Amazon Web Services ブログ
Category: Analytics
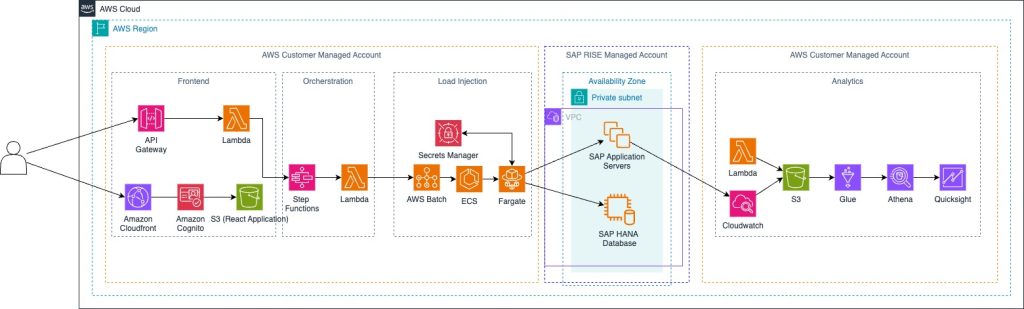
SAPの負荷テスト:AWSによるサーバーレスアプローチ
SAPシステムの適切な負荷テストを実施することは、ピーク使用時にシステムがビジネスのパフォーマンスと信頼性の期待に応えられることを保証する主要な要因です。負荷テストが必要となる典型的なシナリオには、新しい会社/国の展開、ECCからS/4HANAへのソフトウェアリリースアップグレード、アプリケーションパッチ(例:サポートパッケージ)、S/4HANA変革プロジェクト、またはSAP RISEへの移行があります。このような大規模な変更後の安定した運用を確保するため、潜在的なパフォーマンス関連の問題を回避するために、本番カットオーバー前に負荷テストを実行することが推奨されます。このブログでは、オンプレミスまたはRISEにデプロイされたSAP ERPシステムに異なるタイプの負荷を注入するために、AWS上で負荷テストプラットフォームを実装し使用する方法を学びます。

re:Invent 2025 で学ぶ AI を活用した運用管理の構築方法
組織がクラウド環境を拡大し進化させ続ける中、効果的な運用管理はこれまで以上に重要になっています。AWS re:Invent 2025 の Cloud Operations トラックにおける運用管理セッションは、AWS 環境全体で回復力があり、セキュアで効率的な運用プラクティスを構築するのに役立つ包括的なラインナップを提供します。複雑なマルチクラウド環境の管理、AI を活用した自動化の実装、災害復旧戦略の強化など、このトラックはあらゆる方々にコンテンツを提供します。
このブログでは、運用管理における主要テーマを紹介し、クラウド運用戦略を変革するのに役立つセッションを紹介します。

Amazon MSK Express ブローカーが Intelligent Rebalancing をサポートし、操作パフォーマンスが 180 倍高速に
本日より、Amazon Managed Streaming for Apache Kafka (Amazon MSK) Provisioned クラスターで Express ブローカーを使用するすべての新規クラスターで、追加料金なしで Intelligent Rebalancing がサポートされます。この新機能により、Apache Kafka クラスターのスケールアップまたはスケールダウン時に自動的なパーティションバランシング操作を実行できます。Intelligent Rebalancing は、Express ブローカーを使用する Amazon MSK クラスターの Kafka リソースを最適にリバランスすることで、キャパシティ使用率を最大化し、パフォーマンスを向上させます。これにより、パーティションを個別に管理したり、サードパーティツールを使用したりする必要がなくなります。Amazon MSK Express ブローカーの Intelligent Rebalancing は、Standard ブローカーと比較して最大 180 倍高速にこれらの操作を実行します。

D2L が Amazon Quick Sight のビジュアルデータ準備を使用して教育分析を変革した方法
本ブログでは、D2L が Amazon Quick Sight の新しいデータ準備機能を活用し、Performance+ パッケージの Brightspace Analytics 機能を強化した事例をご紹介します。この取り組みにより、教育機関全体でデータインサイトが民主化され、技術的な専門知識を必要とせず、シンプルなクリック操作だけで教育者や管理者が生データを実用的なインサイトに変換できるようになりました。QuickSight の新しいデータ準備エクスペリエンスは、データ変換のための視覚的でローコードなインターフェースを提供することで、技術的な障壁を取り除き、あらゆるスキルレベルのユーザーがデータを直接扱えるようにし、D2L の教育分析アプローチに革命をもたらしました。

Amazon Quick Sight を使用して SQL なしでデータ準備フローを構築する
本ブログでは、中堅小売企業である AnyCompany が、新しい Quick Sight データ準備エクスペリエンスを使用して、ビジネスアナリストが SQL を一行も書くことなく複雑なデータを変換する方法をご紹介します。ステップバイステップのビジュアルインターフェースは、組織がデータを扱う方法を変革し、追加、結合、ピボット解除、集計などの機能を提供することで、技術的な専門知識を持たないユーザーでもデータ変換を利用できるようにする直感的なポイント&クリックインターフェースを通じて、実際のデータ課題を解決します。

Amazon RDS for PostgreSQL および Amazon Aurora PostgreSQL データベース向け AI 搭載チューニングツール: PI Reporter
AWS では、Amazon Relational Database Service (Amazon RDS) […]

Amazon Kinesis Data Streams の On-demand Advantage モード – スループットの即時増加とスケーラブルなストリーミング
Amazon Kinesis Data Streams の新しい On-demand Advantage モードでは、ウォームスループット機能により最大 10 GiB/s の即時にスケーリングでき、コミット使用量料金でスループット使用量が少なくとも 60% 割引されます。トラフィックスパイクへの備えとコスト最適化の両方を実現します。

Amazon Redshift DC2 ノードタイプから Amazon Redshift Serverless へのアップグレード
Amazon Redshift dense compute (DC2) インスタンスから Amazon Redshift Serverless へデータウェアハウスをアップグレードすることでこれらの利点が得られ、ユーザーエクスペリエンスの向上と運用の簡素化を実現し、より効率的でスケーラブルなデータ分析ソリューションを提供します。
この記事では、DC2 インスタンスから Amazon Redshift Serverless へのアップグレードプロセスをご紹介します。

Amazon Quick Sight の軸とデータラベルのフォントカスタマイズによるダッシュボードデザインの拡張
本ブログでは、Amazon Quick Sight ビジュアルの軸とデータラベルに対する新しいフォントカスタマイズ機能について、読みやすくブランドに一貫性のあるダッシュボードを作成するための手順とベストプラクティスを含めて説明します。これらの機能強化により、フォントサイズ、フォントファミリーの選択、テキストスタイルオプション、カスタムカラーをピクセルレベルで制御でき、ダッシュボードのビジュアルデザインを微調整し、エンドユーザーの可読性を向上させることができます。

カスタムパーミッションを使用した Amazon Quick Suite 機能のガバナンス自動化
本ブログでは、Amazon Quick Suiteのカスタム権限を使用してアカウントレベルで機能レベルの制限をプログラムで実装する方法を実証し、組織がエンタープライズグレードのセキュリティとコンプライアンスを維持しながら生成AIの最新イノベーションを採用できるよう支援します。CloudTrail、EventBridge、Lambda、CloudFormationなどのAWSサービスを使用して、新規および既存のQuick Suiteアカウントサブスクリプションの両方でアカウントレベルのAIベース機能をオフにするためにカスタム権限を適用する方法を説明します。