Amazon Web Services 한국 블로그
Amazon Kinesis 업데이트 – Amazon Elasticsearch Service 통합, 샤드 통계 및 시간 기반 반복 기능
Amazon Kinesis는 대용량 스트리밍 데이터를 클라우드에서 손쉽게 처리할 수 있도록 도와 줍니다.
Amazon Kinesis 플랫폼은 3개의 서비스로 구성되어 있습니다: Kinesis Streams은 개발자가 자신의 스트리밍 데이터 처리 애플리케이션을 구현할 수 있습니다; Kinesis Firehose를 통해 스트리밍 데이터를 저장하고 분석하기 위해 AWS에 저장하는 기능에 초점을 맞추었습니다; Kinesis Analytics 를 통해 스트리밍 데이터를 표준 SQL을 통해 분석 할 수 있습니다.
많은 AWS 고객이 스트리밍 데이터를 실시간으로 수집 · 처리하는 방식으로 Kinesis Streams와 Kinesis Firehose을 이용하고 있습니다. 이는 완전 관리 서비스이기 때문에 사용 편의성을 높아 스트리밍 데이터 처리를 위한 인프라를 직접 관리하는 대신 응용 프로그램에 개발하는 시간에 투자를 할 수 있다는 장점이 있습니다.
오늘 Amazon Kinesis Streams와 Kinesis Firehose 관한 3개의 새로운 기능을 신규 발표합니다.
- Elasticsearch 통합– Amazon Kinesis Firehose는 Amazon Elasticsearch Service에 스트리밍 데이터를 전달할 수 있습니다..
- 강화된 모니터링 수치 제공– Amazon Kinesis는 샤드 단위 메트릭을 CloudWatch로 매 분당 보낼 수 있습니다.
- 유연성 확보– Amazon Kinesis에서 시간 기반의 반복자를 이용하여 레코드를 수신 할 수 있습니다.
Amazon Elasticsearch Service 통합
Elasticsearch
는 인기있는 오픈 소스 검색 · 분석 엔진입니다. Amazon Elasticsearch Service는 AWS 클라우드에서 Elasticsearch를 손 쉽게 설치하고, 높은 확장성을 가지고 운영할 수 있는 관리 서비스입니다. 오늘 부터 Kinesis Firehose 데이터 스트림을 Amazon Elasticsearch Service 클러스터에 배포 할 수 있게되었습니다. 이 새로운 기능은 서버의 로그 및 클릭 스트림, 소셜 미디어 트래픽 등으로 인덱스를 생성하고 분석 할 수 있습니다.
전송 받은 레코드 (Elasticsearch 문서)는 지정한 설정에 따라 Kinesis Firehose에서 버퍼링 된 후,여러 문서를 동시에 인덱스를 만들 수 있도록 벌크 요청을 사용하여 자동으로 클러스터를 추가합니다. 또한, 데이터는 Firehose로 전송하기 전에 UTF-8로 인코딩 된 단일 JSON 개체에 두어야 합니다. (관련 정보는 Amazon Kinesis Agent Update – New Data Preprocessing Feature를 참조하십시오).
이제 AWS 관리 콘솔을 통한 설정 방법을 알아보겠습니다. 대상(Amazon Elasticsearch Service)를 선택하고 전송 스트림의 이름을 입력합니다. Elasticsearch 도메인 (livedata 예제)을 선택 인덱스로 지정하고, 인덱스 주기(없음, 시간별, 매일, 매주, 매월)를 선택합니다. 또한, 모든 문서 또는 실패한 문서의 백업을받을 S3 버킷을 지정합니다 :
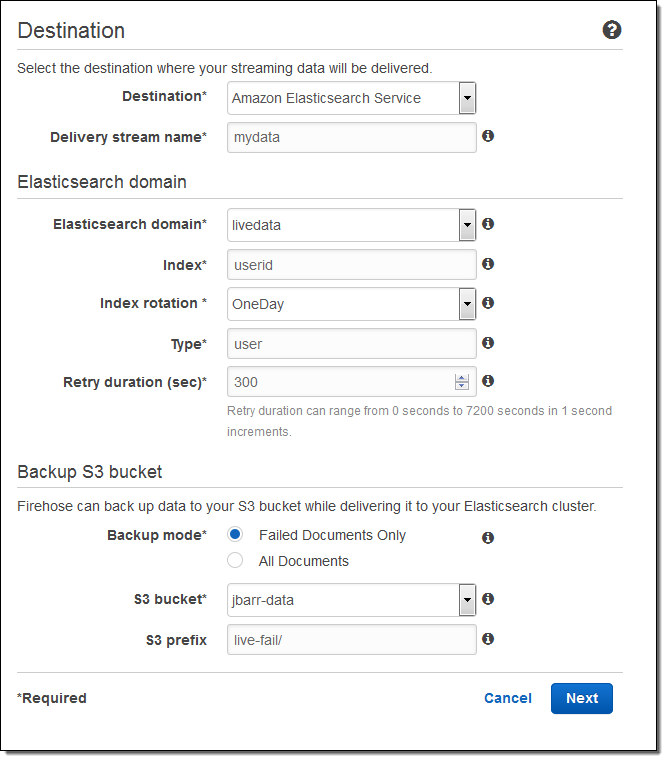
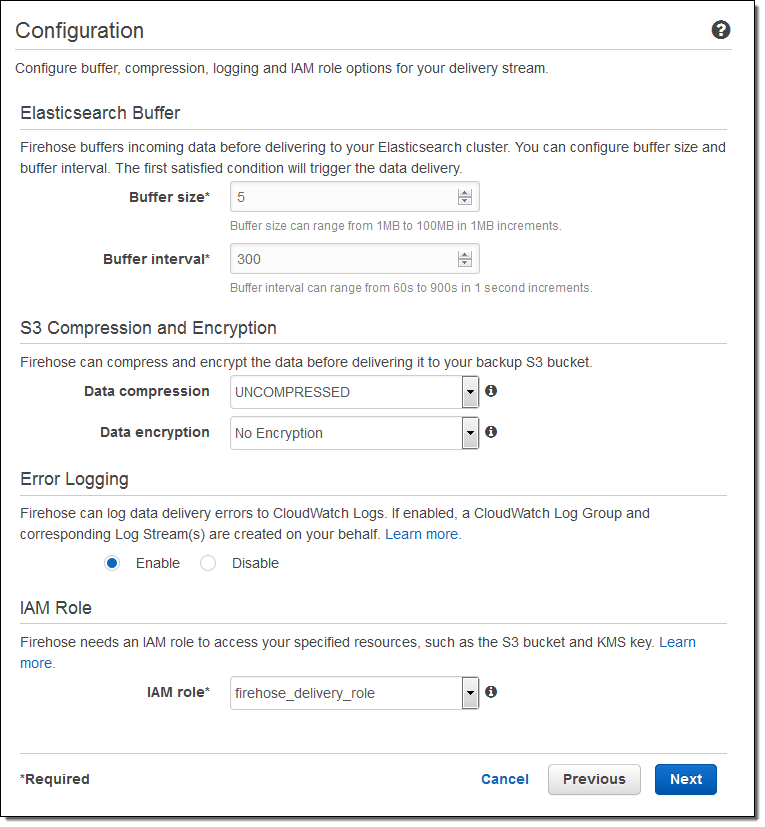
그리고 버퍼의 크기를 지정하고 S3 버킷에 전송되는 데이터의 압축 및 암호화 옵션을 선택합니다. 필요에 따라 로깅을 사용하고 IAM 역할을 선택합니다 :
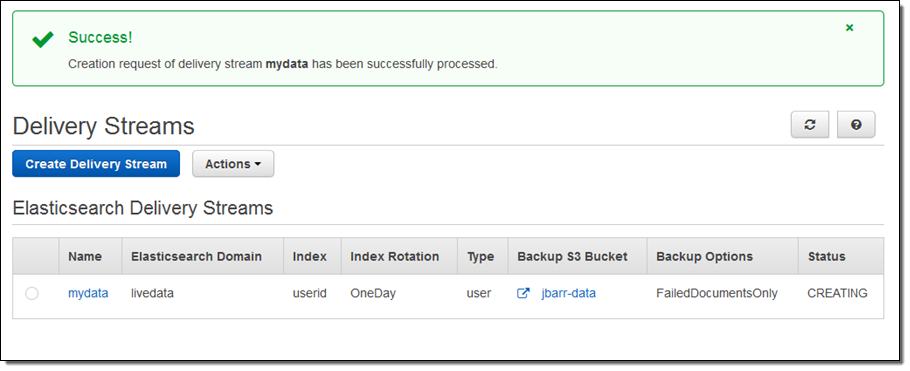
1분 정도 이후에 스트림이 준비 됩니다 :
I can view the delivery metrics in the Console:
스트리밍 데이터가 Elasticsearch에 도달 한 후에는 Kibana와 Elasticsearch 쿼리 언어에 의해 데이터 시각화를 할 수 있습니다.
즉, 통합을 통해 여러분의 스트리밍 데이터를 수집하고 Elasticsearch에 전달 하기 위한 처리 방법은 매우 간단합니다. 더 이상 코드를 작성하거나 자체 데이터 수집 도구를 만들 필요가 없습니다.
샤드 기반 통계 모니터링
모든 Kinesis 스트림은 하나 이상의 샤드로 구성되어 있으며, 모든 샤드는 일정량의 읽기 · 쓰기의 용량을 가지고 있습니다. 필요에 따라 스트림에 샤드를 추가하면 스트림의 용량은 증가합니다.
여러분은 각 샤드의 성능을 파악하기위한 목적으로 샤드 단위의 통계 기능을 활성화 할 수 있게되었습니다. 샤드 당 6개의 메트릭이 있습니다. 각 통계는 1 분에 한 번 보고되고, 일반 통계 단위의 CloudWatch 요금이 부과됩니다. 이러한 신규 기능은 특정 샤드에 부하가 편중되지 않았는지, 다른 샤드와 비교하여 확인하거나 스트리밍 데이터의 전송 파이프 라인을 통해 비효율적 인 부분을 발견 및 변경할 수 있게 됩니다.
아래에는 새로이 측정되는 수치입니다.
IncomingBytes – 샤드로 PUT이 성공한 바이트 수.
IncomingRecords – 샤드로 PUT이 성공한 레코드.
IteratorAgeMilliseconds –샤드에 대한 GetRecords 호출이 취소 된 마지막 레코드의 체류 시간 (밀리 초). 값이 0 인 경우, 읽은 레코드가 완전히 스트림에 붙어 있다는 것을 의미합니다.
OutgoingBytes – 샤드에서받은 바이트 수.
OutgoingRecords – 샤드에서받은 레코드 수.
ReadProvisionedThroughputExceeded – 매초 5 회 또는 2MB를 초과한 GetRecords 호출 수.
WriteProvisionedThroughputExceeded – 매 초 1000 기록 또는 1MB를 초과한 레코드의 수.
EnableEnhancedMetrics 를 호출하는 것으로 활성화 할 수 있습니다. 평소처럼, 일정 기간 동안 집계를 위해 CloudWatch API를 사용할 수 있습니다.
시간 기반 반복 기능
어떤 샤드에 GetShardIterator를 호출 시작점으로 지정하고, 반복 기능을 작성하여 애플리케이션에서 Kinesis 스트림 데이터를 읽을 수 있습니다. 기존의 시작점 선택 (시퀀스 번호 시퀀스 번호 뒤에 가장 오래된 기록, 가장 새로운 레코드)에 추가로 타임 스탬프를 지정할 수 있게되었습니다. 지정한 값 (UNIX 시간 형식)은 읽고 처리하려고하는 가장 오래된 레코드의 타임 스탬프를 나타냅니다.
— Jeff;
이 글은 Amazon Kinesis Update – Amazon Elasticsearch Service Integration, Shard-Level Metrics, Time-Based Iterators의 한국어 번역입니다.