Amazon Web Services ブログ
AWS IoT AnalyticsがGAに
今日は、うれしいお知らせがあります。2018 年 4 月 24 日より、AWS IoT Analytics サービスが一般でご利用いただけるようになりました。接続済みデバイスデータに対し、スケールに合わせてクリーン、処理、強化、保存、分析などを行うことができるようになります。AWS IoT Analytics は、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ) および欧州 (アイルランド) で今すぐご利用いただけます。昨年の 11 月、同僚の Tara Walker が AWS IoT Analytics サービスの機能の一部について珠玉のブログ記事を書き、 Ben Kehoe (AWS コミュニティのヒーローであり、iRobot のリサーチサイエンティスト) が AWS re:Invent にて、柔軟な検索クラスターにデータを送信するために、iRobot の従来からある「変に手の込んだ機械」を AWS IoT Analytics に置き換える方法について講演を行いました。
サービスプレビューの期間中お客様から受け取ったフィードバックを振り返りながら、AWS IoT Analytics チームは BatchPutMessage API を使用して外部のソースからデータを取得する機能や SampleChannelData API を使って既存のデータ、プレビューパイプラインの結果、機械からのプレビューメッセージを処理する機能など、いくつもの新機能を追加しました。
それでは IoT Analytics の主要なコンセプトについて見直して、その後、サンプルを見ていきましょう。
AWS IoT Analytics のコンセプト
AWS IoT Analytics は簡単なコンセプトに分類できます。データ準備をご利用のお客様の場合: チャンネル、パイプライン、データストアが利用できる。データ分析のお客様の場合: データセットとノートブックが利用できる。
データ準備
- チャンネルとは IoT Analytics のエントリポイントであり、既存の IoT Core MQTT トピック、または、Ingestion API を使用してチャンネルにメッセージを送信する外部ソースからデータを収集します。 チャンネルは伸縮自在にスケールし、バイナリ形式か JSON 形式のメッセージを使用します。また、チャンネルは、変更が必要であれば異なるロジックを使用して簡単に再処理を行えるようにするために、変更を加えずに未加工のデバイスデータを保存します。
- パイプラインはチャンネルからのメッセージを使用し、ユーザーがステップに従ってメッセージを処理できるようにします。このステップのことをアクティビティと呼び、たとえば、属性のフィルタリング、フィールドの追加または削除によるメッセージのコンテンツの変換、複雑な変換のための lambda 関数の呼び出し、外部データソースからのデータの追加のほか、IoT Core からのデータを使用したメッセージの強化も実行できます。パイプラインはそのデータをデータストアに出力します。
- データストアはご使用のパイプラインの出力用にクエリ実行可能な IoT 向けに最適化されたデータストレージソリューションです。データストアはコストを最適化するためのカスタム保存期間をサポートします。お客様がデータストアにクエリを行うと、その結果がデータセットに出力されます。
データ分析
- データセットは SQL データベースのビューに似ています。お客様はデータストアに対しクエリを実行してデータセットを作成します。 データセットは手動でも、繰り返しスケジュールを作成して生成することも可能です。
- ノートブックは Amazon SageMaker でホストされている Jupyter ノートブックで、お客様はカスタムコードを使ってそのデータを分析できるほか、データ上に ML モデル構築しトレーニングすることさえも可能です。IoT Analytics では事前作成された一般的 IoT ユースケース向けに、Predictive Maintenance、Anomaly Detection、Fleet Segmentation、 Forecasting といった、複数のノートブックテンプレートを提供しています。
さらに、データ可視化を促進するために Amazon QuickSight 用のデータソースとして IoT 分析を使用することもできます。これらの各サービスの料金情報については、AWS IoT Analytics の料金ページをご覧ください。
IoT Analytics のプレビュー
このプレビューではコンソールを使用していますが、ここでご紹介する内容はすべて CLI でも等しく簡単に実行できます。初めてコンソールでナビゲーションを行うときには、チャンネル、パイプライン、データストアを構築する方法を教えてくれる便利なガイド機能が搭載されています。

最初のステップはチャンネルの作成です。IoT コアを使って MQTT チャンネルにいくつかのデータを作成しておきました。ここではそのチャンネルを選択します。チャンネルに名前を付け、保存期間を選択します。

ここでは自分の IoT Core トピックを選択してデータを取得します。PutMessages API を使用して直接チャンネルにメッセージを投稿することもできます。

これでチャンネルができたので、次のステップはパイプラインの作成です。これを実行するために、[Actions] (アクション) ドロップダウンから、[Create a pipeline from this channel] (このチャンネルからパイプラインを作成する) を選択します。

次に、パイプラインウィザードを見ていきましょう。ここでは自分のパイプラインに名前を付け、ソースを指定します。

パイプラインで想定されるメッセージ属性を選択します。これはサンプリング API を使用してチャンネルから抽出し、どの属性が必要になるか予想するか、JSON に仕様書をアップロードすることもできます。

次に、パイプラインアクティビティを定義します。バイナリデータを取り扱うのであれば、JSON 形式にメッセージを非直列化するために lambda 関数が必要になります。そうすることで、他のフィルター関数がそれを処理できるようになります。フィルターを作成し、他の属性に応じて属性を計算し、さらに IoT コアレジストリのメタデータでメッセージを強化できます。

ここではいくつかのメッセージをフィルタリングしたいだけなので、Lambda 関数でちょっとした変換を行います。

最後に、パイプラインの結果を出力するためのデータストアを選択するか、作成します。
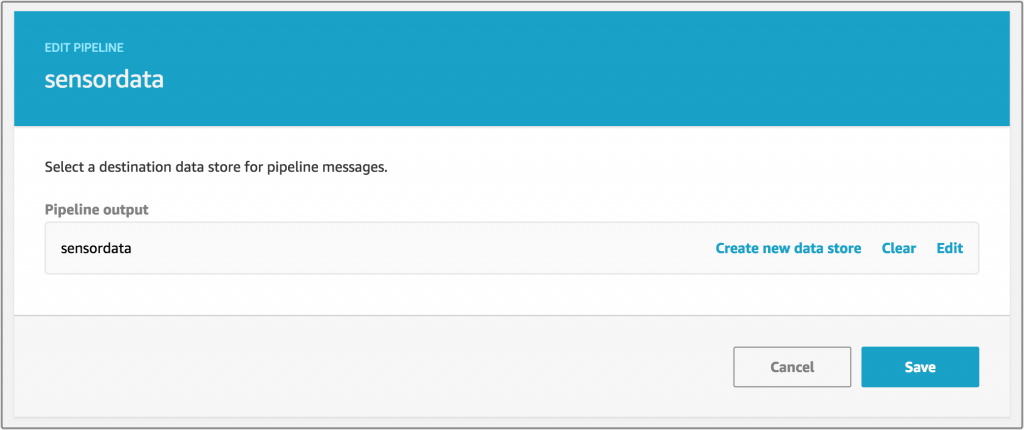
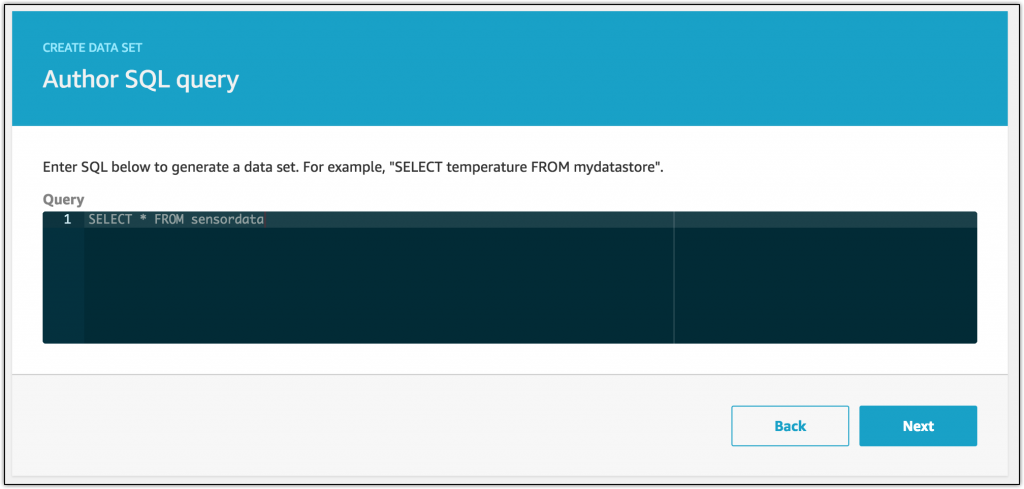
次に、データストアができたら、データセットを作成して、そのデータのビューを作りましょう。

このデータセット用にデータストアから全データを選択するものの、必要に応じて個々の属性を選択することもできます。
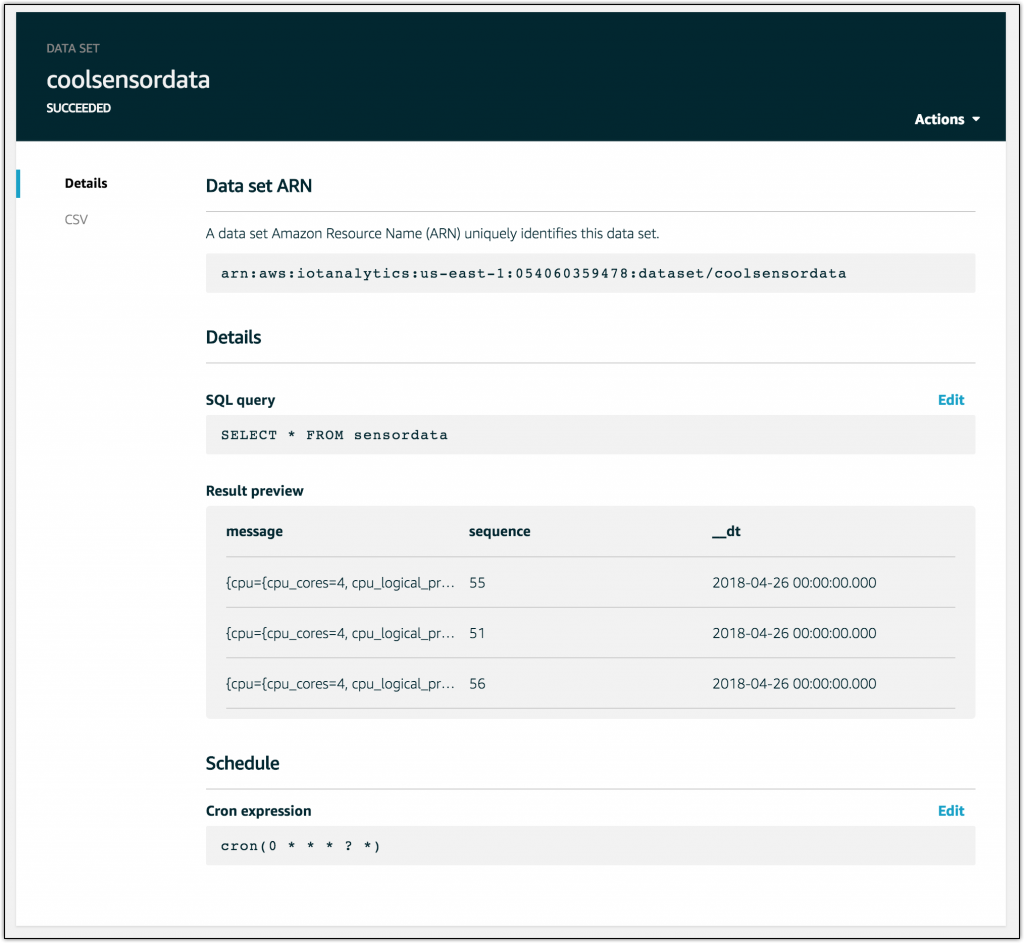
データセットができました。スケジュールのクロン式を調整して、自分の好みの頻度でこれを再実行することができます。
自分のデータからモデルを作るのであれば、SageMaker 対応 Jupyter ノートブックを作成できます。異常検出や出力予測といった、スタートポイントとして最適のテンプレートもいくつかあります。
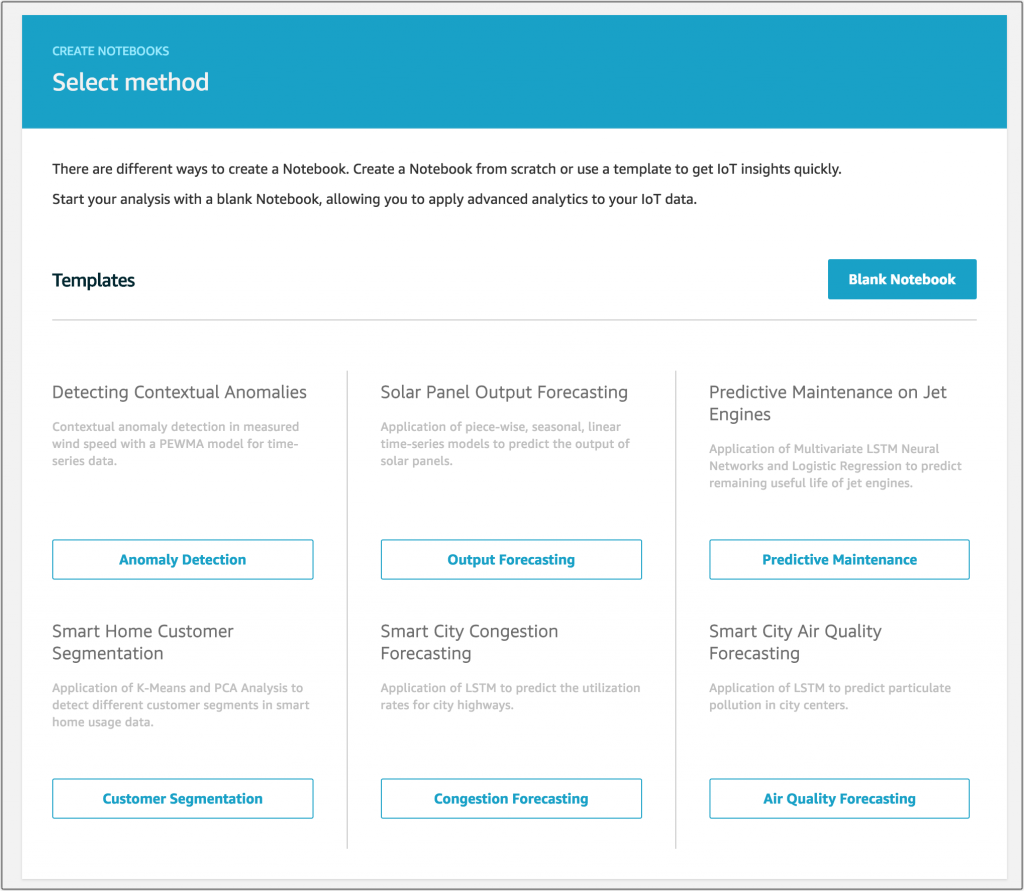
ここでは異常検出ノートブックのサンプルを参照できます。

最後に、自分のデータをシンプルに視覚化するのであれば、QuickSight を使用して、IoT Analytics データセットに移行することもできます。

ご意見をお待ちしています。
AWS IoT Analytics で皆さんがどのようなものを造るかぜひお聞かせください。IoT チームのメンバーはこのサービスに関する皆さんからのご意見をお待ちしています。コメントでも Twitter でもこんな機能があればなど、皆さんのご意見をお聞かせください。
– Randall