亚马逊AWS官方博客
新增功能 – 通过智能分层自动优化 Amazon S3 成本
Amazon Simple Storage Service (S3) 拥有超过 12.5 年的发展历史,它存储数万亿个对象,每秒可以处理数百万个请求。我们的客户依靠 S3 来满足他们的备份与恢复、数据存档、数据湖、大数据分析、混合云存储、原生云存储和灾难恢复需求。在最初的通用标准存储类基础上,我们增加了许多其他类,以便更好地为客户服务。今天,您可以从四个类中进行选择,每个类都是针对特定用例专门设计的。目前提供的选项包括:
 标准 – 专门针对经常访问的数据设计。
标准 – 专门针对经常访问的数据设计。
标准 – IA – 专门针对长期存储且不经常访问的数据设计。
单区 – IA – 专门针对长期存储且不经常访问的非关键数据设计。
Glacier – 专门针对长期存储且经常访问的存档关键数据设计。
您可以在将数据上传到 S3 时选择适用的存储类,也可以使用 S3 的生命周期策略告诉 S3 根据对象的创建日期将对象从“标准”转换为“标准 – IA”、“单区 – IA”或“Glacier”。请注意,低冗余存储类仍受支持,但我们建议在新应用程序中使用“单区 – IA”。
如果现在您想在不同的 S3 存储类之间进行分层,生命周期策略会根据存储对象的创建日期自动移动对象。如果您的数据现在存储在标准存储中,并且您想了解某些存储是否适合 S-IA 存储类,则可以使用 S3 控制台中的存储类分析来确定要使用生命周期分层的对象组。但是,在很多情况下,数据的访问模式是不规则的,或者您完全不了解访问模式,因为组织中的许多应用程序都会访问您的数据集。或者您可能非常专注于您的应用程序,而没有时间使用存储类分析等工具。
全新智能分层
为了让您更轻松地利用 S3 而无需深入了解您的访问模式,我们推出了一个全新的存储类:S3 智能分层。此存储类包含两个访问层:经常访问和不经常访问。两个访问层都提供与标准存储类相同的低延迟。S3 智能分层会监控访问模式并将连续 30 天未访问的对象移动到不经常访问层,而且监控和自动化费用低廉。如果稍后访问数据,则数据会自动移回经常访问层。底线:即使在不断变化的访问模式下,您也可以节省资金,而且不会影响性能,不会产生运营开销,也不会有检索费用。
将新对象上传到 S3 时,可以指定使用智能分层存储类。您还可以使用生命周期策略在指定的时间段后实现转换。没有检索费用,您可以将此新存储类与 S3 的所有其他功能结合使用,包括跨区域复制、加密、对象标记和清单。
如果您确信您的数据不会经常被访问,那么就节省成本而言,标准 – IA 存储类仍然是更好的选择。但是,如果您不了解您的访问模式,或者它们可能会发生变化,那么智能分层更适合您!
智能分层实际操作
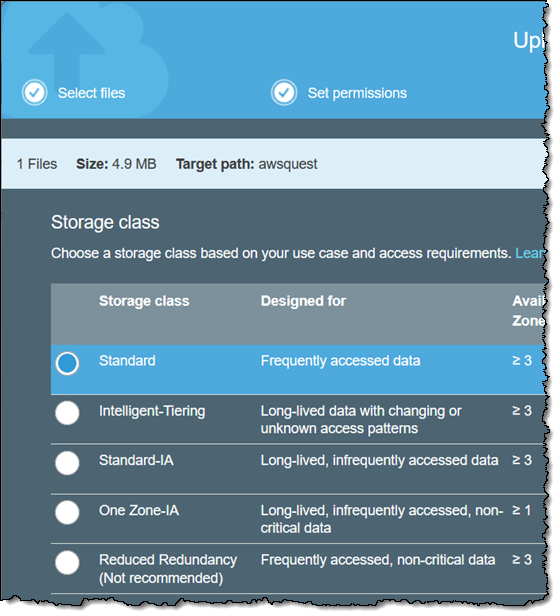
我将对象上传到 S3 时只需选择新的存储类:
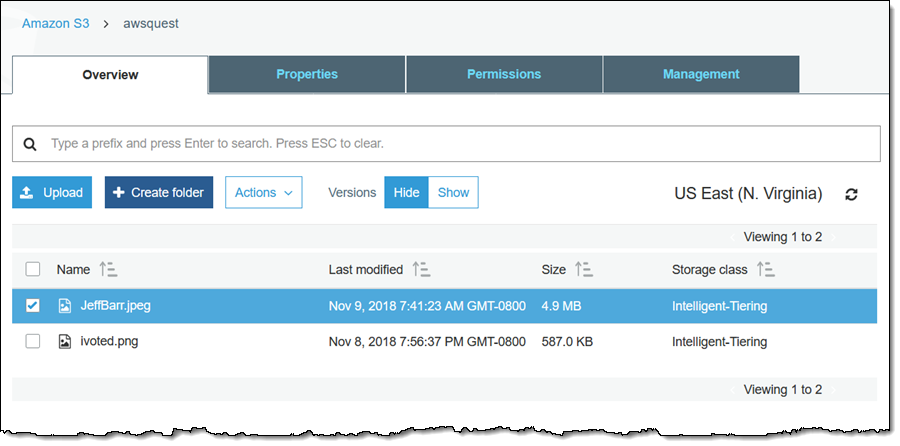
与以往一样,我可以在 S3 控制台中查看存储类:
我可以创建采用智能分层的生命周期规则:
![]()
就是这么简单。以下是您需要了解的一些事项:
对象大小 – 您可以对任何大小的对象使用智能分层,但小于 128KB 的对象永远不会转换到不经常访问层,将按照经常访问层的一般费率进行计费。
对象生命周期 – 对于生命周期少于 30 天的对象,没有提供一种合适的计费方式;所有对象都将按照最少 30 天进行计费。
持久性和可用性 – 智能分层存储类旨在实现 99.9% 的可用性和 99.999999999% 的持久性,SLA 可提供 99.0% 的可用性。
定价 – 与其他存储类一样,您需要为每月存储、请求和数据传输付费。经常访问层中对象的存储与 S3 标准的计费费率相同;不经常访问层中对象的存储与 S3 标准-不经常访问的计费费率相同。当您使用智能分层时,需按对象支付每月少量的监控和自动化费用;这意味着随着对象大小的增长,存储类会变得更加经济。正如我之前提到的,S3 智能分层将根据访问模式自动将数据移回经常访问层,但没有检索费用。
就地查询 – 使用 S3 Select 进行的查询不会更改存储层。Amazon Athena 和 Amazon Redshift Spectrum 使用常规 GET 操作访问数据并将触发转换。
API 和 CLI 访问 – 您可以使用 S3 CLI 和 S3 API 中的存储类 INTELLIGENT_TIERING。
现已推出
这一新存储类现已推出,您可以立即在所有 AWS 区域开始使用。
– Jeff;
另外,还记得我刚刚和您说的数万亿个对象和数百万个请求吗? 我们将它们归入 Amazon Machine Learning 模型,并使用它们来预测每个对象的未来访问模式。然后,参考结果以便以最具成本效益的方式存储 S3 对象。这是一个非常有利的优势,可以通过令人难以置信的 S3 规模和它支持的用例的多样性来实现。据我所知,这项功能是独一无二的!