亚马逊AWS官方博客
使用 AWS Glue 和 Amazon S3 构建数据湖基础
数据湖是一种越来越受欢迎的数据存储和分析方法,可解决处理海量异构数据的难题。数据湖可让组织将所有结构化和非结构化数据存储在一个集中式存储库中。由于数据可以按原样存储,因此无需将其转换为预先定义的数据结构(区别于传统关系型数据仓库)。
许多组织机构都了解使用 Amazon S3 作为数据湖所带来的好处。例如,Amazon S3 是一种高持久性、经济高效的对象存储服务,可支持开放数据格式,同时将存储与计算解耦,并且可与所有 AWS 分析服务集成使用。尽管Amazon S3提供数据湖的基础,但是您也可以根据业务需求添加其他AWS服务来定制数据湖。有关在 AWS 上构建数据湖的详细信息,请参阅什么是数据湖?
由于使用数据湖的主要挑战之一是查找数据并了解数据结构和格式,因此Amazon最近推出了AWS Glue。WS Glue 通过发现数据的结构和格式,显著减少了从 Amazon S3 数据湖快速获得业务洞察力所需的时间和工作量。AWS Glue 可自动抓取 Amazon S3 上的数据,识别数据格式,然后给出建议的可用于其他 AWS 分析服务的数据表结构。
此博文将引导您完成使用 AWS Glue 对 Amazon S3 上的数据进行结构爬取的过程,构建可以被其他 AWS 产品使用的元数据存储
AWS Glue 的功能
AWS Glue 是一种完全托管的数据目录和 ETL(提取、转换和加载)服务,可简化和自动化数据发现、转换和作业计划中难度较大且耗时的任务。AWS Glue 使用能识别常用数据格式和数据类型的预构建分类器(classifiers)抓取数据源并构建数据目录,包括 CSV、Apache Parquet、JSON 等。
因为 AWS Glue 与 Amazon S3、Amazon RDS、Amazon Athena、Amazon Redshift 和 Amazon Redshift Spectrum(这些是现代数据架构的核心组件)相集成,可无缝协调数据的移动和管理。
AWS Glue 数据目录与 Apache Hive Metastore 兼容,并支持常用工具,如 Hive、Presto、Apache Spark 和 Apache Pig。 它还直接与 Amazon Athena、Amazon EMR 和 Amazon Redshift Spectrum 集成。
此外,AWS Glue 数据目录还具有以下扩展,以实现易用性和数据管理功能:
- 通过搜索发现数据
- 使用分类标识和解析文件
- 使用版本控制管理不断变化的架构
有关更多信息,请参阅 AWS Glue 产品详细信息。
Amazon S3 数据湖
AWS Glue 是 Amazon S3 数据湖的一个重要组成部分,为现代数据分析提供数据目录和转换服务。

在上图中,数据针对不同的分析场景进行了暂存。最初,数据以其原始格式被摄取,原始格式是数据的不可变副本。然后,数据将进行转换和充实,以使其对于每种应用场景都更具价值。在此示例中,原始 CSV 文件被转换为 Apache Parquet格式,供 Amazon Athena 使用,以提高性能并降低成本。
通过将数据与其他数据集相结合来提供更多见解,也可以丰富数据。AWS Glue 爬网程序根据作业触发器或预定义计划为数据的每个阶段创建一个表。在此示例中,每次将新文件添加到原始数据 S3 存储桶时,都将使用一个 AWS Lambda 函数来触发 ETL 进程。Amazon Athena、Amazon Redshift Spectrum 和 Amazon EMR 可以使用这些表在任何阶段使用标准 SQL 或 Apache Hive 查询数据。此配置是一种热门的设计模式,可提供敏捷的商业智能,以快速轻松地从各种数据中获取商业价值。
演练
在本演练中,您将定义数据库,配置爬网程序以浏览 Amazon S3 存储桶中的数据,创建表格,将 CSV 文件转换为 Parquet,为 Parquet 数据创建表格,以及使用 Amazon Athena 查询数据。
发现数据
登录 AWS 管理控制台并打开 AWS Glue 控制台。您可以在分析类别找到 AWS Glue服务。在构建此解决方案之前,请查看 AWS 区域列表,了解 Glue 在哪些区域可用。
数据发现的第一步是添加数据库(database)。数据库是表的集合。
- 在控制台中,选择添加数据库。在数据库名称中,键入 nycitytaxi,然后选择创建。

- 选择导航窗格中的表格。表格由列的名称、数据类型定义和有关数据集的其他元数据组成。

- 将表添加到数据库 nycitytaxi。您可以手动或使用爬网程序添加表格。爬网程序是一种连接到数据存储的程序,它会通过分类器的优先级列表来确定数据的架构。AWS Glue 为 CSV、JSON、Avro 等常见文件类型提供分类器。您也可以使用 Grok 模式编写自己的分类器。

- 要添加爬网程序,请输入数据源:一个名为 s3://aws-bigdata-blog/artifacts/glue-data-lake/data/ 的 Amazon S3 存储桶。此 S3 存储桶包含数据文件,其中包含 2017 年 1 月绿色出租车的所有行驶记录。

- 选择下一步。

- 对于 IAM 角色,在下拉列表中选择默认角色 AWSGlueServiceRoleDefault。

- 对于频率,选择按需运行。爬网程序可以按需运行,也可以设置为按计划运行。

- 对于数据库,选择 nycitytaxi。了解 AWS Glue 如何处理架构更改非常重要,这样您就可以选择适当的方法。在此示例中,表格将进行更改以更新。有关架构更改的详细信息,请参阅 AWS Glue 开发人员指南中的使用爬网程序编目表格。

- 查看步骤,然后选择结束。爬网程序已准备就绪,可以运行。选择立即运行。

爬网程序完成后,添加了一个表格。

- 在左侧导航窗格中选择表格,然后选择数据。此屏幕描述了该表格,包括架构、属性和其他有价值的信息。


将数据从 CSV 格式转换为 Parquet 格式
现在,您可以配置和运行作业,将数据从 CSV 转换为 Parquet。Parquet 是一种列式格式,非常适合 Amazon Athena 和 Amazon Redshift Spectrum 等 AWS 分析服务。
- 在左侧导航窗格中的 ETL 下,选择作业,然后选择添加作业。

- 对于名称,请键入 nytaxi-csv-parquet。
- 对于 IAM 角色,请选择 AWSGlueServiceRoleDefault。
- 对于此作业运行,请选择 AWS Glue 生成的建议脚本。
- 提供唯一的 Amazon S3 路径来存储脚本。
- 为临时目录提供唯一的 Amazon S3 目录。
- 选择下一步。

- 选择数据作为数据源。

- 选择在数据目标中创建表格。
- 选择 Parquet 作为格式。
- 选择新位置(不带任何现有对象的新前缀位置)以存储结果。

- 验证架构映射,然后选择完成。

- 查看此作业。此屏幕提供作业的完整视图,并允许您编辑、保存和运行作业。AWS Glue 创建了此脚本。但是,如果需要,您可以创建自己的脚本。

- 选择保存,然后选择运行作业。
添加 Parquet 表和爬网程序
作业完成后,使用爬网程序为 Parquet 数据添加新表。
- 对于爬网程序名称,请键入 nytaxiparquet。

- 选择 S3 作为数据存储。
- 包括在 ETL 中选择的 Amazon S3 路径

- 对于 IAM 角色,请选择 AWSGlueServiceRoleDefault。

- 对于数据库,选择 nycitytaxi。
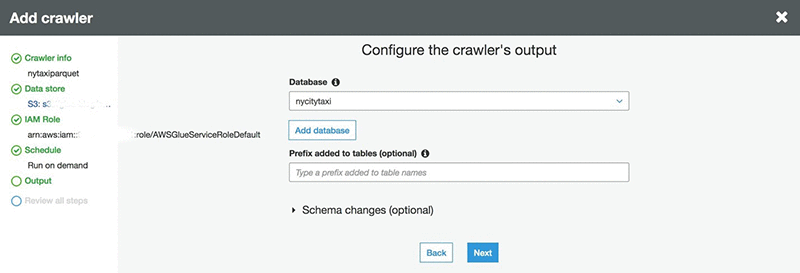
- 对于频率,选择按需运行。

爬网程序完成后,nycitytaxi 数据库中有两个表:一个表用于原始 CSV 数据,另一个表用于转换的 Parquet 数据。
与 Amazon Athena 分析数据
Amazon Athena 是一种交互式查询服务,可使用标准 SQL 轻松分析 Amazon S3 中的数据。Athena 能够查询 CSV 数据。但是Parquet的文件格式可以大幅度地减少查询数据的时间和成本。有关详细信息,请参阅博文 Analyzing Data in Amazon S3 using Amazon Athena。
要将 AWS Glue 与 Amazon Athena 一起使用,您必须将 Athena 数据目录升级到 AWS Glue 数据目录。有关升级 Athena 数据目录的更多信息,请参阅分步指南。
-
- 打开 Athena 的 AWS 管理控制台。查询编辑器将在 nycitytaxi 中显示这两个表格

- 打开 Athena 的 AWS 管理控制台。查询编辑器将在 nycitytaxi 中显示这两个表格
您可以使用标准 SQL 查询数据。
- 选择 nytaxigreenparquet
- 键入
Select * From "nycitytaxi"."data" limit 10; - 选择运行查询。

小结
本博文展示了使用 AWS Glue 和 Amazon S3 轻松构建数据湖基础。通过使用 AWS Glue 在 Amazon S3 上对数据进行结构爬取并构建 Apache Hive 兼容的元数据存储,您可以跨 AWS 分析服务和流行的 Hadoop 生态系统工具使用这份元数据。AWS 服务的这种集成组合功能强大且易于使用,使您能够更快地获得业务见解。
如果您有任何问题或建议,请在下方留言。
其他阅读资源
有关更多信息,请参阅以下博文:
- Build a Schema-On-Read Analytics Pipeline Using Amazon Athena
- Harmonize, Query, and Visualize Data from Various Providers using AWS Glue, Amazon Athena, and Amazon QuickSight
关于作者
 Gordon Heinrich 是一名与全球系统集成商合作的解决方案架构师。 他与我们的合作伙伴和客户合作,为他们提供构建数据湖和使用 AWS 分析服务的架构指导。在闲暇时间,他喜欢和家人一起在科罗拉多滑雪、徒步旅行和骑山地车。
Gordon Heinrich 是一名与全球系统集成商合作的解决方案架构师。 他与我们的合作伙伴和客户合作,为他们提供构建数据湖和使用 AWS 分析服务的架构指导。在闲暇时间,他喜欢和家人一起在科罗拉多滑雪、徒步旅行和骑山地车。