Amazon Web Services 한국 블로그
Amazon EMR 기반 Apache Spark 애플리케이션을 위한 성공적인 메모리 관리 모범 사례
빅데이터 세상에서 가장 일반적인 활용 사례는 다양한 데이터 원본으로 부터 방대한 양의 데이터를 수집, 변환, 분석 하는 것입니다. 여러분은 또한 그 데이터를 분석하여 통찰력을 얻어 낼 수도 있습니다. 이러한 대규모의 데이터와 관련된 작업을 하기 위한 가장 대표적인 클라우드 기반의 솔루션이 Amazon EMR입니다.
Amazon EMR은 AWS에서 Apache Hadoop 및 Apache Spark 같은 빅 데이터 프레임워크의 실행을 간소화해 주는 관리형 클러스터 플랫폼입니다. Amazon EMR을 사용하는 조직은 여러 인스턴스로 구성된 클러스터를 단 몇 분만에 가동할 수 있습니다. 또한 병렬 처리를 통해 다양한 데이터 엔지니어링 및 비즈니스 인텔리전스 워크로드를 처리할 수 있습니다. 이렇게 하면 클러스터 구축 및 확장과 관련한 데이터 처리 시간, 노력 및 비용을 대폭 감소시킬 수 있습니다.
Apache Spark는 오픈 소스 기반의 고속 범용 클러스터 컴퓨팅 소프트웨어 프레임워크로서, 분산 데이터 프로세싱에 널리 사용되고 있습니다. Apache Spark는 I/O 및 작업 실행 시간을 줄이기 위해 여러 노드에 걸쳐 메모리 상에서 병렬 컴퓨팅을 수행하므로 클러스터 메모리(RAM)에 상당히 의존하고 있습니다.
일반적으로, Amazon EMR에서 Spark 애플리케이션을 실행할 때에는 다음과 같은 단계를 수행하게 됩니다.
- Spark 애플리케이션 패키지를Amazon S3에 업로드합니다.
- Apache Spark 설정을 포함하여 Amazon EMR 클러스터를 구성 및 시작합니다.
- Amazon S3를 통해 클러스터에 Spark 애플리케이션 패키지를 설치한 다음 해당 애플리케이션을 실행합니다.
- 애플리케이션이 완료된 후 EMR 클러스터를 종료합니다.
성공적인 결과를 얻으려면 데이터 및 프로세싱 요구 사항을 기반으로 Spark 애플리케이션이 적절히 구성해야 합니다. 기본 설정을 사용하면 Spark가 클러스터의 모든 사용 가능한 리소스를 사용하지 않을 수 있으며 물리 메모리 또는 가상 메모리 문제가 발생할 수 잇습니다. stackoverflow.com로 가면 이 특정 주제와 관련한 수천 가지의 질문을 찾을 수 있습니다.
이 블로그 게시물은 Amazon EMR 기반의 Apache Spark에서의 메모리 관련 문제를 방지하기 위한 모범 사례를 통해 도움을 제공하는 용도로 작성되었습니다.
Spark 애플리케이션의 일반적인 메모리 문제 알아보기
다음에 나열된 문제들은 기본 또는 잘못된 구성을 가진 Spark 애플리케이션에서 발생할 수 있는 몇 가지 메모리 부족 오류의 샘플입니다.
1. 메모리 부족 오류, 자바 힙 메모리
2. 메모리 부족 오류, 물리 메모리 초과
3. 메모리 부족 오류, 가상 메모리 초과
4. 메모리 부족 오류, 익스큐터 메모리 초과
이러한 문제는 다양한 이유로 인해 발생할 수 있습니다. 그 중 일부가 아래에 나열되어 있습니다.
- Spark 익스큐터 인스턴스의 수, 익스큐터 메모리 량, 코어 수 또는 병렬 처리 설정이 많은 양의 데이터를 처리할 수 있도록 적절히 설정되어 있지 않는 경우.
- Spark 익스큐터 물리적 메모리가 YARN에서 할당한 메모리를 초과하는 경우. 이 경우는 Spark 익스큐터 인스턴스 메모리와 메모리 오버헤드의 합계가 메모리 집약적 작업을 처리하기에 충분하지 않은 것입니다. 메모리 집약적 작업에는 캐싱, 셔플링 및 집계(
reduceByKey,groupBy등 사용)가 포함됩니다. 또는, 일부 경우 Spark 익스큐터 인스턴스 메모리와 메모리 오버헤드의 합계가yarn.scheduler.maximum-allocation-mb에 정의된 양보다 많을 수 있습니다. - 가비지 컬렉션과 같은 시스템 작업을 수행하는 데 필요한 메모리를 Spark 익스큐터 인스턴스에서 사용할 수 없는 경우.
다음 섹션에서는 위의 예를 비롯한 다양한 메모리 부족 문제를 방지하기 위해 올바르게 구성하는 방법을 설명해 드리겠습니다.
EMR 기반 Spark 애플리케이션 성공적인 메모리 관리 구성 방법
다음 단계는 Amazon EMR에서 성공적인 Smark 애플리케이션을 구성하는 데 도움이 됩니다.
1. 애플리케이션 요건을 기반으로 인스턴스 유형 및 수 결정
Amazon EMR에는 세 가지 유형의 노드가 있습니다.
- 마스터: EMR 클러스터에는 리소스 관리자 역할을 수행하고 클러스터 및 작업을 관리하는 하나의 마스터가 있습니다.
- 코어: 코드 노드는 마스터 노드에 의해 관리됩니다. 코드 노드는 YARN NodeManager 데몬, Hadoop MapReduce 작업 및 Spark 익스큐터를 실행하여 스토리지를 관리하고, 작업을 실행하고, 노드의 하트비트를 마스터로 전송합니다.
- 작업: 선택 사항인 작업 전용 노드로서 작업을 수행하되 코어 노드와 달리 어떤 데이터도 저장하지 않습니다.
모범 사례 1: Amazon EMR 클러스터의 각 노드 유형에 대해 올바른 유형의 인스턴스를 선택합니다. 이렇게 하는 것은 Amazon EMR에서 Spark 애플리케이션을 성공적으로 실행하는 데 있어 핵심 요소 중 하나입니다.
Amazon EMR 설명서에 언급된 대로, AWS에서 제공하는 인스턴스에는 다양한 범위의 vCPU, 스토리지 및 메모리로 구성된 수많은 유형이 있습니다. 애플리케이션이 컴퓨팅 집약적인지 또는 메모리 집약적인지에 따라 올바른 컴퓨팅 및 메모리 구성을 가진 올바른 인스턴스 유형을 선택할 수 있습니다.
메모리 집약적 애플리케이션의 경우 다른 인스턴스 유형보다 R 타입 인스턴스가 선호됩니다. 컴퓨팅 집약적 애플리케이션의 경우 C 타입 인스턴스가 선호됩니다. 메모리와 컴퓨팅이 균형을 이루는 애플리케이션의 경우 M 타입의 범용 인스턴스가 선호됩니다.
AWS에서 제공하는 각 인스턴스 유형에 대해 가능한 사용 사례를 이해하려면 EC2 서비스 웹 사이트의 Amazon EC2 인스턴스 유형을 참조하십시오.
인스턴스 유형을 결정했으면 각 노드 유형의 인스턴스 수를 결정합니다. 이 작업은 입력 데이터 세트의 크기, 애플리케이션 실행 시간 및 요청 빈도를 기준으로 수행합니다.
2. Spark 구성 파라미터 결정
Spark 구성을 세부적으로 살펴보기 전에 다음 다이어그램을 사용하여 익스큐터 컨테이너 메모리가 어떻게 구성되었는지 살펴보겠습니다.
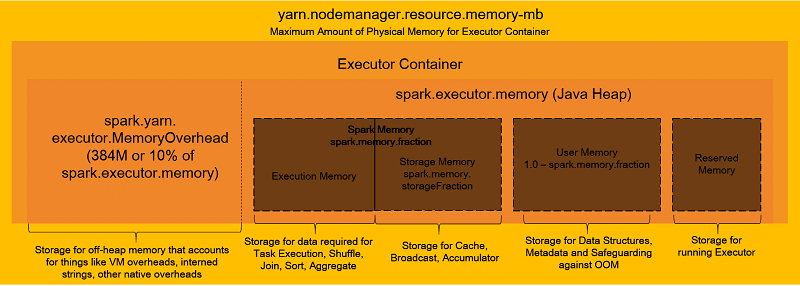
앞의 다이어그램에 표시되었듯이 익스큐터 컨테이너에는 여러 개의 메모리 컴파트먼트가 있습니다. 이 중 하나(실행 메모리)만이 작업 실행에 실제로 사용됩니다. 작업을 장애 없이 효율적으로 실행하려면 이러한 컴파트먼트를 올바르게 구성해야 합니다.
Spark 애플리케이션이 성공적으로 실행되려면 다음의 Spark 구성 파라미터를 신중하게 계산하고 설정합니다.
spark.executor.memory– 작업을 실행하는 각 익스큐터에 사용할 메모리의 크기입니다.spark.executor.cores– 익스큐터에 할당되는 가상 코어의 수입니다.spark.driver.memory– 드라이버에 사용할 메모리의 크기입니다.spark.driver.cores– 드라이버에 사용할 가상 코어의 수입니다.spark.executor.instances– 익스큐터의 수입니다.spark.dynamicAllocation.enabled가 true로 설정된 경우 외에는 이 파라미터를 설정합니다.spark.default.parallelism– 사용자가 파티션 수를 설정하지 않았을 때join,reduceByKey및parallelize와 같은 변환에 의해 반환된 RDD(탄력적 분산 데이터 세트)의 파티션 수 기본값입니다.
Amazon EMR은 릴리스 안내서를 통해 Spark 파라미터의 기본값이 어떻게 설정되는지에 대한 고수준 정보를 제공합니다. 이러한 값은 클러스터의 코어 및 작업 인스턴스 유형을 기반으로 spark-defaults 설정에 자동으로 설정됩니다.
클러스터에서 사용 가능한 모든 리소스를 사용하려면 maximizeResourceAllocation 파라미터를 true로 설정합니다. 이 EMR 특정 옵션은 코어 인스턴스 그룹의 인스턴스에 있는 익스큐터에 사용 가능한 최대 컴퓨팅 및 메모리 리소스를 계산한 다음, spark-defaults 설정에 이러한 파라미터를 설정합니다. 이 설정을 구성해도 일반적으로 기본 수가 낮게 설정되어 있으며 애플리케이션은 클러스터가 전체 성능을 사용하지 않습니다. 예를 들어, 대형 클러스터의 경우 더 많은 병렬 프로세스가 가능하더라도 spark.default.parallelism의 기본값은 사용 가능한 가상 코어 수의 2배에 불과합니다.
YARN의 Spark는 워크로드를 기반으로 Spark 애플리케이션에 사용되는 익스큐터의 수를 동적으로 조정할 수 있습니다. Amazon EMR 릴리스 버전 4.4.0 이상에서는 동적 할당이 기본적으로 활성화되어 있습니다(Spark 설명서의 설명 참조).
spark.dynamicAllocation.enabled 속성의 문제는 하위 속성의 설정이 필요하다는 것입니다. 하위 속성의 일부 예로는 spark.dynamicAllocation.initialExecutors, minExecutors 및 maxExecutors가 있습니다. 대부분의 경우, 클러스터에서 올바른 익스큐터 수를 사용하려면 하위 속성이 필요합니다. 이는 특히 여러 애플리케이션을 동시에 실행하려고 할 때 필요합니다. 하위 속성을 설정하려면 올바른 수를 찾기 위해 많은 시행 착오를 거쳐야 합니다. 올바른 수가 아닌 경우 용량을 예약한 후 실제로 사용하지 않게 될 수 있습니다. 이는 리소스 낭비 또는 다른 애플리케이션의 메모리 오류를 유발합니다.
모범 사례 2:
spark.dynamicAllocation.initialExecutors/minExecutors/maxExecutors에 대한 수가 올바르게 결정된 경우에만spark.dynamicAllocation.enabled를 true로 설정합니다. 그렇지 않은 경우spark.dynamicAllocation.enabled를 false로 설정하고 드라이버 메모리, 익스큐터 메모리 및 CPU 파라미터를 직접 제어합니다. 이렇게 하려면 각 애플리케이션에 대해 이러한 속성을 계산하고 설정합니다(아래 예 참조).
Amazon S3의 파일 저장소 수천 개의 걸쳐 200테라바이트의 데이터를 처리한다고 가정해 보겠습니다. 또한, 이 작업을 1개의 r5.12xlarge 마스터 노드와 19개의 r5.12xlarge 코어 노드로 구성된 Amazon EMR 클러스터를 통해 수행한다고 가정해 보겠습니다. 각 r5.12xlarge 인스턴스는 48개의 가상 코어(vCPU) 및 384GB의 RAM을 가지고 있습니다. 이 모든 계산은 프로덕션용으로 권장되는 --deploy-mode 클러스터를 위한 것입니다.
다음 목록은 앞의 사례를 예로 사용하여 주요 Spark 속성 중 일부를 설정하는 방법을 설명합니다.
spark.executor.cores
익스큐터에 많은 수의 가상 코어를 할당하면 익스큐터 수가 적어지고 병렬 프로세스가 감소됩니다. 적은 수의 가상 코어를 할당하면 익스큐터 수가 많아져 더 많은 양의 I/O 작업을 유발합니다. 기록 데이터에 따라, 최적의 결과를 얻으려면 크기에 상관 없이 모든 클러스터에서 각 익스큐터에 5개의 가상 코어를 구성할 것이 권장됩니다.
앞에서 설명한 클러스터의 경우, 속성 spark.executor.cores는 다음과 같이 할당되어야 합니다: spark.executors.cores = 5 (vCPU)
spark.executor.memory
익스큐터당 가상 코어의 수를 결정한 후에는 이 속성의 계산이 훨씬 쉬워집니다. 먼저, 총 가상 코어 및 익스큐터 가상 코어 수를 사용하여 인스턴스당 익스큐터 수를 얻습니다. 총 가상 코어 수에서 Hadoop 데몬을 위해 예약해 둘 가상 코어 1개를 감산합니다.
인스턴스당 익스큐터 수 = (인스턴스당 총 가상 코어 수 - 1)/ spark.executors.cores
인스턴스당 익스큐터 수 = (48 - 1)/ 5 = 47 / 5 = 9 (가까운 정수로 내림)그런 다음 인스턴스당 RAM 합계 및 인스턴스당 익스큐터 수를 사용하여 총 익스큐터 메모리를 얻습니다. 1GB는 Hadoop 데몬을 위해 남겨둡니다.
이 총 익스큐터 메모리는 익스큐터 메모리와 오버헤드(spark.yarn.executor.memoryOverhead)를 포함합니다. 이 총 익스큐터 메모리의 10%를 메모리 오버헤드에 할당하고 나머지 90%는 익스큐터 메모리에 할당합니다.
spark.driver.memory
이 속성은 spark.executors.memory와 같도록 설정할 것이 권장됩니다.
spark.driver.cores
이 속성은 spark.executors.cores와 같도록 설정할 것이 권장됩니다.
spark.executor.instances
이 속성은 익스큐터 수와 총 인스턴스 수를 곱하여 계산합니다. 드라이버를 위해 1개의 익스큐터를 남겨둡니다.
spark.default.parallelism
이 속성은 다음 공식을 사용하여 설정합니다.
경고: 이 계산에서는 1,700개의 파티션이 도출되지만 고객은 각 파티션의 크기를 예측하고 coalesce 또는 repartition을 사용하여 적절히 이 수를 조절할 것이 권장됩니다.
데이터 프레임의 경우, 파라미터 spark.sql.shuffle.partitions을 spark.default.parallelism과 함께 구성합니다.
앞에서 설명한 파라미터는 모든 Spark 애플리케이션에 있어 매우 중요하지만 다음의 파라미터도 다른 시간 초과 및 메모리 관련 오류를 피하고 원활하게 애플리케이션을 실행하는 데 도움이 됩니다. spark-defaults 구성 파일에 이러한 파라미터를 설정하는 것이 좋습니다.
spark.network.timeout– 모든 네트워크 트랜잭션에 대한 시간 초과 값입니다.spark.executor.heartbeatInterval– 드라이버에 대한 각 익스큐터의 하트비트 간격입니다. 이 값은spark.network.timeout보다 월등히 작아야 합니다.spark.memory.fraction– Spark 실행 및 스토리지에 사용되는 JVM 히프 공간의 비율입니다. 이 수가 낮을수록 누출 및 캐싱된 데이터 제거가 더 자주 발생합니다.spark.memory.storageFraction– 리전 크기 중 spark.memory.fraction에 의해 예비되는 비율로 표현됩니다. 이 수가 높을수록 실행에 사용 가능한 유휴 메모리가 적어집니다. 이는 곧 작업이 디스크로 더 자주 누출됨을 의미합니다.spark.yarn.scheduler.reporterThread.maxFailures– YARN에서 애플리케이션을 장애로 처리하기 전 허용되는 최대 익스큐터 실패 횟수입니다.spark.rdd.compress– 이 속성을 true로 설정하면 RDD 압축을 통해 일부 추가 CPU 시간을 소비하는 대신 상당한 공간을 절약할 수 있습니다.spark.shuffle.compress– 이 속성을 true로 설정하면 맵 출력이 압축되어 공간을 절약합니다.spark.shuffle.spill.compress– 이 속성을 true로 설정하면 셔플 중 누출된 데이터가 압축됩니다.spark.sql.shuffle.partitions– 결합 및 집계를 위한 파티션 수를 설정합니다.spark.serializer– 데이터를 직렬화 또는 역직렬화할 시리얼라이저를 설정합니다. 저는 개인적으로 Java 기본 시리얼라이저보다 빠르고 간결한 Kyro(org.apache.spark.serializer.KryoSerializer)를 시리얼라이저로 선호합니다.
앞에서 설명한 각 파라미터에 대한 자세한 내용은 Spark 설명서를 참조하십시오.
효율적인 Spark 프로세싱을 위해 다음과 같은 프로그래밍 기법을 추가로 고려할 것이 권장됩니다.
coalesce– 더 적은 데이터 이동을 허용하기 위해 파티션 수를 줄입니다.repartition– 파티션 수를 줄이거나 늘이고coalesce와 달리 데이터의 완전 셔플을 수행합니다.partitionBy– 데이터를 수평으로 여러 파티션에 걸쳐 분산시킵니다.bucketBy– 해시 열을 기반으로 데이터를 관리가 보다 용이한 조각(버킷)으로 분해합니다.cache/persist– 데이터 세트를 전체 클러스터 규모의 인 메모리 캐시로 가져옵니다. 이 방식은 작은 검색 데이터 세트를 쿼리하거나 반복 알고리즘을 실행하는 등 데이터를 반복적으로 액세스할 때 유용합니다.
모범 사례 3: 앞의 추가 속성을 애플리케이션 요구 사항을 기반으로 신중하게 계산합니다. Spark 애플리케이션을 제출(
spark-submit)할 때 또는SparkConf객체 내에서spark-defaults에 이러한 속성을 적절히 설정합니다.
3. 메모리를 효과적으로 지우기 위한 올바른 가비지 컬렉터 구현
가비지 컬렉션은 일부 경우에 메모리 부족 오류를 유발할 수 있습니다. 여기에는 애플리케이션에 여러 개의 대규모 RDD가 있는 경우가 포함됩니다. 다른 경우는 작업 실행 메모리와 RDD 캐시된 메모리 사이에 간섭이 있을 때 발생합니다.
여러 개의 가비지 컬렉터를 사용하면 오래된 객체를 제거하고 새 객체를 메모리에 배치할 수 있습니다. 그러나, 최신 G1GC(Garbage First Garbage Collector)는 기존 가비지 컬렉터의 지연 시간 및 처리량 제한 문제를 해결해 줍니다.
모범 사례 4: Spark를 통해 대량의 데이터를 처리할 때에는 항상 가비지 컬렉터를 설치합니다.
파라미터 -XX:+UseG1GC는 G1GC 가비지 컬렉터를 사용해야 함을 지정합니다. (기본값은 -XX:+UseParallelGC) 가비지 컬렉션의 빈도와 실행 시간을 이해하려면 파라미터 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps를 사용합니다. 가비지 컬렉션을 보다 빠르게 초기화하려면 InitiatingHeapOccupancyPercent를 35로 설정합니다(기본값은 0.45). 이렇게 하면 총 메모리에 가비지 컬렉션을 수행하여 상당한 시간이 소요될 가능성이 제거됩니다. 다음은 한 예입니다.
4. YARN 구성 파라미터 설정
모든 Spark 구성 속성을 계산하고 올바르게 설정한 경우에도 가상 메모리가 OS에 의해 과도하게 설정된 경우 드물게 가상 메모리 부족 오류가 발생할 수 있습니다. 이러한 애플리케이션 장애를 방지하려면 YARN 사이트 설정에 다음과 같은 플래그를 설정합니다.
모범 사례 5: 가상 및 물리적 메모리 확인 플래그를 항상 false로 설정합니다.
5. 디버깅 및 모니터링 수행
Spark 구성 옵션이 어디에서 오는지에 대한 세부 정보를 얻으려면 spark-submit을 –verbose 옵션과 함께 실행할 수 있습니다. 또한, Ganglia 및 Spark UI를 사용하여 애플리케이션 진행률, 클러스터 RAM 사용률, 네트워크 I/O 등을 모니터링할 수 있습니다.
다음 예에서는 Ganglia 그래프를 사용하여 구성된 Spark 애플리케이션과 구성되지 않은 Spark 애플리케이션 사이의 결과를 비교해 보겠습니다.
설명된 방식을 따라 구성된 Spark 애플리케이션은 다음 사양의 Amazon EMR 클러스터에서 메모리 문제 없이10TB 데이터를 성공적으로 처리할 수 있습니다.
- 1개의 r5.12xlarge 마스터 노드
- 19개의 r5.12xlarge 코어 노드
- 총 8TB RAM
- 총 960개의 가상 CPU
- 170개의 익스큐터 인스턴스
- 익스큐터당 가상 CPU 5개
- 익스큐터당 37GB 메모리
- 병렬 프로세스 1,700개
다음 Ganglia 그래프를 참조하십시오.


동일한 클러스터에서 기본 구성을 가진 동일한 Spark 애플리케이션을 실행하는 경우 물리적 메모리 부족 오류와 함께 애플리케이션이 실패합니다. 이는 기본 구성(2개의 익스큐터 인스턴스, 병렬 프로세스 2개, 익스큐터당 vCPU 1개, 익스큐터당 8GB 메모리)이 10TB 데이터를 처리하기에 충분하지 않기 때문입니다. 클러스터에 7.8TB의 메모리가 있지만 기본 구성이 애플리케이션에서 16GB 메모리만 사용할 수 있도록 제한하고 있으므로 다음과 같은 메모리 부족 오류가 발생합니다.
또한 대규모 데이터 세트의 경우, 기본 가비지 컬렉터로는 병렬로 작업을 실행하기에 충분한 수준의 효율적인 메모리 지우기가 이루어지지 않기 때문에 잦은 장애가 발생합니다. 다음 차트는 기본 가비지 컬렉터와 G1GC 가비지 컬렉터의 RAM 사용량 및 가비지 컬렉션을 비교하는 데 도움이 됩니다. G1GC에서는 RAM 사용량이 5TB 미만으로 유지됩니다(그래프의 파란색 영역 참조).

기본 가비지 컬렉터(CMS)에서는 RAM 사용량이 5TB를 초과합니다. 이렇게 되면 여러 작업을 동시에 실행할 때 Spark 작업이 실패할 수 있습니다.

EMR 인스턴스 템플릿 및 구성 방법
Spark 및 YARN 구성 파라미터를 설정하는 방법은 여러 가지가 있습니다. 그 중 하나는 EMR 클러스터를 생성할 때 이러한 파라미터를 전달하는 것입니다.
이렇게 하려면 Amazon EMR 콘솔의 Edit software settings 섹션에 적절히 업데이트된 구성 템플릿을 입력할 수 있습니다(Enter configuration). 또는 S3에서 구성을 전달할 수 있습니다(Load JSON from S3).

다음은 샘플 값을 사용한 구성 템플릿입니다. Spark 애플리케이션을 성공적으로 구축하려면 최소한 다음의 파라미터를 계산하고 설정해야 합니다.
마무리
이 글에서는 Amazon EMR에서 Spark 애플리케이션을 제출할 때 발생할 수 있는 메모리 부족 오류와 그 원인 및 이러한 오류를 방지할 수 있는 일련의 모범 사례에 대해 설명했습니다.
이러한 모범 사례는 다양한 Spark 구성 속성에 대한 연구와 이해 및 여러 Spark 애플리케이션의 테스트를 통해 정리되었습니다. 이러한 모범 사례는 대부분의 메모리 부족 시나리오에 적용되지만 드물게 해당 사례가 적용되지 않는 시나리오도 일부 있을 수 있습니다. 그러나 이 블로그 게시물에서는 파라미터를 조정하여 Spark 애플리케이션을 성공적으로 실행하는 데 필요한 모든 세부 정보를 제공한다고 생각됩니다.
이 글은 AWS Bigdata 블로그의 Best practices for successfully managing memory for Apache Spark applications on Amazon EMR의 한국어 번역으로 AWS 데이터분석 전문 솔루션즈 아키텍트인 정세웅님이 감수하였습니다.
 Karunanithi Shanmugam은 AWS Tech and Finance의 데이터 엔지니어입니다.
Karunanithi Shanmugam은 AWS Tech and Finance의 데이터 엔지니어입니다.