Amazon Web Services 한국 블로그
Amazon QuickSight Q – 자동화된 데이터 준비 기능 출시
2021년 9월에 공개된 이 게시글에서 Jeff Barr 씨가 Amazon QuickSight Q의 정식 출시 소식을 발표했었습니다. 요약해서 말씀드리자면, Amazon QuickSight Q는 기업 사용자가 데이터에 대한 간단한 질문을 할 수 있는 자연어 쿼리 기능입니다.
QuickSight Q는 쉬운 언어를 사용하여 데이터를 쿼리하고 대시보드, 제어 기능, 계산을 사용할 필요가 없는 기계 학습(ML) 기반 셀프 서비스 분석을 제공합니다. 작년에 QuickSight Q가 출시되었을 무렵에 ‘2021년에 EMEA에서 가장 높은 매출을 올린 사람’과 같은 간단한 질문을 물으면 몇 초 이내에 (그래픽, 지도, 표 등의 관련 시각 자료가 첨부된) 답변을 받을 수 있었습니다.
분석에 사용한 데이터는 대개 Amazon Redshift와 같은 데이터 웨어하우스에 저장되는데, 이는 안타깝게도 자연어 상호작용 대신 SQL을 통한 프로그래밍 방식 액세스에 최적화되어 있는 경우가 많았습니다. 게다가 당연하겠지만, BI 팀은 대시보드 작성자, BI 엔지니어, 기타 데이터 팀에서 사용하도록 데이터 소스를 최적화하는 경향이 있어, 대시보드에 최적화된 기술적 이름 지정 규약(예: ‘Customer’ 대신 ‘CUST_ID’)과 SQL 쿼리를 사용합니다. 이런 기술적 이름 지정 규약은 비즈니스 사용자가 사용하기에는 직관적이지 않습니다.
BI 팀은 이 문제를 해결하기 위해 기술적 이름을 일반적으로 사용하는 비즈니스 언어 이름으로 직접 변환하고, 자연어 질문에 답할 수 있도록 데이터를 준비하는 데 오랜 시간을 소모합니다.
오늘은 Amazon QuickSight Q를 위한 자동 데이터 준비 기능의 출시 소식을 기쁜 마음으로 전해드립니다. 자동화된 데이터 준비는 기계 학습을 사용하여 데이터에 대한 시맨틱 정보를 추론하고, 열(필드)에 대한 메타데이터로 이를 데이터 세트에 추가함으로써, 자연어 질문을 지원하기 위해 데이터를 준비하는 시간을 단축해줍니다.
QuickSight Q 주제에 대한 간단한 개요
QuickSight Q가 출시되면서 주제를 사용할 수 있게 되었습니다. 주제는 비즈니스 사용자가 질문을 하는 하위 분야를 나타내는 하나 이상의 데이터 세트 모음입니다. 앞서 언급한 예시(‘2021년 EMEA에서 가장 높은 매출을 올린 사람’)의 경우, 이 주제를 생성하는 동안 하나 이상의 데이터 세트(예: Sales/Regional Sales 데이터 세트)가 선택됩니다.
주제가 생성되고 나면 작성자는 다음과 같은 상황에 처합니다.
- 데이터 세트에서 가장 관련이 깊은 열을 선택하여 주제에 추가하는 작업에 시간을 보냅니다(예: time_stamp, date_stamp 열 등을 제거). 대시보드와 보고서에서 열의 사용량 데이터를 알 수 없어서 어떤 열이 비즈니스 사용자와 가장 관련이 깊고 주제에 포함하기에 적절한지 객관적으로 판단하기가 어렵기 때문에 이 작업이 까다롭습니다.
- 그런 다음에는 몇 시간에 걸쳐 데이터를 검토하고 자연어에 맞는 구성을 설정하도록 수동으로 큐레이션해야 합니다(예: ‘Area’를 ‘Region’ 열의 동의어로 추가).
- 마지막으로, 데이터를 표시했을 때 더욱 유용하게 사용할 수 있도록 데이터 서식을 지정하는 데 시간을 소모하게 됩니다.
-

QuickSight Q 주제
Amazon QuickSight Q의 자동 데이터 준비 사용 방법
분석에서 생성: Amazon QuickSight Q를 위한 새로운 자동화된 데이터 준비는 분석에서 주제를 생성하는 시간을 절약하고, 해당 데이터 필드에 대한 동의어와 공통적인 용어를 찾는 ML 훈련 모델을 기반으로 사용자에게 친숙한 이름과 동의어를 자동으로 선택하는 방법으로 모든 변환을 처리하는 데 걸리는 시간을 아낄 수 있습니다. 또한, 가장 관련이 깊은 열을 사용자가 직접 선택할 필요 없이 Amazon QuickSight Q를 위한 자동화된 데이터 준비 기능이 분석에서 사용된 양상에 따라 가치가 높은 열을 자동 선택합니다. 그런 다음, 주제를 기준 분석의 데이터 세트에 결합하고 데이터 내에서 자연어 검색을 지원하는 고유한 문자열 값 색인을 작성합니다.
자동화된 필드 선택 및 분류: 앞서 말씀드렸듯이 Amazon QuickSight Q를 위한 자동화된 데이터 준비는 가치가 높은 열을 선택하지만 어떤 열이 가치가 높은지는 어떻게 알 수 있을까요? Amazon QuickSight Q를 위한 자동화된 데이터 준비는 기존 QuickSight 자산(예: 보고서, 대시보드)의 신호에 기반하여 열 선택을 자동화하고, 비즈니스 사용자와 관련이 깊은 주제를 만드는 데 도움을 줍니다. Amazon QuickSight Q를 위한 자동화된 데이터 준비는 데이터 세트에서 가치가 높은 필드를 선택할 뿐만 아니라, 작성자가 분석에서 생성한 새로운 계산된 필드를 가져오므로 이를 주제에서 다시 생성할 필요가 없습니다.
자동화된 언어 설정: 이 문서를 시작하면서 기술적 이름 지정 규약이 비즈니스 사용자에게 직관적이지 않다는 점을 말씀드렸습니다. 이제 이런 기술적 이름에 시간을 쏟을 필요 없이 공통적인 용어를 사용하여 이런 열 이름이 친숙한 이름과 동의어로 자동 업데이트됩니다. Sales 데이터 세트 예시의 경우 CUST_ID가 친숙한 이름인 ‘Customer’ 및 여러 개의 동의어로 할당되었습니다. 이제 동의어는 (추가적인 맞춤 설정 옵션과 함께) 자동으로 열에 추가되고, 비즈니스 사용자와 관련이 있을 만한 다양한 어휘를 지원합니다.

열에 사용하기 위한 친숙한 이름 및 동의어
자동화된 메타데이터 설정: Amazon QuickSight Q를 위한 자동화된 데이터 준비는 열 값에 따라 열의 시맨틱 유형(Semantic Type)을 탐지하고, 해당 구성을 자동으로 업데이트합니다. 이제 특정 열이 답변에 표시될 경우에 사용할 값 형식이 설정됩니다. 이러한 형식은 분석에서 정의한 형식에서 파생됩니다.
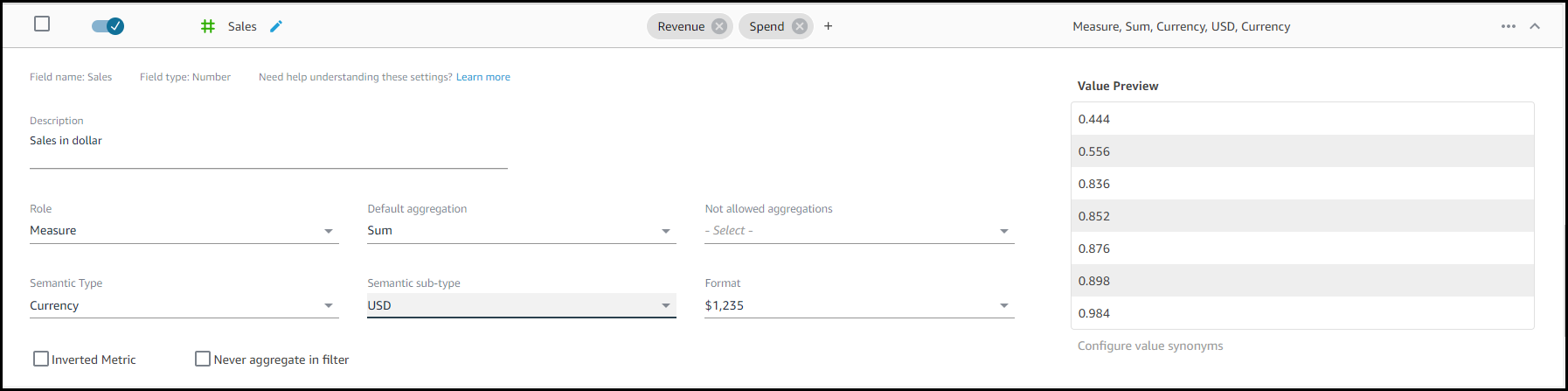
시맨틱 유형 설정
지금 이용 가능
현재 Amazon QuickSight Q를 위한 자동화된 데이터 준비는 QuickSight Q를 제공하는 모든 AWS 리전에 제공됩니다. 자세한 내용은 Amazon QuickSight Q 페이지를 방문하세요. QuickSight 커뮤니티에 참여하여 다른 사람에게 질문하고 배우고, 다른 사람의 질문에 답해 보세요.
– Veliswa x