AWS Glue
Khám phá, chuẩn bị và tích hợp tất cả dữ liệu của bạn ở mọi quy mô
Tại sao nên sử dụng AWS Glue?
Chuẩn bị dữ liệu để thu về kết quả chất lượng là bước đầu tiên trong dự án phân tích hoặc AI. AWS Glue là dịch vụ phi máy chủ, giúp quá trình tích hợp trở nên đơn giản, nhanh chóng và tiết kiệm hơn. Bạn có thể khám phá và kết nối với hơn 100 nguồn dữ liệu đa dạng, quản lý dữ liệu trong danh mục dữ liệu tập trung, đồng thời tạo, chạy và theo dõi quy trình dữ liệu một cách trực quan khi tải dữ liệu vào hồ dữ liệu, kho dữ liệu và lakehouse. Tính năng AI tạo sinh được tích hợp sẵn có khả năng hỗ trợ thông minh cho hoạt động tạo ETL và khắc phục sự cố Spark, cho phép bạn hiện đại hóa tác vụ Apache Spark và phát triển nhanh hơn.

Tích hợp dữ liệu bằng AWS Glue trong thế hệ Amazon SageMaker tiếp theo
Khả năng tích hợp dữ liệu có thể điều chỉnh quy mô, phi máy chủ và tiết kiệm chi phí của AWS Glue trong thế hệ Amazon SageMaker tiếp theo cho phép bạn quản lý và xây dựng khối lượng công việc tại một nơi.

Lợi ích
-
AWS Glue cung cấp tất cả chức năng cần thiết cho quá trình tích hợp dữ liệu để bạn có thể nhận được thông tin chuyên sâu và nhanh chóng đưa dữ liệu vào sử dụng. AWS Glue cung cấp bộ công cụ phi máy chủ, được quản lý toàn phần với tính năng ETL tích hợp sẵn, khám phá sơ đồ và tích hợp liên dịch vụ, cho phép bạn thiết kế và tự động hóa quy trình dữ liệu hiện đại.
AWS Glue tự động mở rộng quy mô ngay cả những công việc xử lý dữ liệu đòi hỏi nhiều tài nguyên nhất từ gigabyte lên petabyte mà không cần quản lý cơ sở hạ tầng và bạn chỉ trả tiền cho các tài nguyên được sử dụng.
-
AWS Glue giúp loại bỏ nhu cầu quản lý cơ sở hạ tầng nhờ khả năng cung cấp quy trình dữ liệu phi máy chủ tích hợp tính năng giám sát và lên lịch, cho phép đội ngũ tập trung xây dựng quy trình công việc dữ liệu thay vì duy trì máy chủ.
-
Nhận sự trợ giúp từ AI trong suốt hành trình tích hợp dữ liệu – từ việc tự động tạo mã ETL đến hiện đại hóa các tác vụ Spark. AWS Glue cung cấp khả năng tạo mã thông minh, nâng cấp Spark được hỗ trợ bởi AI và khắc phục sự cố Spark được tích hợp sẵn.
-
Tích hợp dữ liệu từ mọi vị trí nhờ khả năng kết nối nhanh chóng và dễ dàng với vô số nguồn dữ liệu trong thế hệ Amazon SageMaker tiếp theo. Tạo dự án xử lý dữ liệu kết hợp giữa AWS Glue, Amazon Athena, Amazon EMR và MWAA – tất cả trong Amazon SageMaker – và hưởng lợi từ trải nghiệm giám sát và quản lý chung. Khả năng xử lý dữ liệu của AWS Glue có sẵn trong sổ tay của Amazon SageMaker và ETL trực quan của Amazon SageMaker.
Trường hợp sử dụng
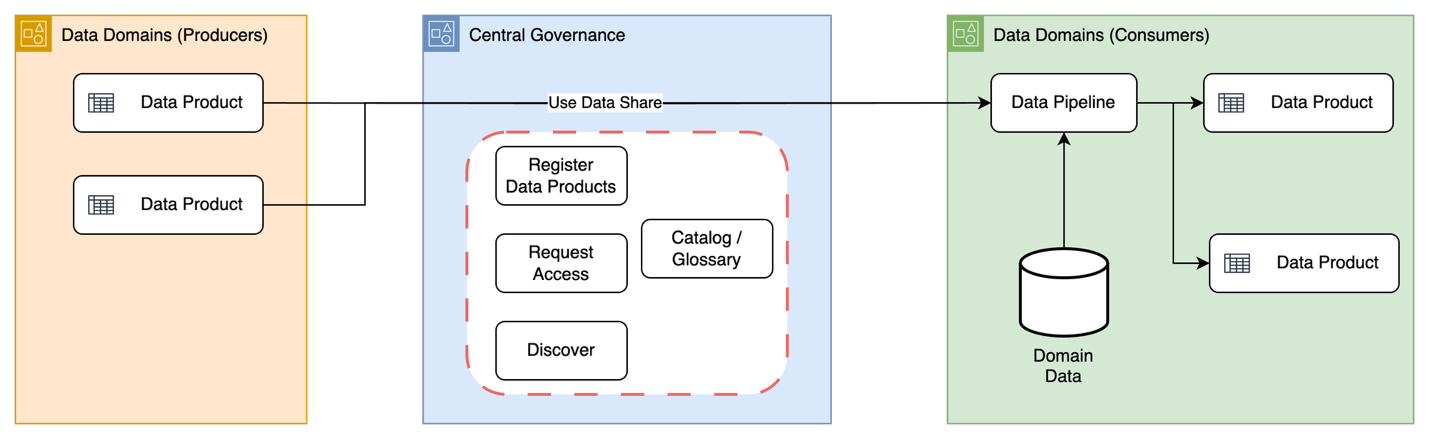
Đơn giản hóa việc quản lý đường ống ETL
Loại bỏ khâu quản lý cơ sở hạ tầng bằng khả năng cung cấp tự động và quản lý nhân lực, đồng thời hợp nhất toàn bộ nhu cầu tích hợp dữ liệu của bạn vào một dịch vụ duy nhất.
Tương tác khám phá, thử nghiệm và xử lý dữ liệu
Với phiên tương tác AWS Glue, kỹ sư dữ liệu có thể tương tác khám phá và chuẩn bị dữ liệu bằng môi trường phát triển tích hợp (IDE) hoặc sổ tay tùy chọn.
Khám phá dữ liệu hiệu quả
Nhanh chóng xác định dữ liệu trên AWS, tại chỗ và trong các đám mây khác, rồi đưa ngay dữ liệu này vào trạng thái sẵn sàng để truy vấn và chuyển đổi.
Hỗ trợ nhiều khung xử lý và khối lượng công việc
Hỗ trợ nhiều khung xử lý dữ liệu khác nhau, chẳng hạn như ETL và ELT, cũng như nhiều khối lượng công việc khác nhau dễ dàng hơn, bao gồm khối lượng công việc theo lô, lô nhỏ và truyền phát.
Thông tin mới




Hôm nay, bạn đã tìm thấy nội dung mình cần chưa?
Chia sẻ với chúng tôi để chúng tôi có thể cải thiện chất lượng nội dung trên trang