亚马逊AWS官方博客
Amazon MSK Connect 简介 — 使用托管式连接器在 Apache Kafka 集群之间流式传输数据
Apache Kafka 是一个开源平台,可用于构建实时的流式处理数据管道和应用程序。在 re:Invent 2018 上,我们介绍了 Amazon Managed Streaming for Apache Kafka,这是一项完全托管的服务,可用于轻松构建和运行使用 Apache Kafka 处理流数据的应用程序。
使用 Apache Kafka 时,您可以捕获来自 IoT 设备、数据库更改事件和网站点击流等来源的实时数据,然后将它们传送到数据库和持久性存储等目标。
Kafka Connect 是 Apache Kafka 的一个开源组件,它提供了一个框架,用于连接数据库、键值存储、搜索索引和文件系统等外部系统。但是,手动运行 Kafka Connect 集群需要您计划和预置所需的基础设施,处理集群操作,并根据负载变化进行扩展。
今天,我们宣布推出一项新功能,让您更轻松地管理 Kafka Connect 集群。通过 MSK Connect,您只需单击几下,即可使用 Kafka Connect 配置和部署连接器。MSK Connect 预置所需的资源并设置集群。它持续监控连接器的运行状况和交付状态,修补和管理底层硬件,并自动扩展连接器以匹配吞吐量的变化。因此,您可以将资源集中在构建应用程序上,而不是管理基础设施。
MSK Connect 与 Kafka Connect 完全兼容,这意味着您无需更改代码即可迁移现有连接器。您不需要 MSK 集群即可使用 MSK Connect。它支持与 Amazon MSK、Apache Kafka 和 Apache Kafka 兼容的集群,将它们作为来源和接收器。只要 MSK Connect 可以私密连接到集群,这些集群就可以自我管理或由 AWS 合作伙伴和第三方管理。
通过 Amazon Aurora 和 Debezium 使用 MSK Connect
为测试 MSK Connect,我使用它从我的一个数据库中流式传输数据更改事件。为此,我使用 Debezium,它是一个基于 Apache Kafka 构建的开源分布式平台,用于捕获变更数据。
我使用与 MySQL 兼容的 Amazon Aurora 数据库作为来源,并使用 Debezium MySQL 连接器,其设置如以下架构图所示:
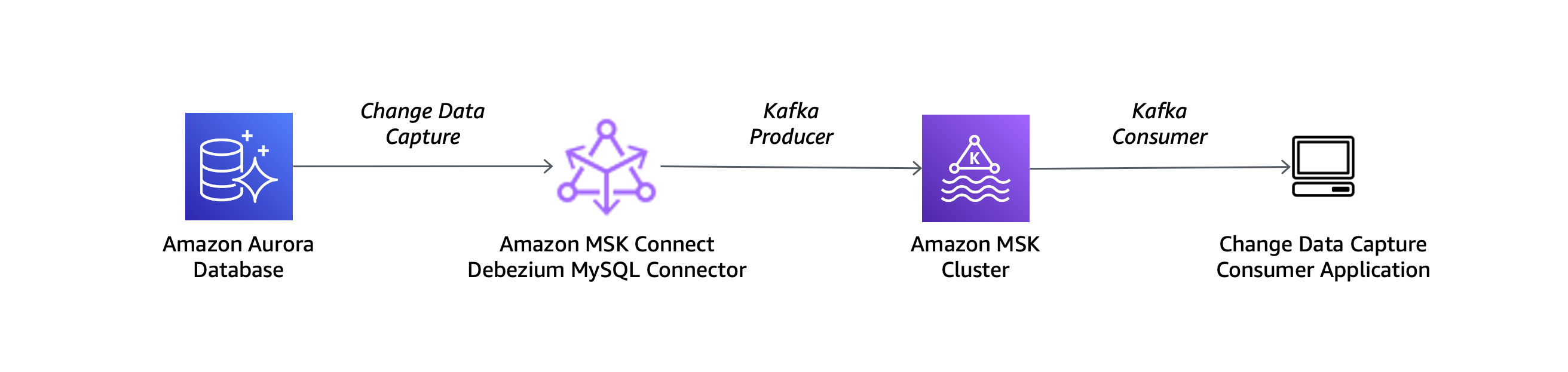
要通过 Debezium 使用我的 Aurora 数据库,我需要打开数据库集群参数组中的二进制日志记录。我按照如何为我的 Amazon Aurora MySQL 集群打开二进制日志记录一文中的步骤进行操作。
接下来,我需要为 MSK Connect 创建一个自定义插件。自定义插件是一组 JAR 文件,其中包含一个或多个连接器、转换或转换器的实现。Amazon MSK 将插件安装在运行连接器的连接集群的工件上。
我从 Debezium 网站上下载了 MySQL 连接器插件的最新稳定发布版本。MSK Connect 接受 ZIP 或 JAR 格式的自定义插件,因此,我将下载的存档转换为 ZIP 格式,并将 JAR 文件保留在主目录中:
然后,我使用 AWS Command Line Interface (CLI) 将自定义插件上传到 Amazon Simple Storage Service (Amazon S3) 存储桶,该存储桶位于我用于 MSK 连接的同一个 AWS 区域:
在Amazon MSK 控制台上有一个新的 MSK Connect 部分。我查看连接器并选择 Create connector(创建连接器)。之后,我创建一个自定义插件,浏览我的 S3 存储桶,并选择我之前上传的自定义插件 ZIP 文件。

我输入插件的名称和描述,然后选择 Next(下一步)。

现在,我已完成自定义插件的配置,接下来开始创建连接器。我输入连接器的名称和描述。

我可以选择使用自我管理的 Apache Kafka 集群或由 MSK 管理的集群。我选择了一个为使用 IAM 身份验证而配置的 MSK 集群。我选择的 MSK 集群与我的 Aurora 数据库位于同一个 virtual private cloud (VPC) 中。要进行连接,MSK 集群和 Aurora 数据库应使用 VPC 的默认安全组。为简单起见,我使用的集群配置是将 auto.create.topics.enable 设置为 true。
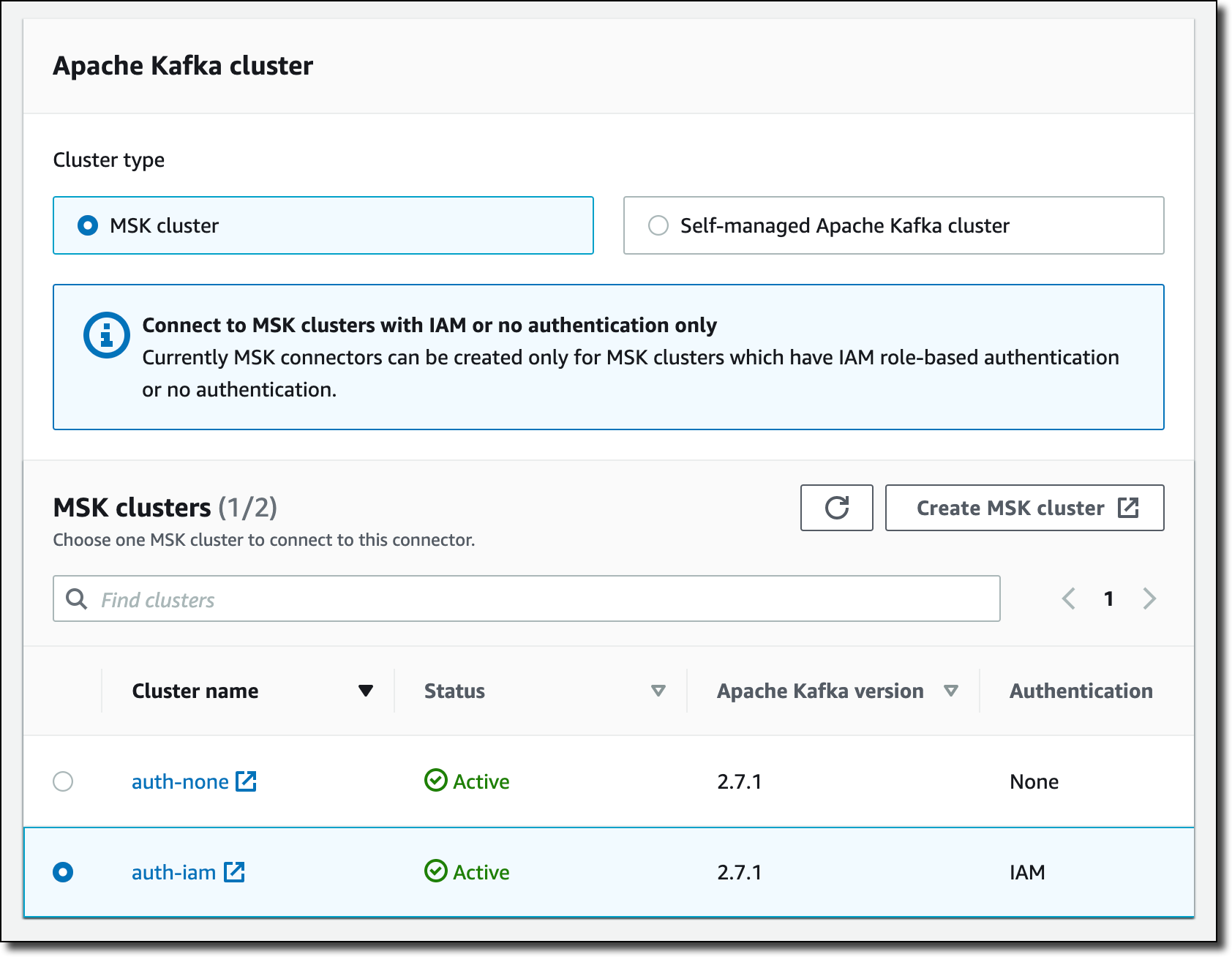
在 Connector configuration(连接器配置)中,我使用以下设置:
其中一些设置是通用的,应为任何连接器指定设置。例如:
connector.class是连接器的 Java 类。tasks.max是应为此连接器创建的最大任务数。
其他设置特定于 Debezium MySQL 连接器:
database.hostname包含我的 Aurora 数据库的写入器实例终端节点。database.server.name是数据库服务器的逻辑名称。它用于 Debezium 创建的 Kafka 主题的名称。database.include.list包含指定服务器托管的数据库的列表。database.history.kafka.topic是 Debezium 在内部使用的 Kafka 主题,用于跟踪数据库架构更改。database.history.kafka.bootstrap.servers包含 MSK 集群的引导服务器。- 最后 8 行(
database.history.consumer.*和database.history.producer.*) 启用 IAM 身份验证,以访问数据库历史记录主题。
在 Connector capacity(连接器容量)中,我可以在自动扩展容量或预配置容量之间选择。对于此设置,我选择 Autoscaled(自动扩展)并将所有其他设置保留为默认设置。

使用自动扩展容量,我可以配置以下参数:
- 每个工件的 MSK Connect Unit (MCU) 计数 — 每个 MCU 提供 1 个 vCPU 的计算和 4 GB 内存。
- 工件数量的最小和最大值。
- 自动扩缩使用率阈值 — 用于触发自动扩展的 MCU 消耗的上限和下限目标使用率阈值(以百分比表示)。
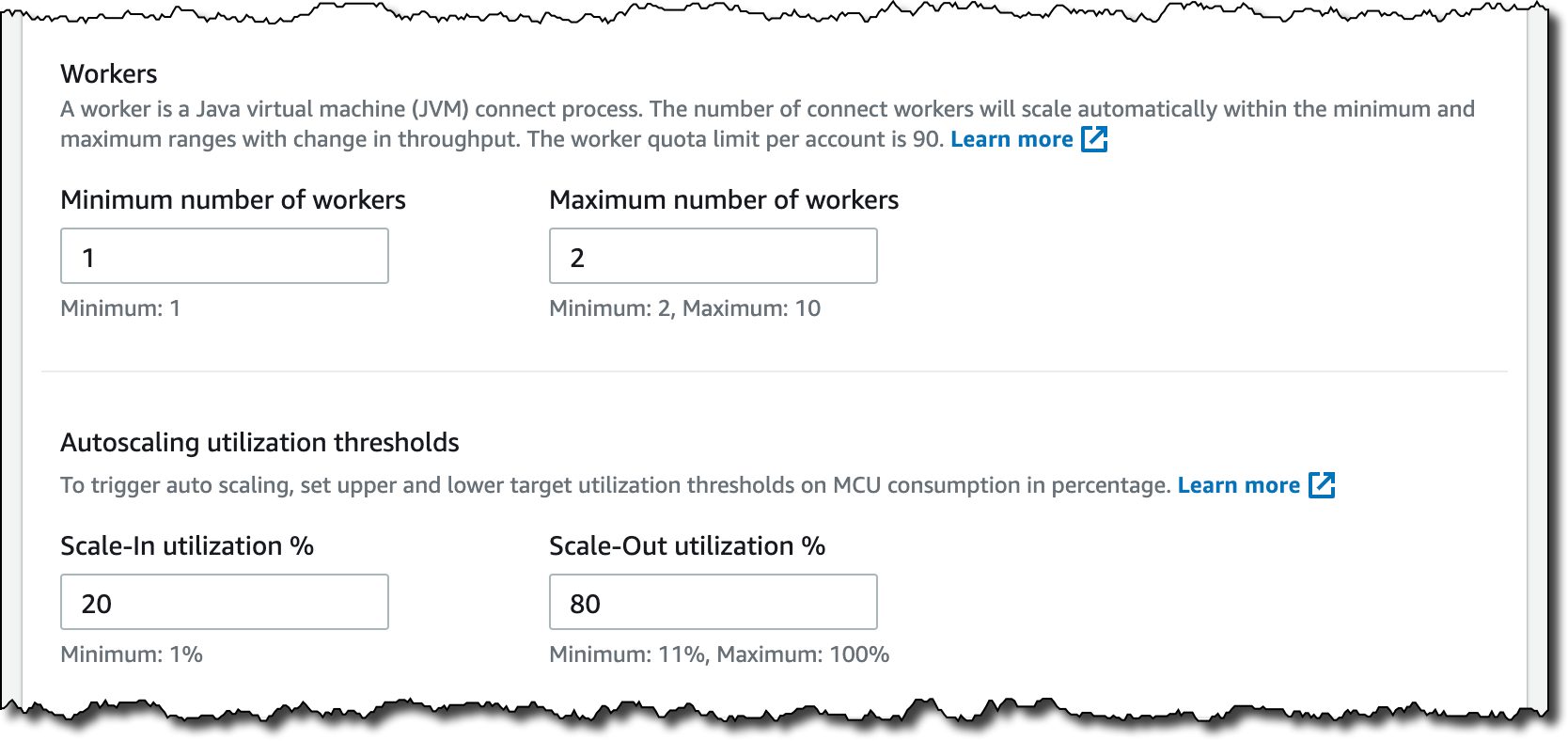
这里总结了连接器的 MCU、内存和网络带宽的最小值和最大值。

对于 Worker configuration(工件配置),您可以使用 Amazon MSK 提供的默认配置或自行配置。我在设置时使用了默认设置。
在 Access permissions(访问权限)中,我创建了一个 IAM 角色。在可信实体中,我添加了 kafkaconnect.amazonaws.com,以允许 MSK Connect 担任该角色。
MSK Connect 使用该角色与 MSK 集群和其他 AWS 服务进行交互。我在设置时添加了:
- 向我之前创建的 Amazon CloudWatch 日志组写入日志的权限。
- 通过 IAM 向我的 MSK 集群进行身份验证的权限。
Debezium 连接器需要访问集群配置才能找到用于创建历史记录主题的复制系数。因此,我向权限策略添加了 kafka-cluster:DescribeClusterDynamicConfiguration action(相当于 Apache Kafka 的 DESCRIBE_CONFIGS cluster ACL)。
根据您的配置,您可能需要向角色添加更多权限(例如,连接器需要访问 S3 存储桶等其他 AWS 资源)。如果是这样,您应在创建连接器之前添加权限。
在 Security(安全性)中,身份验证和传输中加密的设置取自 MSK 集群。
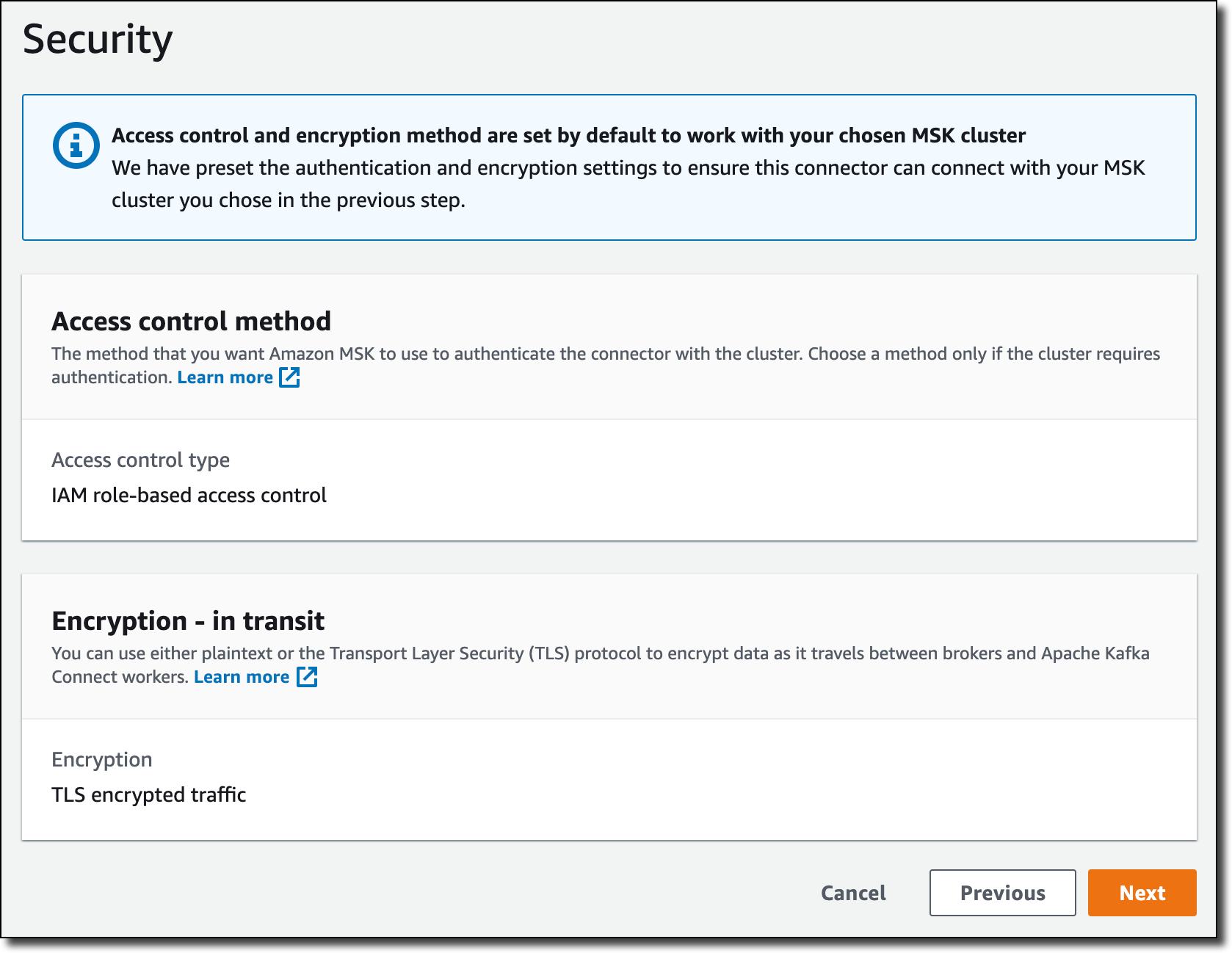
在 Logs(日志)中,我选择将日志传送到 CloudWatch Logs,以获取有关连接器执行的更多信息。通过 CloudWatch Logs,我可以使用 CloudWatch Logs Insights 轻松管理保留期,并以交互方式搜索和分析我的日志数据。我输入日志组 ARN(与之前用于 IAM 角色的日志组相同),然后选择 Next(下一步)。

我查看设置,然后选择 Create connector(创建连接器)。几分钟后,连接器运行。
使用 Amazon Aurora 和 Debezium 测试 MSK Connect
现在让我们测试一下我刚刚设置的架构。我启动了一个 Amazon Elastic Compute Cloud (Amazon EC2) 实例来更新数据库,然后启动几个 Kafka 使用者来查看 Debezium 的运行情况。为了能够连接到 MSK 集群和 Aurora 数据库,我使用相同的 VPC 并分配了默认安全组。我还添加了另一个安全组,为我提供了对实例的 SSH 访问权限。
我下载了 Apache Kafka 的二进制发行版,然后提取主目录中的存档:
为使用 IAM 对 MSK 集群进行身份验证,我按照《Amazon MSK 开发人员指南》中的说明为 IAM 访问控制配置客户端。我下载了适用于 IAM 的 Amazon MSK Library 的最新稳定发行版本:
在 ~/kafka_2.13-2.7.1/config/ 目录中,我创建了一个 client-config.properties 文件来配置 Kafka 客户端,以使用 IAM 身份验证:
我向我的 Bash 配置文件中添加了几行:
- Add Kafka binaries to the
PATH. - Add the MSK Library for IAM to the
CLASSPATH. - Create the
BOOTSTRAP_SERVERSenvironment variable to store the bootstrap servers of my MSK cluster.
$ cat >> ~./bash_profile
export PATH=~/kafka_2.13-2.7.1/bin:$PATH
export CLASSPATH=/home/ec2-user/aws-msk-iam-auth-1.1.0-all.jar
export BOOTSTRAP_SERVERS=<bootstrap servers>然后,我打开了与实例的三个终端连接。
在第一个终端连接中,我为与数据库服务器(电子商务服务器)同名的主题启动了一个 Kafka 使用者。Debezium 使用本主题来流式传输架构更改(例如,创建新表时)。
在第二个终端连接中,我为一个主题启动了另一个 Kafka 使用者,该主题的名称是通过连接数据库服务器(电子商务服务器)、数据库(电子商务)和表(订单)构建的。Debezium 使用本主题来流式传输表的数据更改(例如,插入新记录时)。
在第三个终端连接中,我使用 MariaDB 软件包安装 MySQL 客户端并连接到 Aurora 数据库:
通过此连接,我为我的订单创建了电子商务数据库和表:
这些数据库更改被 MSK Connect 管理的 Debezium 连接器捕获并流式传输到 MSK 集群。在第一个终端中,使用架构更改的主题,我看到了有关数据库和表创建的信息:
之后,我返回第三个终端的数据库连接,在订单表中插入一些记录:
INSERT INTO orders VALUES ("123456", "123", "A super noisy mechanical keyboard", "50.00", "2021-08-16 10:11:12");
INSERT INTO orders VALUES ("123457", "123", "An extremely wide monitor", "500.00", "2021-08-16 11:12:13");
INSERT INTO orders VALUES ("123458", "123", "A too sensible microphone", "150.00", "2021-08-16 12:13:14");
在第二个终端中,我看到有关插入到订单表的记录的信息:
我的变更数据捕获架构已启动并运行,连接器由 MSK Connect 完全托管。
可用性和定价
MSK Connect 现已在以下 AWS 区域推出:非洲(开普敦)、亚太地区(孟买)、亚太地区(首尔)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、加拿大(中部)、欧洲(法兰克福)、欧洲(爱尔兰)、欧洲(伦敦)、欧洲(巴黎)、欧洲(斯德哥尔摩)、南美洲(圣保罗)、美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(加利福尼亚北部)、美国西部(俄勒冈)。有关更多信息,请参阅 AWS 区域服务列表。
使用 MSK Connect 时按实际使用量付费。可以根据您的工作负载自动扩展连接器使用的资源。有关更多信息,请参阅 Amazon MSK 定价页面。
立即使用 MSK Connect 简化对 Apache Kafka 连接器的管理。
— Danilo