Guidance for Dynamic Non-Player Character (NPC) Dialogue on AWS
Overview
How it works
Overview
This architecture diagram shows an overview workflow for hosting a generative AI NPC on AWS.
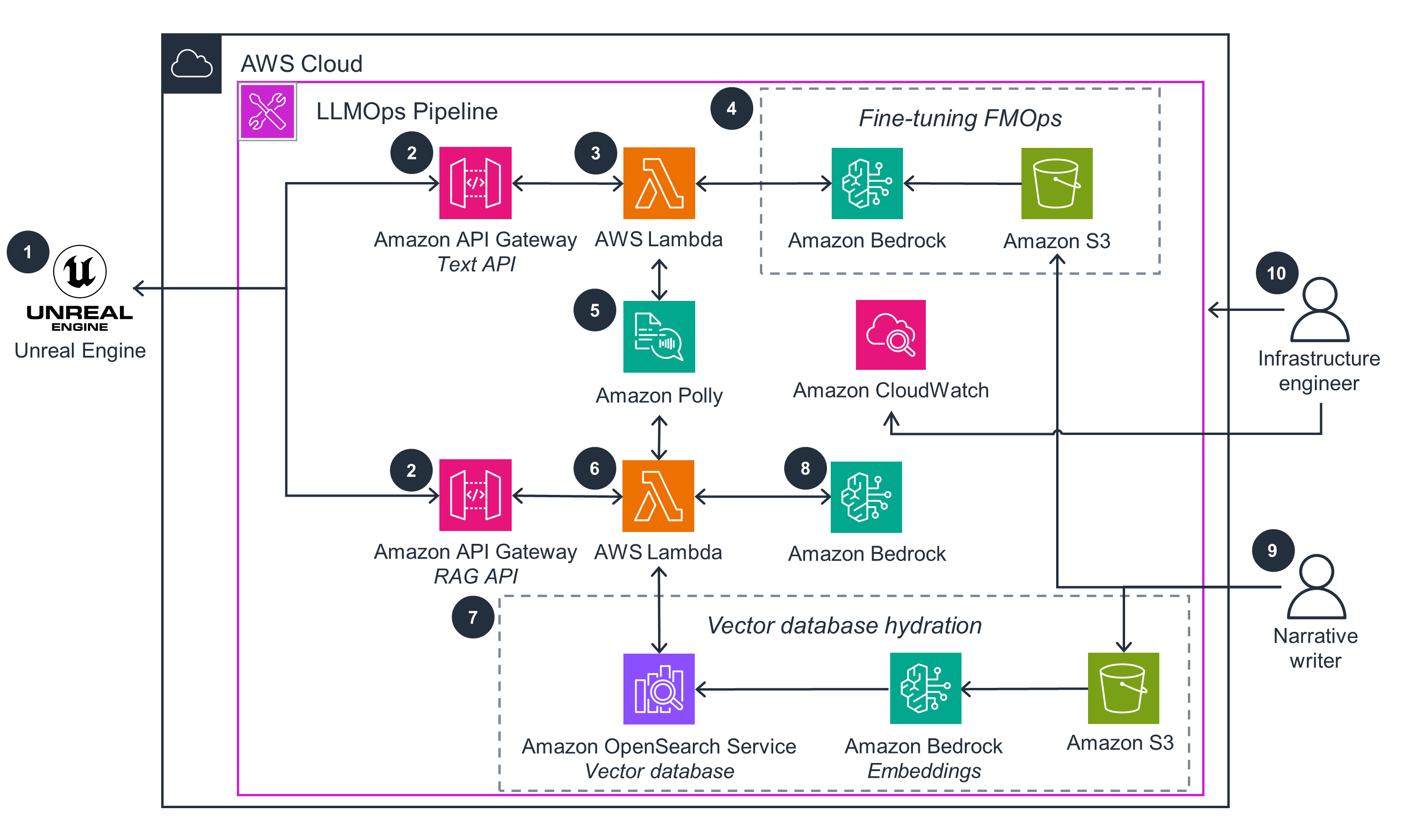
LLMOps Pipeline
This architecture diagram shows the processes of deploying an LLMOps pipeline on AWS.
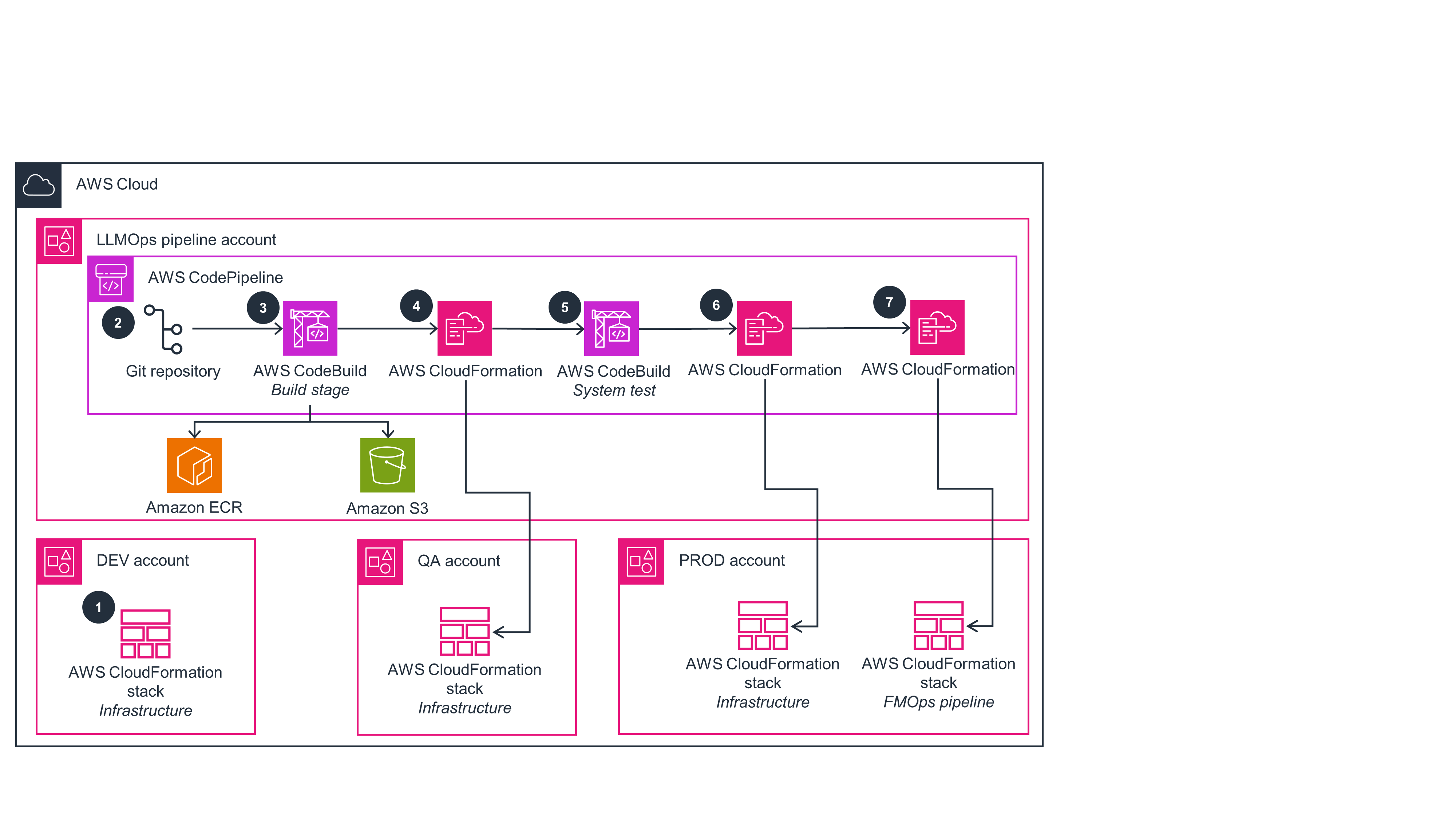
FMOps Pipeline
This architecture diagram shows the process of tuning a generative AI model using FMOps.
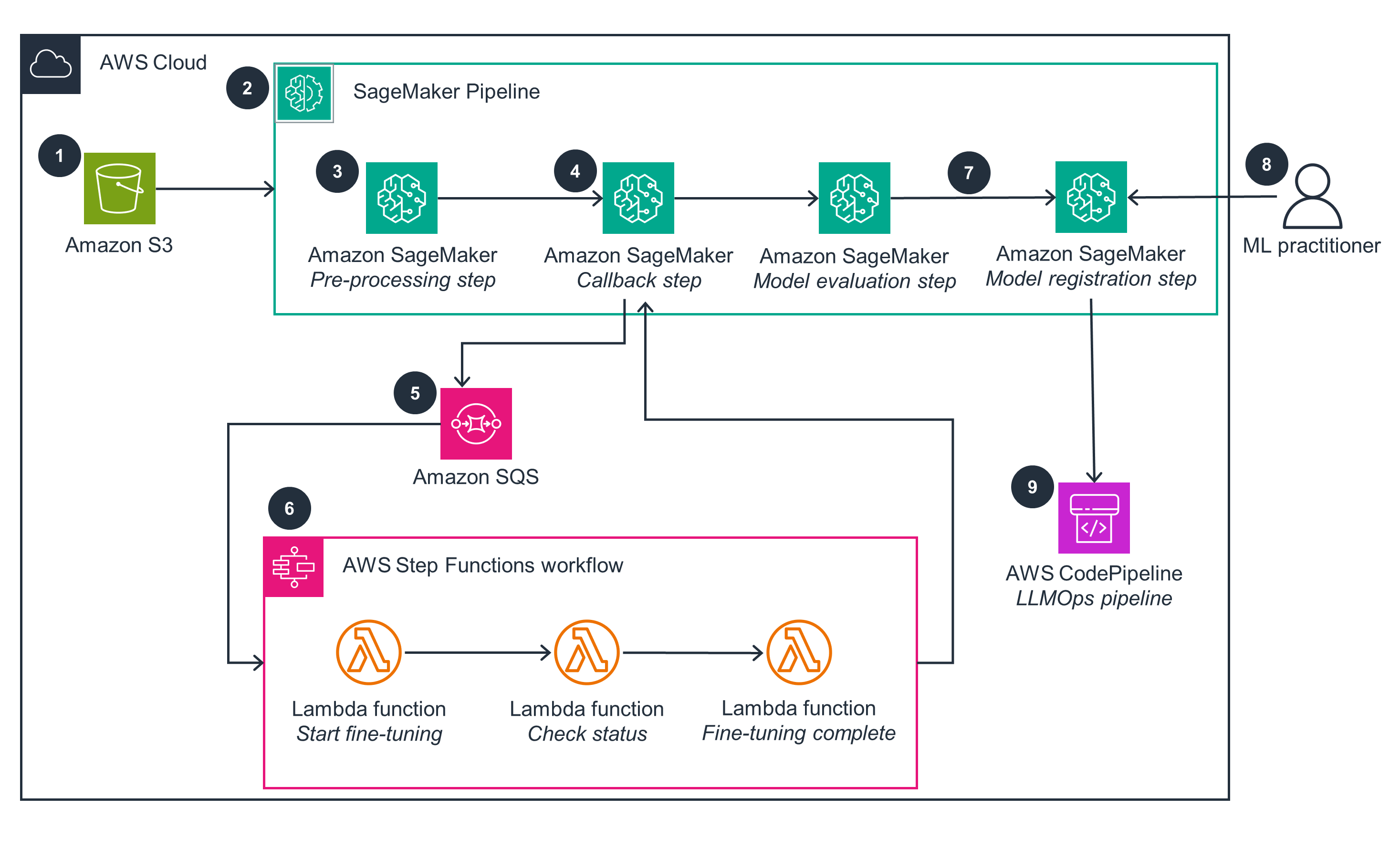
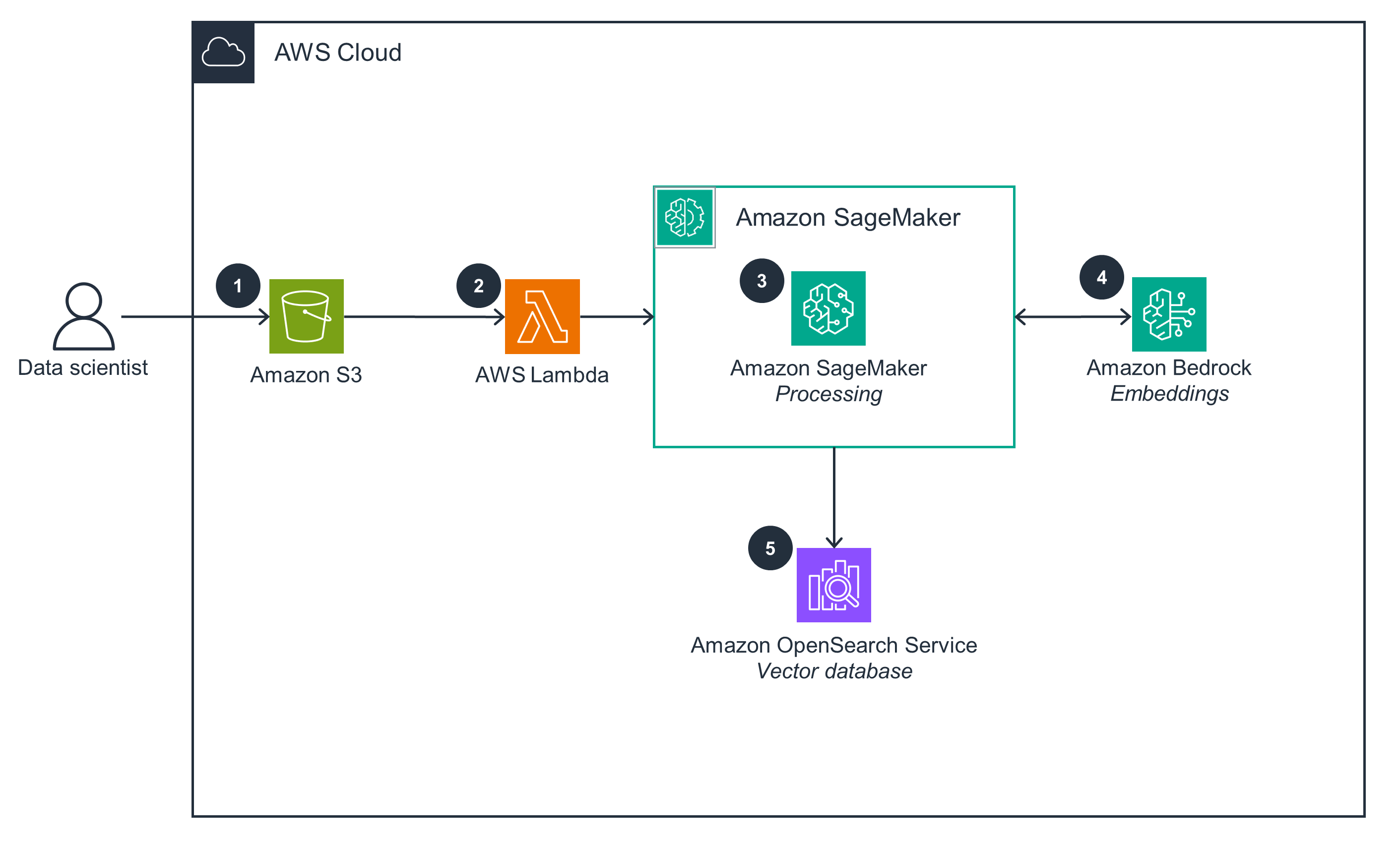
Database Hydration
This architecture diagram shows the process for database hydration by vectorizing and storing gamer lore for RAG.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
This Guidance uses Lambda, API Gateway, and CloudWatch to track all API requests for generated NPC dialogue between the Unreal Engine client and the Amazon Bedrock foundation model. This provides end-to-end visibility into the status of the Guidance, allowing you to granularly track each request and response from the game client so you can quickly identify issues and react accordingly. Additionally, this Guidance is codified as a CDK application using CodePipeline,sooperations teams and developers can address faults and bugs through appropriate change control methodologies and quickly deploy these updates or fixes using the CI/CD pipeline.
Amazon S3 provides encrypted protection for storing game lore documentation at rest in addition to encrypted access for data in transit, while ingesting game lore documentation into the vector or fine-tuning an Amazon Bedrock foundation model. API Gateway adds an additional layer of security between the Unreal Engine and the Amazon Bedrock foundation model by providing TLS-based encryption of all data between the NPC and the model. Lastly, Amazon Bedrock implements automated abuse detection mechanisms to further identify and mitigate violations of the AWS Acceptable Use Policy and the AWS Responsible AI Policy.
API Gateway manages the automated scaling and throttling of requests by the NPC to the foundation model. Additionally, since the entire infrastructure is codified using CI/CD pipelines, you can provision resources across multiple AWS accounts and multiple AWS Regions in parallel. This enables multiple simultaneous infrastructure re-deployment scenarios to help you overcome AWS Region-level failures. As serverless infrastructure resources, API Gateway and Lambda allow you to focus on game development instead of manually managing resource allocation and usage patterns for API requests.
Serverless resources, such as Lambda and API Gateway, contribute to the efficiency of the Guidance by providing both elasticity and scalability. This allows the Guidance to dynamically adapt to an increase or decrease in API calls from the NPC client. An elastic and scalable approach helps you right-size resources for optimal performance and to address unforeseen increases or decreases in API requests—without having to manually manage provisioned infrastructure resources.
Codifying the Guidance as a CDK application provides game developers with the ability to quickly prototype and deploy their NPC characters into production. Amazon Bedrock gives developers quick access to foundation models hosted on Amazon Bedrock through an API Gateway REST API without having to engineer, build, and pre-train them. Turning around quick prototypes helps reduce the time and operations costs associated with building foundation models from scratch.
Lambda provides a serverless, scalable, and event-driven approach without having to provision dedicated compute resources. Amazon S3 implements data lifecycle policies along with compression for all data across this Guidance, allowing for energy-efficient storage. Amazon Bedrock hosts foundation models on AWS silicon, offering better performance per watt of standard compute resources.
Implementation Resources
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages