Amazon Web Services ブログ
データ階層化による Amazon MemoryDB for Redis クラスターのコスト最適化
この記事は Roberto Luna Rojas と Karthik Konaparthi、 Qu Chen によって投稿された Scale your Amazon MemoryDB for Redis clusters at a lower cost with data tiering を翻訳したものです。
Amazon MemoryDB for Redis は、インメモリパフォーマンスとマルチ AZ 耐久性の両方を提供する Redis 互換のデータベースサービスです。MemoryDB は、ユーザーセッションデータ、マイクロサービス間のメッセージストリーミング、支払い処理、ゲームランキング、モノのインターネット (IoT) など、耐久性のあるストレージと超高速パフォーマンスを必要とするユースケースのプライマリデータベースとして使用できます。
2022年11月3日、AWS Graviton2 ベースの R6gd ノードタイプのデータ階層化が MemoryDB で利用可能になったことを発表しました。R6gd ノードを使用する場合、MemoryDB は DRAM とローカルに接続された NVMe ソリッドステートドライブ (SSD) 間でデータを自動的かつ透過的に階層化します。SSD は、Redis ワークロードのレイテンシーがメモリよりもわずかに高くなりますが、コストも大幅に低くなります。データ階層化機能のあるクラスタを使用する場合、R6gd ノードでは総容量がほぼ 5 倍になり (メモリと SSD)、R6g ノード (メモリのみ) と比較して最大使用率で実行すると、アプリケーションへのパフォーマンスへの影響を最小限に抑えながら、ストレージコストを 60% 以上節約できます。
500 バイトの String 値を想定すると、SSD に保存されたデータへの読み取りリクエストには、メモリ内のデータへの読み取りリクエストに比べて、通常は 450 µs のレイテンシが長くなることが予想されます。
最大データ階層化ノードサイズ (db.r6gd.8xlarge) では、単一の 500 ノードクラスターに最大 500 TB を格納できるようになりました (1 つのリードレプリカを使用する場合は 250 TB)。データ階層化は、MemoryDB でサポートされているすべての Redis コマンドとデータ構造と互換性があります。この機能を使用するためにクライアント側を変更する必要はありません。
この記事では、MemoryDB のデータ階層化機能を備えた R6gd インスタンスを使用して、最適なコストで容量をスケーリングする方法について説明します。
データ階層化の仕組み
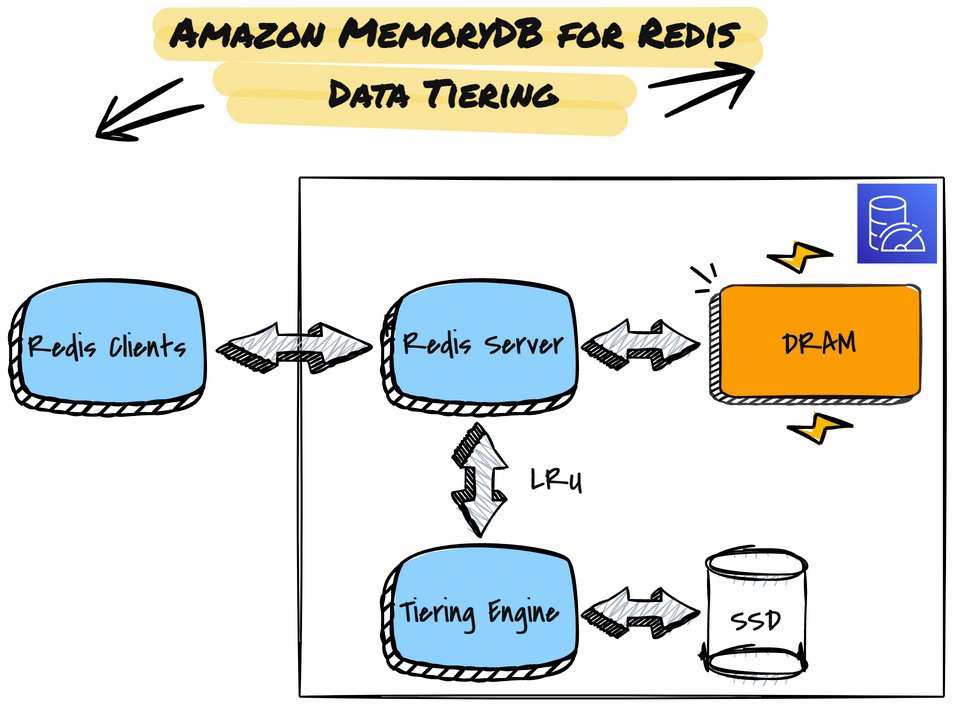
データ階層化のあるクラスターでは、MemoryDB は保存されているすべての項目の最終アクセス時間を監視します。使用可能なメモリ (DRAM) が消費されると、MemoryDB はleast-recently used (LRU) アルゴリズムを使用して、アクセスされていないアイテムをメモリから SSD に自動的に移動します。その後 SSD 上のデータにアクセスすると、MemoryDB は要求を処理する前にデータを自動的かつ非同期的にメモリに戻します。データのサブセットにのみ定期的にアクセスするワークロードがある場合、データ階層化は、多くの場合、アプリケーションのパフォーマンスに明らかな影響を与えることなく、費用対効果の高い方法で容量をスケーリングするための優れたオプションです。
MemoryDB は、高スループットと低レイテンシを実現するように微調整された専用の階層化エンジンを使用して NVMe SSD にデータを保存します。セキュリティとデータの保全性は、階層化エンジンの設計における重要な重点分野でした。すべての Graviton2 ベースのハードウェアと同様に、MemoryDB R6gd ノードは常時オンの 256 ビットの暗号化 DRAM を備えています。さらに、NVMe SSD に保存されているすべてのアイテムは、ノード上のハードウェアモジュールに実装された XTS-AES-256 ブロック暗号を使用して(保存データの暗号化を設定していないクラスターであっても)デフォルトで暗号化されます。NVMe SSD から読み込まれた各項目に crc32c チェックサムを使用してデータ整合性検証を行います。
次の図は、データ階層化機能を備えた MemoryDB ノードの高レベルのアーキテクチャを示しています。
データ階層化を始める
データ階層化の使用を開始するには、次の手順を実行します。
- MemoryDB コンソールのナビゲーションペインで [Clusters] を選択します。
- [クラスターの作成] を選択します。
これにより、クラスター作成ワークフローが開きます。 - Redis のバージョン互換性については、6.2 エンジンを選択してください。
- r6gd ファミリーのノードタイプを選択してください (データ階層化は古いエンジンバージョンや他のノードファミリーではサポートされていません)。
- [次へ] を選択します。
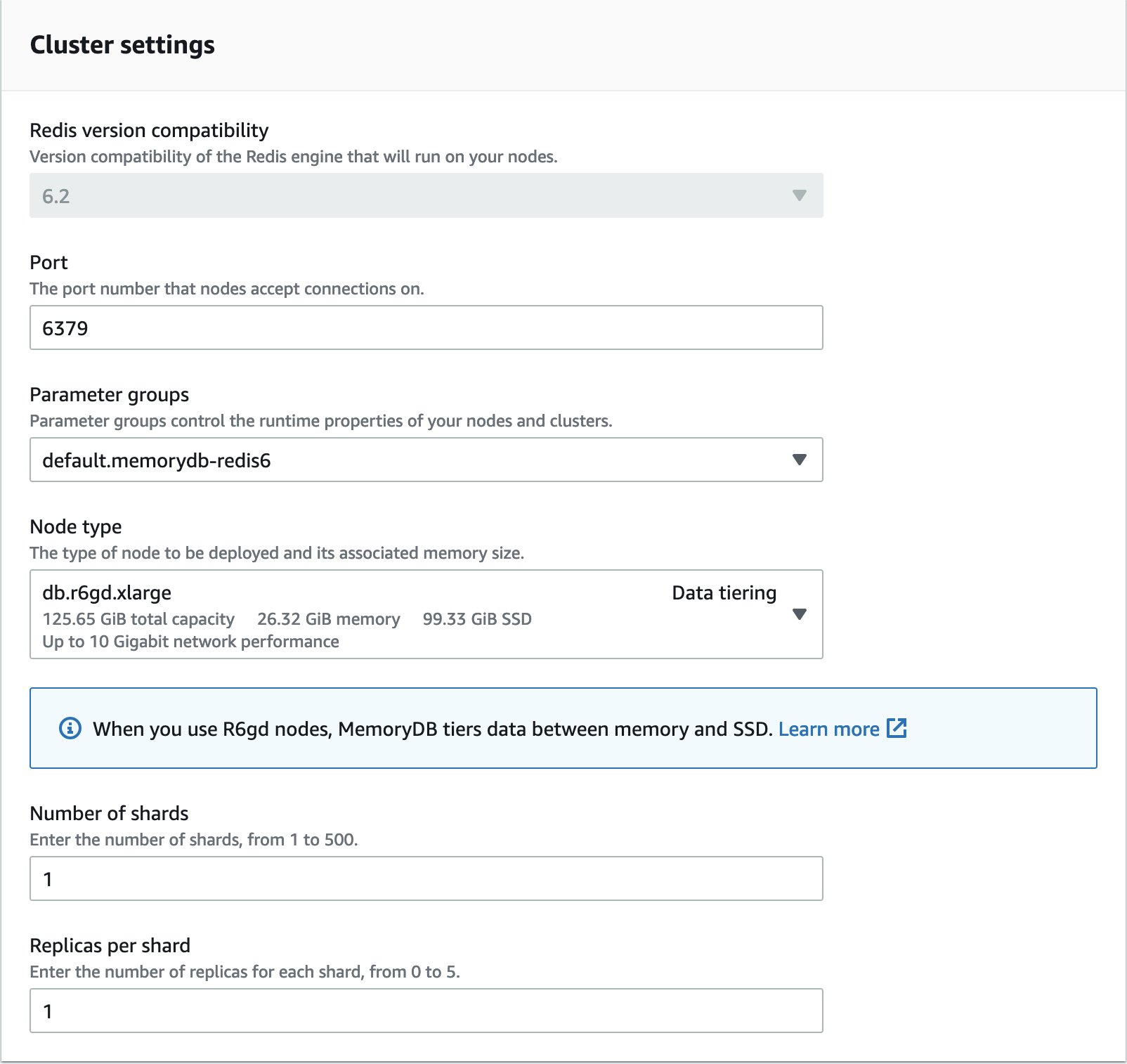

- 名前やサブネットグループなど、必要な残りのクラスター構成パラメーターを入力し、[作成] を選択します。
数分後、クラスターのステータスが Available に変わります。その後、Redis コマンドラインインターフェイスまたは任意の Redis クライアントを使用してクラスターに接続できます。既存の MemoryDB クラスターからデータを移行するには、新しい R6gd クラスターにバックアップを復元できます。
パフォーマンス分析
MemoryDB データ階層化は、データのごく一部に定期的にアクセスするアプリケーションのパフォーマンスへの影響を最小限に抑えるように設計されています。データ階層化は、データの 20% までを定期的にアクセスする大規模なワークロードや、SSD 階層のデータにアクセスしたときに遅延が増えることを許容できるアプリケーションに最適です。これらのワークロードでは、ワーキングセット (定期的にアクセスされるデータセット) は完全にメモリ内で処理され、残りのデータセットは SSD から提供されます。
パフォーマンスを測定するために、 redis-benchmark を使用して負荷を生成しました。転送中の暗号化を有効にした単一ノードの db.r6gd.2xlarge クラスターでテストしました。同じアベイラビリティーゾーンで 5 つの Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを使用して負荷を生成しました。テストセットアップでは、2億5,000万のユニークキー、16バイトのキー長、500バイトの文字列値、100台のクライアント接続をコマンドパイプラインなしで使用しました。
100 台のクライアント接続のうち、90 台のクライアントはホットデータセットと見なされるより狭い範囲のキーに対してリクエストを生成し、残りの 10 台のクライアントはキー範囲全体に対してリクエストを生成したため、リクエストの約 10% は NVMe SSD に保存されているアイテムに対して発行されました。ベンチマークを複数日にわたって継続的に実行しました。
このテストは、データ階層化がアクティブで、アクセス頻度の低いアイテムが再び必要になった場合に MemoryDB がどのように動作するかを示す代表的なサンプルを提供するために、この方法で構築しました。 次の表は、調査結果をまとめたものです。
| ワークロードタイプ | スループット (1 秒あたりのリクエスト数) | 平均レイテンシー (ミリ秒) | レイテンシー p50 (ミリ秒) | レイテンシー p90 (ミリ秒) | レイテンシー p95 (ミリ秒) | レイテンシー p99 (ミリ秒) |
| 書き込み専用 | 28,500 | 3.7 | 3.3 | 4.1 | 5.5 | 7.5 |
| 読み取り専用 | 180,000 | 0.7 | 0.65 | 1.1 | 1.7 | 3.5 |
| 混合(読み取り 80%、書き込み 20%) | 140,000 | 1.6 | 1.3 | 2.4 | 3.6 | 6.2 |
また、ホットデータセットのキー範囲を広げることで、NVMe SSD に保存されているアイテムに対してリクエストの 20% が発行された場合をテストしました。結果は以下の通りです。
| ワークロードタイプ | スループット (1 秒あたりのリクエスト数) | 平均レイテンシー (ミリ秒) | レイテンシー p50 (ミリ秒) | レイテンシー p90 (ミリ秒) | レイテンシー p95 (ミリ秒) | レイテンシー p99 (ミリ秒) |
| 書き込み専用 | 25,000 | 4.1 | 3.5 | 6.5 | 9.1 | 12.2 |
| 読み取り専用 | 101,500 | 1.3 | 0.65 | 4 | 5.9 | 7 |
| 混合(読み取り 80%、書き込み 20%) | 85,000 | 2 | 1.3 | 4.6 | 6.3 | 8.8 |
結果によると、MemoryDB データ階層化ノードは、データのごく一部に定期的にアクセスするアプリケーションのパフォーマンスへの影響が最小限であることがわかります。
Amazon CloudWatch を使用してクラスターをデータ階層化してモニタリングする
今回のリリースでは、MemoryDB で使用できる Amazon CloudWatch メトリクスを更新し、データ階層化のあるクラスターでの SSD の使用状況を反映するようにしました。具体的には、4つの新しい指標と既存の2つの指標に指標ディメンションを追加しました。
新しいメトリックには 2 つのペアがあります。1 つは SSD 階層から読み書きされているデータの量を示す BytesReadFromDisk と BytesWrittenToDisk、そして、SSD 階層から読み書きされる Redis アイテムの量を示す NumItemsReadFromDisk と NumItemsWrittenToDisk です。
これらの 4 つの新しいメトリクスに加えて、CurrItems と BytesUsedForMemoryDB のメトリクスに Tier メトリックディメンションを導入しました。 Tier には、 Memory と SSD の 2 つの値を設定できます。たとえば、CurriItems メトリクスをクエリするときに Tier を指定しない場合、以前と同様にクラスター内のアイテムの総数が取得されます。Tier=Memory または Tier=SSD を指定すると、合計がメモリ内のアイテム数とSSD上のアイテム数でそれぞれ分類されて表示されます。これらの新しい指標と指標ディメンションは、データ階層化のあるクラスターでのみ使用可能であることに注意してください。
ここでは、新しい指標の活用方法の実践例を紹介します。クライアント側のレイテンシーが高い時、NumItemsReadFromDisk を調べることができます。この値が高い場合 (CloudWatch のメトリック計算による GetTypeCmds + SetTypeCmds と比較した場合など)、SSD がメモリに比べてデータ階層化に理想的とは言えないほど頻繁にアクセスされている可能性があります。より大きな r6gd ノードタイプにスケールアップすることも、シャードを追加してスケールアウトして、アクティブなデータセットに対応するためにより多くのRAMを使用することもできます。
まとめ
この記事では、MemoryDB のデータ階層化が、どのようにクラスターを低コストで最大 500 TB のデータまでスケーリングさせるかについて説明しました。データの一部に定期的にアクセスするワークロードのパフォーマンスへの影響を最小限に抑えながら、ストレージコストを 60% 以上節約できます。
MemoryDB のデータ階層化機能を備えた R6gd ノードタイプは、現在、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (北カリフォルニア)、米国西部 (オレゴン)、アジアパシフィック (ムンバイ)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、カナダ (中部)、ヨーロッパ (フランクフルト)、ヨーロッパ (アイルランド)、ヨーロッパ (パリ)、および南米(サンパウロ)地域でご利用いただけます。料金については、 Amazon MemoryDB の料金表を参照してください。
MemoryDB のデータ階層化を使用して、クラスターを低コストでスケーリングできるようになったことを嬉しく思います。データ階層化に関するご意見やご質問をお待ちしておりますので、 memorydb-help@amazon.com またはコメント欄でお問い合わせください。
著者

Roberto Luna Rojas は、ニューヨークを拠点とする AWS インメモリ DB スペシャリストソリューションアーキテクトです。彼はインメモリデータベースを最大限に活用するために、世界中のお客様と一緒に少しずつ取り組んでいます。コンピューターの前にいないときは、家族と過ごしたり、音楽を聴いたり、映画、テレビ番組、スポーツを見たりするのが大好きです。

Karthik Konaparthi は Amazon インメモリデータベースチームのシニアプロダクトマネージャーで、ワシントン州シアトルに拠点を置いています。彼はデータのすべてに情熱を注いでおり、顧客と協力して顧客の要件を理解し、優れた製品を開発することに時間を費やしています。余暇には、新しい場所への旅行や家族との時間を楽しんでいます。

Qu Chen は Amazon ElastiCache と MemoryDB のシニアソフトウェア開発エンジニアです。MemoryDB は、AWS でスケーラブルで高性能な Redis マネージドサービスの構築、運用、保守を担当するチームです。また、オープンソースの Redis プロジェクトにも積極的に貢献しています。余暇には、スポーツ、野外活動、ピアノ音楽の演奏を楽しんでいます。
この記事はソリューションアーキテクトの堤勇人が翻訳しました。原文はこちらです。