が高く、コンテキストを踏まえた商品のレコメンデーションを使用して、顧客が探している商品を見つけやすくします。 |
その他、AWS が考える生成 AI のユースケースについて詳しくは、「生成 AI のビジネス価値を組織で実現」をご覧ください。
Amazon Bedrock を活用したユースケース
Amazon Bedrock は、事前学習済みの高性能な基盤モデルや GUI ベースのツール群を提供することで、生成 AI アプリケーションの開発と運用を劇的に簡略化します。 また、AWS エコシステムとシームレスに連携できるメリットを活かしてさまざまなユースケースが考えられます。
社内ヘルプデスクチャットボット
社内規定や製品マニュアルなどの膨大な社内ドキュメントを Amazon S3 に保存し、ユーザーからの自然言語の質問に対して、関連する情報を Amazon Kendra で全文検索し、Amazon Bedrock の基盤モデルが要約して回答を生成します。「出張申請の方法を教えて」といった問い合わせに、必要な手順を簡潔にまとめて説明する社内ヘルプデスクが構築できます。
金融機関での顧客向けパーソナライズ
Amazon Personalize と連携し、お客様各人の関心に合わせた新サービスや商品の提案メールを Amazon Bedrock の基盤モデルが自動生成し Amazon SES で定期配信したり、「今月の収支を改善するには ?」といった質問に対して質問者の状況を踏まえた具体的な提案を自動生成するシステムを構築できます。
EC サイトの商品説明文の自動生成
商品の基本情報や画像を Amazon Bedrock に入力し、魅力的な説明文を生成します。マルチモーダルな基盤モデルを使って、テキストや画像を解析し、SEO 効果やコンバージョン率の向上を意識した訴求力のあるコピーを生成します。Amazon Bedrock による商品説明文の自動生成を組み込むことで、数百、数千の商品ページを効率的に量産するシステムが構築できます。
Amazon Bedrock を使った実際のプロジェクトについて詳しくは、「Amazon Bedrock のお客様の声」をご覧ください。
多彩な基盤モデル
モダリティとは
モダリティとは、生成 AI における入力および出力の形式を指します。Amazon Bedrock の基盤モデルでは以下の 4 種類のモダリティの入出力をサポートしています。
-
テキスト (Text):テキストを処理するモデルです。文書の生成、テキストの要約、翻訳、感情分析などのテキスト処理タスクに利用できます。
-
チャット (Chat): 会話型のインタラクションを処理するモデルです。ユーザーとの対話を通じて情報を提供したり、質問に答えたりすることができます。
-
イメージ (Image):画像データを処理するモデルです。高品質な画像生成や視覚的なコンテンツ作成に利用できます。
-
埋め込み (Embedding):埋め込みは、テキストや画像などのデータを数値配列へ変換 (ベクトル化) するモデルです。ベクトル化により、異なるフォーマットのデータであっても AI モデルが統一的に扱えるようになり、検索、分類、推論といったタスクを効率的に実行できるようになります。Amazon Bedrock では、埋め込みはナレッジベースの登録に利用されます。
Amazon Bedrock がサポートしている基盤モデル
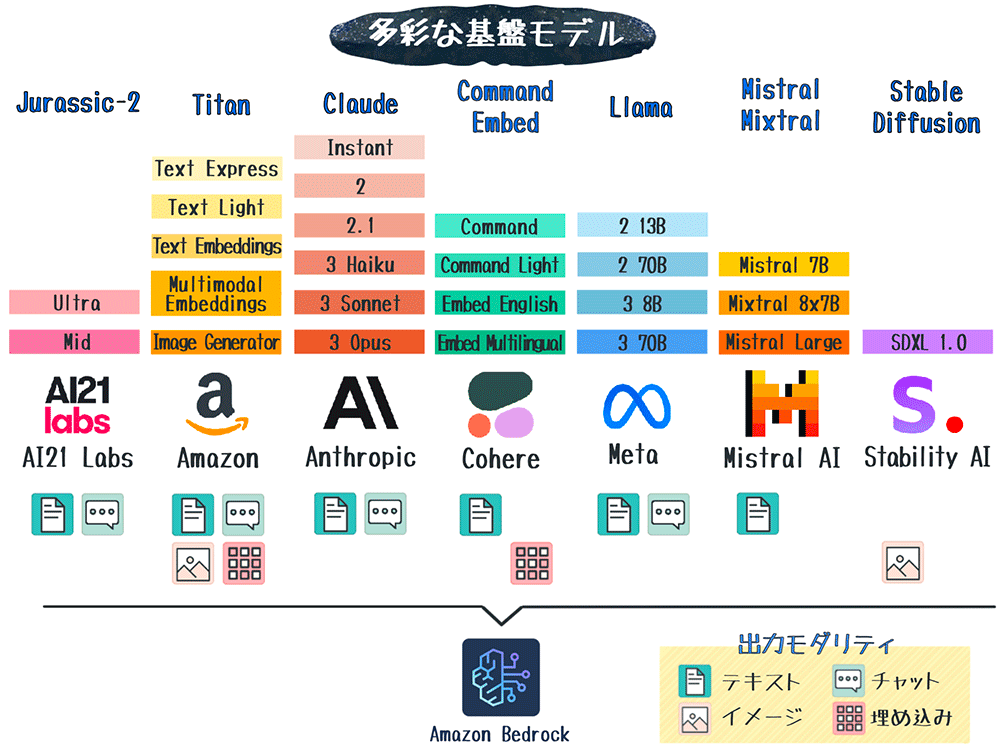
Amazon Bedrock では、Amazon が提供する高精度な基盤モデル Amazon Titan ファミリーに加え、サードパーティーのプロバイダーが提供する多数の基盤モデルを利用できます。
|
プロバイダー |
モデル |
入力モダリティ |
出力モダリティ |
特徴 |
|
Amazon |
テキスト / イメージ |
テキスト / イメージ / チャット / 埋め込み |
高度な自然言語処理、マルチモーダル機能、マルチ言語対応、カスタマイズ可能 |
|
|
Anthropic |
テキスト / イメージ |
テキスト / チャット |
思慮深い対話、コンテンツ制作、推論、コーディング、高速 |
|
|
AI21 Labs |
テキスト |
テキスト / チャット |
企業向け指示実行モデル、テキスト生成、質疑応答、要約 |
|
|
Cohere |
テキスト |
テキスト / 埋め込み |
テキスト生成、要約、検索、分類、クラスタリング、RAG |
|
|
Meta |
テキスト |
テキスト / チャット |
対話、質疑応答、文章読解などの自然言語タスク |
|
|
Mistral AI |
テキスト |
テキスト |
要約、分類、補完、コーディングなど |
|
|
Stability AI |
テキスト / イメージ |
イメージ |
アート、ロゴ、デザインなど高品質な画像生成 |
Amazon Bedrock がサポートしている基盤モデルについて詳しくは、「Amazon Bedrock でサポートされている基盤モデル」をご覧ください。
Amazon Bedrock がサポートしている基盤モデル
Amazon Bedrock では、Amazon が提供する高精度な基盤モデル Amazon Titan ファミリーに加え、サードパーティーのプロバイダーが提供する多数の基盤モデルを利用できます。
|
プロバイダー |
モデル |
入力モダリティ |
出力モダリティ |
特徴 |
|
Amazon |
テキスト / イメージ |
テキスト / イメージ / チャット / 埋め込み |
高度な自然言語処理、マルチモーダル機能、マルチ言語対応、カスタマイズ可能 |
|
|
Anthropic |
テキスト / イメージ |
テキスト / チャット |
思慮深い対話、コンテンツ制作、推論、コーディング、高速 |
|
|
AI21 Labs |
テキスト |
テキスト / チャット |
企業向け指示実行モデル、テキスト生成、質疑応答、要約 |
|
|
Cohere |
テキスト |
テキスト / 埋め込み |
テキスト生成、要約、検索、分類、クラスタリング、RAG |
|
|
Meta |
テキスト |
テキスト / チャット |
対話、質疑応答、文章読解などの自然言語タスク |
|
|
Mistral AI |
テキスト |
テキスト |
要約、分類、補完、コーディングなど |
|
|
Stability AI |
テキスト / イメージ |
イメージ |
アート、ロゴ、デザインなど高品質な画像生成 |
Amazon Bedrock がサポートしている基盤モデルについて詳しくは、「Amazon Bedrock でサポートされている基盤モデル」をご覧ください。
リージョン別のサポート
利用可能なモデルやバージョンは、リージョンによって異なります。2024 年 5 月現在、アジアパシフィック (東京) リージョンであれば、Titan Text G1 - Express や Claude 2.1 などの基盤モデルが利用できます。なお、米国東部 (バージニア北部) リージョンおよび米国西部 (オレゴン) リージョンでは、すべてのモデルが利用できます。
リージョン別のモデルのサポート状況について詳しくは、「AWS 地域別のモデルサポート」をご覧ください。
基盤モデルのライフサイクル
Amazon Bedrock がサポートする基盤モデルは、多機能かつ高精度で安全な最新バージョンを継続的に提供するため、アクティブ、レガシー、サポート終了 (EOL) の 3 つのステータスに従い更新を繰り返します。
例えば、2024 年 5 月現在、以下の 3 つのモデルバージョンはサポート終了しているため、代わりにより新しいバージョンの利用が推奨されます。
|
モデル |
モデルバージョン |
レガシー移行日 |
サポート終了日 |
推奨モデルバージョン |
|
Stable Diffusion |
XL 0.8 |
2024 年 2 月 21 日 |
2024 年 4 月 30 日 |
XL 1.x |
|
Claude |
v1.3 |
2023 年 11 月 28 日 |
2024 年 2 月 28 日 |
v2.1 / v3 |
|
Amazon Titan |
Embeddings - Text v1.1 |
2023 年 11 月 7 日 |
2024 年 2 月 15 日 |
Embeddings - Text v1.2 |
2024 年 3 月には Anthropic 社の次世代最新モデルである Claude 3 ファミリーの中から、Claude 3 Haiku と Claude 3 Sonnet がアクティブになり、4 月には Mistral AI 社のトップクラスの推論能力を持つ Mistral Large がアクティブになりました。現在これらのモデルは、米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (パリ)、アジアパシフィック (シドニー) の 4 リージョンで利用できます。また、4 月 16 日に、Claude 3 ファミリーの中でも最高の推論能力を持ち、AI システムの一般的な評価ベンチマークで最高レベルのパフォーマンスを発揮する Claude 3 Opus が米国西部 (オレゴン) リージョンでサポートを開始しました。さらに 4 月 23 日には、Meta 社の Llama 3 ファミリーから、推論、コード生成、指示理解などの性能が大幅に向上した Llama 3 8B と Llama 3 70B のサポートを米国東部 (バージニア北部) および 米国西部 (オレゴン) リージョンで開始しました。
過去に例を見ないほど技術革新の速度が早い AI の領域において、Amazon Bedrock はサードパーティーのプロバイダーの協力を得ながら、常に最新の基盤モデルを開発社に提供し続ける仕組みを備えています。
基盤モデルのライフサイクルについて詳しくは、「モデルのライフサイクル」をご覧ください。
モデルの運用と連携
Amazon Bedrock では、AWS コンソール上のプレイグラウンドを利用することで基盤モデルを手軽に試すことができます。また、基盤モデルをサービスに統合する場合は、Amazon Bedrock API を通してクライアントアプリケーションから柔軟にモデル推論を実行できます。
なお、プレイグラウンドや API コールで基盤モデルを利用する際には、事前に利用したいモデルへのアクセスをリクエストする必要があります。モデルアクセスについて詳しくは、「モデルアクセス」をご覧ください。
プレイグラウンド
AWS コンソール上のプレイグラウンドを使うことで、コードを一切書かずに、さまざまな基盤モデルの性能を手軽にテストできます。
プレイグラウンドを使ったモデル推論
プレイグラウンドは、以下の手順で簡単に利用できます。
-
プレイグラウンドの起動
Amazon Bedrock コンソールにアクセスし、ナビゲーションペインから利用したいモダリティのプレイグラウンドを起動します。 -
モデルの選択
「モデルを選択」ボタンをクリックし、利用したい基盤モデルを選択します。 -
プロンプトの実行
任意のプロンプトを書いてモデル推論を実行します。
プレイグラウンドの設定と機能
プレイグラウンドでは、デフォルト設定の基盤モデルの性能を試すことができますが、ランダム性や多様性などを調整する推論パラメーターを設定することで、より詳細な条件でのモデル推論も可能です。また文法精度や生成速度などの定量的メトリクスに基づくモデルの自動評価機能や、同一プロンプトで複数モデルを同時に実行できる比較モードも提供されています。
これらのプレイグラウンドの各種機能を使って、開発者はさまざまな観点から基盤モデルをテストし、目的の用途に合ったモデルを選定することができます。
Amazon Bedrock のプレイグラウンドについて詳しくは、「プレイグラウンド」をご覧ください。
Amazon Bedrock API
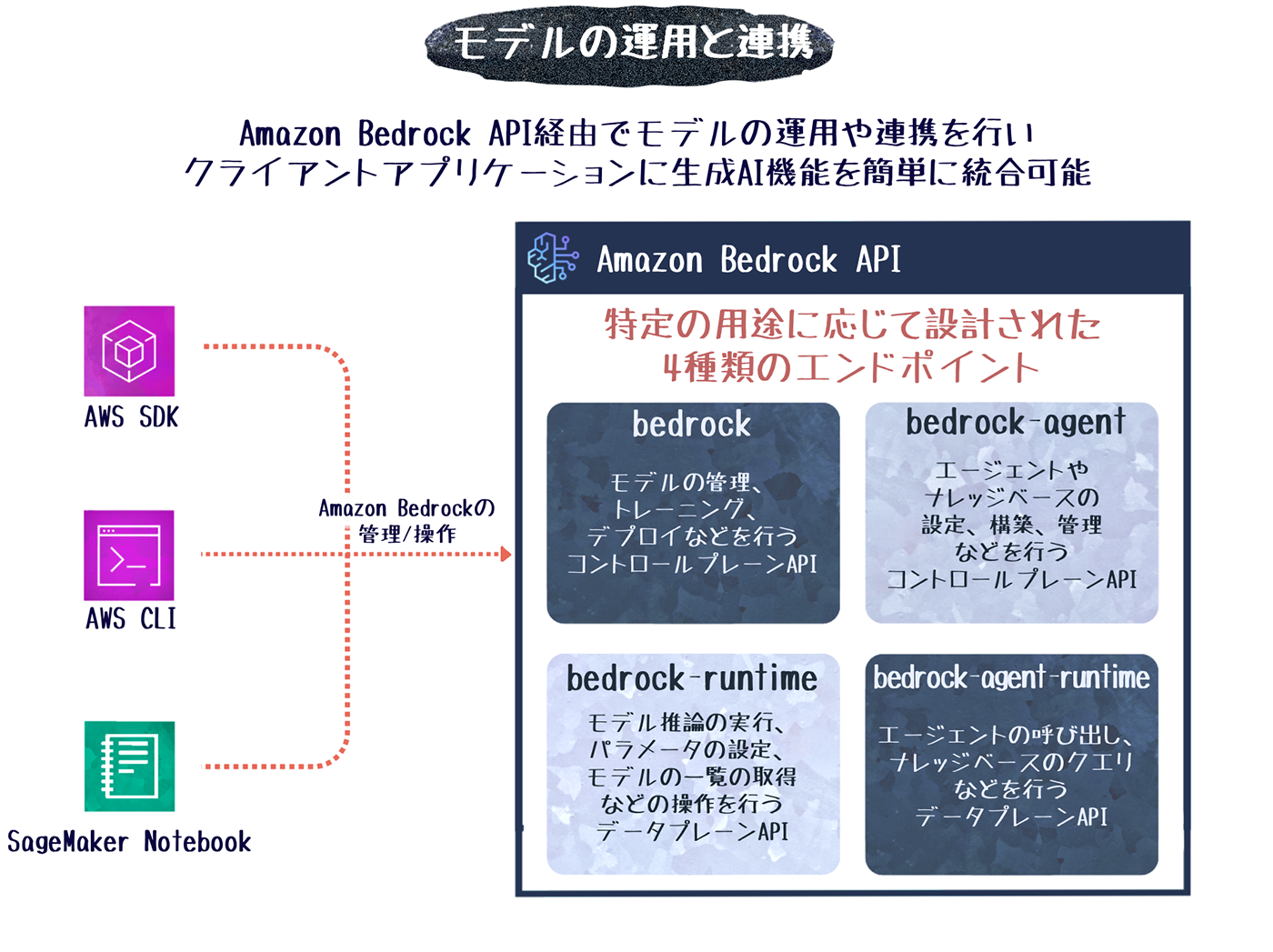
アプリケーションに基盤モデルを実装する際には、Amazon Bedrock API を利用します。Amazon Bedrock API は、モデルの管理、トレーニング、デプロイ、推論リクエストなど、Amazon Bedrock におけるほぼすべての操作が可能です。Amazon Bedrock API は、AWS CLI、AWS SDK および Amazon SageMakerノートブック からアクセスでき、通常のアプリケーション開発と同様の手順で生成 AI 機能をアプリケーションに統合できます。
サービスエンドポイント
Amazon Bedrock API のエンドポイントは、機能ごとに 4 つのサービスカテゴリーに分けられ個別のエンドポイントを持っています。
|
サービスカテゴリー |
説明 |
米国東部 (バージニア北部) リージョンの
|
|
bedrock |
モデルの管理、トレーニング、デプロイなどを実行するコントロールプレーン API |
|
|
bedrock-runtime |
基盤モデルに対して推論リクエストを実行するランタイムプレーン API |
|
|
bedrock-agent |
エージェントとナレッジベースの作成・管理を実行するコントロールプレーン API |
|
|
bedrock-agent-runtime |
エージェントの呼び出しとナレッジベースのクエリを実行するランタイム API |
上記表のエンドポイントは、米国東部 (バージニア北部) us-east-1 リージョンの例ですが、実際のエンドポイントはリージョンごとに異なります。各カテゴリーおよびリージョンごとのサービスエンドポイントについて詳しくは、「Amazon Bedrock エンドポイントとクォータ」をご覧ください。
API を使った推論リクエストの実行
ここでは、AWS SDK for Python (Boto3) を使い、Amazon Bedrock API 経由でモデル推論を実行する方法の概要を説明します。
モデル推論を実行する際は、事前に使用したいモデルのアクセスリクエストを送信し、許可を得る必要があります。
-
環境のセットアップ:
API を実行するクライアント環境に Boto3 ライブラリをインストールします。AWS SDK は、Python 以外にも、Java、.Net、Go など多くの一般的なプログラム言語で利用できます。 -
IAM ロールの設定:
Amazon Bedrock へのアクセス権限を付与した IAM ロールを設定します。Amazon Bedrock のリソースへのアクションは、IAM ポリシーを作成して IAM ロールにアタッチします。 -
推論リクエストの実行:
bedrock-runtime を使って boto3 クライアントを初期化します。プロンプトと推論パラメータを設定したリクエストボディ、利用するモデルなどを引数に指定して invoke_model 関数を実行しモデル推論をリクエストします。 -
推論結果を解析:
JSON 形式のレスポンスをパースします。画像生成のリクエストの場合、Base64 エンコードの文字列を取得するため、適宜デコードします。
推論リクエストのコード例
以下はClaude 2.0でテキスト推論を実行する場合の簡単なコード例です。
# SDKや依存ライブラリを呼び出し
import boto3
import json
# サービスカテゴリーを指定してboto3クライアントを初期化
brt = boto3.client(service_name='bedrock-runtime')
# リクエストボディにプロンプトや推論パラメータを設定
body = json.dumps({
"prompt": "how are you today?",
"max_tokens_to_sample": 300,
"temperature": 0.1
})
# リクエストボディと基盤モデルを指定して推論リクエストを実行
response = brt.invoke_model(body=body, modelId='anthropic.claude-v2')
# 推論結果を出力
response_body = json.loads(response.get('body').read())
print(response_body.get('completion'))Amazon Bedrock API の操作方法
Amazon Bedrock API は、モデル推論以外にも、カスタムモデルの作成やエージェントの設定など、Amazon Bedrock のほぼすべての操作が可能です。Amazon Bedrock API を使ったさまざまな操作について詳しくは、「AWS SDK を使用した Amazon Bedrock のコード例」や「Amazon Bedrock API Reference (英語) 」をご覧ください。
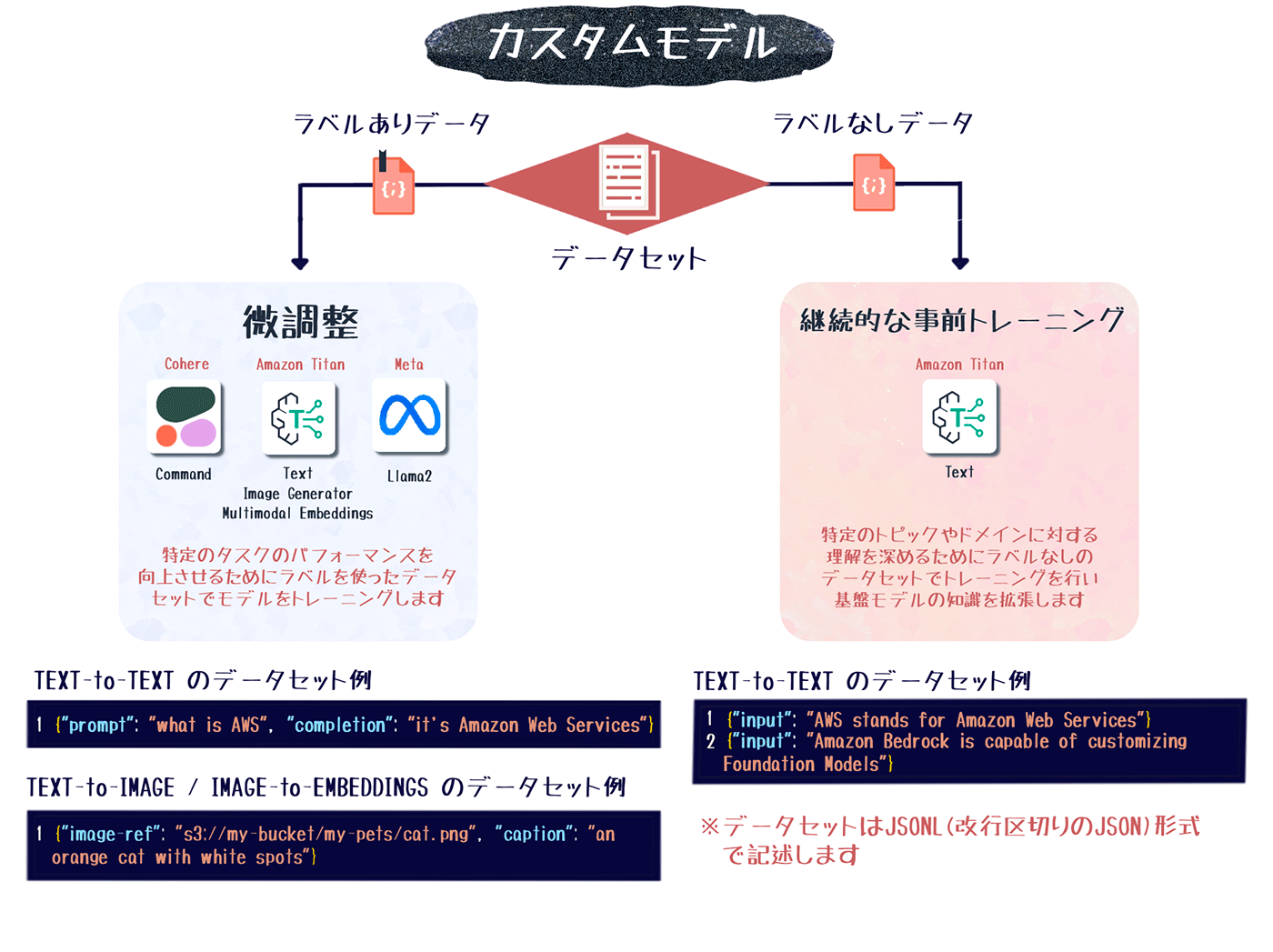
カスタムモデルの構築
Amazon Bedrockでカスタムモデルを構築する場合は、微調整 (ファインチューニング)と継続的な事前トレーニングの 2種類の方法があります。
- 微調整:ラベル付けされたデータセットを使用して、特定のタスクに対する推論を最適化するために基盤モデルをトレーニングします。
- 継続的な事前トレーニング:ラベルなしのデータセットを使用してトレーニングすることで、基盤モデルの汎用性を向上させます。
サポートモデル
基盤モデルをベースとしたカスタムモデルの構築は、2024 年 5月現在、以下の基盤モデルで実施できます。継続的な事前トレーニングは、Amazon Titan Text G1のみサポートしています。
| 基盤モデル | 微調整 | 継続的な事前トレーニング |
| Amazon Titan Text G1 | はい | はい |
| Amazon Titan Image Generator G1 | はい | いいえ |
| Amazon Titan Multimodal Embeddings G1 | はい | いいえ |
| Cohere Command | はい | いいえ |
| Meta Llama 2 | はい | いいえ |
カスタムモデルをサポートしているリージョンやモデルについて詳しくは、「モデルのカスタマイズがサポートされている地域とモデル」をご覧ください。
カスタムモデルの作成
微調整と継続的な事前トレーニングは、Amazon Bedrockコンソールまたは API のいずれかで実行します。
- データセットの準備:
微調整またはトレーニングに使用するデータセットを JSONL形式で準備し、S3に保存します。データセットの形式は、カスタムジョブのタイプ(微調整または継続的な事前トレーニング)と入出力のモダリティによって異なります。 - モデルカスタマイズジョブの作成:
カスタマイズする基盤モデル、データセットの S3アドレス、エポック数や学習率などのハイパーパラメータを設定して、カスタマイズジョブを作成します。 - ジョブのモニタリング:
ジョブを開始してカスタムモデルが作成されるまでは数時間かかることがあります。トレーニングの進行状況を監視し、必要に応じてジョブを停止することも可能です。 - トレーニング結果の確認:
ジョブが完了したら、トレーニングや検証のメトリクスを調べたり、モデル評価を行ったりして、結果を分析します。モデルの精度が十分でない場合は、データセットやハイパーパラメータを調整してトレーニングを再実行します。
作成したカスタムモデルを利用する際は、プロビジョンドスループットを購入する必要があります。プロビジョンドスループットとは、カスタムモデルの同時推論数やパフォーマンスを保証するリソースです。購入したプロビジョンドスループットをカスタムモデルに関連付けたら、プレイグラウンドやAmazon Bedrock APIからカスタムモデルにアクセスします。
Amazon Bedrockのカスタムモデルについて詳しくは、「カスタムモデル」をご覧ください。
カスタムモデルのトレーニング方法
Amazon Bedrock でカスタムモデルを構築する場合は、微調整 (ファインチューニング) と継続的な事前トレーニングの 2 種類の方法があります。
-
微調整:ラベル付けされたデータセットを使用して、特定のタスクに対する推論を最適化するために基盤モデルをトレーニングします。
-
継続的な事前トレーニング:ラベルなしのデータセットを使用してトレーニングすることで、基盤モデルの汎用性を向上させます。
サポートモデル
基盤モデルをベースとしたカスタムモデルの構築は、2024 年 5 月現在、以下の基盤モデルで実施できます。継続的な事前トレーニングは、Amazon Titan Text G1 のみサポートしています。
|
基盤モデル |
微調整 |
継続的な事前トレーニング |
|
Amazon Titan Text G1 |
はい |
はい |
|
Amazon Titan Image Generator G1 |
はい |
いいえ |
|
Amazon Titan Multimodal Embeddings G1 |
はい |
いいえ |
|
Cohere Command |
はい |
いいえ |
|
Meta Llama 2 |
はい |
いいえ |
カスタムモデルをサポートしているリージョンやモデルについて詳しくは、「モデルのカスタマイズがサポートされている地域とモデル」をご覧ください。
カスタムモデルの作成
微調整と継続的な事前トレーニングは、Amazon Bedrock コンソールまたは API のいずれかで実行します。
-
データセットの準備:
微調整またはトレーニングに使用するデータセットを JSONL 形式で準備し、S3 に保存します。データセットの形式は、カスタムジョブのタイプ (微調整または継続的な事前トレーニング) と入出力のモダリティによって異なります。 -
モデルカスタマイズジョブの作成:
カスタマイズする基盤モデル、データセットの S3 アドレス、エポック数や学習率などのハイパーパラメータを設定して、カスタマイズジョブを作成します。 -
ジョブのモニタリング:
ジョブを開始してカスタムモデルが作成されるまでは数時間かかることがあります。トレーニングの進行状況を監視し、必要に応じてジョブを停止することも可能です。 -
トレーニング結果の確認:
ジョブが完了したら、トレーニングや検証のメトリクスを調べたり、モデル評価を行ったりして、結果を分析します。モデルの精度が十分でない場合は、データセットやハイパーパラメータを調整してトレーニングを再実行します。
作成したカスタムモデルを利用する際は、プロビジョンドスループットを購入する必要があります。プロビジョンドスループットとは、カスタムモデルの同時推論数やパフォーマンスを保証するリソースです。購入したプロビジョンドスループットをカスタムモデルに関連付けたら、プレイグラウンドや Amazon Bedrock API からカスタムモデルにアクセスします。
Amazon Bedrock のカスタムモデルについて詳しくは、「カスタムモデル」をご覧ください。
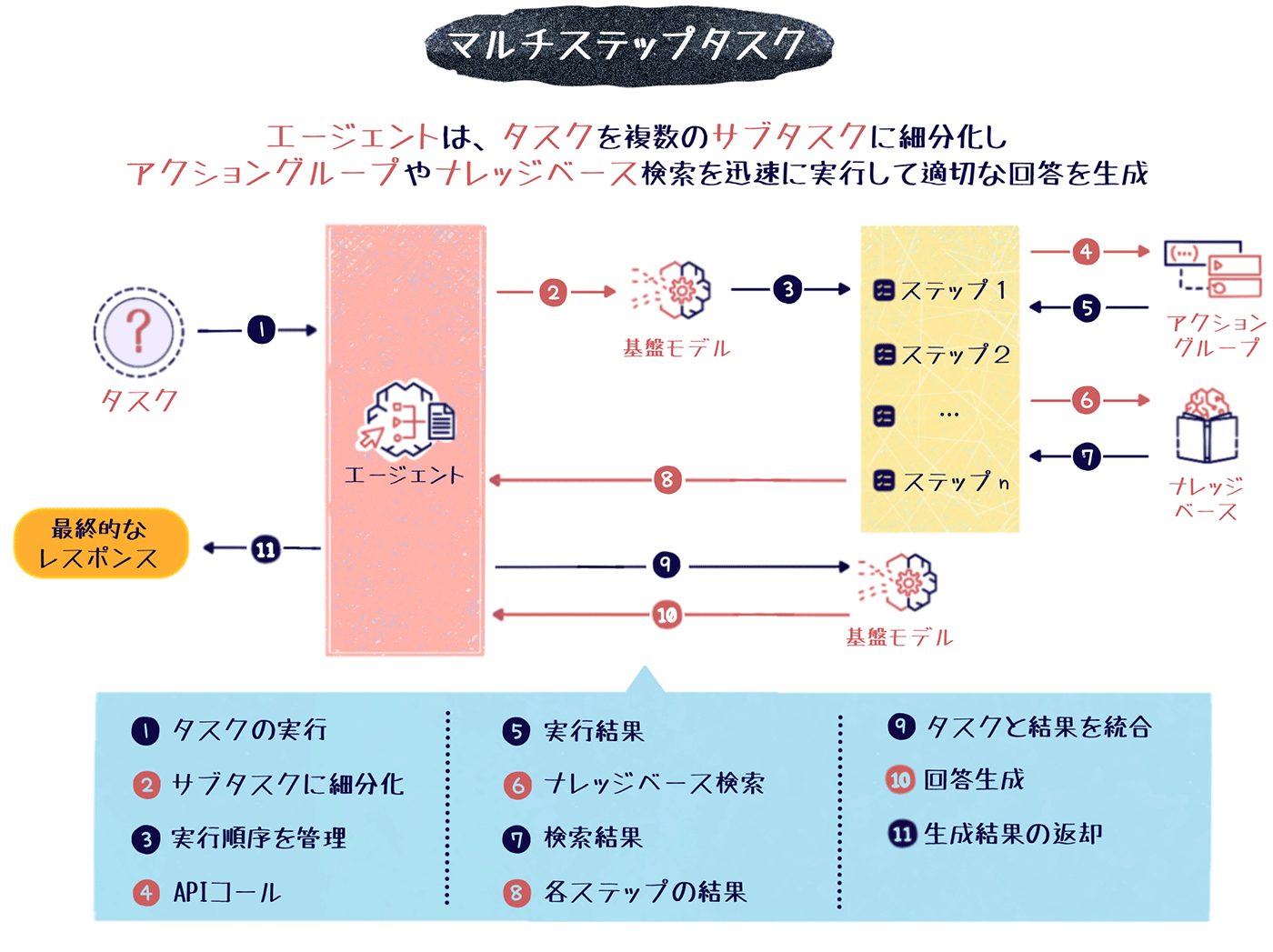
マルチステップタスクの設定
Amazon Bedrock は、一問一答のコンテンツ生成だけでなく、特定のシナリオに沿った複合的なタスクやワークフローを設定できる「エージェント」機能を備えています。エージェントを使用すると、顧客対応のプロセスフローや、製品説明の段階的な導線、多段階の意思決定シーケンスなど、一連のマルチステップタスクを事前に定義できます。
さらに、エージェントにナレッジベースを組み合わせることで、検索拡張生成 (RAG) を活用したアプリケーションを簡単に構築することも可能です。
エージェントの役割
エージェントは、ユーザーからのプロンプトに対して、あらかじめ設定されたツールやデータソースを使用してタスクを実行します。
例えば旅行会社の自動応答システムにエージェントを組み込んだ場合、最初に旅行の目的を尋ね、次に旅行先の候補を提示し、その後予算と日程に基づいて最適なプランを提案する、といった複雑なマルチステップタスクを生成 AI の応答に組み込むことができます。
エージェントの設定
エージェントの設定には、以下のような項目が含まれます。
|
設定項目 |
必須/オプション |
内容 |
|
基本設定 |
必須 |
エージェントの名前、サービスロール、利用する基盤モデルを指定します。 |
|
追加設定 |
オプション |
ユーザー入力、暗号化キー、アイドルセッションタイムアウトなどを設定します。 |
|
エージェント向けの指示 |
必須 |
エージェントに期待する振る舞いを自然言語で記述した指示を入力します。特定のスタイルやトーンを指定することもできます。 |
|
アクショングループ |
オプション |
エージェントが実行するアクションを定義します。外部システムの API の呼び出しなどが含まれます。 |
|
ナレッジベース |
オプション |
エージェントが参照するデータソースを登録します。PDF、テキストファイルなどを Amazon S3 に保存します。 |
自動プロンプト作成
「エージェント向けの指示」には、エージェントに何をすべきか、どのようにユーザーとやり取りすべきかを伝えるための詳細を入力します。
例えば「あなたは保険代理店でオフィスアシスタントとして働いています。フレンドリーで丁寧な対応を心がけています。保険金請求の処理や、保留中の書類手続きの調整を担当しています。」といった具体的な条件を設定をすることで、ユーザーの質問に対して指示に従ったプロンプトが自動作成されます。この例では、保険代理店のアシスタントらしい丁寧なトーンでの応答が可能になります。
最小構成のエージェントでは、基本設定とエージェント向けの指示の設定だけでも作成可能ですが、必要に応じてアクショングループやナレッジベースを作成します。「航空券の予約は、航空券予約アクショングループを用いて処理してください。」や「技術的な質問は、ナレッジベースのマニュアルを参照してください。」などと指示することで、エージェントにアクショングループやナレッジベースを活用させることができます。
アクショングループの設定
アクショングループは、ユーザーの要求に応じて柔軟に処理を実行するための機能です。アクショングループに Lambda 関数を設定し、他の AWS サービスや、外部システムの API をコールすることができます。アクショングループを使うことで、複雑な処理をエージェントに付け加えることができます。
アクショングループの設定の手順は以下の通りです。
-
アクショングループの基本情報:
アクショングループ名や、オプションで任意の説明文を記入します。 -
Lambda 関数の選択:
アクショングループのロジックを定義した Lambda 関数をアクショングループに関連付けます。 -
API スキーマの選択:
アクショングループの API の説明、構造、パラメータなどに関する詳細な情報を、YAML または JSON 形式の OpenAPI スキーマで定義します。API スキーマは、S3 バケットにアップロードするか、コンソール上のインラインスキーマエディタに直接記述します。 -
アクショングループの追加:
アクショングループを追加して、エージェントに関連付けます。一つのエージェントに対して、アクショングループは複数設定できます。
アクショングループの作成方法について詳しくは、「Amazon Bedrock エージェントのアクショングループを作成する」をご覧ください。
ナレッジベースを使った RAG の構築
Amazon Bedrock のナレッジベースは、特定のデータソースをベクトル化してベクトルデータベースに格納する機能です。ナレッジベースを使用すると、検索拡張生成 (RAG) を活用したアプリケーションを簡単に構築できます。
ナレッジベースの登録
S3 バケットに保存したPDF やプレーンテキストのデータソースを、Amazon Titan Embeddings や Cohere Embed などの埋め込みモデルを使ってベクトル化し、Amazon OpenSearch Serverless や Pinecone、Redis Enterprise Cloud などのベクトルデータベースに格納します。ナレッジベース登録後、Amazon Bedrock コンソール上のテキストウィンドウでテストを実施できます。
ナレッジベースについて詳しくは、「Amazon Bedrock のナレッジベース」をご覧ください。
検索拡張生成 (RAG)
RAG とは、生成 AI がトレーニングデータソース以外の信頼できる知識ベースを参照する仕組みを指します。
生成 AI は、時により虚偽の情報を生成してしまう「ハルシネーション」を起こすことが知られています。そこで、生成 AI にモデル外の特定の情報源を参照させることで、ハルシネーションの発生リスクを抑えながら、最新の情報を提供する仕組みとして RAG のアプローチが考えられました。RAG について詳しくは、「RAG とは何ですか?」をご覧ください。
ナレッジベースをエージェントに関連づけることで、ユーザーのプロンプトに応じて、ナレッジベース内の情報を検索する RAG を簡単に構築できます。例えば、最新の製品仕様が記載された PDF ファイルをナレッジベースとして登録し、そのナレッジベースを参照するようエージェントの設定を行います。すると、ユーザーが「この製品の仕様を教えて」と尋ねた場合、エージェントはナレッジベースの PDF を検索し、最新の仕様情報を生成して返答できるようになります。
なお、ナレッジベースを使って RAG を構成する際は、必ずしもエージェントに関連づける必要はありません。例えば、RetrieveAndGenerate API を使ってナレッジベースに直接クエリを実行した上で、モデル推論を実行することも可能です。
その他 Amazon Bedrock のエージェントについて詳しくは、「Agents for Amazon Bedrock」をご覧ください。
責任ある AI とセキュリティ
生成 AI の進化は、人間の創造性を拡張し、新しいアイデアや作品の創出を促進する可能性を秘めています。一方で、生成 AI の生成するコンテンツには、学習データの偏り等の影響で、事実誤認や公序良俗に反する内容が含まれる可能性があります。このため、生成 AI を取り扱う企業には、生成コンテンツの事実確認や表現の適切さの評価が不可欠です。
AWS が提供する AI/ML サービスでは、責任ある AI のポリシーが適用されています。Amazon Bedrock でも同様に、データ保護、不正検出、コンプライアンス準拠、不適切な表現のフィルタリングなど、責任ある AI のためのさまざまな対策が施されています。
セキュリティ対策
ユーザーのプロンプトの内容や、トレーニングデータセットなどは機密性の高い情報です。Amazon Bedrock では、扱うデータの安全性を保持するため、データ保護やモニタリングなどセキュリティ対策の仕組みを備えています。
-
データ暗号化:
Amazon Bedrock のデータは転送時に TLS 1.2、保管時に AWS KMS による暗号化され安全性が確保されます。また、ユーザーの微調整データは、カスタムモデルの微調整以外の目的では利用されません。 -
ネットワークセキュリティ:
VPC を利用して Amazon Bedrock のリソースをプライベートなネットワーク上に配置することで、インターネットからのアクセスを制御できます。また PrivateLink によって、VPC と Amazon Bedrock の間を安全に接続し、ネットワークレベルでの高度なセキュリティを実現します。 -
ログ記録とモニタリング:
Amazon Bedrock への API コールのログや、モデルへの入出力データは S3 や CloudWatch Logs に記録できます。また AWS CloudWatch や AWS CloudTrail を使用して使用状況メトリクスや API アクティビティをモニタリングし、問題が発生した際のトラブルシューティングを行えます。 -
不正利用検出:
Amazon Bedrock は、自動化された不正検出メカニズムを搭載しています。ユーザー入力の内容解析や生成結果の評価などにより、有害なコンテンツの生成やシステムの悪用を検知します。
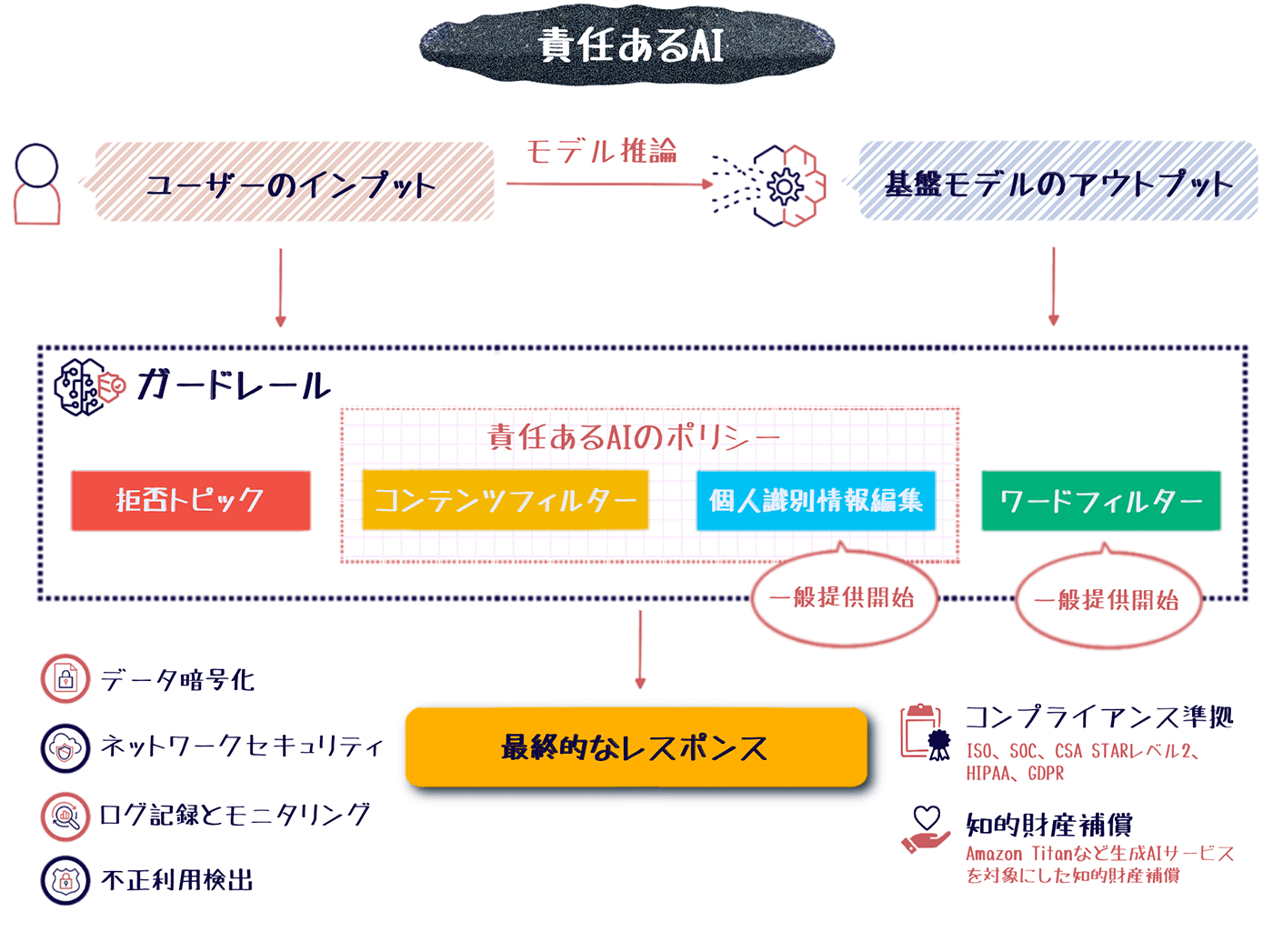
コンプライアンス準拠
Amazon Bedrock は、ISO、SOC、CSA STAR レベル 2 など、主要なコンプライアンス基準の適応対象になっています。また、HIPAA に適合しているため医療分野でも利用可能であり、GDPR に準拠した形での利用も可能です。インシデント発生時の迅速な対応体制が整えられているほか、定期的な内部/外部監査の実施、コンプライアンスレポートの公開など、高度な対策が講じられています。
Amazon Bedrock のコンプライアンスについて詳しくは、「Amazon Bedrock のコンプライアンス検証」をご覧ください。
責任ある AI のポリシー
ガードレールによるコンテンツ保護
Amazon Bedrock では責任ある AI を支援するための ガードレール機能 の 一般提供を開始 しました。ガードレールは、生成するコンテンツに対して責任ある AI のポリシーに従ったルールやフィルターを柔軟に定義・適用できます。ガードレールを設定することで、不適切なコンテンツの生成リスクを低減することができます。
ガードレールでは以下のルールやフィルターの設定が可能です。
|
機能 |
説明 |
|
拒否トピック |
アプリケーションのコンテキストでは望ましくないトピックのセットを定義できます。例えば、オンライン銀行のアシスタントサービスであれば、ユーザーのリクエストであっても無闇に投資アドバイスを提供しないように設計できます。 |
|
コンテンツフィルター |
憎悪、侮辱、性的、暴力のカテゴリにわたって有害なコンテンツをフィルタリングするように閾値を設定できます。 |
|
ワードフィルター (一般提供開始) |
ユーザー入力や基盤モデルで生成されたレスポンスでブロックする単語のセットを定義できます。 |
|
個人識別情報の編集 (一般提供開始) |
個人識別情報 (PII) を自動で識別し、PII を含む入力を選択的に拒否したり、基盤モデルからのレスポンスに含まれる PII を編集できます。 |
ガードレールは、すべての基盤モデルやカスタムモデル、エージェントで利用できます。Amazon Bedrock のガードレールについて詳しくは、「Guardrails for Amazon Bedrock」をご覧ください。
知的財産権侵害の申告に対する補償
責任ある AI の実現に向け、Amazon Titan などの AI サービスは、生成結果に関する著作権侵害の申し立てに対し、知的財産権 (IP) に基づく補償を提供しています。知的財産補償は、AI サービス自体だけでなく、トレーニングデータの利用に関する権利侵害の申し立てにも適用されます。ただし、サービスの利用者側にも、権利侵害の恐れのあるデータを入力しないなど、責任ある運用が求められます。
AWS が知的財産権侵害を補償する AI サービスについて詳しくは、「サービス規約」のセクション 50.10 をご覧ください。
Amazon Titan 以外の基盤モデル利用時の知的財産権侵害申告に対する補償は、各モデルの使用許諾契約に準じます。例えば Claude であれば、Anthropic 社のエンドユーザー使用許諾契約に基づき、Anthropic 社が Claude の利用に関連する知的財産権侵害の申し立てから顧客を防御し、補償する責任を負います。
各基盤モデルの使用許諾契約について詳しくは、AWS Marketplace や Amazon Bedrock コンソールの各プロバイダーページからエンドユーザー使用許諾契約 (EULA) をご覧ください。
Amazon Bedrock の料金体系
生成 AI の開発には、大規模なデータセットと計算リソースが必要不可欠で、自社でゼロから構築する場合、膨大なコストと時間がかかります。その点、Amazon Bedrock を利用することで、事前学習済みの高性能な基盤モデルを利用でき、基礎となるモデル構築の手間とコストを削減できます。
Amazon Bedrock では、「モデルの推論」と「カスタマイズ」に対して利用料金が発生します。例えば、エージェントやナレッジベースを利用する場合であっても、これらの機能で使用した基盤モデルとベクトルデータベースに対してのみ課金され、その他の追加料金は発生しません。
モデル推論の料金
「モデルの推論」とは、基盤モデルを利用した推論、つまり基盤モデルの利用料金です。「モデルの推論」料金には、オンデマンドとプロビジョンドスループットの 2 つのプランがあります。
-
オンデマンド:
従量課金で、実際にモデルが処理を行った分のみ課金されます。プロンプトの入力トークン数 (質問の文字量) と、出力トークン数 (回答の文字量)、および画像の生成量に応じて料金が発生します。 -
プロビジョンドスループット:
時間単位で一定のスループットが保証される月額プランです。大量の安定した処理が必要な場合に適しています。
モデル推論の料金例
モデル推論の料金は、使用するモデルやリージョンによって異なります。以下は、一部のモデルの入力 / 出力 1,000 トークンおよび標準品質の画像 1 枚あたりのオンデマンド料金と、1 か月契約時の 1 時間あたりのプロビジョンドスループット料金の例です。 表は、2024 年 5 月現在の米国東部 (バージニア北部) リージョンの料金表です。
バッチモードの料金
バッチモードとは、S3 バケットに保存している大量のデータを一括して効率的に処理できる推論モードです。バッチモードもオンデマンドと同様に、入力と出力のトークン量に応じた従量課金で料金が発生します。
バッチモードについて詳しくは、「バッチ推論を実行する」をご覧ください。
カスタマイズ料金
特定のタスクや用途に最適化するために、基盤モデルをカスタマイズ (微調整) する際には、トレーニングデータ量と時間に応じた料金、構築したモデルのストレージ料金、カスタムモデル利用の推論料金が発生します。
-
トレーニング料金:テキスト生成モデルの場合、学習データの量とエポック数に基づいて課金
-
ストレージ料金:構築したカスタムモデルの保存領域に月額料金
-
推論料金:カスタムモデルの利用にはスループットプランに応じた料金
Amazon Bedrock の料金体系について詳しくは、「Amazon Bedrock の料金」をご覧ください。
まとめ
最後に、本記事で紹介した機能の全体図を見てみましょう。
この記事では、AWS の生成 AI 開発サービス Amazon Bedrock の機能と特徴について解説しました。Amazon Bedrock は、誰でも手軽に生成 AI アプリケーション開発を実現できるサービスです。目まぐるしく進化する AI 領域へのニーズが高まる一方で、サービスの提供側にはより迅速な対応が求められています。Amazon Bedrock を活用することで、開発者はモデルの選定からカスタマイズ、セキュリティ対策まで、生成 AI 構築における多くの課題を軽減でき、ビジネスロジックの実装に注力することで高度なサービスを迅速に提供できるようになります。Amazon Bedrock は、生成 AI 関連事業の市場競争が激化する中で、開発者にとって強力なパートナーとなるサービスです。
本記事を読んで Amazon Bedrock に興味を持たれた方、実際に使ってみたいと思われた方は、ぜひ製品ページの「Amazon Bedrock」や「Amazon Bedrock を利用して生成 AI アプリケーションを構築する」などのトレーニングも合わせてご覧ください。
全体図
筆者・監修者プロフィール

筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
呉 和仁 (Go Kazuhito)
アマゾン ウェブ サービス ジャパン合同会社
機械学習ソリューションアーキテクト
IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。

監修者プロフィール
本橋 和貴 (Motohashi Kazuki)
アマゾン ウェブ サービス ジャパン合同会社
パートナーアライアンス統括本部 機械学習パートナーソリューションアーキテクト
AWS 上で機械学習関連のソフトウェアを開発しているパートナー企業の技術支援を担当をしています。好きなサービスは Amazon SageMaker です。週末は昔の RPG リメイクゲームの攻略に勤しんでいます。

監修者プロフィール
前川 泰毅 (Maekawa Taiki)
アマゾン ウェブ サービス ジャパン合同会社
メディアソリューションアーキテクト
メディア領域のお客様中心にアーキテクチャ設計や構築を支援しています。機械学習領域を得意としておりソリューションやサンプルコードの作成を行っています。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages