Amazon Web Services ブログ
Amazon RDS for SQL Server におけるリソース使用率メトリクスのキャプチャとチューニング
データベースリソースの使用率を把握すると、データベースワークロードの特性と使用傾向を理解するのに役立ちます。このデータは参照点として役立ち、後の測定値と比較することでパフォーマンスの問題を特定して調査できます。偏差は、パフォーマンスのチューニング、データベースのメンテナンス、または構成の変更を必要とする懸念事項を示している可能性があります。
リソース使用率は通常、オペレーティングシステムとデータベースの使用状況、データベースの待機イベント、クエリ処理時間など、データベースのパフォーマンスに影響を与えるメトリクスを取得します。通常の業務中にこのデータを定期的に収集することで、データベースインスタンスの状態に関する洞察を得ることができます。
Amazon Relational Database Service (Amazon RDS) は、1 分間隔でメトリクスデータを Amazon CloudWatch に自動的に送信します。期間が 1 分のデータポイントは 15 日間使用できます。つまり、開始点となるインスタンスの履歴情報があるということです。収集したメトリクスを使用して、CPU、メモリ、ディスク、ネットワーク、クライアント接続など、データベースインスタンスのリソース使用率を左右するアプリケーションのワークロードパターンを大まかに把握できます。
Amazon RDS には、RDS インスタンスのリソース使用状況を把握するのに役立つ以下のモニタリングツールが用意されています。
この投稿では、Amazon RDS for SQL Server でリソース使用率メトリクスをキャプチャしてチューニングする方法を示します。
Amazon RDS 拡張モニタリング
拡張モニタリングは、DB インスタンスが実行されているオペレーティングシステムのメトリクスをリアルタイムで提供します。これらのメトリクスには 1 秒単位で細かく設定することができ、Amazon RDS コンソールまたは API からアクセスできます。拡張モニタリングは DB インスタンス上のエージェントからメトリクスを収集するのに対し、CloudWatch はハイパーバイザーレイヤーでメトリクスを収集します。詳細については、「拡張モニタリング」をクリックしてください。
主なメトリクスは次のとおりです。
- CPU Utilization – CPU 使用率を監視すると、パフォーマンスの問題の原因が CPU 負荷によるものかどうかを特定するのに役立ちます。たとえば、パフォーマンスの問題が発生した時点で CPU 使用率が 80% で、先週の同じ時間帯の CPU 使用率が同様で問題が報告されなかった場合、CPU がボトルネックではない可能性があります。
- Disk – 読み取り/書き込み IOPS などのメトリクスを使用して I/O とストレージの使用パターンを追跡し、傾向を把握できます。また、ストレージのキャパシティプランニングにおいて、gp2 や io1 ディスクなどの使用可能なボリュームタイプから選択するのにも役立ちます
- Memory – パフォーマンス問題はメモリのボトルネックが関係していることが多くあります。拡張モニタリングでは、システム (合計メモリと使用可能なメモリ) と SQL Server (SQL Server の合計メモリ) のメモリ使用量とパターンを追跡して、ボトルネックを特定できます。
- Network – 拡張モニタリングによって収集されるネットワークパフォーマンスメトリクス (ネットワーク読み取り KB/秒、ネットワーク書き込み KB/秒) は、ネットワーク経由で転送されるデータ量を追跡するのに役立ちます。
これらのメトリクスを使用すると、ビジネスプロセスの重要な日時におけるリソースの使用状況を的確に把握できます。これらの値はリソース使用率の全体像を把握できるため、比較して潜在的なボトルネックを特定する必要がある場合に役立ちます。
CloudWatch でダッシュボードを作成すると、説明されているこれらのパフォーマンスメトリクスを一元的に表示できます。次のスクリーンショットは、CloudWatch と拡張モニタリングのデータを含む統合ダッシュボードを示しています。
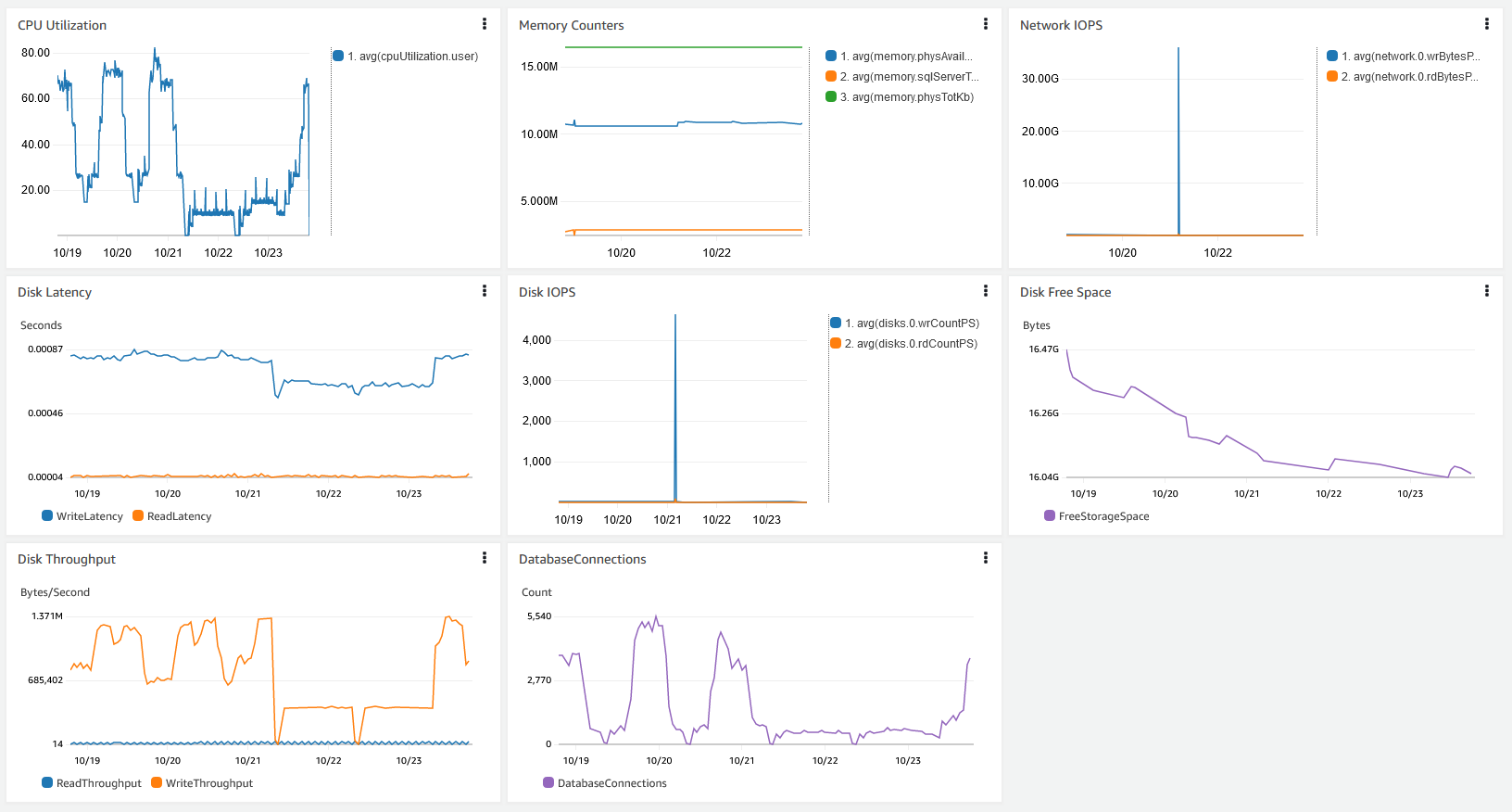
Amazon RDS Performance Insights
Performance Insightsは、RDS データベースのパフォーマンスに関する洞察を提供する監視ツールです。Performance Insights の無料利用枠では、RDS データベースから毎秒データを収集し、7 日間保持します。長期的なパフォーマンストレンドについては、パフォーマンスデータの履歴を最大 2 年間まで延長できます。Performance Insights で表示される情報は ネイティブパフォーマンスメトリクスに基づくため、RDS データベースエンジンごとに若干異なります。Performance Insights を使用すると、一定期間のデータベース負荷、上位の待機タイプ、上位 SQL クエリの傾向を収集できます。この情報を使用して現在のデータと比較し、潜在的な根本原因を特定できます。
ほとんどの SQL Server データベース管理者は、SQL Server の問題を診断およびデバッグするための動的管理ビュー (DMV) に精通しています。DMV ではデータは収集されたままであるため、使用傾向を把握するメカニズムを開発する必要があります。そこで、データの収集と保存を自動化することで Performance Insights が役に立ちます。
主なメトリクスは次のとおりです。
- Access Methods – ページ分割 – これにより I/O のボトルネックが発生する可能性があり、数値が大きい場合は、インデックスの再構築やフィルファクター設定の再検討などのメンテナンス作業が必要であることを示している可能性があります。
- Blocks and Locks – ロックの競合は SQL Server のパフォーマンス上の問題を引き起こす可能性があります。傾向分析のためだけでなく、データベースのパフォーマンスを向上させるためにチューニングが必要な SQL を特定するためにも、この情報を追跡することが重要です。ブロックされたプロセスとデッドロックの数を追跡できます。
- Memory Manager – 保留中のメモリ許可は、一定期間のメモリボトルネックを追跡するのに役立ちます。
- SQL Stats – Performance Insights には、バッチリクエスト、SQL コンパイル、SQL 再コンパイルなど、通常のデータベース負荷の原因となるタスクを理解するのに役立つさまざまな SQL 統計があります。
- Buffer Manager – ページ寿命とバッファキャッシュヒット率は、メモリ不足の検出に役立ちます。ページ読み取りとページ書き込みは、インデックス作成の見直しが必要な場合など、最適化方法に関するガイダンスを提供します。
これらのメトリクスは、SQL Server のパフォーマンスに関するインサイトを提供します。パフォーマンスメトリクスを含む OS とデータベースのメトリクスを詳しく調べて、問題の根本原因を理解することができます。次のスクリーンショットは、これらのメトリクスの例を示しています。

動的管理ビューとクエリストア
異常を特定したら、動的管理ビューを使用してさらに深く調査し、パフォーマンスの問題をデバッグできます。詳細については、「システム動的管理ビュー」を参照してください。
SQL Server 2016 以降、Amazon RDS for SQL Server はクエリストアもサポートします。これを使用して SQL ステートメントのクエリプランを追跡および管理できます。詳細については、「Amazon RDS for SQL Server が Microsoft SQL Server 2016 をサポートするようになりました」を参照してください。
問題の診断とデバッグ: CPU 使用率
アプリケーションが昨日まで最適なパフォーマンスを発揮していたのに、現在はパフォーマンスが低下しているという一般的なシナリオを見てみましょう。このユースケースでは、CloudWatch アラートまたはユーザーからの苦情を通じてこのことを知りました。
メトリクスを調べることから問題の診断を開始します。CloudWatch では、CPU 使用率メトリクスが高く、おそらく 90% を超えていることがわかります。SQL Server プロセスがこの高いパーセンテージに寄与しているかどうかを知りたいと思うでしょう。Amazon RDS コンソールのモニタリングタブのプロセスリストから確認できます。
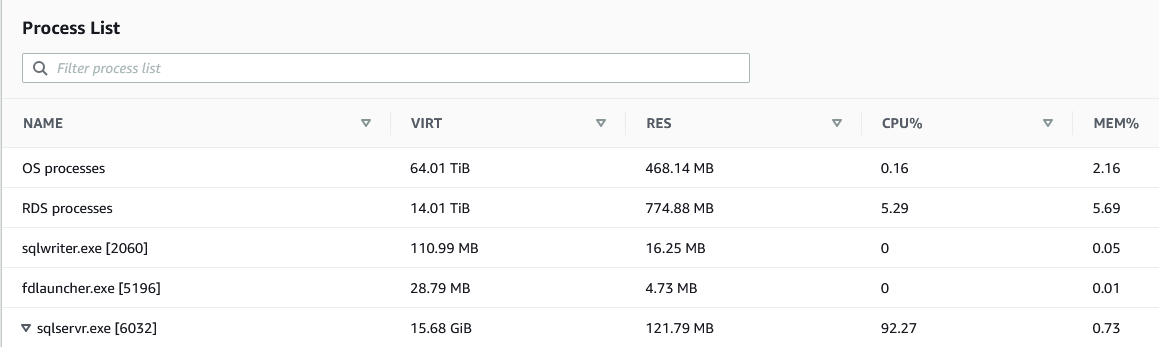
このような場合は、RDS インスタンスのリソース使用状況を追跡することが役立ちます。データがキャプチャされれば、時間の経過に伴う CPU 使用率の傾向を効率的に特定できます。拡張モニタリングでは、過去 30 日間のインスタンスの CPU 使用率の傾向をグラフ化できます。これにより、この挙動が正常かどうかがわかります。
次のステップは、Performance Insights でキャプチャされたデータを使用して、CPU 負荷の原因となっているクエリを特定することです。次のスクリーンショットは、時間の経過と共に蓄積されたデータを含むグラフを示しています。
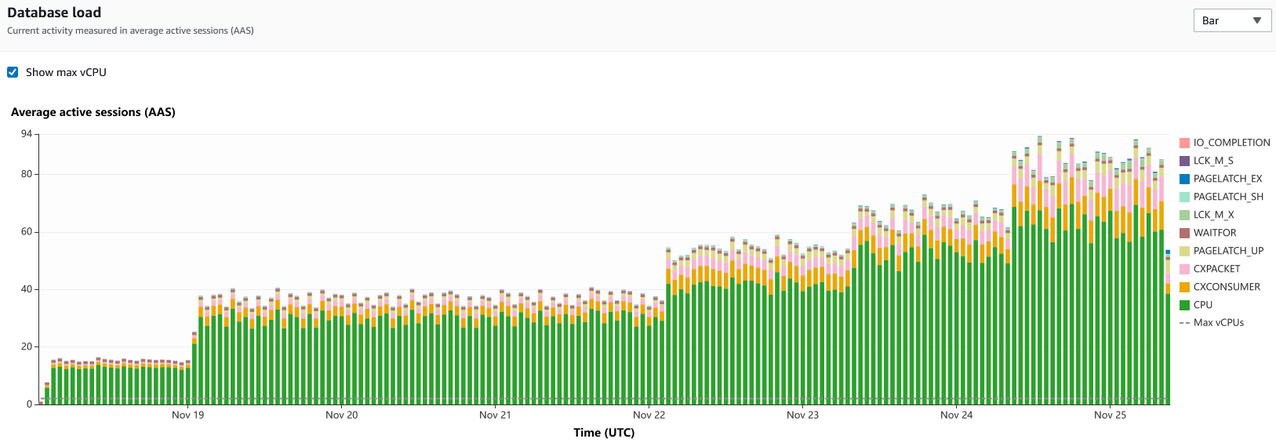
このグラフから、このインスタンスでは CPU の待ち時間が大部分であり、一定期間にわたって増加していることがわかります。この傾向から、キャパシティプランニングに必要なデータも得られます。
関心のある時間に絞り込むと、CPU 使用率別の上位 T-SQL クエリのリストを表示できます。動的管理ビューから実行プランやクエリに関する詳細情報を取得できます。
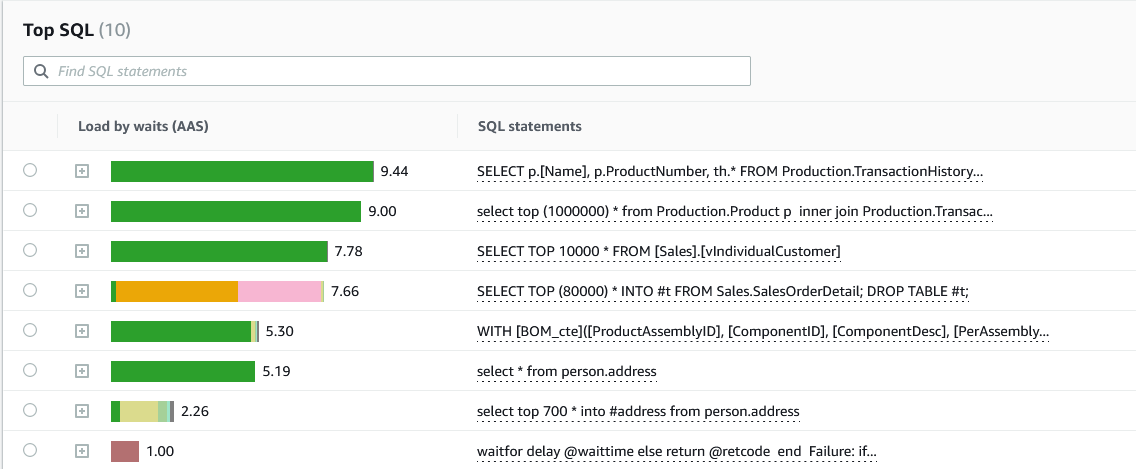
高い CPU 負荷の原因となっている上位 3 つのクエリをとうとう特定しました。クエリ自体に加えて、クエリを実行している上位のホストと上位ユーザーを特定して、トラブルシューティングの取り組みをさらに絞り込むことができます。
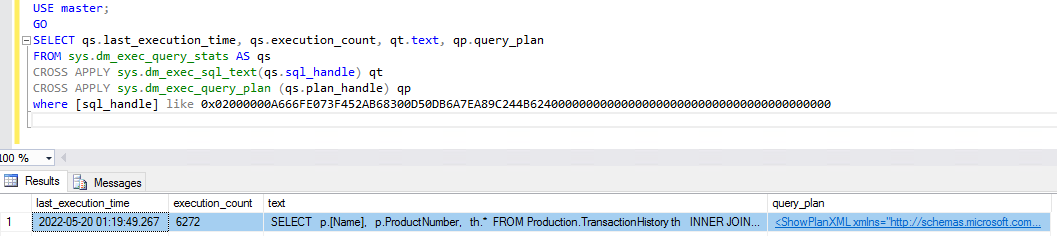
最初のクエリを例として使用します。SQL Server Management Studio (SSMS) を使用してクエリの実行統計と実行プランを取得するには、まずクエリのフィンガープリントを知る必要があります。この情報は、パフォーマンスインサイトから取得できます。

SQL ID は、統計と実行プランを取得するために動的管理ビューに入力する値です。次のスクリーンショットに示すように、SQL ID の前に 0x を付ける必要があります。
クエリプランを作成したら、次のステップは、既知のクエリ最適化方法を使用してクエリを最適化することです。
結論
この投稿では、インスタンスの状態と使用パターンをキャプチャして分析するための優れた方法を提供する、Amazon RDS for SQL Server の拡張モニタリングと Performance Insights について学びました。この情報があると、パフォーマンス問題の最適化とトラブルシューティングに役立ちます。この記事で説明する方法を使用すると、インスタンスのパフォーマンスを向上させることができます。
著者について
 Barry Ooi は、AWSのシニアデータベーススペシャリストソリューションアーキテクトです。彼の専門分野は、お客様が AWS を利用する一環としてクラウドネイティブサービスを使用してデータプラットフォームを設計、構築、実装することです。彼の関心分野には、データ分析と視覚化が含まれます。休暇では、音楽と野外活動を楽しみます。
Barry Ooi は、AWSのシニアデータベーススペシャリストソリューションアーキテクトです。彼の専門分野は、お客様が AWS を利用する一環としてクラウドネイティブサービスを使用してデータプラットフォームを設計、構築、実装することです。彼の関心分野には、データ分析と視覚化が含まれます。休暇では、音楽と野外活動を楽しみます。
 LRita Ladda は、アマゾンウェブサービスのマイクロソフトスペシャリストシニアソリューションアーキテクトで、さまざまなマイクロソフトテクノロジーで 20 年以上の経験があります。SQL Server やその他のデータベースにおけるデータベースソリューションの設計を専門としています。Microsoft ワークロードの AWS への移行とモダナイゼーションに関するアーキテクチャに関するガイダンスをお客様に提供しています。
LRita Ladda は、アマゾンウェブサービスのマイクロソフトスペシャリストシニアソリューションアーキテクトで、さまざまなマイクロソフトテクノロジーで 20 年以上の経験があります。SQL Server やその他のデータベースにおけるデータベースソリューションの設計を専門としています。Microsoft ワークロードの AWS への移行とモダナイゼーションに関するアーキテクチャに関するガイダンスをお客様に提供しています。
翻訳はソリューションアーキテクトの Yoshinori Sawada が担当しました。原文はこちらです。