Amazon Web Services ブログ
AWS DeepLens を使用してゴミ選別機を構築する
このブログ記事では、AWS DeepLens を使用してゴミ選別機の試作品を構築する方法を示します。これは、開発者が機械学習を楽しく実践的に学習するために設計された AWS のディープラーニング対応ビデオカメラです。このゴミ選別機の試作品を構築するプロジェクトから、カスタムデータを使用して画像分類モデルをトレーニングする方法が学べます。
画像分類は強力な機械学習手法であり、機械学習モデルは、多くの例を観察することにより、画像内のさまざまなオブジェクトを区別する方法を学習します。このブログ記事でご紹介する手法を活用して、画像に基づいてオブジェクトを異なる箱に分類すること (果物をサイズやグレードで分類するなど) や、画像内のオブジェクトの存在を検出すること (セルフチェックアウト時にオブジェクトのタイプを認識するなど) が求められる問題を解決できます。
このチュートリアルは、AWS Public Sector Builders Fair のために立ち上げられたスマートリサイクルアームプロジェクトに触発されました。詳細については、「Demonstration: Automatic Recycling」を YouTube でご覧ください。
ソリューションの概要
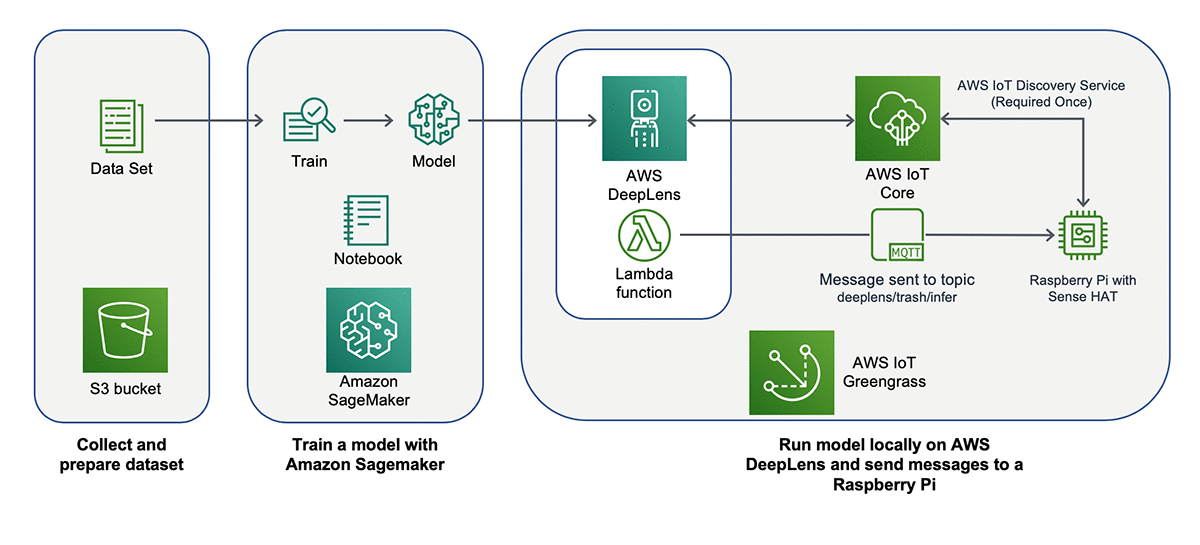
このチュートリアルには、次の手順が含まれます。
- ML アルゴリズムにフィードするデータセットを収集して準備する
- ML モデルをすばやく構築、トレーニング、デプロイする機能を提供するフルマネージドサービスである Amazon SageMaker でモデルをトレーニングする
- AWS DeepLens でローカルにモデルを実行して、データをクラウドに送信せずにゴミの種類を予測する
- オプションで、AWS DeepLens が予測を行った後、AWS IoT Greengrass を介して Raspberry Pi にメッセージを送信するように AWS DeepLens を設定し、アイテムをどのゴミ箱に投げ込むかを見ることができます。
以下の図は、このソリューションのアーキテクチャを示しています。
前提条件
このチュートリアルを完了するには、次の前提条件が必要です。
- AWS アカウント
- AWS DeepLens デバイス。Amazon.com (米国)、Amazon.ca (カナダ)、Amazon.co.jp (日本)、Amazon.de (ドイツ)、Amazon.fr (フランス)、Amazon.es (スペイン)、Amazon.it (イタリア) でご利用いただけます。
- Sense HAT を備えた Raspberry Pi (オプション)
データセットの収集と準備
このチュートリアルでは、画像分類モデルと呼ばれる ML アルゴリズムを使用します。このモデルは、反復を繰り返して多くの例を観察することにより、さまざまなオブジェクトを区別することを学習します。このチュートリアルでは、転移学習と呼ばれる手法を使用して、画像分類モデルのトレーニングに必要な時間とデータを大幅に削減します。Amazon SageMaker の組み込みアルゴリズムを使用した転移学習の詳細については、「画像分類の仕組み」を参照してください。転移学習に必要になるのは、ゴミの種類ごとにたった数百枚の画像です。さらにトレーニングサンプルを追加し、ゴミの種類ごとに視野角と照明を変化させると、モデルのトレーニングに時間がかかりますが、これまでに見たことのないゴミを分類するようにモデルにリクエストしたときに、推論中の精度が向上します。
外に出て自分で画像を収集しにいく前に、公開されている数多くの画像ソースのどれかを使用することを検討してみてください。画像内にあるものの明確なラベル (多くの場合、人の手で貼られたもの) を持つ画像が必要です。使用できるソースには以下があります。
- AWS Open Data – 信頼できるエンティティが一般の利用に供するためにデータセットをオープンにして共有したさまざまなデータセットが含まれています。
- AWS Data Exchange – 無料か有料またはサブスクリプション料金でご利用いただけるデータセットが用意されています。画像は非常に厳選され、ラベルが付けられているため、ほとんどの場合料金がかかります。
- GitHub – 画像データセットを含む、複数の公開リポジトリを提供しています。利用規約を順守し、原作者を引用するようにしてください。
- Kaggle – ML コンペティションで使用されるさまざまな公開データセットが含まれています。これらのデータセットは、多くの場合、スターターコードで提供されます。
- 非営利団体や政府機関 – 公用のデータセットが含まれています。それぞれの利用規約を必ずご確認ください。
- Amazon SageMaker Ground Truth – お持ちの画像からラベル付きデータセットを作成します。自動ラベリング (一般的なオブジェクトにお勧め)、人間のラベラー、または AWS Marketplace サービスから選択でき、より具体的なラベリングユースケースにご利用いただけます。詳細については、「Amazon SageMaker Ground Truth を使用して高精度のトレーニングデータセットを構築する」を参照してください。
画像を収集する上で良い方法は、モデルをより堅牢にするために、さまざまな角度と照明条件で画像を使用することです。次の画像は、モデルが埋め立て、リサイクル、または堆肥に分類する画像のタイプの例です。

ゴミの種類ごとに画像を用意したら、画像をフォルダに分けます。
ML モデルをトレーニングする画像を用意したら、それらを Amazon S3 にアップロードします。まず、S3 バケットを作成します。AWS DeepLens プロジェクトの場合、S3 バケット名は deeplens- のプレフィックスで始まる必要があります。
このチュートリアルでは、リサイクル、埋め立て、堆肥のカテゴリでラベル付けされた画像のデータセットを使います。Amazon SageMaker でモデルをトレーニングするときは、次のステップでこのデータセットをダウンロードします。
Amazon SageMaker を使用したモデルのトレーニング
このチュートリアルでは、モデルをトレーニングするための開発環境として Amazon SageMaker Jupyter ノートブックを使用します。Jupyter Notebook は、ライブコード、方程式、視覚化、および説明テキストを含むドキュメントを作成して共有できるオープンソースのウェブアプリケーションです。すぐにお使いいただけるように完全な Jupyter ノートブックを用意しました。
まず、次の URL からノートブックのサンプルをダウンロードします。aws-deeplens-custom-trash-detector.ipynb
次に、カスタム画像分類モデルを作成するため、グラフィックスプロセッシングユニット (GPU) 対応のトレーニングジョブインスタンスを使用する必要があります。GPU は、ニューラルネットワークのトレーニングに必要な計算の並列化に優れています。このチュートリアルでは、単一の ml.p2.xlarge インスタンスを使用します。GPU 対応のトレーニングジョブインスタンスにアクセスするには、AWS サポートセンターにサービス制限の引き上げリクエストを送信する必要があります。こちらの手順に従って、制限を増やすことができます。
制限の増加を受けたら、Amazon SageMaker ノートブックインスタンスを起動します。
- Amazon SageMaker 無料利用枠に含まれている t2.medium インスタンスタイプを使用します。詳細については、Amazon SageMaker 料金表を参照してください。
- ロールを作成するときは、プロジェクトが使用する S3 バケットを参照してください (deeplens- のプレフィックス)。
ノートブックインスタンスを設定するには最大 1 分間かかることがあります。
ノートブックインスタンスページのステータスが InService に変わったら、[Open Jupyter] を選択して、新しく作成した Jupyter ノートブックインスタンスを起動します。
先にダウンロードした aws-deeplens-custom-trash-detector.ipynb ファイルをアップロードします。

ノートブックを開き、最後まで指示に従ってください。カーネルの設定について尋ねられたら、[conda_mxnet_p36] を選択します。
Jupyter ノートブックには、テキストセルとコードセルが混在しています。コードを実行するには、セルを選択して Shift + Enter を押します。セルの実行中は、そのセルの横にアスタリスクが表示されます。セルが完成すると、元のセルの下に出力番号と新しい出力セルが表示されます。
ノートブックの指示に最後まで従うと、さまざまな種類のゴミを区別するためのトレーニング済みモデルが完成します。
AWS DeepLens でモデルをローカルに実行する
AWS DeepLens プロジェクトは、モデルと推論関数の 2 つの部分で構成されています。推論は、モデルがこれまでに見たことのない新しい画像に適用し、予測を取得する場合に使います。モデルは、アルゴリズムと、トレーニングプロセスを通じて学習したパラメータで構成されます。Amazon SageMaker でトレーニングしたモデル、または独自のマシンでトレーニングした外部モデルをお使いいただけます。このチュートリアルでは、トレーニングしたばかりの Amazon SageMaker モデルを使用します。
モデルを AWS DeepLens にインポートする
AWS DeepLens コンソールで、[Models] に移動し、[Import model] をクリックします。
[Amazon SageMaker trained model] を選択します。次に、最新のジョブ ID とモデル名を選択します。次に、モデルフレームワークとして [MXNet] を選択します。

次に、[import model] をクリックします。
推論関数を作成する
推論機能は、モデルを AWS DeepLens で実行するように最適化し、各カメラフレームをモデルにフィードして予測を取得します。推論関数では、AWS Lambda を使用して、AWS DeepLens にデプロイする関数を作成します。Lambda 関数は、カメラから出てくる各フレームに対して (AWS DeepLens デバイスでローカルに) 推論を実行します。
このチュートリアルでは、推論の Lambda 関数の例を示します。
最初に、AWS DeepLens にデプロイする AWS Lambda 関数を作成する必要があります。
- コンピュータに deeplens-trash-lambda.zip をダウンロードします。
- AWS マネジメントコンソールで AWS Lambda に移動し、[Create Function] をクリックします。
- 次に、[Author from Scratch] を選択し、以下のオプションが選択されていることを確認します。
- ランタイム: Python 2.7
- 実行ロールを選択または作成: Use an existing role
- 既存のロール: service-role/AWSDeepLensLambdaRole
- 関数が作成されたら、関数の詳細ページを下にスクロールして、[Code entry type] で [Upload zip] を選択します。
- 以前にダウンロードした deeplens-trash-lambda.zip をアップロードします。
- [Save] を選択して、入力したコードを保存します。
- [Actions] ドロップダウンメニューリストから、[Publish new version] を選択します。関数を公開すると、AWS DeepLens コンソールで使用できるようになり、カスタムプロジェクトに追加できるようになります。
- バージョン番号を入力して、[公開] をクリックします。
Lambda 関数を理解する
このセクションでは、Lambda 関数のいくつかの重要な部分について説明します。
まず、注意が必要なファイルが 2 つあります。labels.txt と lambda_function.py です。
labels.txt には、ニューラルネットワーク (整数) の出力をマップするための人間が読めるラベルのリストが含まれています。
lambda_function.py には、すべてのカメラフレームで予測を生成して結果を送り返すために呼び出される関数のコードが含まれています。
ここに、lambda_function.py. の重要な部分があります。
最初に、モデルをロードして最適化します。GPU を備えたクラウド仮想マシンと比較すると、AWS DeepLens のコンピューティング能力は低くなっています。AWS DeepLens は Intel OpenVino モデルオプティマイザーを使用して、Amazon SageMaker でトレーニングされたモデルをハードウェアで実行するように最適化します。次のコードは、モデルをローカルで実行するように最適化します。
次に、カメラからの画像に対してフレームごとにモデルを実行します。次のコードを参照してください。
最後に、テキスト予測結果をクラウドに送り返します。モデルが正しく機能していることを確認するには、テキスト結果をクラウドで表示するのが便利な方法です。各 AWS DeepLens デバイスには、推論結果を受信するために自動的に作成される専用の iot_topic があります。または、ビデオストリームに結果をオーバーレイするか、推論結果を Raspberry Pi などの別のデバイスに送信することもできます。次のコードを参照してください。
カスタム AWS DeepLens プロジェクトを作成する
AWS DeepLens コンソールの [Projects] ページで、[Create Projects] をクリックします。
[Blank Project Option] を選択します。
プロジェクトに -trash-sorter という名前を付けます。
次に、[Add model] をクリックして、たった今作成したモデルを選択します。
次に、[Add function] をクリックし、前に作成した AWS Lambda 関数を名前で検索します。
次に、プロジェクトを作成する [Create] をクリックします。
モデルを AWS DeepLens にインポートする
AWS DeepLens コンソールの [Projects] ページで、デプロイするプロジェクトを選択してから、[Deploy to device] をクリックします。

対象デバイスの画面で、リストからデバイスを選択し、[Review] をクリックします。
次に、[Deploy] をクリックします。AWS DeepLens が接続されているネットワークの速度によっては、デプロイが完了するまでに最大 10 分かかる場合があります。デプロイが完了すると、次のような緑色のバナーが表示されます。
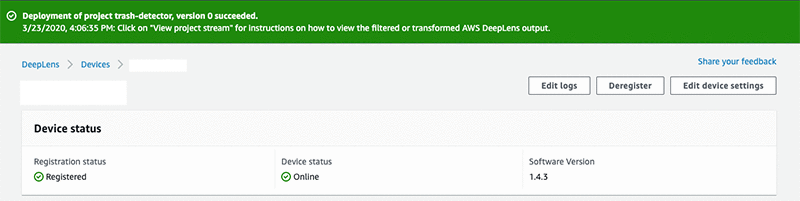
おめでとうございます。モデルを AWS DeepLens でローカルに実行できました!
テキスト出力を表示するには、デバイスの詳細ページを下にスクロールして、[Project output] セクションを表示します。セクションの指示に従ってトピックをコピーし、AWS IoT コンソールに移動してトピックをサブスクライブします。

下のスクリーンショットのような結果が表示されるはずです。

ビデオストリームまたはテキスト出力を確認する手順については、こちらを参照してください。
AWS IoT でアクションを起こす
このセクションでは、AWS DeepLens から Raspberry Pi などの IoT デバイスに結果を送信するオプションの手順について説明します。Raspberry Pi は、これらの結果を使用して、腕を動かしたり、どのゴミ箱にアイテムを捨てるかを通知するメッセージを表示したりできます。このブログ記事では、これらの手順を大まかに説明しています。詳しい手順については、こちらの手順をご覧ください。
AWS DeepLens Lambda 関数を更新する
Raspberry Pi が実行するアクションを認識するために、AWS DeepLens はモデル推論からの出力を含むメッセージを送信する必要があります。既存の AWS DeepLens Lambda 関数に新しいコード行を追加し、新しい MQTT トピックにメッセージを送信してください。更新されたプロジェクトをデプロイする前に、必ず Lambda 関数の新しいバージョンを保存して公開してください。これにより、AWS DeepLens が更新された機能を使用できるようになります。詳しい手順については、こちらをご覧ください。
Greengrass グループにデバイスを追加する
AWS IoT Greengrass を使用すると、クラウドへの接続が断続的であっても、接続されたデバイスが動作できます。デバイスは、オンラインまたはオフラインのときにデータを収集して処理できます。デバイス間で直接的に安全な通信を行えるようにするには、Raspberry Pi を既存の Greengrass グループに追加する必要があります。手順については、「AWS IoT Greengrass グループで AWS IoT デバイスを作成する」を参照してください。名前が deeplens で始まる既存のグループを選択してください。詳しい手順については、こちらをご覧ください。
Raspberry Pi を Greengrass グループに追加したら、サブスクリプションを作成して、Lambda 関数の MQTT トピックが適切な送信先に送られるようにする必要があります。この使用例では、Lambda 関数が deeplens/trash/inferの MQTT トピックを使用して Raspberry Pi にメッセージを送信するようにします。 サブスクリプションを追加した後、必ず Greengrass グループを AWS DeepLens にデプロイしてください。詳しい手順については、こちらをご覧ください。
デフォルトでは、AWS DeepLens はポート 8883 のトラフィックをブロックします。これは、ローカルの AWS IoT Greengrass 通信に必要です。この通信を許可するには、まずコンピュータのターミナルを開いて AWS DeepLens デバイスに SSH 接続し、ssh aws_cam@<YOUR_DEEPLENS_IP> と入力します。SSH 接続を有効にする必要がある場合は、こちらの手順に従ってください。次に、sudo ufw allow 8883 と入力してファイアウォールポートを開きます。 詳しい手順については、こちらをご覧ください。
Lambda 関数を更新するたびに、作成したデバイスとサブスクリプションで Greengrass グループを更新する必要があります。AWS IoT で新しいデバイスを再作成する必要はありません。その定義は残るからです。Greengrass グループに既存のデバイスを追加し、サブスクリプションを再作成して、グループをデプロイするだけです。
Raspberry Pi の設定
モデルの推論を MQTT トピックに送信するように AWS DeepLens を設定した後、MQTT トピックのメッセージをリッスンするように Raspberry Pi を準備する必要があります。Raspberry Pi は Python を使用して AWS IoT と対話するため、AWS IoT Device SDK for Python がインストールされていることを確認してください。詳細については、「AWS IoT Device SDK for Python のインストール」を参照してください。
Python スクリプトがメッセージを受信し、アクションを実行します。サンプルスクリプトについては、こちらからダウンロードできます。または、AWS IoT Device SDK のテンプレートとして basicDiscovery.py を使用して独自のスクリプトを作成することもできます。スクリプトは、新しい AWS IoT Greengrass デバイスの作成中にダウンロードされた証明書を使用します。詳細については、「通信のテスト」を参照してください。
まとめ
このチュートリアルでは、画像分類モデルをトレーニングし、それを AWS DeepLens にデプロイしてゴミを分類する方法を学びました。次に、ご自身のデータを使ってチュートリアルで説明した手順を実践してみてください。
このチュートリアルおよび AWS DeepLens を使用したその他のチュートリアル、サンプル、プロジェクトのアイデアの詳細な説明については、www.awsdeeplens.recipes を参照してください。
著者について
 Todd Reagan は、テキサス州ダラスを拠点とするアマゾン ウェブ サービスのソリューションアーキテクトで、Machine Learning と IoT に情熱を傾けています。余暇は、家族と屋外で過ごしたり、景勝地をめぐって写真撮影をしたり、ゴルフをしたりするのが好きです。
Todd Reagan は、テキサス州ダラスを拠点とするアマゾン ウェブ サービスのソリューションアーキテクトで、Machine Learning と IoT に情熱を傾けています。余暇は、家族と屋外で過ごしたり、景勝地をめぐって写真撮影をしたり、ゴルフをしたりするのが好きです。
 Varun Rao Bhamidimarri は、テキサス州ダラスに拠点を置くアマゾン ウェブ サービスのエンタープライズソリューションアーキテクトです。彼は、お客様がクラウド対応分析ソリューションを採用して、そのビジネス要件を満たせるように支援することに注力しています。
Varun Rao Bhamidimarri は、テキサス州ダラスに拠点を置くアマゾン ウェブ サービスのエンタープライズソリューションアーキテクトです。彼は、お客様がクラウド対応分析ソリューションを採用して、そのビジネス要件を満たせるように支援することに注力しています。
 Juan Pablo Bustos は、テキサス州ダラスに拠点を置くアマゾン ウェブ サービスのグローバルアカウントのソリューションアーキテクトです。余暇には、音楽を作曲して演奏したり、家族と一緒に行き当たったレストランを試したりして時間を過ごすのが大好きです。
Juan Pablo Bustos は、テキサス州ダラスに拠点を置くアマゾン ウェブ サービスのグローバルアカウントのソリューションアーキテクトです。余暇には、音楽を作曲して演奏したり、家族と一緒に行き当たったレストランを試したりして時間を過ごすのが大好きです。
 Raj Kadiyala は、AWS WWPS パートナー組織の AI/ML テクノロジービジネス開発マネージャーです。Raj は Machine Learning で 12 年以上の経験があり、余暇には機械学習を探索して日々使える実用的なソリューションを探したり、コロラドの素晴らしいアウトドアでアクティビティに勤しんだりするのが好きです。
Raj Kadiyala は、AWS WWPS パートナー組織の AI/ML テクノロジービジネス開発マネージャーです。Raj は Machine Learning で 12 年以上の経験があり、余暇には機械学習を探索して日々使える実用的なソリューションを探したり、コロラドの素晴らしいアウトドアでアクティビティに勤しんだりするのが好きです。
 Phu Nguyen は AWS DeepLens のプロダクトマネージャーです。彼は、あらゆるスキルレベルの開発者に機械学習の門戸を広げる製品を構築しています。
Phu Nguyen は AWS DeepLens のプロダクトマネージャーです。彼は、あらゆるスキルレベルの開発者に機械学習の門戸を広げる製品を構築しています。