Amazon Web Services ブログ
Amazon Forecastを用いた半導体新製品と既存製品の販売予測
本記事は、Predicting new and existing product sales in semiconductors using Amazon Forecast を翻訳したものです。
NXP セミコンダクターズ N.V. と AWS Machine Learning Solutions Lab (MLSL) が共同で執筆しました。
機械学習 (ML) はデータから実用的な洞察を得てプロセスを合理化し収益を向上させるために、幅広い業界で活用されています。この記事では、半導体業界の業界リーダー NXP が AWS Machine Learning Solutions Lab (MLSL) と連携し機械学習技術を活用して NXP の研究開発 (R&D) 予算の配分を最適化し長期的な投資収益率 (ROI) を最大化した事例を紹介します。
NXP は伸び代の大きいと目される新しい半導体ソリューションの開発に多くの力を注いでいます。市場の成長を上回るために、NXP は研究開発に投資し急成長する大規模セグメントに重点をおくことで市場におけるリーディングポジションを創出し、そして拡大しています。今回の取り組みでは、さまざまな材料グループとビジネスラインにわたる新製品と既存製品の月次販売予測を作成することが求められました。この記事では、MLSL と NXP が、NXP のさまざまな製品の長期販売予測に Amazon Forecast やその他のカスタムモデルの適用方法について紹介します。
“ 私たちは、Amazon Machine Learning Solutions Lab の技術者と専門家のチームと協力して、新製品の売上を予測するソリューションを構築し、研究開発費を最適化するための意思決定プロセスにおいてどのような追加機能が役立つかを考察しました。数週間のうちに、チームはいくつかのビジネスライン、製品グループ、および個々の製品レベルにおいて、複数のソリューションと分析手法を開発しました。MLSL には、現在の手作業による予測を補完する売上予測モデルの提供と、 Amazon Forecast と Amazon SageMaker を使用した新しい機械学習アプローチで製品ライフサイクルのモデル化で支援いただきました。また、 私たちのチームと常に協力的なワークストリームを維持しながら、AWS インフラストラクチャを使用した ML 開発に関する技術的な卓越性とベストプラクティスに関して私たちの専門家のスキルアップ支援もいただきました。”
ー Bart Zeeman, NXP セミコンダクターズ社 CTO オフィス ストラテジスト兼アナリスト
目的とユースケース
NXP と MLSL チームの間では、さまざまなエンドマーケットにおける NXP の全体的な売上を予測することが目的として定められています。一般に、NXP チームは複数の製品グループを含むさまざまなビジネスラインの販売が考慮されたマクロレベルの販売に関心があります。さらに、NXPチームは新たに展開された商品の製品ライフサイクルを予測することにも関心がありました。製品のライフサイクルは4つのフェーズ(初期、成長期、成熟期、衰退期)に分けられます。製品ライフサイクルの予測ができるようになると、NXP チームは各製品が生み出す収益を特定し、最も売上高の高い製品、または研究開発活動の ROI を最大化する可能性の高い製品にさらに研究開発資金を割り当てることができます。さらにミクロなレベルで長期間の売上を予測できるようになると、時間の経過とともに収益がどう変化するかをボトムアップで分析することができます。
これ以降のセクションでは、長期的な売上予測のために堅牢で効率的なモデルの開発に関連する主要な課題を提示します。さらに期待された精度を達成するために検討されたさまざまなモデリング手法の背後にある考えを説明します。そして、NXP のマーケットの専門家による売上予測に関して提示されたモデルとパフォーマンスを比較し、最終的なモデルの評価を示します。また最先端の点群ベースの製品ライフサイクル予測アルゴリズムの性能も実証します。
課題
各製品レベルのような細かいミクロレベルのモデリングを用いて売上を予測するにあたり、販売データの欠損が大きな課題の1つでした。このデータの欠損は各月の販売データの欠損に起因します。同様に、マクロレベルの売上予測では、保持する過去の販売データの期間が限られていました。販売データの欠損と過去データの期間の制約は、2026年までの長期的な売上を予測する際のモデルの精度に大きな影響を与えます。探索的データ分析 (EDA) では、ミクロレベルの売上(製品レベル)からマクロレベルの売上(ビジネスラインレベル)に移行するにつれて、欠損値の影響が小さくなることが確認されました。しかし、過去の販売データの長さが最大140ヶ月であるため、モデルの精度という点では依然として大きな課題がありました。
モデリング技術
探索的データ分析ののちに、NXP にとって最大のエンドマーケットの1つ (自動車エンドマーケット) のビジネスライン、製品グループレベルと製品レベルでの予測に注力しました。ただ、私たちが開発したソリューションは他のエンドマーケットにも拡大できます。ビジネスライン、製品グループレベルと各製品レベルでのモデリングにはそれぞれモデルの精度とデータの取得しやすさに関してメリット、デメリットが存在します。下のテーブルでは、各レベルにおけるメリット、デメリットをまとめています。マクロレベルでの売上予測では、最終的に Amazon Forecast の AutoPredictor を活用しました。同様にミクロレベルでの売上予測では新たな点群ベースのアプローチを開発しました。

マクロ売上予測(トップダウン)
マクロレベルで2026年の長期の売り上げを予測するために、私たちは Amazon Forecast、GluonTS、N-BEATS(GluonTSとPyTorchで実装)を含む複数の方法で検証しました。全体的に、Amazon Forecast はバックテスト手法(この記事の評価メトリクスセクションにて記載)において他のすべての予測を上回りました。私たちは AutoPredictor の予測精度を人手による予測とも比較しました。
私たちは解釈しやすいという特性から N-BEATS の利用も提案しました。N-BEATS は、予測に残差ブロックを積み重ねた残差コネクションを採用したフィードフォワードネットワークのアンサンブルを使用する、非常にシンプルで強力なアーキテクチャをベースにしています。このアーキテクチャには、さらに誘導バイアスが内包されていて、トレンドや季節性を抽出できる時系列モデルとなっています(下図参照)。これらは、PyTorch Forecasting を使用して生成されました。
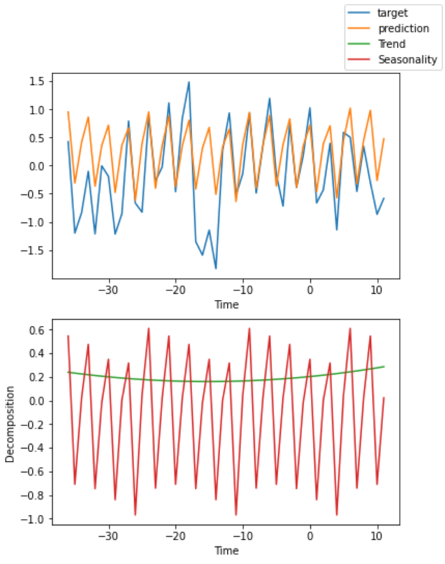
ミクロ売上予測(ボトムアップ)
このセクションでは、コールドスタートプロダクトを検討する中で新たに開発され、下図に示される製品のライフサイクルを予測する手法について議論します。これは PyTorch を使用して Amazon SageMaker Studio 上に構築されました。まず、点群ベースでの方法を紹介します。この方法は売上データを点群に変換し、各点はその製品のある時点における販売数を表します。点群ベースのニューラルネットワークモデルは製品のライフサイクル曲線(下図参照)のパラメータを学習するためにこのデータを使用して追加でトレーニングされます。このアプローチでは、製品ライフサイクルカーブを予測するためのコールドスタート問題に取り組むために製品説明を Bag of Words として含むなど追加機能も盛り込みました。
点群ベースの時系列製品ライフサイクル予測
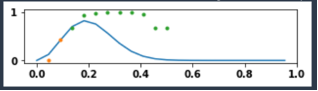
私たちは、製品のライフサイクルとミクロなレベルでの売り上げを予測するために点群ベースの新たなアプローチを開発しました。コールドスタートの製品ライフサイクル予測のモデル精度をさらに改善するために追加の機能実装も行いました。これらの機能は、製品製造コンセプトや関連するその他の関連カテゴリ情報などが含まれます。このような追加データは、製品が市場に投入される前であっても、モデルが新製品の売上を予測するのに役立ちます(コールドスタート)。下図は点群ベースの手法を示しています。モデルには正規化された売り上げの数と市場に投入されての経過期間を入力として渡します。これらの入力に基づいて、モデルは勾配降下法でパラメータを学習します。予測段階では、コールドスタート製品の特徴に沿ったパラメータを使用して、ライフサイクルを予測します。製品レベルで多数の欠損値がある場合には、ほとんどすべての既存の時系列モデルに対しては悪影響を与えます。この新たなソリューションはライフサイクルモデルのアイデアをもとに時系列を点群として扱っているので欠損値の影響を軽減します。

下図はどのように点群ベースのライフサイクル手法が欠損値の問題を解決しほとんどトレーニングサンプルのない製品ライフサイクルの予測ができるようになったかを示します。X 軸は、市場に投入された時間を、Y 軸は製品の販売数を表します。オレンジの点はトレーニングサンプルを表し、緑の点はテストサンプルを表し、青い線はモデルによって予測された製品のライフサイクルを示します。

方法論
マクロレベルの売上を予測するために、Amazon Forecast などの手法を用いました。同様に、ミクロな売上には最先端の点群ベースの独自モデルを開発しました。Forecast はモデルの精度のおいて他の手法よりも優れた結果を示しました。Amazon Simple Storage Service (Amazon S3)からトレーニングサンプルを取得するデータの処理パイプラインを作成するために SageMaker notebook instance を使用しました。さらに、このトレーニングデータを Forecast のインプットとして、モデルをトレーニングし長期的な売上を予測しました。
Amazon Forecast を使用した時系列モデルのトレーニングは主に 3 つのステップから構成されます。最初は、Amazon S3 から履歴データをインポートします。次に、履歴データを用いて予測子をトレーニングします。最後に、予測を生成するトレーニング済みの予測子をデプロイします。このセクションでは、各ステップのコードスニペットとともに詳細に説明します。
最新の売上データを取得することから始めます。このステップでは、正しいフォーマットでAmazon S3 にデータセットをアップロードします。Amazon Forecast には入力として3つの列 : timestamp、item_id、target_value (売上データ) が用意されます。timestamp 列には、時間単位や日単位などで形式を整えられる売上の日時が入ります。item_id 列には販売商品の名前を、target_value には、売上の数が記載されます。次に、Amazon S3 の中に置かれたトレーニングデータのパス、時系列データの頻度 (H、D、W、M、Y)、データセットの名前、データセットの属性を指定します(データセットの各列とデータタイプのマッピング)。続いて、Boto3 API から create_dataset 関数を呼び出し、Domain、DatasetType、DatasetName、DatasetFrequency、Schema などの属性を持つデータセットを作成しました。この関数は Amazon Resource Name (ARN) を含む JSON オブジェクトを返します。この ARN は後続のステップで使用されます。下記コード :
dataset_path = "PATH_OF_DATASET_IN_S3"
DATASET_FREQUENCY = "M" # Frequency of dataset (H, D, W, M, Y)
TS_DATASET_NAME = "NAME_OF_THE_DATASET"
TS_SCHEMA = {
"Attributes":[
{
"AttributeName":"item_id",
"AttributeType":"string"
},
{
"AttributeName":"timestamp",
"AttributeType":"timestamp"
},
{
"AttributeName":"target_value",
"AttributeType":"float"
}
]
}
create_dataset_response = forecast.create_dataset(Domain="CUSTOM",
DatasetType='TARGET_TIME_SERIES',
DatasetName=TS_DATASET_NAME,
DataFrequency=DATASET_FREQUENCY,
Schema=TS_SCHEMA)
ts_dataset_arn = create_dataset_response['DatasetArn']
データセットが作成されると Boto3 の create_dataset_import_job 関数を利用して Forecast にインポートされます。その create_dataset_import_job 関数には、ジョブの名前(文字列)、前のステップで作成されたデータセットの ARN 、Amazon S3 におかれたトレーニングデータの場所、タイムスタンプのフォーマットを引数として渡します。それは、インポートジョブの ARN を含む JSON オブジェクトが返されます。下記コード :
TIMESTAMP_FORMAT = "yyyy-MM-dd"
TS_IMPORT_JOB_NAME = "SALES_DATA_IMPORT_JOB_NAME"
ts_dataset_import_job_response = \
forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME,
DatasetArn=ts_dataset_arn,
DataSource= {
"S3Config" : {
"Path": ts_s3_path,
"RoleArn": role_arn
}
},
TimestampFormat=TIMESTAMP_FORMAT,
TimeZone = TIMEZONE)
ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']そしてインポートしたデータセットを使って、create_dataset_group 関数を用いてデータセットグループを作成しました。この関数は、ドメイン (予測のドメインを定義する文字列)、データセットグループ名、データセット ARN を入力として受け取ります。下記コード :
DATASET_GROUP_NAME = "SALES_DATA_GROUP_NAME"
DATASET_ARNS = [ts_dataset_arn]
create_dataset_group_response = \
forecast.create_dataset_group(Domain="CUSTOM",
DatasetGroupName=DATASET_GROUP_NAME,
DatasetArns=DATASET_ARNS)
dataset_group_arn = create_dataset_group_response['DatasetGroupArn']
次に、予測モデルをトレーニングさせるためにデータセットグループを使用します。Amazon Forecast では、さまざまな最先端のモデルを提供します ; トレーニングにはどのモデルも使うことができます。デフォルトのモデルには AutoPredictor が使用されます。AutoPredictor を使用することの主なメリットは、入力データセットの基づいて 6 つの最先端モデルからなるアンサンブルから最適なモデルを使用し、アイテムごとに自動で予測を生成することです。Boto3 API は auto prediction モデルをトレーニングするための create_auto_predictor 関数を提供します。この関数の入力パラメータは、PredictorName、ForecastHorizon、ForecastFrequency です。利用者は、予測期間と予測の頻度を選択できます。予測期間は、未来の予測のウィンドウサイズで表され、時間単位、日単位、週単位、月単位などの形式で渡されます。同様に予測の頻度は、時間単位、日単位、週単位、月単位、年単位など、予測値の粒度を表します。主にさまざまなビジネスラインの NXP の月次の売上予測に着目しました。下記コード :
PREDICTOR_NAME = "SALES_PREDICTOR"
FORECAST_HORIZON = 24
FORECAST_FREQUENCY = "M"
create_auto_predictor_response = \
forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME,
ForecastHorizon = FORECAST_HORIZON,
ForecastFrequency = FORECAST_FREQUENCY,
DataConfig = {
'DatasetGroupArn': dataset_group_arn
})
predictor_arn = create_auto_predictor_response['PredictorArn']このトレーニングされた予測子から予測値が生成されます。前でトレーニングされた予測子から create_forecast 関数を使用して予測が生成されます。この関数は、予測の名前、予測子の ARN を入力として受け取り、予測子で決められた予測期間と頻度での予測値を生成します。
FORECAST_NAME = "SALES_FORECAST"
create_forecast_response = \
forecast.create_forecast(ForecastName=FORECAST_NAME,
PredictorArn=predictor_arn)Amazon Forecast は完全なるマネージドサービスで自動でトレーニングデータとテストデータを生成し、生成されたモデルの予測値に対する信頼性を評価するためにさまざまな精度メトリクスを提供します。しかし、予測データの合意形成や、人間の予測値との比較のために、過去データを手動でトレーニングデータとテストデータに分割しました。検証データはそのモデルに入れずにトレーニングデータを使用してモデルのトレーニングを行い、検証データの期間の予測を生成しました。テストデータはモデルのパフォーマンスを評価するために予測値との比較を行いました。検証メトリクスには、平均絶対誤差率 (MAPE) 、重み付き絶対誤差率(WAPE)などが含まれています。次のセクションで議論されるように、精度メトリクスには WAPE が活用されました。
評価メトリクス
まず、長期売上予測 (2026 年売上) に対する予測モデルの予測値を検証するため、バックテストによるモデル性能の検証を行いました。WAPE を用いてモデルの精度を評価しました。WAPE の値が小さいほど、モデルの精度が高くなります。MAPE のような他の誤差メトリクスに対する WAPE の主な優位点は、各製品の売上の個々の影響を評価することです。そのため、全体の誤差を計算する際に、各製品の総売上への影響の大きさを考慮します。例えば、3,000 万円を生み出す製品で 2% の誤差を生じ、5 万円を生み出す製品で 10% の誤差を生じた場合、MAPE では全てを説明することができないでしょう。一方で、WAPE ではこれらの違いを説明できます。また、モデル予測の上限と下限を示すために、売上についてさまざまなパーセント値を予測しました。
マクロレベルの売上予測モデルの検証
続いて、WAPE の値に関してモデルの性能を評価しました。テスト用と検証用にそのデータを分けてモデルの WAPE 値を計算しました。例えば、2019 年のWAPE 値では、2011 年から 2018 年の売上データを使用してモデルをトレーニングし次の 12 ヶ月間の売上 (2019 年の売上)を予測しました。次に、下記の公式を使用して WAPE 値を計算しました。下記式 :

2020 年と 2021 年の WAPE 値も同じ手順で繰り返し計算しました。2019、2020、2021 年の自動車エンド市場のビジネスラインのWAPE 値を評価しました。結果として、2020 年の年(COVID-19の間)でさえも Amazon Forecast の WAPE 値は 0.33 を達成しました。 2019 年と 2021 年には、当社のモデルで WAPE 値 0.1 未満を達成し高い精度を示しました。
マクロレベルの売上予測のベースライン比較
Amazon Forecast を使用して開発されたマクロな売上予測モデルを3つのベースラインモデルと 2019、2020、2021 年の WAPE 値に関して比較しました(下図参照)。Amazon forecast は 3 年間全てにおいて、他のベースラインモデルを大きく上回るか、同程度のパフォーマンスを示しました。これらの結果は、我々の最終的な予測モデルの有効性を実証します。

マクロレベルの売上予測モデル vs 人間の予測
さらにマクロレベルのモデルを検証するために、私たちのモデルと人間によって予測された売上値を比較しました。毎年 4期目 の初めに、NXP のマーケティングの専門家が各ビジネスラインの売上を予測します。その際、 NXP の製品の売上に潜在的に影響を与えうるグローバル指標だけでなくグローバルマーケットのトレンドも考慮します。2019、2020、2021 年の実際の売上に関してモデルの予測と人の予測で誤差率を比較します。2011 – 2018 のデータを使用して 3 つのモデルをトレーニングし 2021 年までの売上を予測しました。次に実際の売上に関して MAPE を計算しました。そして、2018 年の終わりまでの人間の予測値を利用します (1年先の予測から 3 年先の予測まで、モデルを検証します)。2019 年 (1年先の予測から 2 年先の予測まで)、2020 年(1年先の予測)でもこの値を予測するプロセスを繰り返します。全体的に、モデルは人間の予測と同等か、場合によってはそれ以上の性能を発揮しました。これらの結果は、私たちのモデルの有効性と信頼性を示しています。
ミクロレベルの売上予測と製品のライフサイクル
次の図は、各製品について非常に少ない観測値 (すなわち、製品ライフサイクル予測のための入力で 1 つか 2 つの観測値) にアクセスしながら、製品データを使用してモデルがどのような結果を返すかを示しています。オレンジの点はトレーニングデータを、緑の点はテストデータを、青の線はモデルが予測した製品のライフサイクルを表しています。


このモデルは、新しいデータが加わっても再トレーニングを行う必要なく、コンテキストのためにより多くの観察データを提供することができます。下の図は、より多くのコンテキストを与えたときにモデルがどのように振る舞うかを検証しています。結局、コンテキストが多いほど WAPE 値は低くなります。
加えて、製造技術や他のカテゴリ情報など各製品の追加機能を組み込むことを試み、外的要因はコンテキストが低いうちは WAPE 値を下げることを促進することがわかりました(下図参照)。この結果に対して2つの説明ができます。1つ目は、ハイコンテキストの範囲では、データがそれ自体を説明するようにする必要があるので、追加の機能付与はこのプロセスを妨げる可能性があります。2つ目は、より良い機能が必要であり、1000 次元の one-hot エンコーディング (bag of words) を使用しました。より優れた特徴量エンジニアリング技術により、WAPE をさらに低減できると考えられます。
こうした追加データは、マーケットに製品が出る前でさえも新しい製品の売り上げをモデルが予測できるようになる可能性があります。例えば、下図は、外的な要因だけで、どれだけ予測できるかを示しています。

結論
この記事では、MLSL と NXP のチームがマクロレベルとミクロレベルで NXP の長期間の売上を予測するのにどう協業しているかを紹介しました。NXP のチームは今後、この売上予測を自社のプロセスでどのように活用するかを学びます。例えば、研究開発日の決定や ROI の向上のためのインプットとして活用できます。Amazon Forecast を使用してビジネスラインの売り上げ (マクロ売上) を予測したのですが、これをトップダウンアプローチと呼びます。製品レベルでの欠損値やコールドスタートの問題に取り組むために時系列を点群として活用する新たなアプローチを提示しました。このアプローチをボトムアップと呼びましたが、そこでは各製品の月次の売上を予測しました。さらにコールドスタートに対するモデルの性能を高めるために各製品の外的要因を実装しました。
全体として、この取り組みで開発されたモデルは、人の予測に比べ、同程度の性能を発揮しました。場合によっては、長期的に人間の予測よりも良い結果を出すこともありました。これらの結果は、私たちのモデルの有効性と信頼性を示しています。
このソリューションはどんな予測問題にも活用することができます。ML ソリューションの設計や開発にさらなる支援が必要な場合、 MLSL チームまで気軽に相談ください。
著者について
 Souad Boutane は、NXP-CTOのデータサイエンティストです。先進的なツールや技術を駆使してビジネスの決定を支援するためにさまざまなデータから深い洞察を行います。
Souad Boutane は、NXP-CTOのデータサイエンティストです。先進的なツールや技術を駆使してビジネスの決定を支援するためにさまざまなデータから深い洞察を行います。
 Ben Fridolin は、NXP-CTOのデータサイエンティストです。AIとクラウドの活用を促進する役割を担います。専門は、機械学習、深層学習、end-to-end の機械学習ソリューションです。
Ben Fridolin は、NXP-CTOのデータサイエンティストです。AIとクラウドの活用を促進する役割を担います。専門は、機械学習、深層学習、end-to-end の機械学習ソリューションです。
 Cornee Geenenは、NXPのデータポートフォリオチームのプロジェクトリーダーです。データ中心の組織へとデジタルトランスフォーメーションするための支援をします。
Cornee Geenenは、NXPのデータポートフォリオチームのプロジェクトリーダーです。データ中心の組織へとデジタルトランスフォーメーションするための支援をします。
 Bart Zeemanは、NXP-CTOのデータ分析に関して情熱を持ったストラテジストです。さらなる成長とイノベーションのためにより良いデータドリブンな意思決定を加速します。
Bart Zeemanは、NXP-CTOのデータ分析に関して情熱を持ったストラテジストです。さらなる成長とイノベーションのためにより良いデータドリブンな意思決定を加速します。
 Ahsan Aliは、Amazon Machine Learning Solutions Labの応用技術者です。お客様と一緒にさまざまなドメインで最先端のAI/ML 技術を活用して緊急かつコストのかかる問題を解決します。
Ahsan Aliは、Amazon Machine Learning Solutions Labの応用技術者です。お客様と一緒にさまざまなドメインで最先端のAI/ML 技術を活用して緊急かつコストのかかる問題を解決します。
 Yifu HuはAmazon Machine Learning Solutions Labの応用技術者です。さまざまな業界のお客様のビジネス課題に取り組むためのクリエイティブなML ソリューションの設計を支援します。
Yifu HuはAmazon Machine Learning Solutions Labの応用技術者です。さまざまな業界のお客様のビジネス課題に取り組むためのクリエイティブなML ソリューションの設計を支援します。
 Mehdi NooriはAmazon Machine Learning Solutions Labの応用技術者です。さなざまな業界にまたがる大きな組織に対してMLソリューションの開発を支援し、エネルギー分野のリードをします。彼は、顧客がサステイナブルなゴールを達成するためにAI/MLの技術を活用することに注力します。
Mehdi NooriはAmazon Machine Learning Solutions Labの応用技術者です。さなざまな業界にまたがる大きな組織に対してMLソリューションの開発を支援し、エネルギー分野のリードをします。彼は、顧客がサステイナブルなゴールを達成するためにAI/MLの技術を活用することに注力します。
 Huzefa Rangwalaは、AWSのAIREの応用技術者のシニアマネージャーです。彼はデータ資産からの発見をベースに機械学習を活用する科学者と技術者がいるチームをリードします。彼の研究テーマは責任あるAI、連合学習、ヘルスケアやライフサイエンスにおける機械学習の応用です。
Huzefa Rangwalaは、AWSのAIREの応用技術者のシニアマネージャーです。彼はデータ資産からの発見をベースに機械学習を活用する科学者と技術者がいるチームをリードします。彼の研究テーマは責任あるAI、連合学習、ヘルスケアやライフサイエンスにおける機械学習の応用です。