Amazon Web Services ブログ
スナップショットを使用したSAP HANA データベースの自動化された回復手順を作成する方法
多くのお客様が、クラウドへのSAPの移行を検討しています。それぞれの移行において、すべてのお客様がクラウドにおける適切なアーキテクチャを定義するに違いありません。定義したサービスレベル契約 (SLA)を満たし、実装した手順は運用プロセスを準拠する必要があります。
このブログ記事では、AWSが持つパワーと機能を発揮するためのクラウドネイティブなアプローチについて説明します。クラウド環境で本稼働システムを構築するときに、SAP HANA システムレプリケーション (HSR)、あるいはサードパーティ製のクラスターソフトウェアを利用するのは依然としてごもっともです。とはいえ、私たちは、Amazon EC2 Auto ScalingやAmazon Elastic Block Store (EBS) スナップショットのようなクラウドネイティブな機能を使用した代替アプローチに焦点を当てようと思います。これらの機能を使用して、重要ではないSAPアプリケーション向けに、ネイティブのバックアップ/リストア機能、自動化されたプロセス、低コストを重視したインフラストラクチャを構築しましょう。
高速かつ自動化されたリストアプロセスは、クラウド環境がもたらす新しい特性を提供できます。オンデマンドインスタンスにより、必要になったときにインスタンスを展開することができ、SAPシステムの可用性を向上することができます。自動化されたリストアプロセスに任せることで、パイロットライトのアプローチやホットスタンバイとして実装されたかどうかに関わらず、スタンバイインスタンスのコストを削減できます。さらに、サードパーティ製ソフトウェアの追加ライセンス費用が不要です。
ソリューション概要
SAP HANA データベースのスタンバイリソースがない場合、取り組むのは、複数のアベイラビリティーゾーンにまたがって堅牢で可用性の高いアーキテクチャを実装することです。リージョン内の任意のアベイラビリティーゾーンでリストアプロセスをトリガーできることを確認する必要があります。
Amazon EBS スナップショットは、ここで説明するアーキテクチャの基礎になります。スナップショットは、データベースのサイズに関係なく、高速なバックアッププロセスを提供します。スナップショットは、Amazon Simple Storage Service (S3)に保存され、アベイラビリティーゾーンをまたがって自動的に複製されます。つまり、別のアベイラビリティーゾーン内で、スナップショットから新しいボリュームを作成できるということです。さらに、Amazon EBS スナップショットはデフォルトで増分保存します。最新のスナップショット以降の差分の変更のみが保存されます。復元力のある高可用性アーキテクチャを実装するには、自動化が重要です。何かが失敗した場合に備えて、データベースをリカバリーするすべての手順を自動化する必要があります。
次の図はハイレベルなアーキテクチャを表しています。

Amazon EBS スナップショットとSAP HANA データベースの統合を構成
開始するには、次の変更を加えたSAP HANA on AWSクイックスタートを使用します。
- /backupディレクトリは、デフォルトではEBS st1ボリュームをもとにしています。これをAmazon Elastic File System (Amazon EFS)で提供されるNFS共有の/backup_efsに置き換えましょう。
- SAP HANAの設定を調整する必要があります (パラメータ:
basepath_logbackup、basepath_databackupとbasepath_catalogbackup)。バックアップはAmazon EFSに直接書き込まれ、アベイラビリティーゾーンをまたがって複製されます。これでバックアップ、特にログバックアップが安全に保存されるようになり、障害がアベイラビリティーゾーンに影響を与える場合であっても引き続き利用できます。 - さらに、Amazon EFS 低頻度アクセス (EFS IA)のオプションを有効にします。これにより、7、14、30、60、または90日間アクセスしていないデータが自動的に移動します。最近のAmazon EFS 低頻度アクセスストレージの料金の引き下げにより、標準のAmazon EFSと比較して最大92%のコストを節約できます。SAP HANAのログバックアップデータは、データへのアクセスはリカバリープロセス中にのみ必要なため、EFS IAが最適なユースケースです。
ログのバックアップは/backup_efsに自動的に書き込まれます。デフォルトでは、SAP HANAは15分ごとにログバックアップをトリガーします。この値を小さくして、目標復旧ポイント (RPO)をさらに短くすることもできます。
これで、ログファイルが利用可能になり、複数のアベイラビリティーゾーンにまたがって安全に保存されたので、スナップショットを使用したデータベースの完全バックアップを構成できます。
SAP HANA スナップショット用のスクリプト
スクリプト「aws-sap-hana-snapshot.sh」では、次のコマンドが実装されています。次のコード例を用いて、最も重要なコマンドについて説明します。
- データベースにストレージスナップショットを認識させる必要があるため、SAP HANA バックアップカタログにエントリが必要です。このスナップショット用のスクリプトでは、次のSQLコマンドによってEBSスナップショットが実行される前に自動的にエントリを追加します。
SAP HANA データベースにログオンするために、システムユーザーのパスワードをSAP HANA hdbuserstoreに保存しておきます。
- これでデータベースがストレージスナップショットを認識するようになったので、リストア後にデータベースのロールフォワードが可能になります。EBSボリュームのスナップショットをトリガーするには、複数のEBSボリュームにわたってポイントインタイムでクラッシュ整合性のあるスナップショットを作成するスナップショット機能を使用します。この機能の利点は、複数のボリュームの同期をとるために、ボリュームレベルで手動の入出力 (I/O)のフリーズ処理が必要ないことです。この機能が利用可能になる前は、データボリュームとログボリュームのI/Oフリーズを
dmsetup suspend <lvm-group-name>で実装する必要がありました。次のコードスニペットを使用して、ルートボリュームを除くすべてのボリュームのスナップショットを実行します。 - スナップショットの実行後、SAP HANA バックアップカタログでバックアップを確認します。
もし、SAP HANA バックアップカタログに従ってスナップショットが成功しなかった場合、AWS上のスナップショットは削除されます。
これで、AWSのスナップショットを介したフルバックアップとEFSに書き込まれたログバックアップを使用したバックアッププロセスを確立できました。どちらのストレージ格納先もアベイラビリティーゾーンから独立しており、別のアベイラビリティーゾーンからアクセスできます。そのため、後から別のアベイラビリティーゾーンでAWS Auto Scaling グループと組み合わせてデータベース全体を再作成できます。
AWS Auto Scalingの構成
最小および最大容量を1つのインスタンスで指定したAWS Auto Scaling グループを設定します。Amazon Elastic Compute Cloud (Amazon EC2) インスタンスにハードウェア障害などの問題が起きた場合、AWS Auto Scaling グループが自動的にAmazon Machine Image (AMI)をもとにした新しいインスタンスを作成します。複数のアベイラビリティーゾーンを選択することにより、希望する容量がこれらのアベイラビリティーゾーンに分散されます。
次のセクションでは、自動化されたリストアプロセスについて説明します。
- AMIを作成します。これは、後でAWS Auto Scaling グループで使用されます。
/hana/dataと/hana/logに紐づくすべてのボリュームを削除する必要があります。これらのボリュームは、スナップショットから自動的に再作成されるため、AMIに含めません。

- 起動設定を作成します。

- 起動設定では、先ほど作成したAMIをソースにし、必要なインスタンスサイズを選択します。

- システムクラッシュが起きたときにリストア手順を開始するために、userdata-hana-restore.shスクリプトをAmazon EC2 ユーザーデータに保存し、Amazon EC2 インスタンスの初期起動中に実行されるようにします。最新のスナップショットから新しいボリュームが作成されます。これらの新しいボリュームはAmazon EC2 インスタンスにアタッチされ、データベースログを最新の状態にロールフォワードします。このスクリプトは、高度な詳細にあるユーザーデータ部分に追加します。

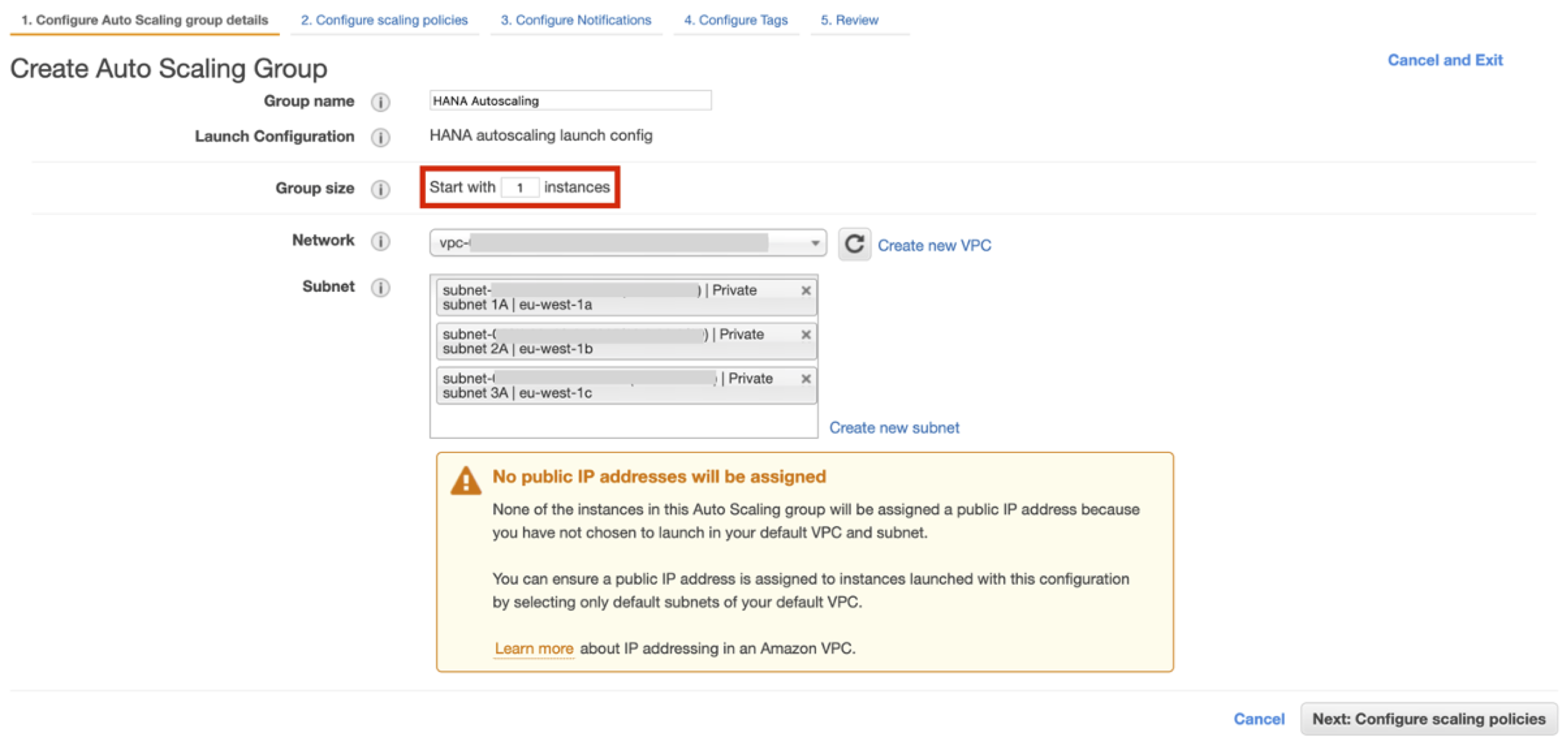
- 起動設定を作成したら、AWS Auto Scaling グループを設定できます。

- グループサイズは1インスタンスです。新しいインスタンスを展開してもいいすべての利用可能なサブネットを選択します。

- グループサイズは初期サイズのままにします。







SAP HANA リストア用のスクリプト
restore.shスクリプトとリストアプロセスの各ステップを詳しく見てみましょう。
前提条件として、AWSパラメータストアに2つのパラメータが必要です。AWS Systems Manager パラメータストアは、SAP HANA データボリュームとログボリュームのためのボリュームIDを記録します。
- コマンドラインインターフェイスでパラメータを作成するには、次のコマンドを使用します。
このステップは、AWSパラメータストアにこのパラメータを作成するための設定の間で、1回だけ必要です。値は、スクリプトによって自動的に後で更新されます。
- 最新のスナップショットから新しいボリュームを作成するために、このスクリプトでは、スナップショットスクリプトとsnapshot-idを使って作成された最新のスナップショットを探します。
リストアプロセスでは、リカバリーするログファイルの数を減らすために、最新のスナップショットを使用する必要があります。AMIはSAP HANA データボリュームとログボリュームなしで作成したため、これらのボリュームはEBSスナップショットから作成する必要があります。
- スナップショットから新しいボリュームを作成します。
ボリュームをインスタンスにアタッチする前に、手順を遅らせてボリュームが利用可能になるまで待つことを推奨します。
- ボリュームをインスタンスにアタッチします。
ここでデータベースを開始すると、スナップショットが取得された時間に基づいて、クラッシュ整合性のある状態になります。データベースを最新の状態にリカバリーするには、EFSに保存されているログファイルを使用できます。AMIは、起動時にEFSファイルシステムを自動的にマウントします。
- SAP HANAを最新の状態までリカバリーするには、ポイントインタイムリカバリーをトリガーする必要があります。これは、リカバリーがスナップショットに基づいており、将来のタイムスタンプを持つことを表しています。
スナップショットスクリプトの前提条件を考慮することが重要です。特に、DBインスタンスの起動後、SAP HANA テナントデータベースの自動起動を無効にします。テナントがオンラインの場合、ログファイルをリカバリーすることはできなくなりました。再起動なしのオプションを使用すれば、テナントの自動起動を防ぐことができます。
非再起動モードを設定するSQLコマンド:
リストア時間は、2つの主な側面に依存します。1) スナップショットから新しいボリュームを作成する時間、2) リカバリーするログファイルの数です。ボリュームの作成は、ボリュームサイズとボリュームタイプによって異なります。Amazon EBS 高速スナップショット復元は、新しく作成されたボリュームを初期化するための時間を短縮することが可能です。データベースのリカバリープロセスは、スナップショットが作成されてからのログファイルの数とデータベースの変更率に依存します。
考慮すべき追加の事項
AWS Auto Scaling グループが新しいインスタンスを作成すると、新しく作成されたインスタンスのIPは変わります。SAPアプリケーションサーバーはこれを認識する必要があります。Amazon Route 53のDNSエントリを変更し、IPを更新することができます。加えて、AWS Auto Scaling グループは別のアベイラビリティーゾーンで新しいインスタンスを起動することもできます。この構成では、アプリケーションサーバーは別のアベイラビリティーゾーンにとどまっているため、レイテンシーが少しだけ高くなるアベイラビリティーゾーン間のトラフィックが発生する可能性があります。
結論
異なるアベイラビリティーゾーンをまたがって最新の状態に自動的にリカバリーするSAP HANAの高可用性アーキテクチャを低コストで実装できます。Amazon EC2 スポットインスタンスは、コストをさらに削減できます。スポットインスタンスが取り消されると、AWS Auto Scalingは重要ではないシステムのデータベースを自動的にリカバリーします。自動化されたリストアプロセスでは、アクティブなスタンバイリソースは必要ありません。さらに高い可用性とのトレードオフや本稼働ワークロードがあり、それらはSAP HANA システムレプリケーションで実現できます。
翻訳はPartner SA 河原が担当しました。原文はこちらです。