- AWS Solutions Library
- Guidance for Intelligent Document Processing on AWS

Guidance for Intelligent Document Processing on AWS
Overview
This Guidance demonstrates how to implement Intelligent Document Processing (IDP) using AWS AI agents to transform traditional document-heavy workflows into streamlined, automated processes. It helps organizations significantly reduce operational costs while accelerating decision-making and customer service delivery. The solution shows how businesses can eliminate manual data entry, minimize errors, and reallocate human resources to higher-value tasks. Furthermore, it demonstrates how to leverage extracted document data for advanced analytics and machine learning applications, enabling real-time business insights, fraud detection, and new revenue opportunities. This architecture brings together proven AWS services to help organizations modernize their document processing workflows and achieve greater operational efficiency.
How it works
Prompt Flows
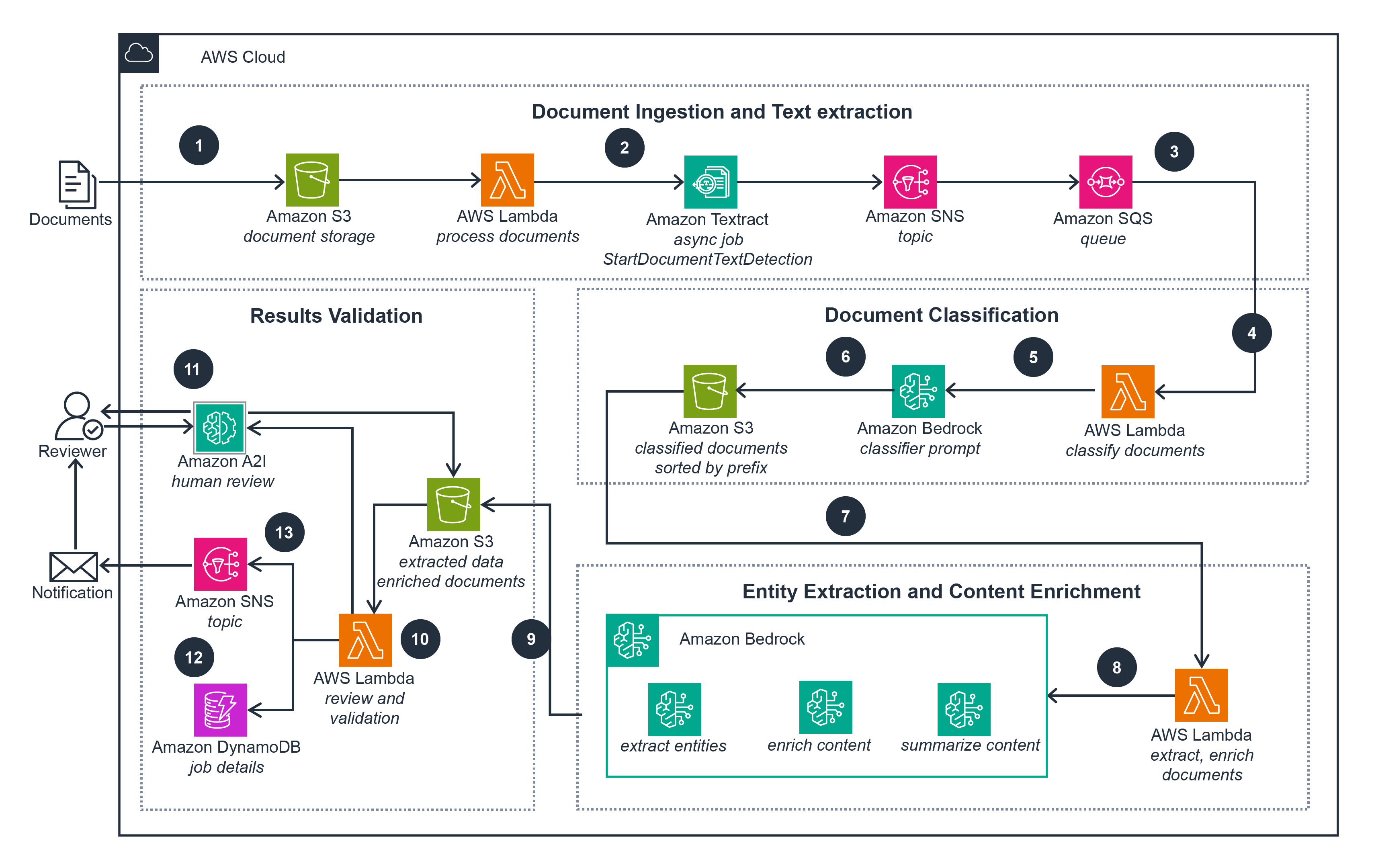
This architecture diagram shows how you can automate document processing with AWS artificial intelligence and machine learning (AI/ML) services, allowingyou to speed up business processes, improve decision quality, and reduce overall costs.
AgentCore: Overview
This architecture implements an intelligent document processing system using Amazon Bedrock AgentCore, where multiple specialized agents collaborate through graph-based workflows to automatically identify, extract, validate, and learn from business documents with minimal human intervention.

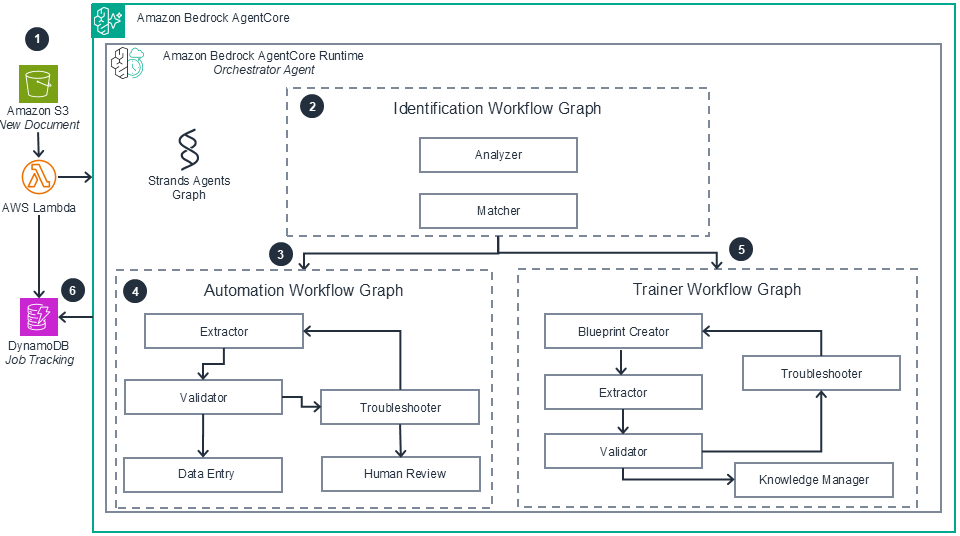
AgentCore: Multi-Agent Orchestration
This diagram details the multi-agent workflow running within Amazon Bedrock AgentCore Runtime from the previous architecture, showing how specialized AI agents collaborate through graph-based orchestration to automatically process documents, with dual workflows handling known document types through automated extraction and validation, while unknown documents trigger blueprint creation with human oversight for continuous system learning.
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
The Intelligent Document Processing architecture can be fully deployed using infrastructure as code (IaC) methodologies. The serverless infrastructure components can be provisioned using the AWS Cloud Development Kit (CDK) found below and orchestrated through the low-code visual workflow service, AWS Step Functions. This automation can be seamlessly integrated into your development pipeline, enabling rapid iteration and consistent deployments. Observability for this Guidance is achieved through the use of Amazon CloudWatch logs, which capture telemetry data from the AWS AI agents employed, such as Amazon Textract and Amazon Comprehend.
The AI services in this Guidance support security for both resting and transitional data. Amazon Textract, Amazon Comprehend, and Amazon Comprehend Medical support encryption at rest with Amazon S3 buckets and AWS Key Management Service (AWS KMS). In addition, Amazon Textract provides an asynchronous API and Amazon Comprehend Medical services support in-memory data processing.
In addition, Intelligent Document Processing can be orchestrated with a serverless backend with AWS Identity and Access Management (IAM) for authentication and secure validation. You can also define separation of access control per user role. For example, you can give the owner full access to all documents, but allow an operator to access only de-identified documents.
Finally, this architecture includes the capability to categorize documents accurately by using Amazon Comprehend to detect personally identifiable information (PII). Also, when you want to detect Protected Health Information (PHI), use Amazon Comprehend Medical PHI identification and redaction options to scan clinical text.
Read the Security whitepaperThe Intelligent Document Processing architecture uses managed, Regional AI services provided by AWS. The reliability and availability of these services within the selected AWS Region are maintained by AWS. The inherent nature of the managed AI services helps ensure resilience to failures and high availability. Should you choose to use Amazon S3 as the scalable data store, it is recommended to consider enabling Amazon S3 cross-Region replication. This additional measure can further increase the reliability of this and provide access to disaster recovery options.
Read the Reliability whitepaperThe serverless and event-driven architecture of this Guidance promotes efficiency, as resources are not wasted when documents are not being processed. It can be scaled in a particular Region to accommodate for large scale document processing, achieved by increasing the call rates for the AI agents and Lambda. You can also design a serverless decoupled architecture with Amazon SNS and Amazon SQS for concurrent processing of multiple documents. Lastly, Intelligent Document Processing can be configured to operate in real-time with response times in seconds, or in asynchronous mode, depending on your specific requirements.
Intelligent Document Processing minimizes costs by using a serverless, event-driven architecture, where you only pay for the time and resources consumed during document processing. Amazon Comprehend offers options to train custom models in addition to utilizing pre-defined entity extraction capabilities. For urgent, real-time document processing requirements, the Amazon Comprehend resource endpoints can be used for custom models. However, if your use case can accommodate asynchronous or batch processing, it is recommended to use asynchronous jobs for Amazon Comprehend custom models to optimize costs.
Read the Cost Optimization whitepaperBy extensively using managed services and dynamic scaling capabilities, the environmental impact of the backend infrastructure supporting this Guidance is minimized. AWS managed services handle the provisioning, scaling, and maintenance of the underlying compute, storage, and networking resources, offloading the operational overhead you and your team. Additionally, the dynamic scaling capabilities inherent in managed services and serverless architectures helps ensure that resources are provisioned and utilized only when needed to process incoming workloads, preventing over-provisioning and optimizing the environmental footprint of the backend services powering this Guidance.
Disclaimer
The sample code; software libraries; command line tools; proofs of concept; templates; or other related technology (including any of the foregoing that are provided by our personnel) is provided to you as AWS Content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content in your production accounts, or on production or other critical data. You are responsible for testing, securing, and optimizing the AWS Content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
References to third-party services or organizations in this Guidance do not imply an endorsement, sponsorship, or affiliation between Amazon or AWS and the third party. Guidance from AWS is a technical starting point, and you can customize your integration with third-party services when you deploy the architecture.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages