Amazon Web Services 한국 블로그
Edge기반 기계 학습: AWS IoT Greengrass를 활용한 이미지 분류 모델 훈련 (Part 2)
이 블로그 게시물의 1부에서는 재활용 시설의 분류기가 네 가지 음료 용기를 식별할 수 있도록 해 주는 이미지 분류 모델을 생성했고, 이 모델을 AWS IoT Greengrass Image Classification Connector를 사용하여 AWS IoT Greengrass 코어 디바이스에 배포하는 것을 구현했습니다. 지난 re:Invent 2018에서 발표된 AWS IoT Greengrass 커넥터를 사용하면 코드를 작성하지 않고 IoT Greengrass 코어 디바이스를 타사 애플리케이션, 온프레미스 소프트웨어 및 AWS 서비스에 연결할 수 있습니다.
1부 끝부분에서 우리는 음료 용기 예측이 항상 정확하거나 높은 신뢰도를 일관적으로 제공하지 못할 수 있다는 것을 볼 수 있었습니다. 2부에서는 예측 신뢰도 임계값을 위반하는 이미지를 업로드하도록 애플리케이션을 확장하고, 모델을 재훈련하여 IoT Greengrass 코어 디바이스에 다시 배포하는 것을 구현 하겠습니다.
참고: 이 블로그 게시물의 정보는 1부의 내용에 상당 부분 의존하고 있습니다. 계속하기 전에 1부의 단계들을 모두 완료하시는 것을 권장드립니다.
개요
이 게시물에서는 1부에서 생성한 음료 분류기 Lambda 함수를 확장하여 캡처된 이미지의 예측 신뢰도를 확인하는 별도의 단계를 코드에 추가합니다. 예측 신뢰도가 최소 또는 최대 임계값 범위를 벗어나는 이미지를 추후 Amazon SageMaker 모델 훈련 작업에 사용하기 위해 이미지에 수동으로 레이블을 지정할 수 있도록 Amazon S3에 업로드 됩니다. 다시 말해, Amazon SageMaker 노트북이 새로 레이블이 지정된 이 이미지들을 다운로드하고 원본 Caltech 256 데이터 세트와 결합한 다음 새 데이터와 원본 데이터가 조합된 새 모델을 생성하는 방법을 구현합니다. 마지막으로, IoT Greengrass 그룹 커넥터의 모델을 업데이트하고 코어 디바이스에 재배포하겠습니다.
2부를 마치면 여기에 표시된 것과 유사한 아키텍처가 완성됩니다. 이미지의 번호는 모델 재훈련 작업의 흐름 순서를 나타냅니다.

사전 조건
Lambda 함수에서 Amazon S3에 액세스하기 위해 AWS SDK for Python(Boto3)을 사용하겠습니다. 다음 명령을 실행하여 Raspberry Pi에 이 SDK를 설치합니다.
애플리케이션 확장 및 테스트
이미지를 S3에 업로드하려면 코어 디바이스에 S3 버킷 액세스 권한을 부여해야 합니다.
S3 권한 구성
AWS IoT 콘솔에 있는 그룹의 설정 페이지에서 [Group Role]의 값을 따로 적어 둡니다. 역할이 그룹에 대해 이미 구성되어 있지 않은 경우에는 AWS IoT Greengrass 개발자 가이드의 IAM 역할 구성을 참조하십시오.
그룹에 S3 액세스 권한을 부여하려면 IAM 콘솔을 사용하여 해당 역할에 AmazonS3FullAccess 정책을 추가해야 합니다. IAM 콘솔에서 [Roles]를 선택합니다. IoT Greengrass 그룹에 대한 역할을 찾아 선택 후 요약 페이지에서 [Attach policies]를 선택합니다.
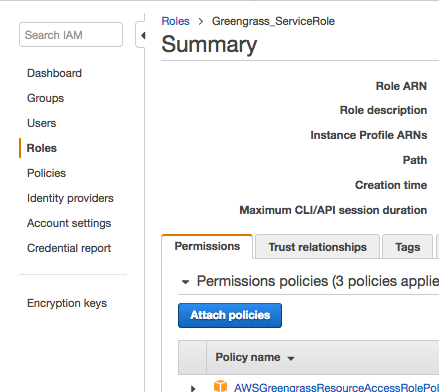
AmazonS3FullAccess를 검색하여 확인란을 선택한 다음 [Attach policy]를 선택합니다.

그룹에 배포를 수행합니다. 그룹은 이제 S3에 대한 읽기 및 쓰기 권한을 가집니다.
다른 AWS 서비스와의 상호 작용에 대한 자세한 내용은 AWS IoT Greengrass 개발자 가이드의 모듈 6: AWS 클라우드 서비스 액세스를 참조하십시오.
음료 분류기 Lambda 함수 확장
이번 단계에서는 음료 분류기 Lambda 함수를 확장하겠습니다. 새 코드는 S3와 통합됩니다. 이 코드는 레이블을 지정할 이미지를 언제 업로드하여 새 훈련 데이터로 사용할 지를 결정하는 논리를 제공합니다. 다음과 같이 실패한 이미지를 업로드하고자 합니다.
- 최고 임계값 초과. 신뢰도가 낮은 예측을 검증하는 데이터로 사용됩니다.
- 최소 임계값 미달. 태그를 지정하여 데이터 세트에 포함합니다.
음료 분류기 Lambda 함수를 GitHub에 있는 코드를 사용하여 업데이트합니다.
새 배포를 생성합니다.
필드의 데이터 수집
음료 분류기는 이제 수동 레이블 지정을 위해 필드의 데이터를 수집하여 S3에 업로드할 수 있습니다. 이제 S3 버킷의 image-classification 폴더에 다음과 같은 항목을 볼 수 있습니다.
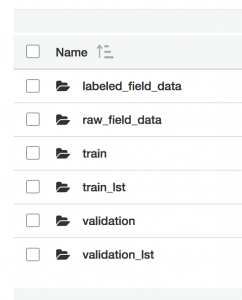
업데이트된 애플리케이션을 사용해 다섯 가지 범주 각각에 대해 시간을 두고 이미지를 수집해 보십시오. 여기에서는 광범위한 테스트 데이터 수집을 위해 각 클래스에 대해 다양한 물체의 사진을 여러 다른 각도에서 찍어 범주당 50개의 추가 이미지를 수집했습니다. 이미지를 분류하고 1부의 방식과 같이 /request/classify/beverage_container 주제에 게시하고 /response/prediction/beverage_container 주제를 구독하면 AWS IoT 콘솔의 [Test] 페이지에서 결과를 볼 수 있습니다.
다음은 캡처한 이미지의 일부 예입니다.








필드 데이터 레이블 지정
데이터에 레이블을 지정하려면 S3 버킷의 raw_field_data 폴더에 있는 이미지를 검토하고 labeled_field_data 폴더에 있는 각각의 범주 폴더로 이미지를 이동해야 합니다. 이 작업에는 AWS CLI를 사용하는 것이 좋습니다.
S3 버킷을 데스크탑의 폴더에 동기화합니다.
로컬 raw_field_data 폴더에 있는 이미지를 검토합니다. 각 이미지를 검토하고 로컬 labeled_field_data 폴더에 있는 각각의 폴더로 이동합니다.
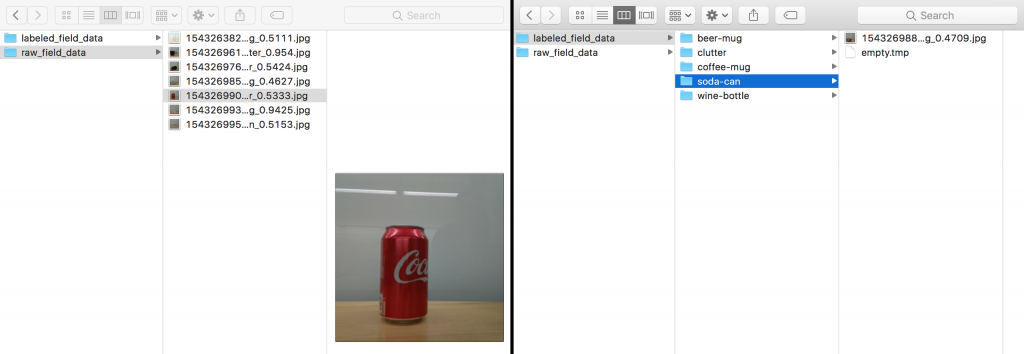
레이블을 지정한 후 다음 명령을 실행하여 S3를 업데이트합니다. 이렇게 하면 레이블이 지정되지 않은 이미지가 올바르게 레이블이 지정된 폴더로 이동합니다.
모델 재훈련
이제 새로 레이블이 지정된 데이터를 모델 재훈련에 사용할 수 있습니다. 1부에서 사용한 Amazon SageMaker 노트북(여기에 있는 노트북에서 복사)으로 돌아갑니다. 노트북에 있는 단계를 따르고 끝까지 진행 후 아래 과정들을 계속하여 진행합니다.
참고: 훈련 데이터를 추가할 때마다 노트북의 2부를 다시 실행할 수 있습니다. 이렇게 하면 코어 디바이스에 배포할 수 있는 새 모델이 생성됩니다.
모델 재배포
이제 재훈련된 모델을 배포할 수 있습니다. IoT Greengrass 그룹으로 돌아가 1부에서 생성한 기계 학습 리소스를 편집합니다. Amazon SageMaker 훈련 작업에 대한 드롭다운 메뉴에서 새 훈련 작업을 선택합니다. [Save]를 선택한 다음 배포를 생성합니다. 배포를 완료하면 Lambda 함수에서 새 모델을 사용하게 됩니다.
새 모델 테스트
이제 새 모델을 배포했으니 어떻게 처리되는지 성능 테스트할 수 있습니다. AWS의 테스트에서는 모델이 테스트 대상을 일관적으로 식별하는 능력에 개선 효과가 있었습니다. 직접 테스트를 수행하여 자신의 모델이 어떤 결과를 보여주는지 확인해 보십시오.
모델 성능 측정에 대한 자세한 내용은 Amazon SageMaker 이미지 분류 샘플 노트북을 참조하십시오.
복습
이 게시물의 1부와 2부에서는 새 AWS IoT Greengrass Image Classification connector를 사용하여 몇 가지 음료 용기 범주를 식별하는 AWS IoT Greengrass 애플리케이션을 생성했습니다. 2부에서는 이 애플리케이션을 확장하여 필드의 데이터를 수집하고 1부에서 생성한 모델을 재훈련하도록 했습니다.
여러분의 구축한 애플리케이션도 보고 싶습니다! AWS IoT Greengrass에서 앞으로 발표할 새로운 내용을 기대하시기 바랍니다.
다음 작업
이 게시물의 예를 가지고 계속 다양한 시도해 보려는 경우 다음과 같은 몇 가지 아이디어를 활용해 보십시오. 모델 재훈련 및 개선에 대한 자세한 내용은 Amazon SageMaker 이미지 분류 설명서를 참고하시기 바랍니다.
다음과 같은 작업도 시도해 볼 수 있습니다.
- Amazon SageMaker Ground Truth 사용.
- 모델에 새 클래스 추가.
- Amazon SageMaker 노트북의 훈련 파라미터를 다양하게 조정하여 모델 정확도 개선.
- 반복 훈련을 사용하도록 AmazonSageMaker 노트북의 훈련 구성 업데이트. Amazon SageMaker 개발자 가이드의 Image Classification 알고리즘 참조 권장.
- 코어 디바이스가 오프라인 상태일 때 캡처한 이미지를 저장했다가 클라우드 연결이 복원되었을 때 S3에 업로드하는 버퍼링 메커니즘 추가.
자세한 내용은 https://aws.amazon.com/greengrass/를 참고하세요.
– Mark Mevorah;