Amazon Web Services ブログ
Amazon SageMaker を使用したメジャーリーグベースボールでの新しいスタッツの計算
ファンに沢山の新しい展開を見せてくれた爽快なレギュラーシーズンが終わり、2019 年のメジャーリーグベースボール (MLB) ポストシーズンがやってきました。MLB とアマゾン ウェブ サービス (AWS) は、MLB ゲームで盗塁成功確率、シフトの影響、およびピッチャーの類似点マッチアップ分析の 3 つの新しいリアルタイムの機械学習 (ML) スタッツを開発して実現するためにチームアップしました。これらの機能は、莫大な量の野球データを収集し、ファンが野球の試合を楽しむあらゆる面において、より多くの洞察、見解、および背景を提供するための MLB の最新鋭テクノロジー、Statcast Ai を通じて、ファンが野球をより深く理解できるようにしてくれます。
この記事では、ゲームへの深い洞察をファンに提供することにおいて機械学習が担う役割について見ていきます。また、これらの洞察の裏にある Amazon SageMaker でのトレーニングとデプロイメントプロセスを表すコードスニペットも提供します。
機械学習が二塁盗塁
盗塁成功確率は、ピッチャーと盗塁ランナー間におけるいたちごっこへの視聴者の理解に新たな奥行きを提供します。

盗塁成功確率を計算するため、AWS は MLB データを使用して、選手が盗塁しようとする場合に安全に二塁を踏むことができるかどうかを判断する 37 の変数を対象とした何千ものデータポイントを分析する ML モデルをトレーニングし、テストしてデプロイしました。これらの変数には、ランナーのスピードと瞬発力、キャッチャーの平均ポップタイム (二塁送球時間)、ピッチャーの球速と利き手、打者、ピッチャー、およびランナーの履歴的な盗塁成功率、そして試合状況についての関連データが含まれます。
私たちは、MLB によって提供された、約 5,500 の盗塁成功と約 1,800 の盗塁死の約 7,300 の盗塁試行に相当する 2015 年から 2018 年の履歴的なプレイデータを使用することで、ロジスティック回帰、サポートベクターマシン、ランダムフォレスト、およびニューラルネットワークなどのさまざまな分類アルゴリズムを探索する 10 分割交差検証アプローチをとりました。クラス不均衡に対応するため、クラスの重み、カスタム損失関数、およびサンプリング戦略を含む多数の戦略を適用し、盗塁成功の確立を予測するために最適なモデルが、人気の DL フレームワークで事前設定されている、Amazon Deep Learning (DL) AMI で訓練されたディープニューラルネットワークであることを突き止めました。トレーニングされたモデルは、予測をリアルタイムで試合時のグラフィックに統合するために必要な 1 秒未満の応答時間を提供した Amazon SageMaker を使用して、複数のアベイラビリティーゾーン全体で自動スケールされた ML インスタンスにデプロイされました。詳細については、Deploy trained Keras or TensorFlow models using Amazon SageMaker を参照してください。
一塁の選手が二塁盗塁を企てると、視聴者は画面で選手の盗塁成功確率スコアをリアルタイムで見ることができます。
MLB は 2018 年のポストシーズン中、ファンに盗塁成功確率のパイロットテストとプレビューを提供しました。実況アナウンサーとファンからのフィードバックの結果、MLB と AWS は前オフシーズン中に、新しいグラフィック、リプレイ用リアルタイムスタッツのために改善されたレイテンシー、そしてより洗練された外観の強化バージョンを共同で開発しました。特筆したい強化の 1 つは「Go Zone」で、これは選手が盗塁に成功する確率が最小 85% に達するという基準値に沿ったポイントです。
選手が二塁にリードを取り、「Go Zone」ポイントに到達すると、視聴者はその選手の成功確率が動的に変更され、成功の可能性が飛躍的に伸びるのを見ることができます。 ランナーが二塁を踏むと、「セーフ」または「アウト」判定のどちらになるかにかかわらず、視聴者には、最終的な結果を左右した可能性があるランナーの疾走速度やキャッチャーのポップタイムといった様々な要因から生成されたデータをリプレイ時に見る機会があります。また、そのデータは緑、黄色、および赤に色分けされており、選手が無事に二塁に進めたかどうかを決める上で最も大きな影響を与えた要因をファンが視覚化するために役立ちます。

内野守備戦略の影響の予測
過去 10 年間、MLB では内野シフトの台頭ほど劇的な変化はほとんどありませんでした。これは、「状況に応じた野手の守備位置の再編成で、野手を従来の守備位置から移動させる」ことです。 チームは、打者の打球の引っ張り傾向などの打球パターンを利用するためにシフトを使います (左利き打者にはライト、右利き打者にはレフト)。打者が打席に入ると、打者の履歴的な打球方向のエリアを守るために内野手がそれぞれの守備位置を調整します。
Statcast AI データを使用することにより、チームは安打を防ぐために選手をシフトすることによってその守備を有利にすることができ、チームは現在、野球史上のどの時代よりも頻繁にこの戦略を採用しています。リーグ全体のシフト率は、2016 年の 13.8% から 2019 年の 25.6% と、過去 3 年間で 86% 上昇しました。
AWS と MLB はチームを組んで、野球ファンにシフト戦略の有効性に対する洞察を提供するために機械学習を利用し、打者が打席に入る時に、履歴データと Amazon SageMaker を使用してシフト影響 (ゴロに関する打者の期待平均打率における変化) を推定するモデルを開発しました。内野手がフィールド内を移動すると、守備側の守備位置の変化で期待平均打率を再計算することによって、シフト影響が動的に更新されます。これによって、ファンにリアルタイムの経験が提供されます。
データを使用したシフト影響の数値化
打球分布図は、打者の特定の方向に球を打つ傾向を図示することができます。この分布図は、選手の打球がフィールドの各セクションに打たれる割合を示します。以下の図は、内野手の守備範囲内に飛んだジョーイ・ギャロ (テキサスレンジャーズ) の打球の 2018 年分布図を示すもので、本塁からの推定飛距離は 200 フィート (約 60 メートル) 以下として定義されています。詳細については、Baseball Savant でジョーイ・ギャロの現在のスタッツを参照してください。
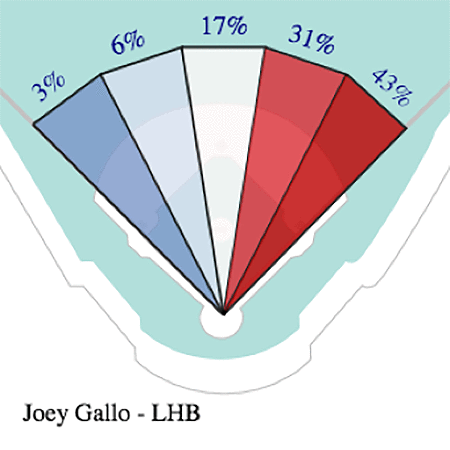
上記の図は、2018 年に 74% の打球を二塁の右側に飛ばしたジョーイ・ギャロの、球を右側に引っ張る傾向を示しています。準備を整えた守備側は、内野の右側に守備を集中させることでこの観察結果をうまく利用することができるため、球の軌道を遮り、打球をアウトにする可能性が高まります。
私たちは、過去 3 シーズンのプレー、つまり内野への約 60,000 の打球を考慮することにより、打者の履歴的な打球分布に基づいた打者に対する特定の内野手の配置の値を推定しました。これら打数それぞれについて、打者の既知の疾走速度と利き手を調べると同時に、打球の発射角度と打ち出し速度、および投球中の内野手の位置の情報を集めました。野球における攻撃力には多くの指標がありますが、私たちは Batting Average on Balls In Play、つまりフィールド内に飛んだ本塁打以外の安打の割合を使用することにしました。
特定の配置が攻撃値を低減させる量を推定することによって、シフトがどれほど効果的になり得るかを計算しました。球の予想飛行経路などの新しい特性を導き出し、カテゴリ変数の One-Hot-Encoding を行った後で、打たれた球が安打につながる確率を推定するために、データを各種 ML フレームワークに投入する準備が整いました。そこから、内野手の配置の変更に起因する確率の変化を計算することができるようになりました。
Amazon SageMaker を使用したシフト影響の計算
私たちは、ML モデルを 50,000 を超える打数サンプルでトレーニングし、Amazon SageMaker での事前構築された XGBoost アルゴリズム による Amazon SageMaker の自動モデルチューニング機能を使用したハイパーパラメータ最適化 (HPO) ジョブでのベイズ検索の結果が、ほぼ 10,000 イベントの検証セットにおいて全体的な精度 88%、リコール 88%、および f1 スコア 88% という最も高性能な予測を返したことを突き止めました。Amazon SageMaker での HPO ジョブの起動は、ジョブを説明するパラメータを定義するというシンプルなものです。起動後、ジョブをコアインフラストラクチャ (Amazon EC2、Amazon S3、Amazon ECS) に送りこみ、定義されたハイパーパラメータスペースを効率良くイテレートして、最適なモデルを探します。
ここに記載するコードスニペットは、AWS の製品とツールのための Python API である boto3 を使用します。Amazon SageMaker は、Amazon SageMaker と人気のあるディープラーニングフレームワークでの作業のための高レベルの抽象化がいくつか含まれたオープンソースライブラリである SageMaker Python SDK も提供します。
HPO ジョブの定義
これは、Amazon SageMaker クライアントをセットアップし、チューニングジョブを定義することから始めました。これによって、チューニング中に変更するパラメータと、最適化の対象としたい評価メトリクスが指定されます。以下のコードでは、検証セットにおけるログ損失を最小限にするように設定しました。
HPO ジョブの起動
上記の Python ディクショナリでチューニングジョブを定義したところで、それを Amazon SageMaker クライアントに送信します。このクライアントは次に、ECS から XGBoost を実行するように最適化されたコンテナを持つ EC2 インスタンスを起動するプロセスを自動化します。以下のコードを参照してください。
試合中、所定の打者をその最近の打数で分析し、これらのイベントをグリッドに配置された内野手のすべての位置についてモデルでこれらのイベントを実行することができます。推論のために必要なコンピューティング量は、各グリッドセルのサイズが縮小されると共に幾何学的に増加するため、サイズを調整して、意義のある予測に必要な解像度とコンピューティング時間の間バランスを取りました。例えば、左側にシフトした遊撃手について考えてみましょう。彼が 1 フィート (約 30 cm) しか動かなかった場合、打球の結果にはごくわずかな影響しかありません。しかし、彼が 10 フィート (約 3 メートル) 左に移動するとすれば、ライトに引っ張られたゴロを受け止めるためにより良い態勢を整えることができるでしょう。データセットにあるすべての打数を調べることによって、私たちは、10 フィート (約 3 メートル) 四方のセルで構成されているグリッドで、このようなバランスを見つけました。これは 10,000 を超える内野手構成に相当します。
HPO ジョブからパフォーマンスが最良のモデルを取得し、本番にデプロイするプロセスは次のセクションで説明します。リアルタイムの推論には多数のコールが必要であることから、モデルの結果は実際の試合中に関連する予測を提供するルックアップテーブルに事前投入されます。
パフォーマンスが最良のモデルのデプロイメント
各チューニングジョブは多数のジョブを起動し、そこから先ほど HPO の設定時に定義した基準に従って最良のモデルが選択されます。Amazon SageMaker から、まず最良のトレーニングジョブとそのモデルアーティファクトを引き出します。これらは S3 バケットに保存され、そこからトレーニングおよび検証データセットが引き出されます。以下のコードを参照してください。
次に、XGBoost モデルを実行するために最適化されている事前設定されたコンテナを参照し、それを最も良くトレーニングされたモデルのモデルアーティファクトにリンクします。アカウントでモデル/コンテナペアが作成されたら、インスタンスタイプ、インスタンスの数、および希望するトラフィック分割 (A/B テスト向け) でエンドポイントを設定することができます。
エンドポイントからの推論
Amazon SageMaker のランタイムクライアントは、モデルから予測を行い、EC2 のモデルコンテナをホストするエンドポイントにリクエストを送信して、出力を返します。カスタムモデルのためのエンドポイントのエントリポイントと、データ処理ステップを設定できます。
所定の打者と内野手構成に対するすべての予測を使用して、ルックアップテーブルに保存されたモデルから返された安打の確率の平均値を求め、打球の同じサンプルの Expected Batting Average を減算します。その結果のメトリックがシフト影響です。
マッチアップ分析
アメリカンリーグとナショナルリーグからのチームが互いに競い合うインターリーグ戦では、多くの打者がこれまで見たことのないピッチャーと対決します。インターリーグ戦の結果を推定することは、関連する履歴データに限りがあることから困難です。AWS は、類似したピッチャーをグループ化し、打者が類似するピッチャーに対してこれまでどのようにプレーしてきたかの洞察を得るために MLB と協力しました。私たちは、専門家の専門知識と何十万もの投球から成るデータを組み合わせて、類似するピッチャーを特定するために使用できる追加のパターンを見つけることを可能にする機械学習アプローチをとりました。
モデリング
マッチング問題が通常ユーザーの製品に対する志向を計算することによって解決されるレコメンデーションシステムの分野からヒントを得て、ここではピッチャーと打者間の相互作用を判断する方法を探ります。レコメンダーを構築するために適切なアルゴリズムは沢山ありますが、アルゴリズムに投入された類似アイテムをクラスター化できるものはあまりありません。この分野に最適なのがニューラルネットワークです。ニューラルネットワークアーキテクチャのエンド層は、それが画像であるかピッチャー ID であるかにかかわらず、入力データの数値表現として解釈することができます。入力データがあれば、それに関連付けられた数値表現、つまり埋め込みを他の入力アイテムと比較することができます。互いに近接するこれらの埋め込みは、この埋め込み領域内だけではなく、解釈可能な特性においても類似しています。例えば、私たちはどのピッチャーが類似しているかを定義する上で利き手が影響することを期待します。レコメンデーションシステムとアイテムのクラスタリングのこのアプローチは、Deep Matrix Factorization として知られています。
Deep Matrix Factorization は、エンティティのペア間における非線形相互作用から成り、コンテンツベースのフィルタリングと協調フィルタリングの技法も組み込まれています。Matrix Factorization のようにピッチャー/打者マトリクスだけで作業するのではなく、今回は各ピッチャーと打者をそれぞれ独自の埋め込みと整合させてから、それらを投球の結果を予想するためにトレーニングされた一連の隠れ層を通過させるニューラルネットワークを構築しました。このアーキテクチャの協調的な特質に加えて、ボールカウント、出塁しているランナーの人数、およびスコアなどの追加のコンテキストデータが各投球に含まれます。
モデルは各投球の予測結果に対して最適化されており、これには投球特性 (スライダー、チェンジアップ、速球など) と、結果 (ボール、ストライク、空振りなど) の両方が含まれます。この分類問題でモデルをトレーニングした後、ピッチャー ID 入力のエンド層が、その特定のピッチャーの埋め込みとして抽出されます。
結果
打者がこれまで対決したことのないピッチャーに対して打席に入る時、相手側のピッチャーに最も近い埋め込みを検索し、その一群のピッチャーに対して OPS (On-Base Plus Slugging) 割合を計算します。この結果を実際に見るには、9/11/19: FSN-Ohio executes OPS comparison をご覧ください。
まとめ
MLB は、ファンが野球を体験するためのさらなる方法を取り入れた革新的な経験を生み出すためにクラウドコンピューティングを使用します。盗塁成功確率、シフト影響、およびピッチャー類似性マッチアップ分析により、MLB はフィールドで起こっている事柄に関する説得力のあるリアルタイムの洞察を提供し、ファンが愛する試合のユニークなドラマを築き上げる背景へのつながりを強めます。
このポストシーズンでは、ファンがプレー中の盗塁確率、内野配置の潜在的な影響を目にし、ピッチャーが類似しているとされる理由について友人と討論を始める機会が何度もあるでしょう。
ファンには、ESPN および MLB Network などのパートナーによる試合の生放送でこれらの新しいスタッツを見ることを期待していいただけます。また、NFL およびフォーミュラ 1 などの他のプロスポーツリーグも、そのクラウドと機械学習のプロバイダーとして AWS を選択しています。
Amazon SageMaker での HPO ジョブの実装の初めから終わりまでの完全な例は、AWSLabs GitHub リポジトリでご覧いただけます。製品またはプロセスにおける機械学習の使用を促進させるための支援をご希望の場合は、Amazon ML Solutions Lab プログラムまでお問い合わせください。
著者について
 Hussain Karimi は Amazon ML Solutions Lab のデータサイエンティストで、様々な分野でユニークな洞察を見いだす機械学習モデルを開発するために AWS のお客様と連携しています。
Hussain Karimi は Amazon ML Solutions Lab のデータサイエンティストで、様々な分野でユニークな洞察を見いだす機械学習モデルを開発するために AWS のお客様と連携しています。
 Travis Petersen は MLB Advanced Media のシニアデータサイエンティストで、フォーダム大学の非常勤教授でもあります。
Travis Petersen は MLB Advanced Media のシニアデータサイエンティストで、フォーダム大学の非常勤教授でもあります。
 Priya Ponnapalli は Amazon ML Solutions Lab のプリンシパルサイエンティスト兼マネージャーで、さまざまな業界に属する AWS のお客様による AI およびクラウド導入促進のお手伝いをしています。
Priya Ponnapalli は Amazon ML Solutions Lab のプリンシパルサイエンティスト兼マネージャーで、さまざまな業界に属する AWS のお客様による AI およびクラウド導入促進のお手伝いをしています。