Amazon Web Services ブログ
OpenSearch における 10 億規模のユースケースに適した k-NN アルゴリズムの選定
この記事は、Choose the k-NN algorithm for your billion-scale use case with OpenSearch を翻訳したものです。
自然言語処理 (NLP) システムや、レコメンドエンジン、または検索システムなどの機械学習 (ML) アプリケーションを構築しようとすると、ワークフローのどこかで k 最近傍 (k-NN) 検索アルゴリズムを使用することがよくあります。データポイントの数が数億や数十億に達すると、k-NN 検索システムのスケーリングが大きな課題となります。近似最近傍 (ANN) 検索アルゴリズムは、この課題を解決するための優れた方法の 1 つです。
k-NN は、他の ML の技術と比較すると比較的シンプルな問題です。それは、点の集合とクエリが与えられた時、クエリに最も近い k 個の点を集合の中から探すという問題です。その素朴な解法も同様に理解しやすいです。つまり、集合の中のそれぞれの点において、クエリとの距離を計算し、その途中の上位 k 個を記録するという解法です。

この素朴なアプローチの問題点は、それほどスケールしないことです。検索時の計算量は O(NlogK) となります。ここで、N はベクトルの数、k は最近傍点の数です。この計算量は、点が数千ほどしかない場合はあまり気になりませんが、サイズが数百万となると顕著になります。正確には k-NN アルゴリズムの中には検索を高速化できるものもありますが、高次元においては素朴な方法と同じような性能になりがちです。
ANN 検索の話に移ります。k-NN 問題におけるいくつかの制約を緩めれば、検索時のレイテンシーを減らすことができます。
- インデックス作成にかかる時間が増えることを許容する
- クエリ時に使用するメモリ空間が増えることを許容する
- 集合の中の k-NN の近似を返すことを許容する
これを実現するいくつかアルゴリズムがこれまで発見されています。
OpenSearch は、コミュニティ主導の Apache 2.0 ライセンスのオープンソース検索・分析ソフトウェアであり、データの取り込み、検索、可視化、分析を容易に行うことができます。OpenSearch k-NN プラグインは、OpenSearch クラスター内でこれらのアルゴリズムのいくつかを使用する機能を提供しています。この記事では、サポートされている異なるアルゴリズムについて考察し、それらの間のトレードオフを学ぶために実験を行います。
Hierarchical Navigable Small Worlds (HNSW) アルゴリズム
Hierarchical Navigable Small Worlds (HNSW) アルゴリズムは、ANN 検索で最も良く使われるアルゴリズムの 1 つです。k-NN プラグインがサポートした最初のアルゴリズムであり、近傍検索ライブラリ nmslib の非常に効率的な実装を使用しています。これはクエリのレイテンシーと Recall (再現率) のトレードオフが最も優れており、また学習が不要です。このアルゴリズムの核となる考え方は、互いに近いインデックスベクトルを結ぶエッジを持つグラフを構築することです。そして、検索時にはこのグラフを部分的に走査してクエリベクトルの近似最近傍を見つけます。クエリの最近傍の方向に向けて走査するために、このアルゴリズムは常にクエリに最も近い候補を次に訪れます。
しかし、どのベクトルから走査を始めるべきでしょうか?ランダムなベクトルを選ぶこともできますが、インデックスが大きい場合にはクエリの実際の最近傍から大きく離れてしまう可能性があり、悪い結果に繋がってしまいます。クエリベクトルから大まかに近いベクトルから探索を始めるために、このアルゴリズムでは 1 つのグラフだけでなく、階層構造のグラフを構築します。全てのベクトルは最下層に追加され、ランダムなサブセットがその上の層に追加され、それらのランダムなサブセットがその上の層に追加され、といったような具合で構築されます。
検索時には、最上層のランダムなベクトルから初め、部分的に走査してその層におけるクエリベクトルの最近傍点を (近似的に) 見つけ、そしてこのベクトルを出発点として下の層を走査していきます。これを最下層に到達するまで繰り返します。最下層では、走査を行いますが、今回は最近傍をただ探索するのではなく、途中で訪れた k 最近傍点を記録します。
下図はその過程を表しています。 (この図は原著論文 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs 内の画像から着想を得ています)
 HNSW では 3 つのパラメータを調整することができます。
HNSW では 3 つのパラメータを調整することができます。
- m – グラフ内で 1 つのベクトルが持つことのできるエッジの最大数です。この値が大きいほど、グラフが消費するメモリ量は多くなりますが、検索の近似性能は良くなる可能性があります。
- ef_search – 走査時に訪れる候補ノードのキューのサイズです。あるノードを訪れると、その近傍ノードが将来訪れるノードとしてキューに追加されます。この値が大きいほど検索のレイテンシーが増しますが、検索のより良い近似が得られる可能性があります。
- ef_construction –
ef_searchと非常に似ています。このアルゴリズムでは、あるノードがグラフに追加されると、この新しいノードをクエリベクトルとしてグラフにクエリを行い、m 個のエッジを見つけます。このパラメータは、この走査における候補のキューサイズを決定します。この値が大きいほどインデックス作成にかかるレイテンシーが増えますが、検索のより良い近似が得られる可能性があります。
HNSW の詳細については、論文 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs をお読みください。
メモリ消費
HNSW は非常に優れた近似最近傍検索を低レイテンシーで実現できますが、大きなメモリを消費し得ます。HNSW の各グラフはおよそ 1.1 * (4 * dimension + 8 * m) * num_vectors バイトのメモリを消費します。
dimensionはベクトルの次元です。mはアルゴリズムのパラメータであり、1 つの層の中における各ノードの接続数を決めます。num_vectorsはインデックス内のベクトルの数です。
耐久性と可用性を保証するために、特に本番のワークロードで実行する場合は、OpenSearch のインデックスは少なくとも一つのレプリカシャードを持つことが推奨されています。したがって、必要なメモリは (1 + レプリカ数) 倍になります。それぞれが 128 次元のベクトルが 10 億個あるデータ量で、m がデフォルトの 16 に設定されている場合、必要なメモリ量は以下のように推定されます。
1.1 * (4 * 128 + 8 * 16) * 1,000,000,000 * 2 = 1,408 GB
例えば、ベクトルのサイズを 512 次元に、 m を固有次元が高いベクトルに推奨される値である 100 に上げると、ユースケースによっては、合計で約 4 TB のメモリが必要になることがあります。
OpenSearch では、このメモリ要件に対応するために、常にクラスターを水平にスケールすることができます。しかし、これはインフラストラクチャのコストの対価を払うことになります。スケーリングがあまり意味をなさない場面では、k-NN システムのメモリフットプリントを減らす選択肢を検討する必要があります。幸いなことに、これを実現するためのアルゴリズムは存在します。
転置ファイルシステム (IVF) アルゴリズム
最近傍近似を行う異なるアプローチを検討してみましょう。インデックスベクトルを複数のバケットに分け、そして、検索時間を減らすためにそれらのバケットのサブセットのみを検索します。大まかに言うと、これが転置ファイルシステム (IVF) ANN アルゴリズムが行っていることです。OpenSearch 1.2 では、k-NN プラグインが Faiss による IVF 実装をサポートするようになりました。Faiss は Meta がオープンソースで提供している、密なベクトルの近傍検索とクラスタリングを効率的に行うライブラリです。
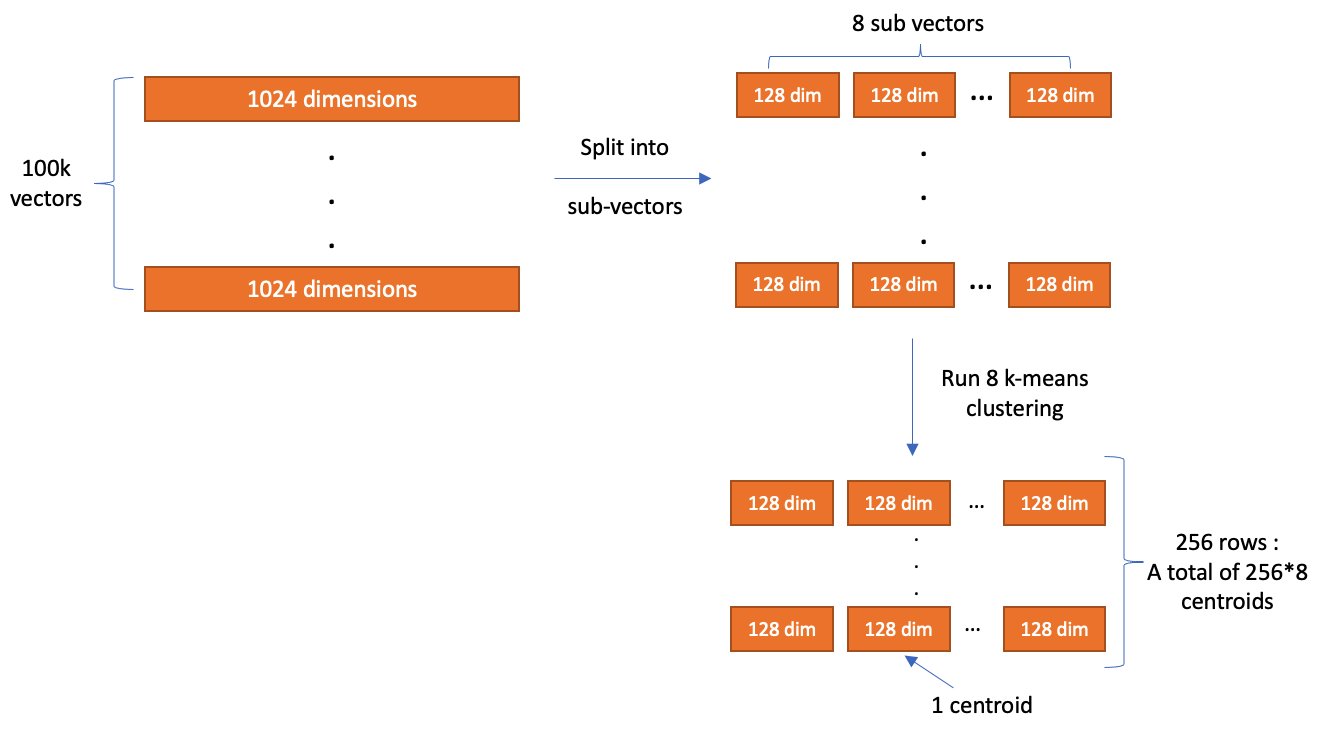
しかし、ランダムにベクトルを異なるバケットに分割してそのサブセットのみを検索すると、近似性能が低くなってしまいます。IVF アルゴリズムは、よりエレガントなアプローチを使用しています。まず、インデックスの作成を始める前に、各バケットに代表的なベクトルを割り当てます。ベクトルをインデックス化すると、最も近い代表ベクトルを持つバケットに追加されます。このように、互いに近いベクトルは大体同じかあるいは近くのバケットに配置されます。
バケットの代表ベクトルを決定するために、IVF アルゴリズムは学習が必要になります。このステップでは、学習データに対して k-Means クラスタリングを行い、その結果得られるセントロイドのベクトルを代表ベクトルとします。下図はその過程を表したものです。

IVF には 2 つのパラメータがあります。
- nlist – 作成するバケットの数。バケットが多いと学習時間が長くなりますが、検索の精度が向上する可能性があります。
- nprobes – 検索するバケットの数。このパラメータはかなり単純なものです。検索するバケットの数が多いと、検索時間が長くなりますが、より良い近似が得られるようになります。
メモリ消費
一般的に、IVF はインデックス化されたベクトルごとにエッジの集合を保存する必要がないため、HNSW に比べて必要なメモリが少ないです。
IVF ではおよそ次のようなメモリ量が必要になると推測されます。
1.1 * (((4 * dimension) * num_vectors) + (4 * nlist * dimension)) bytes
HNSW の章で調査した、10 億個の 128 次元ベクトルがありレプリケーション数が 1 であるという場面において、nlist が 4096 の IVF アルゴリズムでは以下のメモリ量が必要になります。
1.1 * (((4 * 128) * 2,000,000,000) + (4 * 4096 * 128)) bytes = 1126 GB
HNSWの方がクエリのレイテンシーと近似精度のトレードオフが優れているため、メモリの節約には代償を伴います。
直積量子化 (PQ) ベクトル圧縮
HNSW や IVF を使うと最近傍検索を高速化することができますが、多量のメモリを消費してしまいます。10 億ベクトルほどの規模となると、インデックス構造を保つために数千 GB のメモリが必要になってきます。ベクトル数やベクトルの次元数を大きくすると、この要件はさらに大きくなります。k-NN のインデックスが使用する領域を大幅に削減する方法はないのでしょうか?
答えはイエスです!実際に、ベクトルが必要とするメモリの量を減らす方法には様々なものがあります。埋め込みモデルを変更して小さなベクトルを生成したり、主成分分析 (PCA) のような技術を使ってベクトルの次元数を削減することもできます。他にも、量子化を使用した方法があります。量子化の一般的な考え方は、連続した値を持つ大きなベクトル空間を離散的な値を持つ小さな空間にマッピングするというものです。ベクトルが小さな空間にマッピングされると、より少ないビット数で表現することができます。しかし、その代償として、小さな空間にマッピングされると、ベクトルに関するいくらかの情報が失われてしまいます。
直積量子化 (PQ) は最近傍検索の領域では非常に良く使われる量子化手法です。ANN アルゴリズムと併用して最近傍検索に使うことができます。 OpenSearch 1.2 では、k-NN プラグインに IVF と共に Faiss の PQ 実装をサポートするようになりました。
PQ の主な考え方は、一つのベクトルをいくつかのサブベクトルに分割し、サブベクトルを固定長のビット数でそれぞれ符号化するというものです。元のベクトルを分割するサブベクトルの数はパラメータ m で制御し、各サブベクトルを符号化するためのビット数は code_size で制御します。符号化が終わると、ベクトルはおよそ m * code_size ビットに圧縮されます。例えば、10万個の 1024 次元のベクトルがあるとします。m = 8、code_size = 8 とすると、PQ は各ベクトルを 8 個の 128 次元のベクトルに分割し、各サブベクトルを 8 ビットに符号化します。
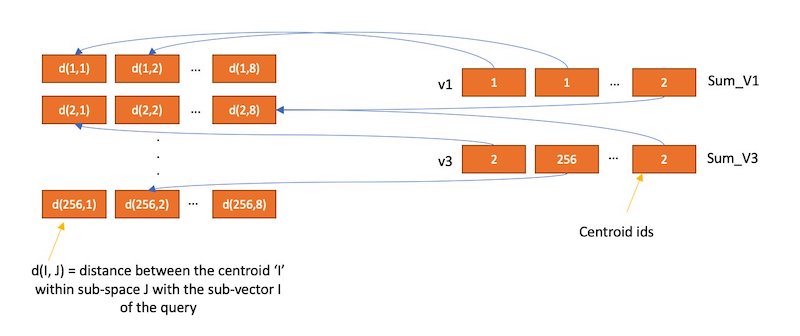
符号化に使用する値は学習段階で生成されます。学習時には、各サブベクトルのパーティションにつき 2encode_size のエントリーを持つテーブルを作成します。次に、k の値を 2encode_size とする k-Means クラスタリングを、学習データにおけるサブベクトルのパーティションに対して実行します。ここで生成されるセントロイドがパーティションのテーブルのエントリとして追加されます。
全てのテーブルが作成された後、各サブベクトルをパーティションのテーブルで最も近いベクトルの ID に置き換えることにより、ベクトルを符号化します。code_size = 8 の例では、テーブルの要素が 28 個であるため、ID を保存するのに 8 ビットしか必要ではありません。つまり、dimension = 1024、m = 8 とすると、1 つのベクトルの合計サイズは (32 ビット浮動小数点のデータ型を使用すると仮定すると) 4096 バイトから約 8 バイトに削減されます!
 ベクトルを復号化したい時は、保存された ID を利用して各パーティションのテーブルからベクトルを取り出すことで、近似的にベクトルを再構成することができます。そして、クエリベクトルから再構成したベクトルまでの距離を計算し、最近傍検索に利用することができます。(実際には、この処理を高速化するために ADC などの更なる最適化技術が k-NN 検索に使われることは注目に値します)
ベクトルを復号化したい時は、保存された ID を利用して各パーティションのテーブルからベクトルを取り出すことで、近似的にベクトルを再構成することができます。そして、クエリベクトルから再構成したベクトルまでの距離を計算し、最近傍検索に利用することができます。(実際には、この処理を高速化するために ADC などの更なる最適化技術が k-NN 検索に使われることは注目に値します)
 メモリ消費
メモリ消費
先に述べたように、PQ は各ベクトルをおよそ m * code_size ビットにいくらかのオーバーヘッドを加えて符号化します。
IVF と組み合わせる時、インデックスサイズを次のように見積もることができます。
1.1 * ((((code_size / 8) * m + overhead_per_vector) * num_vectors) + (4 * nlist * dimension) + (2 code_size * 4 * dimension) bytes
10 億ベクトル、dimension = 128、m = 8、code_size = 8、n_list = 4096 とすると、推定される合計のメモリ消費量は 70 GB となります。
1.1 * ((((8 / 8) * 8 + 24) * 1,000,000,000) + (4 * 4096 * 128) + (2^8 * 4 * 128)) * 2 = 70 GB
OpenSearch で k-NN を実行する
まず、OpenSearch のクラスターが稼働していることを確認します。手順については、Cluster formation を参照してください。よりマネージドなソリューションとして、Amazon OpenSearch Service を使用することもできます。
実験に入る前に、OpenSearch で k-NN ワークロードを実行する方法について説明します。まず、インデックスを作成する必要があります。インデックスとは、一連のドキュメントを容易に検索できるような形で保存するものです。k-NN の場合、インデックスのマッピングは OpenSearch に何のアルゴリズムを使用し、どのパラメータを使用するかを伝えます。まず、検索アルゴリズムとして HNSW を使用するインデックスを作成するところから始めます。
mappings では、ベクトルデータを保存するために、knn_vector データ型の my_vector というフィールドを設定します。また、OpenSearch が nmsllib の HNSW 実装を使用するように、engine に nmslib を設定します。さらに、space_type に l2 を渡しています。space_type は、2 つのベクトル間の距離を計算するために使われる関数を意味します。l2 はユークリッド距離を指します。OpenSearch はコサイン類似度や内積距離関数もサポートしています。
インデックスが作成された後、いくつか偽のデータを取り込むことができます。
ドキュメントをインデックスにいくらか追加したら、それを検索することができます。
IVF や PQ を使用するインデックスを作成する方法は、これらのアルゴリズムが学習を必要とするため、少し異なります。インデックスを作成する前に、学習 API を使用してモデルを作成する必要があります。
training_index と training_field は学習データの格納場所を指します。学習データのインデックスに必要なのは、モデルに必要なのと同じ次元の knn_vector フィールドを持つことだけです。method は検索に使用するアルゴリズムを定義します。
学習のリクエストが送信されると、バックグラウンドで学習が実行されます。学習が完了したかどうか確認するには、GET model API を使用します。
モデルが作成されると、このモデルを使用するインデックスを作成することができます。
インデックスを作成したら、HNSW の時と同じように、そこにドキュメントを追加して検索することができます。
実験
これらのアルゴリズムが実際にどのような性能になるのか、どのようなトレードオフがあるのかを知るためにいくつかの実験を行ってみましょう。ここでは、HNSW と PQ を使用した IVF インデックスを比較します。この実験では、検索精度クエリレイテンシー、メモリ消費量に注目します。これらのトレードオフはスケール時に観測されるものであるため、128 次元の 10 億個のベクトルを含む BIGANN データセットを使用します。このデータセットには、ユークリッド距離において、クエリを最も近い 100 個の教師データベクトルにマッピングした、テストデータの 1 万クエリも含まれています。
具体的には、以下の検索メトリクスを計算します。
- Latency p99 (ms), Latency p90 (ms), Latency p50 (ms) – いくつかの分位数におけるクエリのレイテンシー (ミリ秒単位)
- recall@10 – プラグインが返した 10 個の結果のうち、近傍の教師データの上位 10 個が含まれる割合
- Native memory consumption (GB) – クエリ実行時にプラグインが使用するメモリ量
注意点として、BIGANN データセットはデータ型として符号なし整数を使用していることです。knn_vector フィールドは符号なし整数をサポートしていないため、データは自動的に浮動小数点に変換されます。
実験を実行するために、以下のステップを行います。
- OpenSearch ベンチマークフレームワークを使用して、クラスターにデータセットを取り込みます。(コードは GitHub にあります)
- 取り込みが完了したら、warm API を使用して、検索ワークロードのためにクラスターを準備します。
- 1 万個のテストクエリをクラスターに対して 10 回実行し、集計結果を得ます。
このクエリはパフィーマンスを向上させるために、ベクトルではなくドキュメント ID のみを返します (このコードは GitHub にあります)。
パラメータ選択
実験を行う上で厄介なのは、パラメータの選択です。全てをテストするには異なるパラメータの組み合わせが多すぎます。そこで、HNSW と IVFPQ について、3 つの構成を作ることにしました。
- 検索レイテンシーとメモリを最適化する
- recall を最適化する
- その中間を取る
それぞれの最適化戦略では、2 つの構成を選択しました。
HNSW では、目的のトレードオフを実現するために、m、ef_construction、ef_search のパラメータを調整することができます。
- m – グラフ内のノードが持つことができるエッジの数の最大数を制御します。各ノードがその全てのエッジを保存する必要があるため、 この値を大きくするとメモリフットプリントが増加しますが、グラフの接続性が向上して recall が改善されます。
- ef_construction – グラフにノードを追加する時のエッジの候補キューのサイズを制御します。この値を大きくすると検討する候補の数が増え、インデックスのレイテンシーが増加します。しかし、より多くの候補が考慮されるため、グラフの質が向上し、検索時の recall の向上に繋がります。
- ef_search –
ef_constructionと似ており、検索時にグラフを走査するための候補キューのサイズを制御します。この値を大きくすると、検索レイテンシーは増加しますが、recall も向上します。
一般に、次の表に詳述するように、パラメータを徐々に増加させるような構成としました。
| Config ID | 最適化戦略 | m | ef_construction | ef_search |
| hnsw1 | Optimize for memory and search latency | 8 | 32 | 32 |
| hnsw2 | Optimize for memory and search latency | 16 | 32 | 32 |
| hnsw3 | Balance between latency, memory, and recall | 16 | 128 | 128 |
| hnsw4 | Balance between latency, memory, and recall | 32 | 256 | 256 |
| hnsw5 | Optimize for recall | 32 | 512 | 512 |
| hnsw6 | Optimize for recall | 64 | 512 | 512 |
IVFの場合、2つのパラメータを調整することができます。
- nlist – パーティションの粒度を制御します。このパラメータの推奨値は、インデックスに含まれるベクトル数に基づいた関数から得られます。注意すべき点は、Lucene セグメントに対応する Faiss インデックスが存在するということです。シャードごとに複数の Lucene セグメントがあり、OpenSearch のインデックスごとに複数のシャードが存在します。今回の試算では、シャードあたり 100 個のセグメント、シャードが 24 個と仮定したので、Faiss インデックスあたり約 42 万個のベクトル存在することになります。この値をもとに、適切な値を 4096 と推定し、実験ではこれを一定としました。
- nprobes – 検索するときの nlist バケットの数を制御します。値を大きくすると、検索レイテンシーが増加する代わりに、recall が改善します。
PQの場合、2つのパラメータを調整することができます。
- m – ベクトルを分割するパーティションの数を制御します。この値が大きいほど、符号化したベクトルは元のベクトルとより近似したものになりますが、その分メモリ消費量が増えます。
- code_size – サブベクトルを符号化するためのビット数を制御します。この値が大きいほど、符号化したベクトルは元のベクトルにより近似したものになりますが、その分メモリ消費量が増えます。最大値は 8 であるため、全ての実験において 8 で一定としました。
次の表は、私達の方針をまとめたものです。
| Config ID | 最適化戦略 | nprobes | m (num_sub_vectors) |
| ivfpq1 | Optimize for memory and search latency | 8 | 8 |
| ivfpq2 | Optimize for memory and search latency | 16 | 8 |
| ivfpq3 | Balance between latency, memory, and recall | 32 | 16 |
| ivfpq4 | Balance between latency, memory, and recall | 64 | 32 |
| ivfpq5 | Optimize for recall | 128 | 16 |
| ivfpq6 | Optimize for recall | 128 | 32 |
さらに、IVFPQ に使用する学習データの量について理解する必要があります。一般に、Faiss では、k-Means の学習を含むコンポーネントに 30,000から 256,000 の学習用のベクトルを使用することを推奨しています。私達の構成では、k-Means の最大の k は、nlist パラメータの 4096 となります。この式から、推奨される学習用のデータセットサイズは、122,880 から 1,048,576 ベクトルとなるため、私達は 100 万ベクトルとしました。
最後に、インデックスの構成についてですが、シャード数を選択する必要があります。OpenSearch の場合、シャードサイズは 10〜50 GB の間にすることが推奨されています。実験的に、HNSW では 64 シャード、IVFPQ では 42 シャードが適当であると判断しました。どちらのインデックス構成も、レプリカは 1 台で構成されています。
クラスター構成
これらの実験を行うために、OpenSearch のバージョン 1.3 を使用した Amazon OpenSearch Service を使ってクラスターを作成しました。メモリサイズとコストのトレードオフが優れた r5 インスタンスファミリーを使用することにしました。
ノード数は、ノードあたりのアルゴリズムに使用できるメモリ量と、アルゴリズムが必要とするメモリの総量に依存します。より多くのノードとメモリを持てば、一般に性能は向上しますが、今回の実験ではコスト最小にしたいです。ノードあたりの使用可能なメモリ量は、memory_available = (node_memory - jvm_size) * circuit_breaker_limit で計算され、以下のパラメータが設定されています。
- node_memory – インスタンスの合計メモリ。
- jvm_size – OpenSearch の JVM ヒープサイズ。32 GB に設定します。
- circuit_breaker_limit – サーキットブレーカーのためのネイティブメモリ使用量の閾値。0.5 に設定します。
HNSW と IVFPQ では必要なメモリが異なるため、各アルゴリズムに必要なメモリを見積もり、それに応じて必要なノード数を決定します。
HNSW の場合、m = 64 で、前のセクションの計算式で必要な合計のメモリ量は約 2,252 GB となります。したがって、r5.12xlarge (384 GB メモリ) では、memory_available は、176 GB であり、必要なノード数は約 12 であるが、安定性のために 16 に切り上げています。
IVFPQ アルゴリズムは必要とするメモリ量が少ないため、より小さなインスタンスタイプである r5.4xlarge インスタンス (128 GB メモリ) を使用することができます。したがって、アルゴリズムの memory_available は、48 GB となります。推定されるアルゴリズムのメモリ消費量は合計 193 GB、必要なノード数は 4 で、安定性のために 6 に切り上げています。
どちらのクラスターでも、専用のリーダーノードとして、c5.2xlarge インスタンスタイプを使用しています。これにより、クラスターの安定性はより高まります。
AWS Pricing Calculator によると、この特定のユースケースでは、HNSW クラスターの 1 時間あたりのコストは約 75 ドルで、IVFPQ クラスターでは 1 時間あたり約 11 ドルです。これは、結果を比較する際に重要になってきます。
また、これらのベンチマークは、インスタンスの種類とメモリサイズが同等であれば Amazon Elastic Compute Cloud (Amazon EC2) を使用して、カスタムインフラストラクチャで実行できることも留意しておくと良いでしょう。
結果
以下の表は、実験から得られた結果をまとめたものです。
| Test ID | p50 Query latency (ms) | p90 Query latency (ms) | p99 Query latency (ms) | Recall@10 | Native memory consumption (GB) |
| hnsw1 | 9.1 | 11 | 16.9 | 0.84 | 1182 |
| hnsw2 | 11 | 12.1 | 17.8 | 0.93 | 1305 |
| hnsw3 | 23.1 | 27.1 | 32.2 | 0.99 | 1306 |
| hnsw4 | 54.1 | 68.3 | 80.2 | 0.99 | 1555 |
| hnsw5 | 83.4 | 100.6 | 114.7 | 0.99 | 1555 |
| hnsw6 | 103.7 | 131.8 | 151.7 | 0.99 | 2055 |
| Test ID | p50 Query latency (ms) | p90 Query latency (ms) | p99 Query latency (ms) | Recall@10 | Native memory consumption (GB) |
| ivfpq1 | 74.9 | 100.5 | 106.4 | 0.17 | 68 |
| ivfpq2 | 78.5 | 104.6 | 110.2 | 0.18 | 68 |
| ivfpq3 | 87.8 | 107 | 122 | 0.39 | 83 |
| ivfpq4 | 117.2 | 131.1 | 151.8 | 0.61 | 114 |
| ivfpq5 | 128.3 | 174.1 | 195.7 | 0.40 | 83 |
| ivfpq6 | 163 | 196.5 | 228.9 | 0.61 | 114 |
HNSW クラスタは、より多くのリソースを使用することから予想されるように、クエリのレイテンシーが低く、recall が高いです。しかしながら、IVFPQ インデックスでは使用するメモリが大幅に少なくなっています。
HNSW の場合、パラメータを増やすと、実際にレイテンシーを犠牲にして recall が向上します。IVFPQ では、m を増加させることが recall 向上に最も大きな影響を与えます。nprobes を増加させると、recall がわずかに改善されますが、レイテンシーが大幅に増加してしまいます。
結論
この投稿では、OpenSearch において 10 億を超えるデータポイントの規模で近似 k-NN 検索を実行するために使用される様々なアルゴリズムとテクニックを取り上げました。前のベンチマークのセクションで見たように、全てのメトリクスを一度に最適化するアルゴリズムや方法はありません。HNSW、IVF、PQ はそれぞれ、k-NN ワークロードの異なるメトリクスを最適化することができます。使用する k-NN アルゴリズムを選択する際には、まず必要なユースケースを理解し、(近似最近傍検索はどれだけ正確である必要があるか?どのくらい速くなければならないか?予算は?など) そして、それらを満たすようにアルゴリズムの設定を調整します。
私達が使用したベンチマークコードは GitHub で見ることができます。また、近傍 k-NN 検索 の説明に従って、今日から近似 k-NN 検索を始めることもできます。OpenSearch クラスターのマネージドなソリューションをお探しであれば、Amazon OpenSearch Service をチェックしてください。