Amazon Web Services 한국 블로그
Amazon SageMaker 출시 – 기계 학습 기반 서비스 가속화
기계 학습(Machine Learning)은 많은 스타트업 및 대기업을 위한 중추적 기술입니다. 수십 년간의 투자와 발전에도 불구하고 기계 학습 모델을 개발 및 학습하고 유지하는 것은 여전히 다루기 힘들고 까다로운 일입니다. 일반적으로 기계 학습을 애플리케이션에 통합하는 프로세스에는 전문가 팀이 수개월 동안 불일치 설정을 조정하고 수정하는 과정이 포함됩니다. 기업과 개발자들이 원하는 것은 개발부터 실제 운영까지의 총체적인 파이프라인입니다.
Amazon SageMaker 소개
Amazon SageMaker는 데이터 과학자, 개발자, 기계 학습 전문가가 모든 규모의 기계 학습 모델을 간편하게 만들어 학습 및 배포할 수 있는 총체적인 종합 관리형 서비스입니다. 이 서비스는 기계 학습을 위한 모든 작업의 능률을 대폭 높여 주므로 기계 학습을 실제 운영 애플리케이션에 신속하게 추가할 수 있습니다.
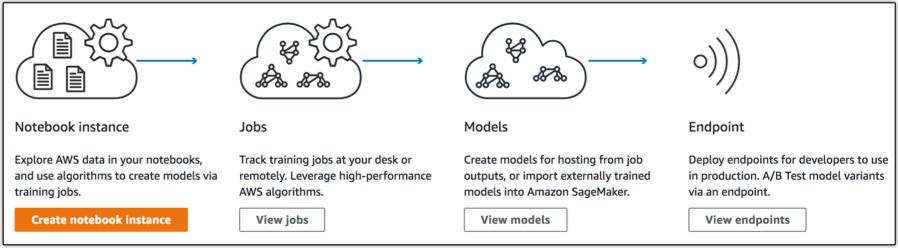
Amazon SageMaker의 3가지 주요 구성 요소는 다음과 같습니다.
- 노트북 기반 코딩: 설정 작업이 필요 없는 호스팅형 Jupyter 노트북 IDE로서, 데이터 탐색, 정리 및 사전 처리를 수행합니다. 이러한 IDE를 일반 인스턴스 유형이나 GPU 구동 인스턴스에서 실행할 수 있습니다.
- 모델 학습: 배포된 모듈 구축, 학습 및 확인 서비스. 기본으로 제공되는 지도(supervised) 및 비지도(unsupervised) 학습 알고리즘과 프레임워크를 사용하거나, 도커 컨테이너를 사용하여 학습을 직접 만들 수 있습니다. 이 학습은 모델 구축 속도를 높이기 위해 수십 개의 인스턴스로 확장할 수 있습니다. 학습 데이터를 S3에서 읽어와서 모델 결과물이 S3에 저장됩니다. 이 모델 결과물은 데이터에 종속된 모델 파라미터이며, 모델에서 추론할 수 있는 코드가 아닙니다. 이렇게 구분되기 때문에 Amazon SageMaker 학습 모델을 IoT 디바이스 같은 다른 플랫폼에 쉽게 배포할 수 있습니다.
- 모델 호스팅: 모델을 호출하여 실시간 추론을 받기 위한 HTTPs 엔드포인트 모델 호스팅 서비스. 이러한 엔드포인트는 트래픽을 지원하도록 확장할 수 있으며 여러 모델에 대해 동시에 A/B 테스트를 수행할 수 있습니다. 또한 기본 제공되는 SDK를 사용하여 이러한 엔드포인트를 생성하거나, 도커 이미지를 사용하여 구성을 직접 제공할 수 있습니다.
이러한 구성 요소를 별개로 사용할 수 있기 때문에 Amazon SageMaker를 사용하면 기존 파이프라인의 공백을 쉽게 채울 수 있습니다. 즉, 서비스를 전체적으로 이용할 때 사용할 수 있는 몇 가지 강력한 기능이 있습니다.
SageMaker 사용
Apache MXNet 기반 이미지 분류자를 만들어 학습하고 배포하려 합니다. Gluon 언어, CIFAR-10 데이터 세트, ResNet V2 모델 아키텍처를 사용하겠습니다.
Jupyter 노트북을 사용하여 저작

노트북 인스턴스를 만들 경우 이 인스턴스는 딥 러닝에서 일반적인 Anaconda 패키지 및 라이브러리와 함께 제공된 ML 컴퓨팅 인스턴스를 실행하고, 5GB ML 스토리지 볼륨 및 다양한 알고리즘을 보여주는 몇 가지 예제 노트북을 실행합니다. 리소스에 간편하고 안전하게 액세스할 수 있도록 하기 위해 VPC에 ENI를 생성하는 VPC 지원을 선택적으로 구성할 수도 있습니다.
인스턴스가 프로비저닝되면 노트북을 열고 코드 작성을 시작할 수 있습니다.

모델 학습
간결하게 하기 위해 여기서는 실제 모델 학습 코드를 생략할 것이지만, 일반적으로 모든 종류의 Amazon SageMaker 공통 프레임워크 학습의 경우 다음과 같은 간단한 학습 인터페이스를 구현할 수 있습니다.
def train(
channel_input_dirs, hyperparameters, output_data_dir,
model_dir, num_gpus, hosts, current_host):
pass
def save(model):
passAmazon SageMaker 인프라의 ml.p2.xlarge 인스턴스 4개에 배포된 학습 작업을 생성하려고 합니다. 로컬에 필요한 모든 데이터를 이미 다운로드했습니다.
import sagemaker
from sagemaker.mxnet import MXNet
m = MXNet("cifar10.py", role=role,
train_instance_count=4, train_instance_type="ml.p2.xlarge",
hyperparameters={'batch_size': 128, 'epochs': 50,
'learning_rate': 0.1, 'momentum': 0.9})모델 학습 작업을 만들었으므로 이제 다음을 호출하여 데이터를 제공할 수 있습니다. m.fit("s3://randall-likes-sagemaker/data/gluon-cifar10").
작업 콘솔로 이동하면 작업이 실행 중임을 볼 수 있습니다.

호스팅 및 실시간 추론
모델 학습이 완료되었으므로 이제 예측 생성을 시작할 수 있습니다. 위와 동일한 코드를 사용하여 엔드포인트를 만들고 실행하겠습니다.
predictor = m.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge')
그런 다음 엔드포인트를 호출하는 것은 실행하는 것만큼 간단합니다. predictor.predict(img_input)!
100줄도 안 되는 코드에 기계 학습 파이프라인이 완성되었습니다.
이제 Amazon SageMaker의 모델 호스팅 구성 요소를 어떻게 사용할 수 있는지를 보여주는 예제를 한 가지 더 살펴보겠습니다.
사용자 지정 도커 컨테이너 사용
Amazon SageMaker는 학습 알고리즘이나 추론 컨테이너를 직접 쉽게 작성할 수 있는 도커 컨테이너용의 간단한 사양을 정의합니다.
여기에서 설명한 아키텍처를 기반으로 하는 기존 모델이 있으며, 실시간 추론을 위해 이 모델을 호스팅하려고 합니다.
추론을 수행할 간단한 Dockerfile과 flask 앱을 만들었습니다.
모델을 불러와 예측을 생성하는 코드는 각각 다를 것이기 때문에 여기서는 생략했습니다. 기본적으로, 입력 URL에서 이미지를 다운로드하여 이 이미지 데이터를 예측용 MXNet 모델에 전달하는 메서드를 만들었습니다.
from flask import Flask, request, jsonify
import predict
app = Flask(__name__)
@app.route('/ping')
def ping():
return ("", 200)
@app.route('/invocations', methods=["POST"])
def invoke():
data = request.get_json(force=True)
return jsonify(predict.download_and_predict(data['url']))
if __name__ == '__main__':
app.run(port=8080)FROM mxnet/python:latest
WORKDIR /app
COPY *.py /app/
COPY models /app/models
RUN pip install -U numpy flask scikit-image
ENTRYPOINT ["python", "app.py"]
EXPOSE 8080이 이미지를 ECR에 넣은 후 Amazon SageMaker의 모델 콘솔로 이동하여 새 모델을 만듭니다.

새 모델을 만든 후 엔드포인트도 할당하겠습니다.

이제 AWS Lambda 또는 다른 애플리케이션에서 직접 엔드포인트를 호출할 수 있습니다. 트위터 계정을 설정하여 이 모델을 공개하고 있습니다. 이 모델이 위치를 추정할 수 있는지 보려면 @WhereML에 사진을 트윗해 보십시오.
import boto3
import json
sagemaker = boto3.client('sagemaker-runtime')
data = {'url': 'https://pbs.twimg.com/media/DPwe4kMUMAAWCd_.jpg'}
result = sagemaker.invoke_endpoint(
EndpointName='predict',
Body=json.dumps(data)
)
사용 요금
AWS 프리 티어를 사용하는 고객은 Amazon SageMaker를 무료로 시작할 수 있습니다. 첫 두 달 동안은 매달 250시간의 t2.medium 노트북 사용량, 학습을 위한 50시간의 m4.xlarge 사용량, 호스팅을 위한 125시간의 m4.xlarge 사용량이 제공됩니다. 프리 티어 후에는 리전별로 요금이 다르지만 초 단위 인스턴스 사용량, GB 기준 스토리지 사용량, GB 기준 데이터 전송량(서비스 송수신)으로 청구됩니다.
올해 re:Invent를 위한 블로그 게시물을 작성하기 전에는 최고를 선택하지 말라고 Jeff가 그러더군요. 맞는 말이었습니다. 정말 대단한 몇 가지 출시 중에서도 Amazon SageMaker는 제게 있어 re:Invent 2017의 최고 서비스입니다. 우리 고객들이 이렇게 놀라운 도구를 사용하여 어떤 것을 수행해 낼 수 있을지 정말 기대됩니다.
– Randall;
이 글은 AWS re:Invent 2017의 신규 서비스로서 Amazon SageMaker – Accelerating Machine Learning의 한국어 번역입니다.