Amazon Web Services ブログ
Amazon Redshift Spectrum – S3のデータを直接クエリし、エクサバイトまでスケール可能
現在、数クリックでクラウド上にコンピュートリソースやストレージリソースを構築可能です。現在のチャレンジは、それらのリソースを活用して生のデータを出来る限り素早く、かつ効果的に活用可能な結果に変換することです。
Amazon Redshiftを活用することで、AWSのお客様はペタバイト級のデータウェアハウスを構築し、社内・社外の多様なデータソースからのデータを統合することが可能です。Redshiftは巨大な表に複雑なクエリ(複数の表をジョインする等)を実行することに最適化されているため、小売、在庫、ファイナンシャルデータといった膨大なデータを特別な苦労なく処理することができます。Redshiftにデータをロードした後は、Redshiftパートナーが提供するビジネスインテリジェンス(BI)ツールやエンタープライズレポーティングツールを活用することが可能です。
データウェアハウスを使い続ける上での1つの大きなチャレンジは、継続的に更新される、もしくは追加されるデータを速いペースでロードすることです。高速なクエリーパフォーマンスを提供するために、データをロードするというフェーズでは圧縮、データの正規化や最適化といった作業が行われます。これらの作業自体は自動化、スケールさせることは可能ですが、複雑なロード作業はデータウェアハウス維持にオーバーヘッドと複雑さを追加し、効果的な活用方法を得ることを阻害する場合もあります。
データフォーマットについては別の興味深いチャレンジが存在します。いくつかのアプリケーションはデータウェアハウスの外でデータ元々のフォーマットのままで処理を行っています。他のアプリケーションはデータウェアハウスにデータを取り込み、クエリーを実行しています。この利用方法だと同じデータが2つの場所に存在することになりますのでストレージを効率的に使えていないことになりますし、ロードがタイムリーに行われていない環境では、それぞれのアプリケーションで異なった結果が返る可能性があります。
Amazon Redshift Spectrum
データを置いた場所によらず、そのままのデータフォーマットでAmazon Redshiftのパワーとフレキシビリティを活用できるようにするため、Amazon Redshift Spectrumをローンチいたします。Spectrumを使うことで、Amazon Simple Storage Service (S3)上に置かれたファイルをRedshiftにロードしたり特殊な準備をすることなく、高度なクエリを実行することが可能になります。
使い方はこれまで通り、データソース(データベースへの接続)を作成してクエリーをRedshiftに投入するだけです。クエリー実行の背後ではSpectrumが数千台までスケールするインスタンスが用意されており、データセットがエクサバイトを超えて大きくなっても、高速なデータ取り出しと一貫したパフォーマンスを実現します!S3上のデータを直接クエリーできるようになるということは、Redshiftのクエリーモデルや、全てのレポーティングツール、BIツールを維持したまま、コンピュートリソースとストレージリソースをそれぞれ独立してスケールさせることが出来るようになるということです。クエリーはRedshiftにストアされたデータとS3上に置かれたデータの任意の組み合わせを参照することが可能です。
クエリーが投入されると、Redshiftはクエリーを分解してクエリープラン(実行計画)を作成します。クエリープランはS3上に置かれたデータにおけるカラムナ(列指向)フォーマットの特性および日付等のキーでのパーティションの特性をいかし、読み取る量が最小になるように作成されます。クエリープランが出来るとRedshiftは巨大な共有プールに用意されているSpectrumワーカーに指示を出し、射影・フィルター・アグリゲーションといったSQL操作をS3上のファイルに対して実行させます。結果セットを作成する最終的なプロセスはRedshiftの中で実行され、ユーザに結果が返されます。
SpectrumはS3上に保存されたデータに直接アクセスできるということは、他のAWSサービス、例えばAmazon EMRやAmazon Athenaといったサービスを使ってそのデータを処理できるということです。また、頻繁にアクセスされるデータはRedshiftのローカルストレージに維持して、他はS3に置くであるとか、ディメンジョン表に加えてファクト表の直近データだけRedshiftに置き、他の古いデータはS3に置くといったハイブリッドな構成を実現することも可能です。より高いレベルでの並列実行を実現するために、複数のRedshiftクラスターを用意してS3上の同じデータを参照させるということも可能になります。
SpectrumはCSV/TSV、Parquet、SequenceFile、RCFileといったオープンなフォーマットをサポートします。ファイルはGzipかSnappyで圧縮しておくことが可能です。この他のフォーマットや圧縮アルゴリズムについては、今後サポートすることを計画しています。
Spectrum イン・アクション
サンプルデータセットを使って、クエリーを実行することでSpectrumを試してみましょう!
まずExternal SchemaとExternal Databaseを作成するところから始めます:(訳注:External Databaseはこの後で定義するExternal Tableの定義を格納しておくためのデータベースです。External SchemaはIAMロールの情報を保持し、SpectrumはそのIAM権限でS3上にアクセスします)
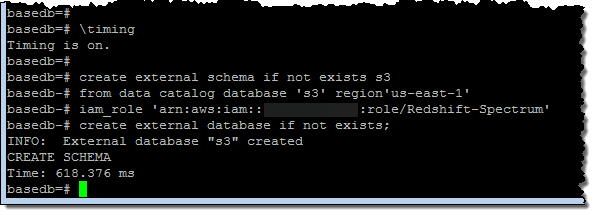
そして、External Table (外部表)をデータベースの中に定義します:
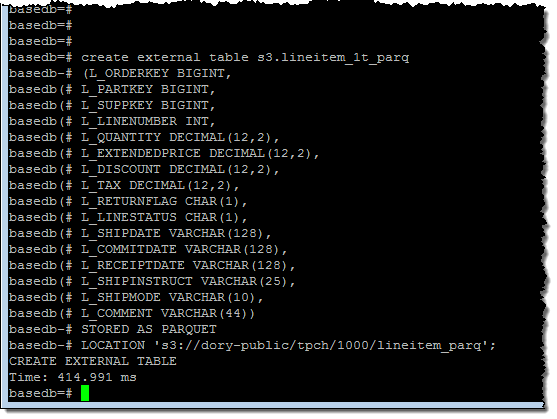
このExternal Tableで定義したデータの行数を得るために、簡単なクエリーを実行してみましょう(61億行):
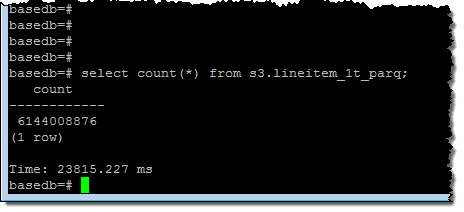
最後に全ての列を使ったクエリーを実行します:
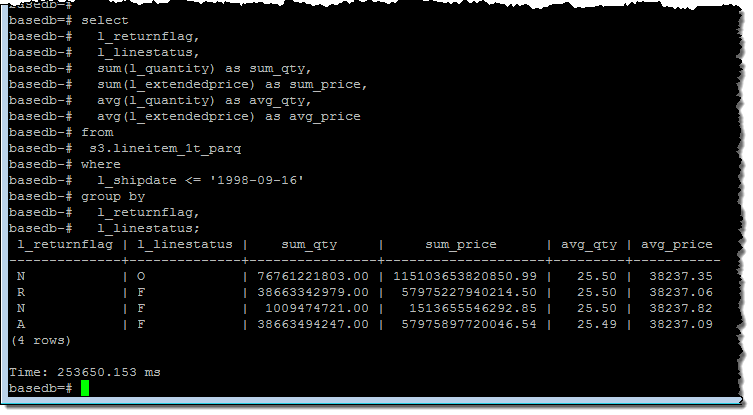
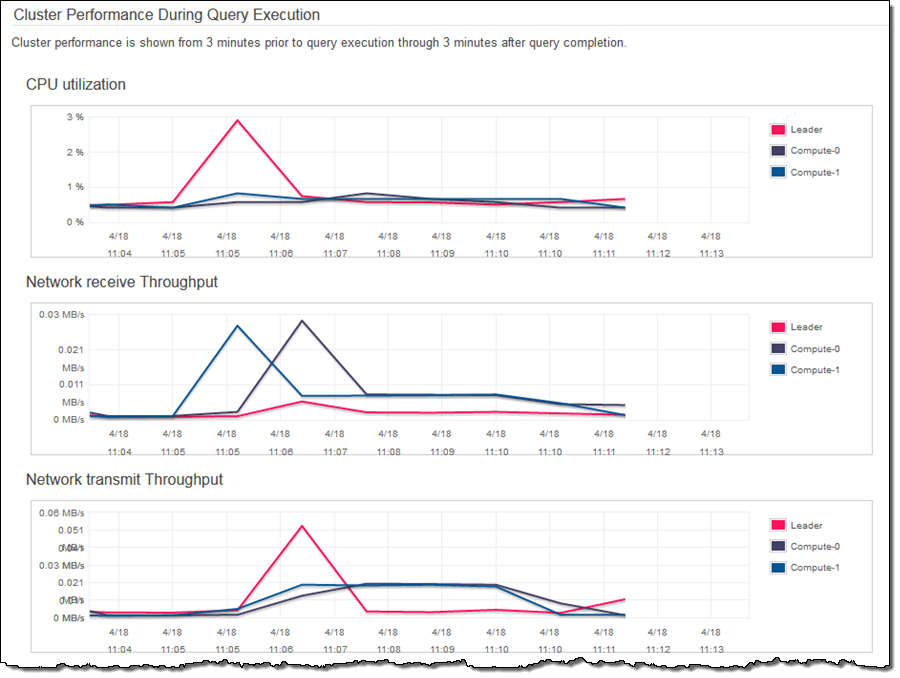
ご覧いただいたように、Spectrumは60億行のデータ全体をスキャンする必要がある演算を4分と少々で実行できています。クラスターのパフォーマンスを確認すると、CPUパワーはまだ十分な余裕があり、同様のクエリーを多数並列実行することが可能であることが見て取れます:
本日からご利用可能です!
Amazon Redshift Spectrumは、本日、今からご利用可能です!
Spectrumの費用はクエリーによってS3から読み取られたデータサイズによって決まり、1TBあたり$5です(データを圧縮したり、カラムナフォーマットでデータを保存することで費用を節約することが可能です)。Redshiftのクラスターの稼動費用やS3の保存費用は通常通り必要になりますが、Spectrumを使ったクエリーを実行しない限りはSpectrumの費用は発生しません。
(訳注:Spectrumは各リージョンに順次展開されていき、展開後のメンテナンスウィンドウのタイミングでクラスターにパッチが適用されます。パッチ1.0.1293以降のRedshiftクラスターであればSpectrumが使用可能になっています。本稿執筆時点では東京リージョンにはまだ展開されていませんでしたが、例えばバージニア北部リージョン等にはすでに展開されています。Spectrumの使い方についてはこちらのドキュメントを参照してください)
– Jeff;
翻訳:下佐粉 昭(@simosako)