Amazon Web Services ブログ
Amazon SageMaker ニューラルトピックモデルのご紹介
構造化データおよび非構造化データは前例のないペースで生成されているため、膨大な量の情報を整理し、検索し、理解するための適切なツールが必要です。こういったデータの有効活用は難しいことです。これは特に非構造化データの場合に当てはまります。企業が持つデータの 80% 以上が構造化されていないと推定されています。 テキスト分析とは、非構造化テキストを意味のあるデータに変換することで事実に基づく意思決定をサポートすることを目的とした分析プロセスです。トピックモデリング、エンティティとキーフレーズの抽出、センチメント分析、および共参照関係の解決など、テキスト分析にはさまざまな技術が使用されています。
それでは、トピックモデリングとは一体何なのでしょうか?
トピックモデリングとは、ドキュメントのコーパスを「トピック」に編成するために使用されます。これは、ドキュメント内の単語の統計的分布に基づくグループ化のことを指します。完全マネージド型のテキストアナリティクスサービスである Amazon Comprehend は、顧客からのフィードバックの整理、インシデントやワークグループ文書のサポートなど一般的なユースケースに最も適した、事前設定済みのトピックモデリング API を提供します。Amazon Comprehend は、トークン化やモデルのトレーニング、パラメータの調整などのトピックモデリングに関連する多くの一般的な手順を取り除くために提案されたトピックモデリングの選択肢です。Amazon SageMaker のニューラルトピックモデル (NTM) は、特定の文体やドメインのテキストコーパス上でのモデルのトレーニングやトピックモデルの Web アプリケーションの一部としてのホスティングなど、細かく制御されたトレーニングや最適化、そしてトピックモデルのホスティングが必要なユースケースに対応しています。Amazon SageMaker NTM は最先端のトピックモデリングの出発点を提供し、それにより顧客はネットワークアーキテクチャやデータセットの特異性に対応するためのハイパーパラメーターの変更、そしてそれらのアプリケーションに基づいた文書モデリングの精度、人間の解釈可能性、および学習されたトピックの粒度などののような多数のメトリックとの間のトレードオフの調整といった柔軟性を手に入れることができます。さらに、Amazon SageMaker NTM は簡単に構成可能なトレーニングおよびホスティングインフラストラクチャ、自動的なハイパーパラメータの最適化、Auto Scaling による完全マネージド型のホスティングなど、Amazon SageMaker プラットフォームのフルパワーを活用しています。
トピックモデリングの技術的定義は、各トピックは単語の分布であり、各文書は一連の文書 (コーパスとも呼ばれる) にわたるトピックの混合物であるということです。たとえば「自転車」、「車」、「マイル」、「ブレーキ」などの単語が頻繁に出現するドキュメントのコレクションは、「輸送」に関するトピックを共有する可能性があります。もしも別のコレクションが「SCSI」、「ポート」、「フロッピー」、「シリアル」などの単語を共有する場合、「コンピュータ」に関するトピックについて議論している可能性があります。トピックモデリングのプロセスとは、すべてのトピックへの単語の分布やトピックの混合分布などの隠れた変数を文書全体のコレクションを観察することにより推測することなのです。次の図は、単語、トピック、およびドキュメントの間の関係性を示しています。
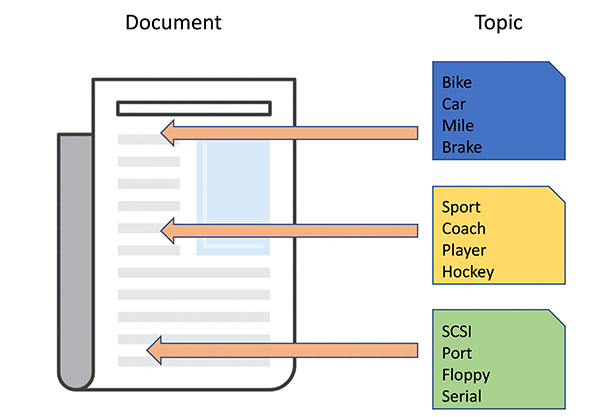
トピックモデリングには、検出されたトピックに基づくドキュメントの分類、トピックにマップされたタグを使用したコンテンツの自動タグ付け、ドキュメント内のトピックを使用したドキュメントの要約、トピックを使用した情報検索、トピックの類似性に基づくコンテンツの推奨などの多くの実践的なユースケースが存在します。トピックモデリングは、ダウンストリームのテキストに関連した機械学習タスクのための機能エンジニアリングステップとしても使用できます。また、トピックモデリングは根底にあるテーマとの一連の観測を記述しようと試みる一般的なアルゴリズムでもあるのです。ここではテキストドキュメントに焦点を当てていますが、この観測は他のタイプのデータにも適用可能です。例えば、トピックモデルはインターネットサービスプロバイダや企業ネットワークのネットワーク上のピアツーピアアプリケーションの発見など、他の離散データユースケースのモデリングにも使用されます。
Amazon SageMaker ニューラルトピックモデル (NTM)
Amazon SageMaker は、Jupyter ノートブックホスティングサービス、拡張性の高い機械学習トレーニングサービス、Web スケールの組み込みアルゴリズム、モデルホスティングサービスを提供するエンドツーエンドの機械学習プラットフォームです。Amazon SageMaker Neural Topic Model (NTM) と Amazon SageMaker Latent Dirichlet Allocation (LDA) の 2 つのトピックモデリングアルゴリズムがビルトイン (ファーストパーティとも呼ばれる) アルゴリズムのリストに含まれています。このブログ記事では、NTM に焦点を当てます。 トピックモデルは、挑戦的な事後推論の問題を含む確率的なグラフィカルモデルの古典的な例です。SageMaker NTM では、ニューラルネットワークベースの変分推論フレームワーク [1] の下でトピックモデリングを実装します。難しい推論問題は、確率的勾配降下のようなスケーラブルな方法によって解決される最適化問題として当てはめられます。従来の推論スキームと比較して、ニューラルネットワークの実装はスケーラブルなモデルトレーニングおよび低レイテンシーの推論を可能にします。さらには神経推論フレームワークの柔軟性により、我々はさらに素早く新しい機能を追加し、より広い範囲の顧客ユースケースに役立てることができます。 アルゴリズムの高レベルアーキテクチャを次の図に示します。

SageMaker NTM はドキュメントの高次元単語数ベクトルを入力として取り込み、それらを低次元の隠れ表現にマップし、元の入力を隠れ表現から再現します。モデルによって学習された隠れた表現は、文書に関連するトピックの混ぜ合された重みに対応します。トピックの意味論的意味は、再構成層によって学習された各トピックのランキング上位の単語によって決定されます。SageMaker NTM のトレーニング目標は、再構成誤謬を最小化することであり、データの負の対数尤度の上限に対応する和である Kullback-Leibler_divergence です。
SageMaker NTM は、大規模なモデルトレーニングのための高度に分散したクラスタ環境でトレーニングされます。これはトレーニングジョブ用、必要なトレーニングチャンネル、オプションの検証およびテストを含むものの 3 つのデータチャンネルをサポートしています。検証チャンネルはトレーニングジョブをいつ停止するかを決定するために使用されます。 各トレーニングノードにはトレーニングおよび検証データを複製または分割するオプションがあり、ストリーミング機能が利用可能な場合にはデータをストリーミングすることもできます。推測時には、SageMaker NTM は CSV または RecordIO-wrapped-Protobuf ファイル形式でデータ入力を受け取ります。
SageMaker NTM はモデルパフォーマンス調整のためのハイパーパラメータのリストをサポートしています。これらのハイパーパラメータを使用して、抽出するトピック数、エポック数、精度とトレーニング時間のトレードオフを微調整する学習率などのノブを設定できます。リスト内のいくつかのハイパーパラメータを次に示します。使用可能なハイパーパラメータの一覧については、NTM ハイパーパラメータを参照してください。
- feature_dim – 機能ディメンションで、ボキャブラリサイズに設定する必要があります
- num_topics – 抽出するトピックの数
- mini_batch_size – 各ワーカーインスタンスのバッチサイズマルチ GPU インスタンスでは、この数はさらに GPU の数で除算されることに注意してください。したがって、たとえば 8-GPU マシン (ml.p2.8xlarge など) でトレーニングを行い、各 GPU にバッチごとに 1024 個のトレーニング例があるようにするには、mini_batch_size を 8196 に設定する必要があります。
- epochs – トレーニングをするエポックの最大数。トレーニングは早期に停止する場合があります
- num_patience_epochs と tolerance は早期停止動作を制御します。大まかに言えば、最後の num_patience_epochs エポックの範囲内で検証の損失が改善されていない場合、アルゴリズムはトレーニングを中止します。「tolerance」より小さい改善は非改善と見なされます。
- optimizer と learning_rate – デフォルトでは adadelta オプティマイザを使用し、learning_rate は設定する必要はありません。他のオプティマイザでは、適切な学習率の選択には実験が必要な場合があります。
モデルトレーニングに SageMaker NTM を使用するには、トレーニングジョブを作成し、データチャネル、ハイパーパラメータ、計算リソースタイプ、および番号を指定します。SageMaker NTM トレーニングジョブを作成するには、複数の方法があります。Amazon SageMaker コンソールを使用してトレーニングジョブを設定および開始することも、Python スクリプトまたは Jupyter ノートブックで SageMaker Python SDK を使用してトレーニングジョブを構成して開始することもできます。また、SageMaker Spark SDK を使用して NTM モデルトレーニングワークフローを Spark パイプライン内に直接統合することもできます。
Amazon SageMaker NTM トレーニングは CPU 上で動作しますが、GPU の計算能力を十分に活用することもできます。大きなデータセットの場合、P2 または P3 インスタンスなどの GPU インスタンスを使用することをお勧めします。
訓練中、Jupyter ノートブック環境でジョブが開始されている場合、Amazon SageMaker はトレーニング統計を Amazon CloudWatch Logs と Jupyter コンソールに出力します。トレーニングの統計には、各トレーニングステップの単語の分布と、モデルを使用するかどうかを決定する際に役立つ、総損失と KL の相違に関する統計情報が含まれています。
監督されていない生成モデルとして、モデルトレーニングの進捗状況を事前に設定されていた期待値と比較するための精度やエラーメトリックは提供していません。モデルトレーニングの進行の主な指標は、上述したデータの負の対数尤度に対応するトレーニング損失である。トレーニングされたモデルが目に見えないデータをどれだけ一般化したか評価するために、NTM をトレーニングする際にはモデルトレーニングの進捗状況を適切に評価できるよう常に検証データセットを提供し、オーバーフィットを避けるために早期停止が有効になっていることをお勧めします。
モデルがいかにうまくデータを記述し再構築するかを測定するトレーニングの損失に加え、テキストのトピックモデリングについても各トピックを代表する上位 N 語は意味論的に意味があり、したがって人間が解釈可能でなければなりません。しかし、解釈可能性というものは評価するのには少々主観的です。人間の専門家なしで計算できる最も広く受け入れられているメトリックは、正規化されたポイントワイズ相互情報 (NPMI) に基づくトピックの一貫性です。NPMI の評価には、大きな外部参照コーパスと集中的な計算が必要です。このメトリックは現在 NTM では利用できません。NTM からの出力に基づいてオフラインで NPMI を計算することに関心があるユーザーについては、[2] を参照してください。
モデルをトレーニングした後、単一の API 呼び出しによる Amazon SageMaker でのモデルのホストも可能です。Amazon SageMaker は Auto Scaling されたクラスタ環境でトレーニングされたモデルの RESTful API エンドポイントを提供し、ホスティングのためのデフォルトの推論機能を提供します。 AWS SDK、AWS CLI、SageMaker Python SDK など、ホストされた NTM SageMaker API エンドポイントを呼び出す方法はいくつかあります。モデルホスティングについては、通常、モデルサービング用の CPU インスタンスから開始するだけで十分です。GPU ベースのインスタンスも、より高いパフォーマンスのために利用可能です。
SageMaker NTM モデル推論の出力は以下のようになります。(入力データには、各文書ごとに個別の予測出力行があります。10 進数は、ドキュメントに割り当てられている各トピックの重みを表します。)

推論の出力形式:「topic_weights」は、各ドキュメントのトピックの強さを表す負ではない数値のリストです。
各トピックの意味論的な意味を判断する場合は、トレーニングジョブの単語ディストリビューションを実際の単語にマッピングできます。トレーニングジョブの CloudWatch ログを開くと、次の図のようなログの末尾にある単語の分布を見つけることができます。この図では各行はトピックを表し、1 つの行の整数はトピックの最上位ワードを表します。その後、整数を元の語彙にマッピングすることによって、実際の言葉をルックアップすることができます。

20NewsGroup データセットを使用したモデルトレーニング
それでは、20NewsGroup データセットを使用した、異なる 20 のニュースグループから集められた 20,000 のメッセージから構成されるモデルをトレーニングしてみましょう。これはトピックモデリングのベンチマークデータセットとして幅広く使われています。このエクササイズでは、SageMaker Jupyter インスタンスを起動するためのステップの実施、SageMaker トレーニングサービスと SageMaker NTM アルゴリズムを使用したトピックモデルのトレーニング、そし SageMaker ホスティングサービスを利用したモデルのホスティングを行います。
SageMaker ノートブックインスタンスをまだ実行していない場合は、ノートブックインスタンスを起動して Jupyter ダッシュボードを起動するために以下の手順に従ってください。
また、Amazon S3 バケットにデータセットとモデルアーティファクトを保存する必要があります。それでは、作成してみましょう。「sagemaker-xx」という S3 バケットを作成します。ここで、「xx」はバケットを区別するためのイニシャルです。 後でノートブックを構築する際には、このバケットが必要です。もしもあなたが S3 バケットを作成する方法に慣れていない場合、こちらの指示に従ってください。
これで、私たちはエクササイズ用の新しい Jupyter ノートブックを作成する準備ができました。開始するには新しいドロップダウンメニューを選択し、「fvconda_mxnet_p36」メニュー項目を選択して空のノートブックを作成します。ノートブックの名前を変更し、識別しやすくします。さらに、以下のセルは Jupyter のノートブックで入手できます。ここでスクラッチから始めるのではなく準備されたノートブックに従うこともできます。
データの準備
データセットの取得
このセクションでは、まずデータセットをダウンロードし解凍します。次に、各文書からテキストコンテンツを抽出します。
20NewsGroup データセットは、このロケーションにある UCI マシンラーニングレポジトリで利用できます。データセットのダウンロードに進む前に、データセットの説明ページから引用した確認、著作権、および利用可能性に関する以下の要件に注意してください。
今度はパッケージを解凍して、20 個の文書フォルダを見てみましょう。
次に、すべてのドキュメントを読み込み、メッセージ本文を文字列のリストとして抽出します。
新しいセルで次のコードを実行し、トレーニングデータセットの内容を簡単に見ていきましょう。
見てみるとわかるように、データセットのエントリーは単なるプレーンテキストパラグラフです。適切なデータ形式に処理する必要があります。
プレーンテキストから語彙 (bag-of-words, BOW) まで、
アルゴリズムへの入力文書は、トレーニングと推論の両方で、単語数を表す整数のベクトルである必要があります。これは、いわゆるバッグオブワード (BOW) 表現です。プレーンテキストを BOW に変換するには、まず文書を「トークン化」する必要があります。つまり、単語を識別し、それぞれに整数 ID を割り当てます。 次に、各文書内の各トークンの出現を数え、BOW ベクトルを形成する。めったに使用されない言葉はモデルに与える影響が非常に小さく無視することができるので、頻繁に使用される 2,000 個のトークン (単語) を保持します。
この例では、シンプルな字句解析を nltk パッケージから使用し、 scikit-learn での CountVectorizer でトークンカウントを実行する。詳細については、ドキュメントをご参照ください。また、spaCy は、使いやすいトークン化機能と字句解析機能も提供します。
次のセルでは、 nltk からトークナイザーと字句解析を使用します。リストの理解に関しては、単純なルールを実装します。2 文字より長く、 token_pattern にマッチする単語だけを考慮します。
定義されたトークナイザを使用して、ボキャブラリサイズを vocab_size へ限定している間にトークンカウントを次へとカウントします。
オプションで、非常に短い文書を削除することを検討することもできます。次のセルは、25 語未満の文書を削除します。これは確かにアプリケーションに依存するものですが、いくつかの正当性もあります。複数のトピックを表現する非常に短いドキュメントを想像するのは難しいです。トピックモデリングでは、各ドキュメントを複数のトピックが混在するようにモデル化します。ですので、短いドキュメントのモデリングには最適ではありません。
NTM モデルのすべてのパラメータ (重みとバイアス) は np.float32 タイプなので、入力するデータも np.float32 にする必要があります。ミニバッチのトレーニング中に繰り返しキャスティングを行うのではなく、このタイプキャスティングを先に行う方がよいでしょう。
モデリングのトレーニングの一般的な実践として、トレーニングセット、検証セット、テストセットが必要です。トレーニングセットは、モデルが実際にトレーニングをされている一連のデータです。しかし私たちが本当に気にしているのは、トレーニングセットのモデルのパフォーマンスではなく、まだ見ぬの将来のデータに対するパフォーマンスです。したがってトレーニング中に、目に見えないデータのモデルのパフォーマンスを検証するために検証セットのスコア (または損失) を定期的に計算します。モデルの一般化能力を評価することにより、過度のトレーニングを避けるために、早期停止によって最適な点で訓練を停止することができます。
トレーニングセットしかなく妥当性検証セットがない場合、NTM モデルはトレーニングセットのスコアに依存して早期停止を実行するため、オーバートレーニングが発生する可能性があります。したがって、常にモデルに検証セットを提供しておくことをお勧めします。
ここでは、データセットの 80% をトレーニングセットとして使用し、残りを検証セットとテストセットに使用します。トレーニングで検証セットを使用し、モデルの推論を実証するためにテストセットを使用します。
Amazon S3 にデータを保存する
まずデータの場所とアクセスの役割を指定する必要があります。これはあなたが編集しなければならないであろうノートブックの唯一のセルです。特に、以下のデータが必要です。
- トレーニングとモデルデータに使用する S3 バケットとプレフィックス。これは、ノートブックインスタンス、トレーニング、およびホスティングと同じ領域内にある必要があります。
- IAM の役割は、データに対するトレーニングとホスティングのアクセスを提供するために使用されます。これらを作成する方法については、ドキュメントをご参照ください。
NTM アルゴリズムおよび他のファーストパーティ SageMaker アルゴリズムは、RecordIO Protobuf 形式のデータを受け入れます。SageMaker Python API は、データを簡単にこの形式に変換するためのヘルパー関数を提供します。ここでは、データを RecordIO Protobuf 形式に変換し、Amazon S3 にアップロードするヘルパー関数を定義します。加えて、 n_parts によって指定されたデータを複数部分へと分割するオプションが用意されています。
このアルゴリズムは本質的にトレーニングフォルダ (「チャンネル」) 内の複数のファイルをサポートしており、大きなデータセットに非常に役立つ可能性があります。さらに、複数のワーカー (計算インスタンス) で分散トレーニングを使用する場合、複数のファイルを使用することで、異なる従業員に便利にトレーニングデータの異なる部分を配布することができます。
このヘルパー関数の中で、SageMaker Python SDK が提供する write_spmatrix_to_sparse_tensor 関数を使用して、scipy の疎行列を RecordIO Protobuf 形式に変換します。
モデルトレーニング
トレーニングと検証のデータセットを作成し、Amazon S3 にアップロードしました。次に、準備したデータに対して NTM アルゴリズムを使用する Amazon SageMaker トレーニングジョブを設定します
Amazon SageMaker は Amazon Elastic Container Registry (ECR) Docker コンテナを使用し、NTM トレーニングイメージをホストします。次の Amazon ECR コンテナは、現在 SageMaker NTM トレーニングでさまざまな地域において利用可能です。最新の Docker コンテナレジストリについては、Amazon SageMaker: 共通パラメータをご参照ください。
以下のセルのコードは、現在のリージョンに基づいて自動的にアルゴリズムコンテナを選択します。sagemaker.estimator.Estimator の API 呼び出しでは、トレーニングジョブのインスタンスのタイプとカウントも指定します。20NewsGroups のデータセットは比較的小さいため、CPU のみのインスタンス (ml.c4.xlarge) を選択しましたが、他のインスタンスタイプに変更することは自由です: https://aws.amazon.com/sagemaker/pricing/instance-types/。NTM は GPU ハードウェアをフルに活用し、一般的には GPU では CPU よりも約 1 桁高速です。マルチ GPU またはマルチインスタンストレーニングは、通信オーバーヘッドが計算時間に比べて低い場合、トレーニング速度をほぼ直線的に改善します。
次に、NTM 固有のハイパーパラメータを指定します。これらのハイパーパラメータの意味については、前のセクションの説明をご参照ください。
次に、トレーニング中にトレーニングデータと検証データをどのように作業者に配布するかを指定する必要があります。データチャネルには 2 つのモードがあります:
FullyReplicated: すべてのデータファイルがすべての作業者にコピーされます。ShardedByS3Key: データファイルは異なる作業者に分割されます。つまり、各ワーカーは完全なデータセットの異なる部分を受け取ります。
執筆時点では、Python SDK はデフォルトですべてのデータチャンネルで FullyReplicated モードを利用します。これは検証 (テスト) チャネルには望ましいのですが、複数の作業者を使用する場合はトレーニングチャネルにとって効率的ではありません。我々は各作業者にエポック内の異なる勾配を提供するために、完全なデータセットの異なる部分を通過させたいのです。我々 distribution を ShardedByS3Key に以下のようにトレーニングデータチャンネル用に指定します。
これでトレーニングの準備が整いました。以下のセルは実行に数分かかります。以下のコマンドは、最初に必要なハードウェアを供給します。ハードウェアプロビジョニングプロセスの進行状況を示す一連のドットが表示されます。リソースが割り当てられたら、トレーニングログが表示されます。複数の作業者の場合、ログカラーと「INFO」に続く ID は、異なる作業者によって生成されたログを識別します。
以下のように表示された場合
出力ログの最後には、トレーニングが正常に完了し、出力 NTM モデルが指定された出力パスに格納されたことを意味します。また、Amazon SageMaker コンソールを使用して、トレーニングジョブのステータスに関する情報を表示することもできます。
モデルホスティングと推論
トレーニングされた NTM モデルはそれ自体で何もしません。データの推論を行うために計算したモデルを使用したいと考えています。この例では、与えられたドキュメントを表すトピックの混合を予測することを意味します。SageMaker Python SDK を使用して推論のエンドポイントを作成します deploy() 先に定義したジョブの関数です。推論が計算されるインスタンスタイプと、スピンアップするインスタンスの初期数を指定します。
デプロイメントが完了したら次のコードを実行してテストデータを準備し、推論のエンドポイントを呼び出します。 さまざまな形式のデータを推論のエンドポイントに渡すことができます。ここでは、CSV 形式のデータを渡す方法を示します。推論エンドポイントを設定し、推論のためにテストデータセットから 5 つのドキュメントを渡すときに、SageMaker Python SDK ユーティリティ csv_serialize と json_deserializer を使用します。
予測の可視化
予測結果を表示するより直感的な方法は、5 つのサンプルテストデータのトピック割り当てを視覚化することです。新しいセルで次のコードを実行して、20 のトピックのトピック割り当ての棒グラフをプロットします。
出力例は以下のようになります。

エンドポイントの削除
追加のホスティングコストを避けるためにエンドポイントを維持したくない場合は、以下のコードを実行することでエンドポイントを削除し、エンドポイントをバックする EC2 インスタンスを終了できます。
まとめ
おめでとうございます! SageMaker NTM アルゴリズムを使用してトピックモデルを習得しました。この演習では、SageMaker NTM アルゴリズム用の 20NewsGroup データセットを準備する方法を学び、Amazon SageMaker トレーニングサービスを使用してモデルをトレーニングしました。また、Amazon SageMaker ホスティングサービスを使用してモデルをデプロイすることも学び、エンドポイントに対してリアルタイム推論を行いました。
完全なノートブックをダウンロードできます。このノートにはトレーニングされたモデルを調査するための追加の手順とサンプルコードが含まれています。また、いくつかのサンプルトピックを、各トピックの下に表示される単語の確率に比例した単語サイズでワードクラウド (以下のスクリーンショット参照) として視覚化するためのコードもあります。

Amazon SageMaker と Neural Topic Model をもっと大きなデータセットでどのように使用できるかを見てみたい場合は、このウェビナーをご覧ください。 Amazon EMR とAmazon SageMaker をどのように統合すれば 550 万件以上も記事を持つ英文ウィキペディア全体を処理することができるかが説明されています。また、4 NVIDIA Tesla V100 GPUs を装備した 16 ml.p3.8xlarge インスタンスのスケールでいかにしてモデルがトレーニングされるかについても習得することができます。
リファレンス
[1] Yishu Miao, Edward Grefenstette, and Phil Blunsom. Discovering discrete latent topics with neural variational inference. In International Conference on Machine Learning, 2410 ページ
[2] Jey Han Lau, D avid Newman, and Timothy Baldwin. Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, 530 ページ
今回のブログ投稿者について
 David Ping は AWS ソリューションアーキテクチャオーガナイゼーションのプリンシパルソリューションアーキテクトです。彼は AWS を使用したクラウドと機械の学習ソリューションを構築するためにお客様と協力しています。彼はニューヨークのメトロエリアに住み、最新の機械学習技術の習得を楽しんでいます。
David Ping は AWS ソリューションアーキテクチャオーガナイゼーションのプリンシパルソリューションアーキテクトです。彼は AWS を使用したクラウドと機械の学習ソリューションを構築するためにお客様と協力しています。彼はニューヨークのメトロエリアに住み、最新の機械学習技術の習得を楽しんでいます。
 Ran Ding は AWS AI アルゴリズムチームのアプライドサイエンティストで、Amazon SageMaker の機械学習アルゴリズムを研究、開発しています。Amazon 以前はワシントン大学で電気工学の博士号を取得し、光学プロセッサーを製造するスタートアップ企業で働いていました。
Ran Ding は AWS AI アルゴリズムチームのアプライドサイエンティストで、Amazon SageMaker の機械学習アルゴリズムを研究、開発しています。Amazon 以前はワシントン大学で電気工学の博士号を取得し、光学プロセッサーを製造するスタートアップ企業で働いていました。
 Ramesh Nallapati は、AWS AI SageMaker チームのシニアアプライドサイエンティストです。彼は主に自然言語処理ドメインで規模の大きい画期的なディープニューラルネットワークを構築することに取り組んでいます。彼はディープラーニングに非常に情熱的で、AI の最新動向を学び、この分野に力を入れて貢献することに興奮しています。
Ramesh Nallapati は、AWS AI SageMaker チームのシニアアプライドサイエンティストです。彼は主に自然言語処理ドメインで規模の大きい画期的なディープニューラルネットワークを構築することに取り組んでいます。彼はディープラーニングに非常に情熱的で、AI の最新動向を学び、この分野に力を入れて貢献することに興奮しています。
 Julio Delgado Mangas は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの AWS サービスに貢献しました。Amazon に合流する以前は、研究エンジニアとして人間の脳に関するプロジェクトに携わっていました。
Julio Delgado Mangas は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの AWS サービスに貢献しました。Amazon に合流する以前は、研究エンジニアとして人間の脳に関するプロジェクトに携わっていました。
 Bing Xiang は AWS AI のプリンシパルサイエンティストおよびマネージャーです。彼は、AWS サービスのディープラーニング、機械学習、および自然言語処理に取り組んでいる科学者とエンジニアのチームをいくつか率いています。Amazon に入社する前は、IBM Watson の主任研究スタッフメンバーおよびマネージャーでした。
Bing Xiang は AWS AI のプリンシパルサイエンティストおよびマネージャーです。彼は、AWS サービスのディープラーニング、機械学習、および自然言語処理に取り組んでいる科学者とエンジニアのチームをいくつか率いています。Amazon に入社する前は、IBM Watson の主任研究スタッフメンバーおよびマネージャーでした。