请参阅以下示例
mysql> SELECT * INTO OUTFILE S3 's3-us-west-2://aws-sagemaker-aurora-bucket-1/churn.txt' FORMAT CSV HEADER FROM churn;
Query OK, 5001 rows affected (0.25 sec)
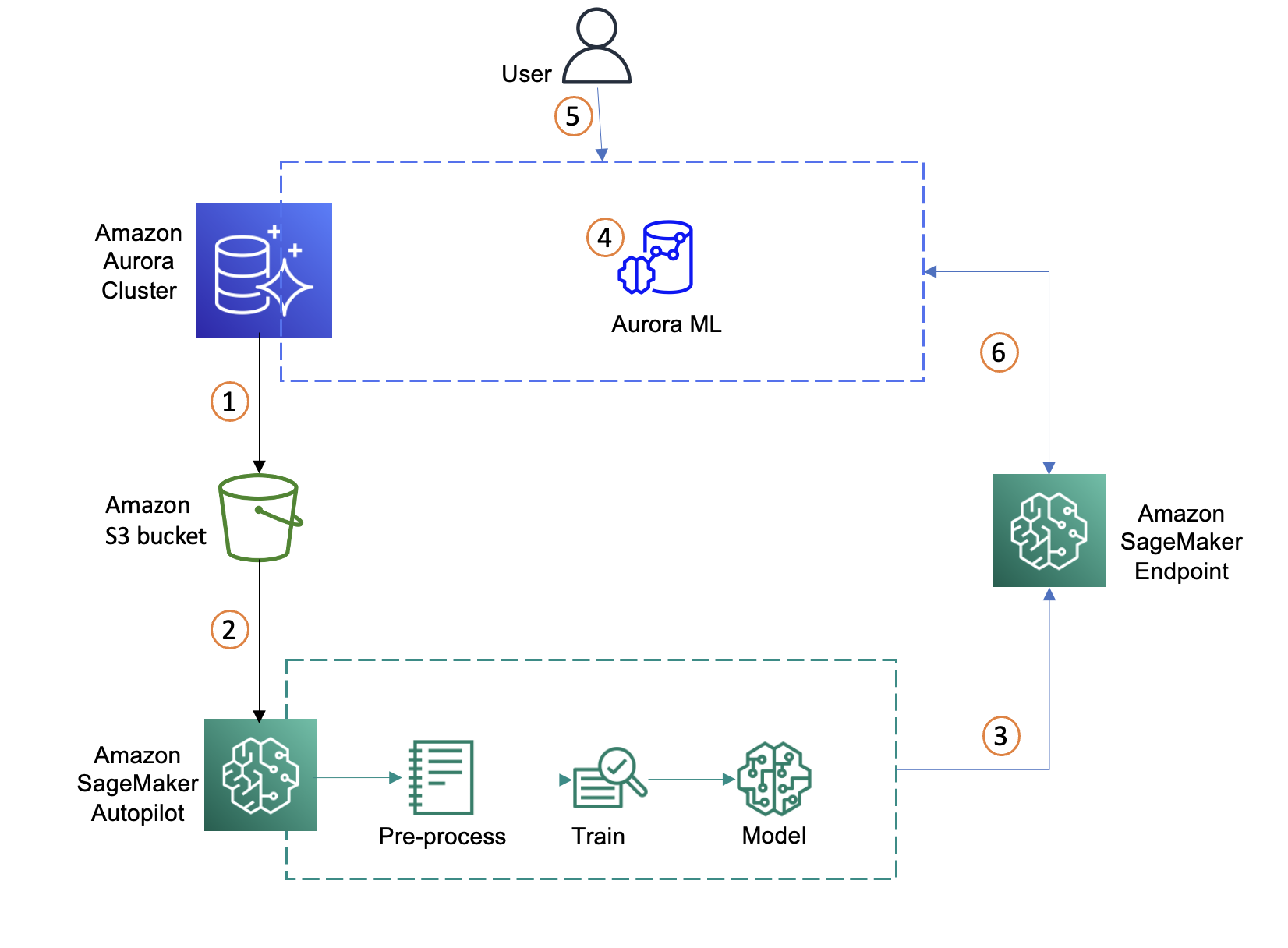
使用带导入数据集的 Autopilot 创建机器学习模型
现在,S3 存储桶中的数据已准备就绪,让我们向 Autopilot 提供数据的 S3 路径以创建和自动训练机器学习模型。
- 使用 Amazon SageMaker Studio 启动器启动 Autopilot。
- 创建 Autopilot 实验。
- 在 Experiment and data details(实验和数据详细信息)选项卡中提供所需的设置并从 Amazon S3 存储桶导入流失数据集。
 Autopilot 支持不同的训练模型和算法来解决机器学习问题。
Autopilot 支持不同的训练模型和算法来解决机器学习问题。
- 在 Training Method(训练方法)选项卡上,选择 Auto(自动),这将允许 Autopilot 根据您的数据集大小选择集成或超参数优化(HPO)。

- 在 Deployment and Advanced settings(部署和高级设置)选项卡上,您可以选择 Auto deploy(自动部署)来自动部署 SageMaker 端点。
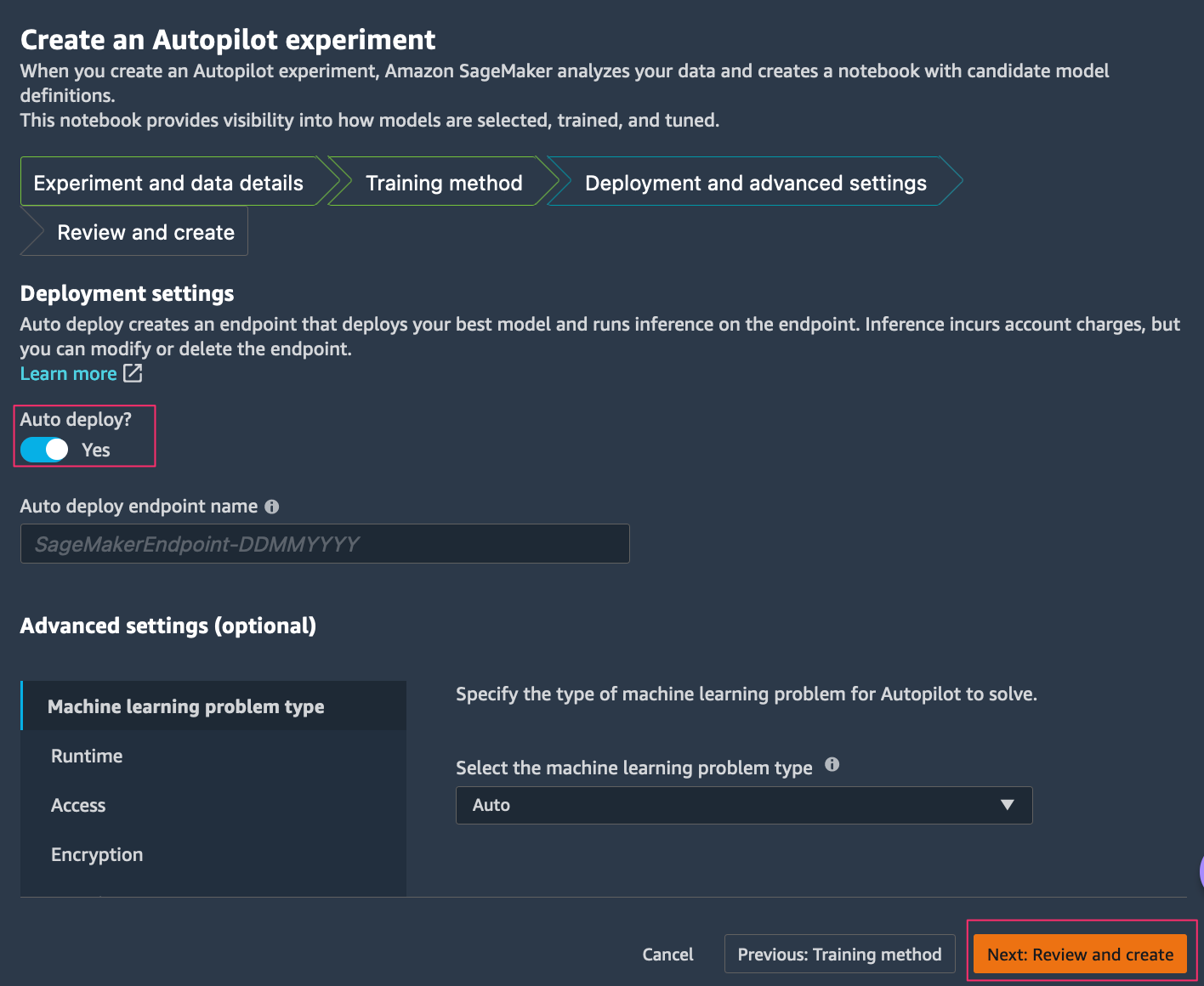
- 在 Review and create(查看并创建)选项卡上,查看您提供的所有设置,然后选择 Create experiment(创建实验)。
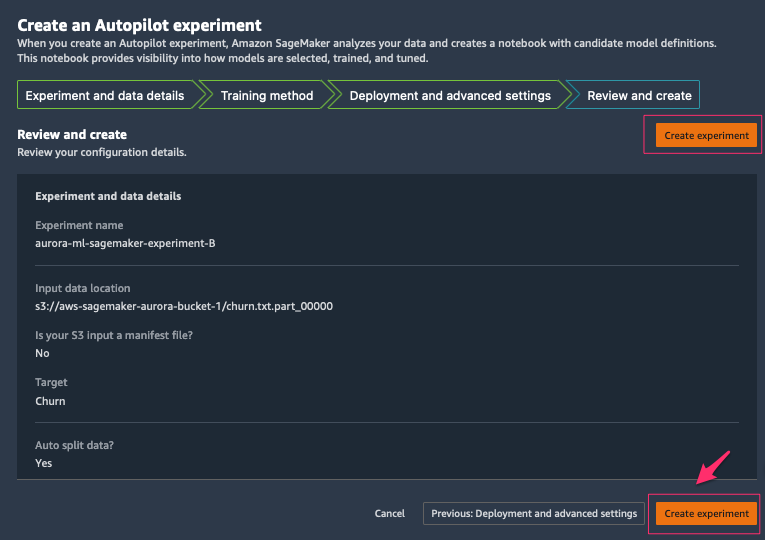
在 Autopilot 开始实验后,该服务会自动检查原始输入数据,应用特征处理器并选取最佳潜在算法。在该服务选择算法后,Autopilot 会使用超参数优化搜索过程来优化其性能。这通常称为训练和调整模型。最终,这将帮助生成一个模型,该模型能够准确地预测从未见过的数据。Autopilot 自动跟踪模型性能,然后根据机器学习问题的类型,按准确度、F1 分数、精度和召回率等指标对最终模型进行排名。在此情况下,我们重点关注 F1 分数,因为我们要对客户是否丢失进行分类(二进制分类)。
选择最佳的机器学习模型并部署 SageMaker 端点
如果您在上一步中没有选择 Auto deploy(自动部署)选项,则可以选择部署任意已排名的模型。您可以通过选择模型(右键单击)并选择 Deploy model(部署模型),或通过在排名列表中选择最佳模型并选择 Deploy model(部署模型)来完成此操作。
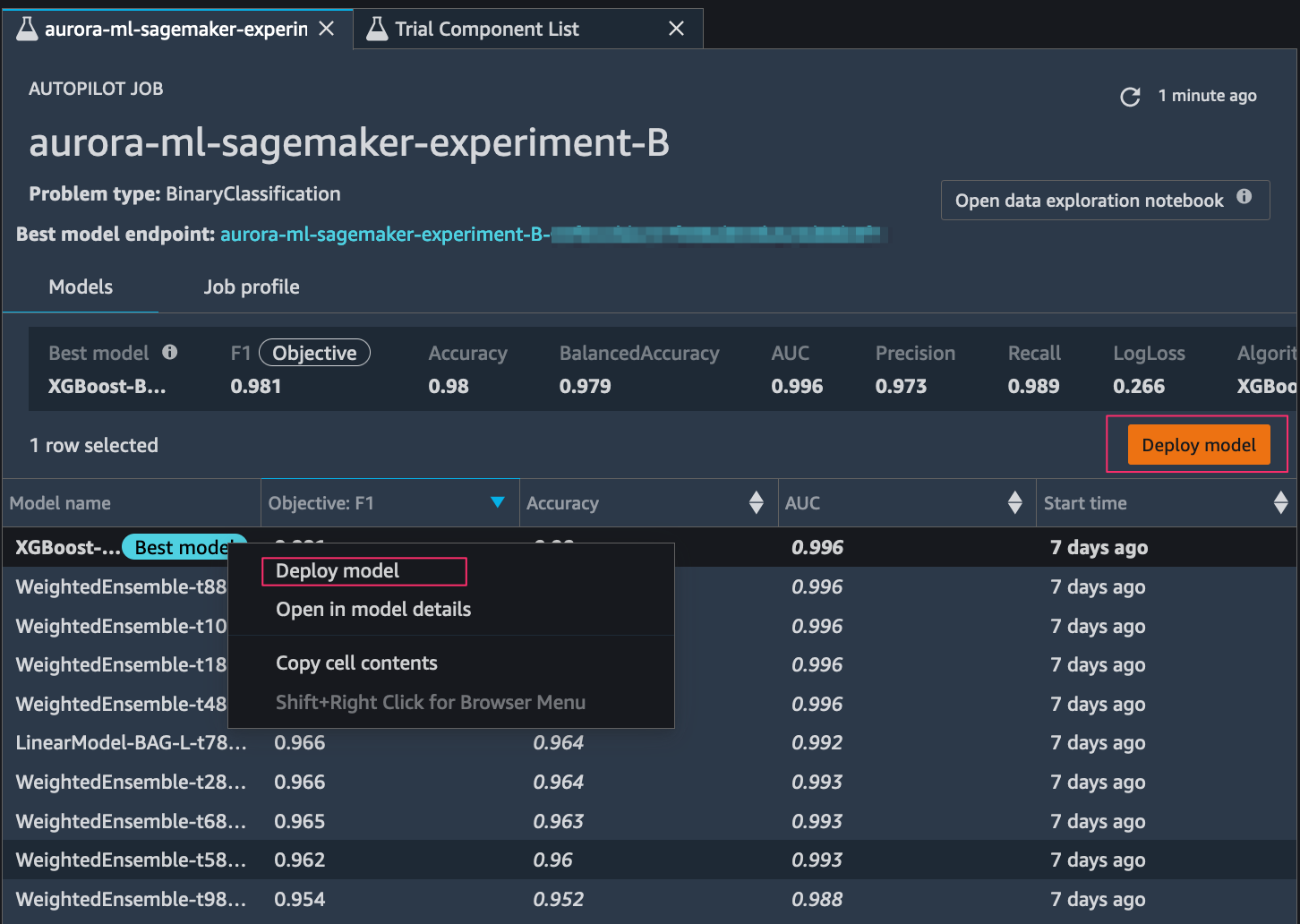
在我们设置模型端点之后,下一步是将 Aurora 与 SageMaker 端点集成,以使用 SQL 命令推断数据集中的客户流失情况。
将 Aurora 与 SageMaker 集成
Aurora 可以直接安全地调用 SageMaker,而无需通过应用程序层。我们需要先通过配置 AWS Identity and Access Management(IAM)角色来使 Aurora MySQL 集群能够访问 AWS ML,之后才能通过 Aurora 访问 SageMaker。有关更多信息,请参阅设置对 SageMaker 的 IAM 访问。此角色向我们的 Aurora MySQL 数据库的用户授予对 AWS ML 服务的访问权限。
要设置 Aurora 与 SageMaker 的集成,请完成以下步骤:
- 创建 IAM policy。
以下策略添加 Aurora MySQL 代表我们调用 SageMaker 函数所需的权限。我们可以在单个策略中指定要从 Aurora MySQL 集群访问的所有 SageMaker 端点。该策略还允许我们为 SageMaker 端点指定 AWS 区域。但是,Aurora MySQL 集群只能调用已在与集群相同的区域中部署的 SageMaker 模型。将区域、AWS 账户 ID 和 SageMaker 端点名称添加到策略中。将以下策略保存到 JSON 文件中。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAuroraToInvokeRCFEndPoint",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource": "arn:aws:sagemaker:region:123456789012:endpoint/endpointName"
}
]
}
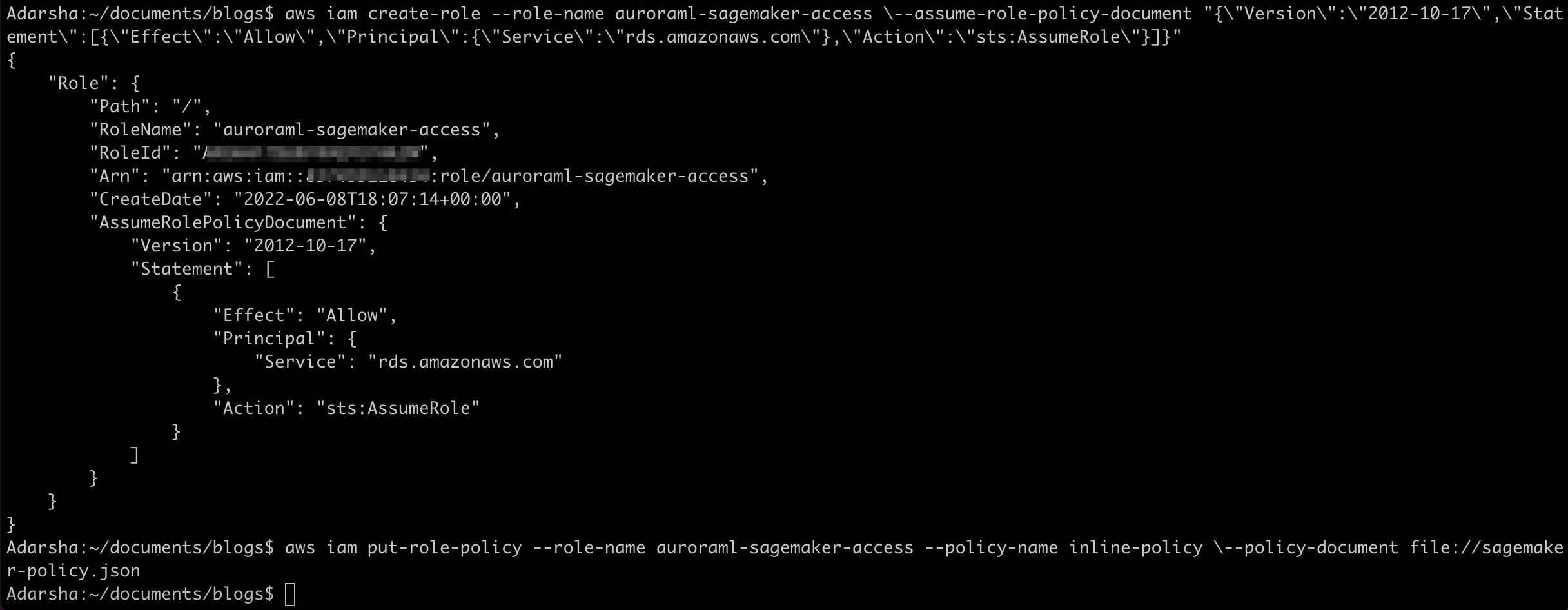
- 我们在创建 IAM policy 后,创建一个 IAM 角色,Aurora MySQL 集群可以代表我们的数据库用户代入该角色来访问 ML 服务。以下 create-role 命令创建一个名为
auroraml-sagemaker-access 的角色:
aws iam create-role \
--role-name auroraml-sagemaker-access \
--assume-role-policy-document "{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"rds.amazonaws.com\"},\"Action\":\"sts:AssumeRole\"}]}"
- 运行以下命令,将我们创建的策略附加到新角色:
aws iam put-role-policy \
--role-name auroraml-sagemaker-access --policy-name inline-policy \
--policy-document file://sagemaker-policy.json
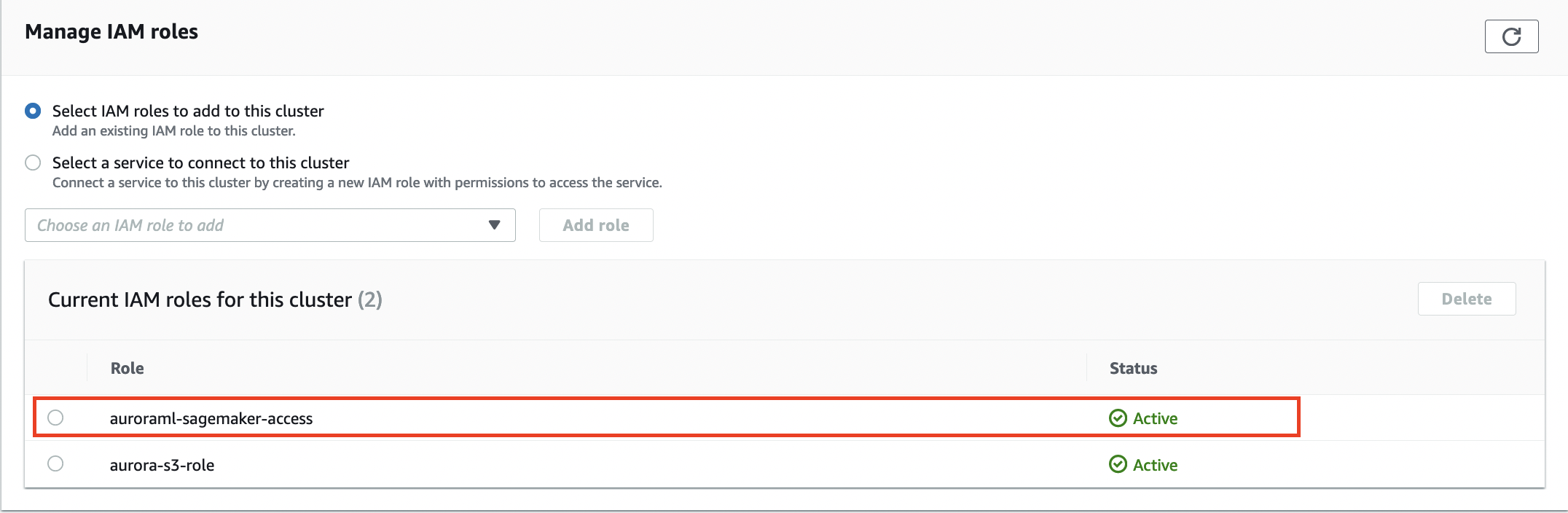
- 将 IAM 角色与 Aurora 数据库集群关联:
aws rds add-role-to-db-cluster \
--db-cluster-identifier database-aurora-ml \
--role-arn $(aws iam list-roles --query 'Roles[?RoleName==`auroraml-sagemaker-access`].Arn' --output text)
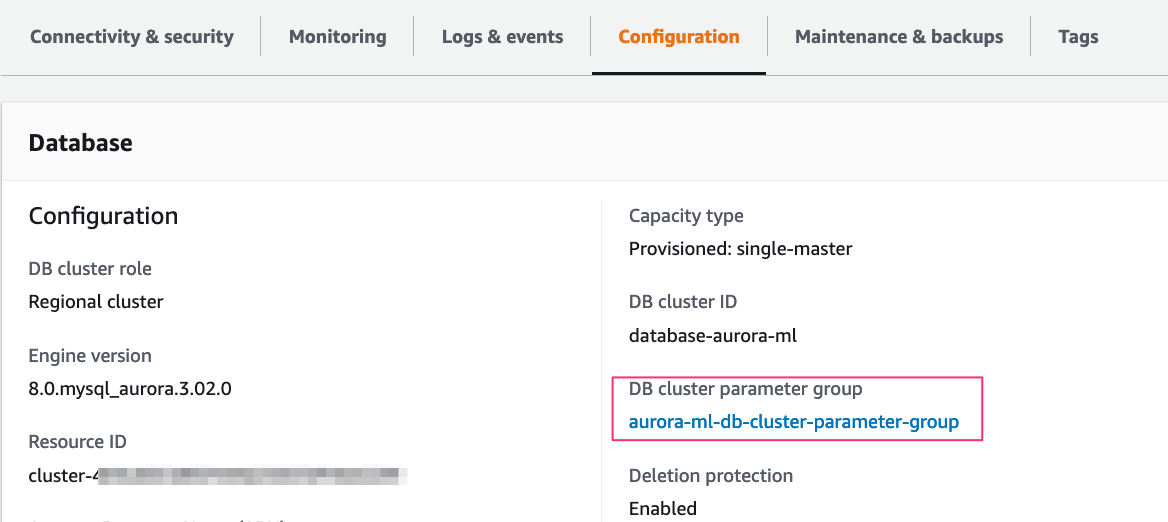
- 创建自定义数据库集群参数组,以允许数据库用户通过 aws_default_sagemaker_role 参数访问 SageMaker 端点。
aws rds create-db-cluster-parameter-group \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group \
--db-parameter-group-family aurora-mysql8.0 \
--description "My Aurora ML cluster parameter group"
- 将我们创建的自定义集群参数组
aurora-ml-db-cluster-parameter-group 附加到 Aurora 集群:
aws rds modify-db-cluster \
--db-cluster-identifier database-aurora-ml \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group
- 验证集群是否可用,然后将 IAM 角色
auroraml-sagemaker-access ARN 设置为自定义数据库集群参数组中的参数 aws_default_sagemaker_role,然后将其应用于集群。
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group \
--parameters "ParameterName=aws_default_sagemaker_role,ParameterValue=$(aws iam list-roles --query 'Roles[?RoleName==`auroraml-sagemaker-access`].Arn' --output text),ApplyMethod=pending-reboot"
如果首次附加自定义集群参数组,则需要手动重新启动集群中的所有节点。如果它是单节点集群,请重新启动写入器实例以应用更改。只有在我们手动重新启动每个关联的数据库集群中的数据库实例后,参数更改才会生效。由于我们附加的是自定义集群参数组 aurora-ml-db-cluster-parameter-group,因此,我们对多可用区集群执行失效转移,从而重新启动写入器和读取器节点。
- 对集群进行失效转移以应用自定义数据库集群参数组的更改:
aws rds failover-db-cluster --db-cluster-identifier database-aurora-ml
- 验证集群参数组是否已应用并显示同步状态。
aws rds describe-db-clusters \
--db-cluster-identifier <DB cluster identifier> \
--query 'DBClusters[*].DBClusterMembers'
请参阅以下示例:
aws rds describe-db-clusters --db-cluster-identifier database-aurora-ml --query 'DBClusters[*].DBClusterMembers'
[
[
{
"DBInstanceIdentifier": "reader",
"IsClusterWriter": false,
"DBClusterParameterGroupStatus": "in-sync",
"PromotionTier": 1
},
{
"DBInstanceIdentifier": "database-1-instance-1",
"IsClusterWriter": true,
"DBClusterParameterGroupStatus": "in-sync",
"PromotionTier": 1
}
]
]
使用 SageMaker 端点在 Aurora 中创建 SQL 函数
- 连接到 Aurora MySQL 集群并切换到我们之前创建的
mltest 数据库:
mysql> use mltest;
Database changed
- 使用您在上一步中创建的 SageMaker 端点,通过以下命令创建 SQL 函数:
CREATE FUNCTION `will_churn`(
state varchar(2048),
acc_length bigint(20),
area_code bigint(20),
phone varchar(1000),
int_plan varchar(2048),
vmail_plan varchar(2048),
vmail_msg bigint(20),
day_mins double,
day_calls bigint(20),
day_charge bigint(20),
eve_mins double,
eve_calls bigint(20),
eve_charge bigint(20),
night_mins double,
night_calls bigint(20),
night_charge bigint(20),
int_calls bigint(20),
int_charge bigint(20),
cust_service_calls bigint(20)
) RETURNS varchar(2048) CHARSET latin1
alias aws_sagemaker_invoke_endpoint
endpoint name '<SageMaker endpoint>';
使用 SQL 查询从 Aurora 调用 SageMaker 端点
现在我们已有一个链接回 SageMaker 端点的集成函数,数据库集群可以将值传递给 SageMaker 并检索推断。在以下示例中,我们将流失表中的值作为函数输入提交,以确定特定客户是否将流失。这将由 Will Churn? 列中的 True 或 False 结果表示。
mysql> SELECT will_churn('IN',65,415,'329-6603','no','no',0,129.1,137,21.95,228.5,83,
19.42,208.8,111,9.4,12.7,6,3.43,4) AS'Will Churn?';
+-------------+
| Will Churn? |
+-------------+
| False. |
+-------------+
1 row in set (0.06 sec)
mysql> SELECT c.state,c.acc_length,c.area_code, c.int_plan,c.phone, will_churn('c.state',c.acc_length,c.area_code,'c.int_plan','c.phone',
'c.vmail_plan',c.vmail_msg,c.day_mins,c.day_calls,c.day_charge,c.eve_mins,
c.eve_calls,c.eve_charge,c.night_mins,c.night_calls,c.night_charge,
c.int_mins,c.int_calls,c.int_charge,c.cust_service_calls) AS 'Will Churn?' from churn as c limit 5;
+-------+------------+-----------+----------+----------+-------------+
| state | acc_length | area_code | int_plan | phone | Will Churn? |
+-------+------------+-----------+----------+----------+-------------+
| OK | 112 | 415 | no | 327-1058 | False. |
| CO | 22 | 510 | no | 327-1319 | False. |
| AZ | 87 | 510 | no | 327-3053 | False. |
| UT | 103 | 510 | no | 327-3587 | True. |
| SD | 91 | 510 | no | 327-3850 | False. |
+-------+------------+-----------+----------+----------+-------------+
清理
此解决方案中涉及的服务会产生费用。使用完此解决方案后,请清理以下资源:
结论
在本博文中,我们已了解如何使用 Autopilot 构建客户流失机器学习模型,以及如何从 Aurora 集群调用 SageMaker 端点。现在,我们可以使用 SQL 实时从 SageMaker 端点获取机器学习推理。您可以在企业的客户保留活动中使用这些关于客户流失的推理。
请继续关注本系列的第 2 部分,在该部分中,我们将讨论如何实施 Aurora ML 性能优化,以便访问实时数据的模型推理。
关于作者
 Adarsha Kuthuru 是 Amazon Web Services 的数据库专家级解决方案架构师。她与客户合作,在 AWS Cloud 中设计可扩展、高度可用且安全的解决方案。工作之余,她喜欢画画、看书或在太平洋西北地区徒步。
Adarsha Kuthuru 是 Amazon Web Services 的数据库专家级解决方案架构师。她与客户合作,在 AWS Cloud 中设计可扩展、高度可用且安全的解决方案。工作之余,她喜欢画画、看书或在太平洋西北地区徒步。
 Mani Khanuja 是 Amazon Web Services(AWS)的人工智能和机器学习专家 SA。她帮助客户使用机器学习来解决他们在 AWS 方面的业务挑战。她将大部分时间花在深入研究和指导客户实施与计算机视觉、自然语言处理、预测、边缘机器学习等相关的人工智能/机器学习项目上。她热衷于边缘机器学习。她使用自动驾驶套件和原型制造生产线创建了自己的实验室,并在那里度过了很多空闲时间。
Mani Khanuja 是 Amazon Web Services(AWS)的人工智能和机器学习专家 SA。她帮助客户使用机器学习来解决他们在 AWS 方面的业务挑战。她将大部分时间花在深入研究和指导客户实施与计算机视觉、自然语言处理、预测、边缘机器学习等相关的人工智能/机器学习项目上。她热衷于边缘机器学习。她使用自动驾驶套件和原型制造生产线创建了自己的实验室,并在那里度过了很多空闲时间。