Businesses today want to enhance the data stored in their relational databases and incorporate up-to-the-minute predictions from machine learning (ML) models. However, most ML processing is done offline in separate systems, resulting in delays in receiving ML inferences for use in applications. AWS wants to make it efficient to incorporate real-time model inferences in your applications without any ML training.
We use two AWS services in this post. Amazon Aurora is a relational database management system (RDBMS) built for the cloud with MySQL and PostgreSQL compatibility. Aurora gives you the performance and availability of commercial-grade databases at one-tenth the cost.
Amazon SageMaker Autopilot is an automated machine learning (AutoML) solution that performs all the tasks you need to complete an end-to-end ML workflow. It explores and prepares your data, applies different algorithms to generate a model, and transparently provides model insights and explainability reports to help you interpret the results. Autopilot can also create a real-time endpoint for online inference. We can access Autopilot’s one-click features in Amazon SageMaker Studio or by using APIs, SDKs, or a command line interface.
Amazon Aurora machine learning (Aurora ML) is a feature of Aurora that enables you to add ML-based predictions to applications via the familiar SQL programming language without prior ML experience. It provides simple, optimized, and secure integration between Aurora and AWS ML services without having to build custom integrations or move data around. Aurora ML provides a faster and easier way to enable ML services to work with data in your Aurora database. Because Aurora makes direct calls to Amazon SageMaker, Aurora ML is suitable for low-latency, real-time use cases such as fraud detection, ad targeting, and product recommendations, where ML-based predictions need to be made quickly on large amounts of data.
In Part 1 of this series, we show you how you can build a customer churn ML model with Autopilot to generate accurate ML predictions on your own—without requiring any ML experience. We will show you how to invoke a SageMaker endpoint to predict customer churn using familiar SQL statements from Aurora cluster. These predictions can now be accessed with SQL just like any other data stored in Aurora. In Part 2, we discuss how to implement performance optimizations to get inferences on real-time data.
Overview of solution
In this post, we assume the role of a data analyst with SQL expertise working for a wireless provider. We’ve been tasked with identifying customers that are potentially at risk of leaving the service for a different provider (customer churn). We have access to aggregated and anonymized service usage and other customer behavior data stored in Aurora. We want to know if this data can help explain why a customer would leave. If we can identify factors that explain churn, then wireless providers can take corrective actions to change predicted behavior, such as running targeted retention campaigns.
We start with identifying data in the Aurora database, exporting it to Amazon Simple Storage Service (Amazon S3), and using the data to set up an Autopilot experiment in SageMaker to automatically process the data, train the customer churn model, and deploy model to an endpoint. We then create a function in Aurora to call the endpoint and generate predictions in real time from the Aurora database. The following diagram illustrates this workflow.
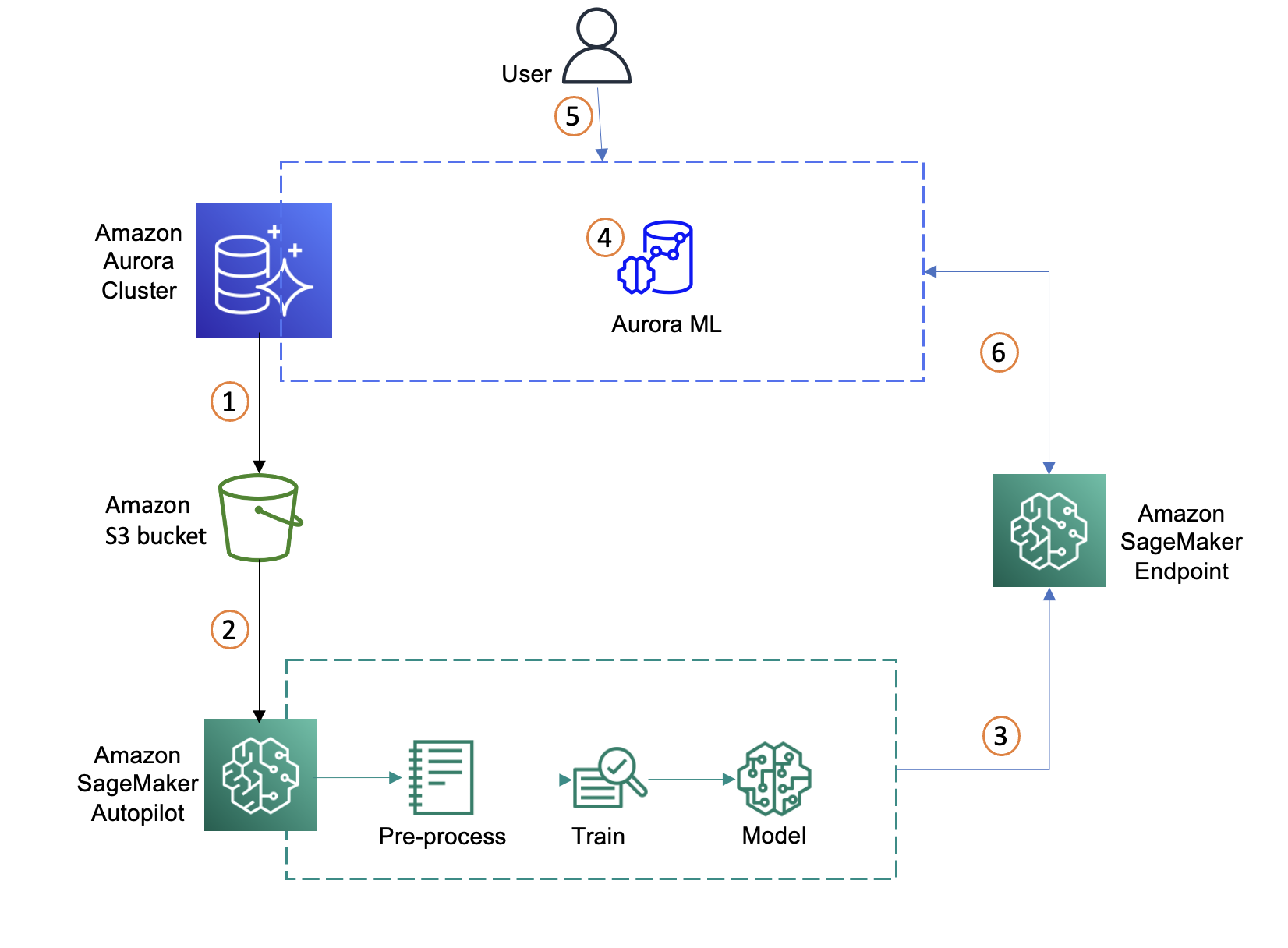
- Identify a dataset on the Aurora cluster and move data to S3 bucket
- Create an ML model using SageMaker Autopilot with the imported dataset
- Select the best ML model and deploy the SageMaker endpoint
- Integrate Aurora with SageMaker
- Create a SQL function using the SageMaker endpoint
- Invoke the SageMaker endpoint through SQL query
Identify a dataset on the Aurora cluster
If you have an existing dataset in the Aurora cluster that you wish to use as the basis for your model then you can consider connecting to Amazon SageMaker Data Wrangler to do some expert curation and feature engineering and then train a model with Autopilot to get accurate inferences. To use an existing dataset from your Aurora cluster, skip to the next section Move Aurora data to the S3 bucket.
If you want to use our test dataset that has already been preprocessed, the following steps show how to load a dataset into an Amazon Aurora MySQL-Compatible Edition cluster and then make it available for SageMaker to create an ML model. We can create an AWS Cloud9 instance or set up the AWS Command Line Interface (AWS CLI) to access the AWS resources. For more information, see Setting up AWS Cloud9 and Set Up the AWS Command Line Interface (AWS CLI), respectively. For this post, we use an AWS Cloud9 instance. For pricing refer to AWS Cloud9 Pricing.
Standard pricing will apply for all the AWS resources used. For Aurora database, you will be charged for I/Os, compute and storage. For full pricing refer to Amazon Aurora Pricing. You pay for storing objects in your S3 buckets and for the underlying compute and storage resources used by SageMaker Autopilot and the endpoint deployed. For full pricing refer to Amazon SageMaker Pricing.
Our Aurora cluster needs to be set up to use LOAD DATA FROM S3, then we run the following SQL queries to create the mltest database and a table with customer features (columns) to use for predicting customer churn.
- Connect to the Aurora MySQL cluster and following is a sample command:
mysql -h database-aurora-ml.cluster-xxxxxxx.us-west-2.rds.amazonaws.com -u admin -P 3306 -p
- Create a test database:
- Create a sample table to load data:
use mltest;
CREATE TABLE `churn` (
`state` varchar(2048) DEFAULT NULL,
`acc_length` bigint(20) DEFAULT NULL,
`area_code` bigint(20) DEFAULT NULL,
`int_plan` varchar(2048) DEFAULT NULL,
`phone` varchar(1000) NOT NULL,
`vmail_plan` varchar(2048) DEFAULT NULL,
`vmail_msg` bigint(20) DEFAULT NULL,
`day_mins` double DEFAULT NULL,
`day_calls` bigint(20) DEFAULT NULL,
`day_charge` bigint(20) DEFAULT NULL,
`eve_mins` double DEFAULT NULL,
`eve_calls` bigint(20) DEFAULT NULL,
`eve_charge` bigint(20) DEFAULT NULL,
`night_mins` double DEFAULT NULL,
`night_calls` bigint(20) DEFAULT NULL,
`night_charge` bigint(20) DEFAULT NULL,
`int_mins` double DEFAULT NULL,
`int_calls` bigint(20) DEFAULT NULL,
`int_charge` bigint(20) DEFAULT NULL,
`cust_service_calls` bigint(20) DEFAULT NULL,
`Churn` varchar(2048) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- Run LOAD DATA FROM S3 to load the data from the SageMaker sample S3 bucket to the Aurora MySQL cluster:
LOAD DATA FROM S3 's3-us-east-1://sagemaker-sample-files/datasets/tabular/synthetic/churn.txt'
INTO TABLE `churn`
COLUMNS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(state,acc_length,area_code,phone,int_plan,vmail_plan,vmail_msg,day_mins,
day_calls,day_charge,eve_mins,eve_calls,eve_charge,night_mins,night_calls,
night_charge,int_mins,int_calls,int_charge,cust_service_calls,Churn);
Move Aurora data to the S3 bucket
At this point, whether you are using our test data or you own data, we now have a dataset in Aurora that we want to use to create an ML model. So first we must load the data to S3 so it can be accessed by SageMaker. To load the data we can use the SELECT INTO OUTFILE S3 statement to query data from an Aurora MySQL DB cluster and save it directly into text files stored in an S3 bucket.
Before we can save data into an S3 bucket, we must first give our Aurora MySQL DB cluster permission to access Amazon S3. After setting the permissions, we run the following commands to load data to Amazon S3:
mysql> select count(*) from churn;
+----------+
| count(*) |
+----------+
| 5000 |
+----------+
1 row in set (0.03 sec)
SELECT * INTO OUTFILE S3 's3-region://bucket-name/file-prefix' FORMAT CSV HEADER FROM churn;
See the following example
mysql> SELECT * INTO OUTFILE S3 's3-us-west-2://aws-sagemaker-aurora-bucket-1/churn.txt' FORMAT CSV HEADER FROM churn;
Query OK, 5001 rows affected (0.25 sec)
Create an ML model using Autopilot with the imported dataset
Now that the data is ready in our S3 bucket, let’s provide the S3 path of the data to Autopilot to create and automatically train an ML model.
- Launch Autopilot using the Amazon SageMaker Studio Launcher.
- Create an Autopilot experiment.
- Provide the required settings and import the churn dataset from Amazon S3 bucket in the Experiment and data details tab.
 Autopilot supports different training model and algorithms to address machine learning problems.
Autopilot supports different training model and algorithms to address machine learning problems.
- On the Training Method Tab, Choose Auto, which allows Autopilot to choose either Ensembling or Hyperparameter optimization (HPO) based on your dataset size.

- On the Deployment and Advanced settings tab, you have option to auto deploy the SageMaker endpoint by selecting Auto deploy.
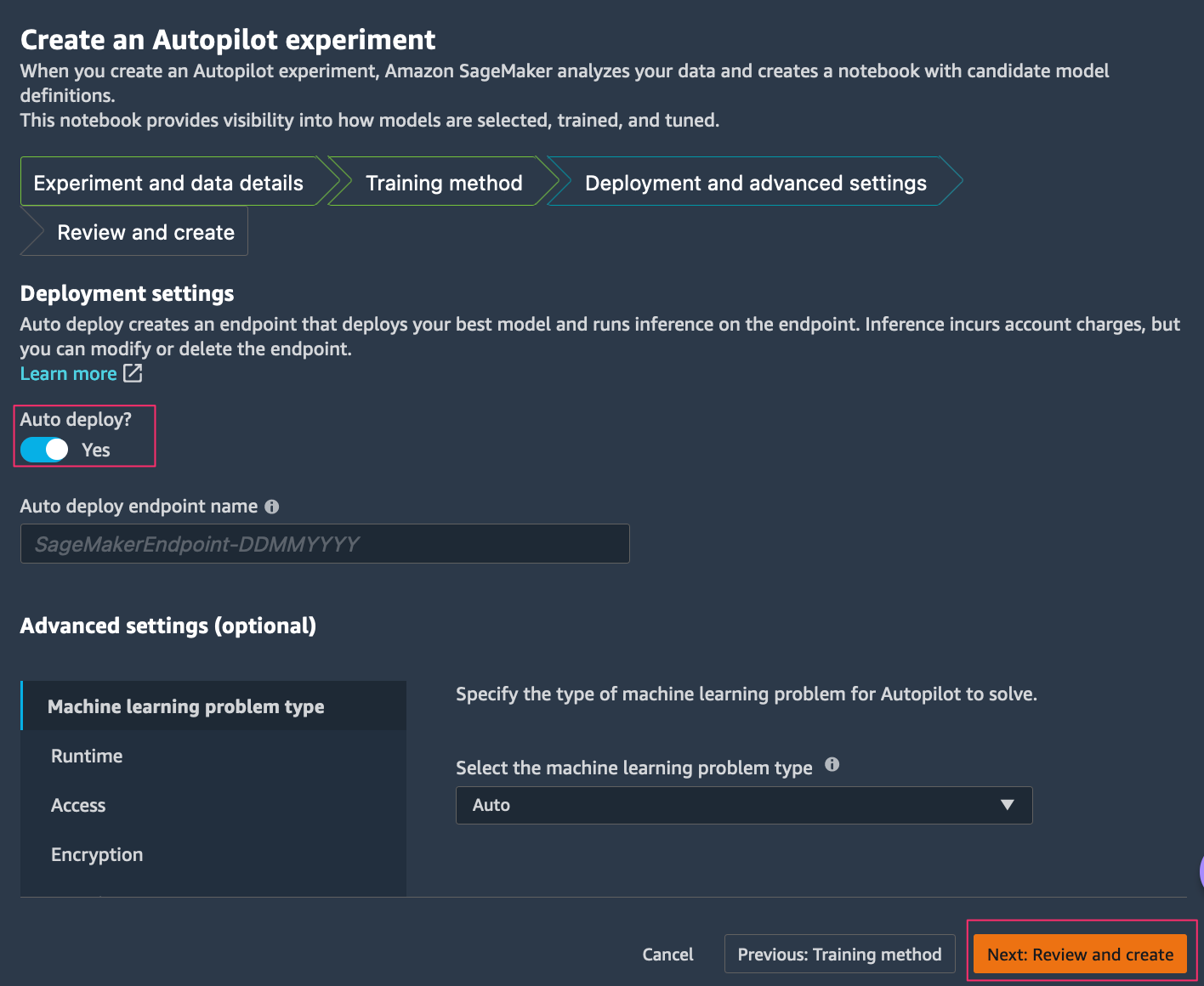
- On the Review and create tab, review all the settings you provided and choose Create experiment.
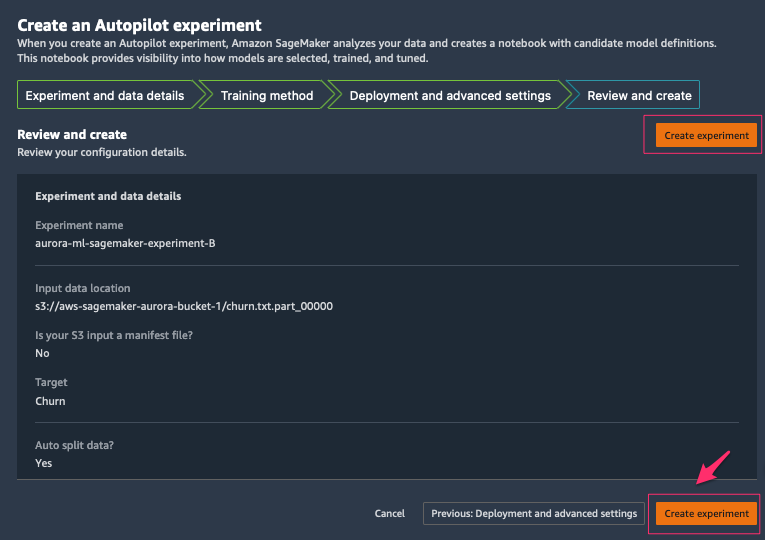
After Autopilot begins an experiment, the service automatically inspects the raw input data, applies feature processors, and picks the best potential algorithms. After it chooses an algorithm, Autopilot optimizes its performance using a hyperparameter optimization search process. This is often referred to as training and tuning the model. This ultimately helps produce a model that can accurately make predictions on data it has never seen. Autopilot automatically tracks model performance, and then ranks the final models based on metrics such as accuracy, F1-score, precision, and recall, based on the type of ML problem. In this case, we focus on F1-score, because we want to classify whether the customer will leave or not (binary classification).
Select the best ML model and deploy the SageMaker endpoint
If you didn’t choose the Auto deploy option in the previous step, you have the option to deploy any of the ranked models. You can do so either by choosing the model (right-click) and choosing Deploy model, or by selecting the best model in the ranked list and choosing Deploy model.
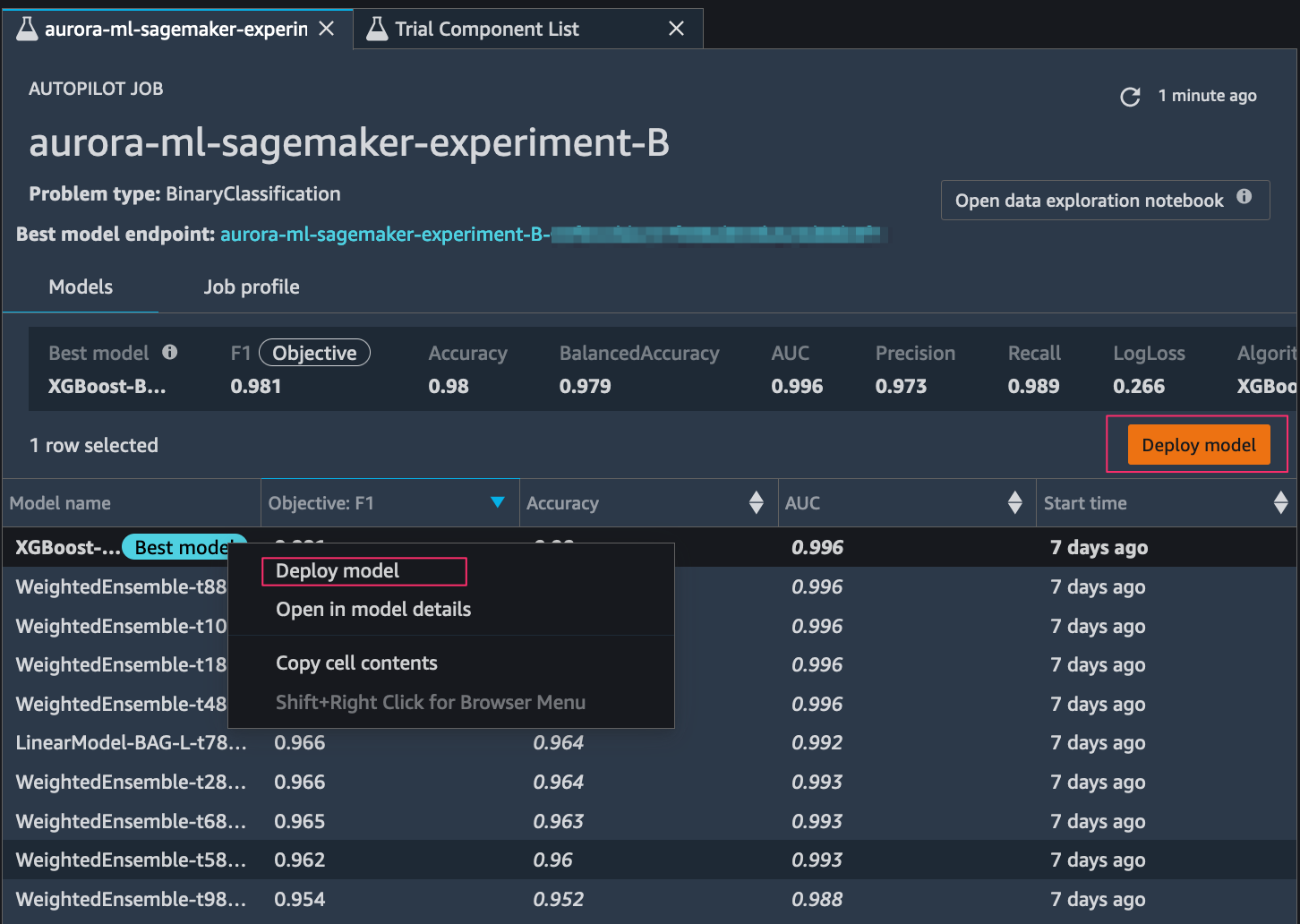
After we set up the model endpoint, the next step is the process of integrating Aurora with the SageMaker endpoint to infer customer churn in a dataset using SQL commands.
Integrate Aurora with SageMaker
Aurora can make direct and secure calls to SageMaker that don’t go through the application layer. Before we can access SageMaker through Aurora, we need to enable the Aurora MySQL cluster to access AWS ML by configuring an AWS Identity and Access Management (IAM) role. For more information, refer to Setting up IAM access to SageMaker. This role authorizes the user of our Aurora MySQL database to access AWS ML services.
To set up Aurora integration with SageMaker, complete the following steps:
- Create an IAM policy.
The following policy adds the permissions required by Aurora MySQL to invoke a SageMaker function on our behalf. We can specify all the SageMaker endpoints to access from our Aurora MySQL cluster in a single policy. The policy also allows us to specify the AWS Region for an SageMaker endpoint. However, an Aurora MySQL cluster can only invoke SageMaker models deployed in the same Region as the cluster. Add the region, AWS account ID and SageMaker endpoint name to the policy. Save this below policy to a JSON file.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAuroraToInvokeRCFEndPoint",
"Effect": "Allow",
"Action": "sagemaker:InvokeEndpoint",
"Resource": "arn:aws:sagemaker:region:123456789012:endpoint/endpointName"
}
]
}
- After we create the IAM policy, create an IAM role that the Aurora MySQL cluster can assume on behalf of our database users to access ML services. The following create-role command creates a role named
auroraml-sagemaker-access:
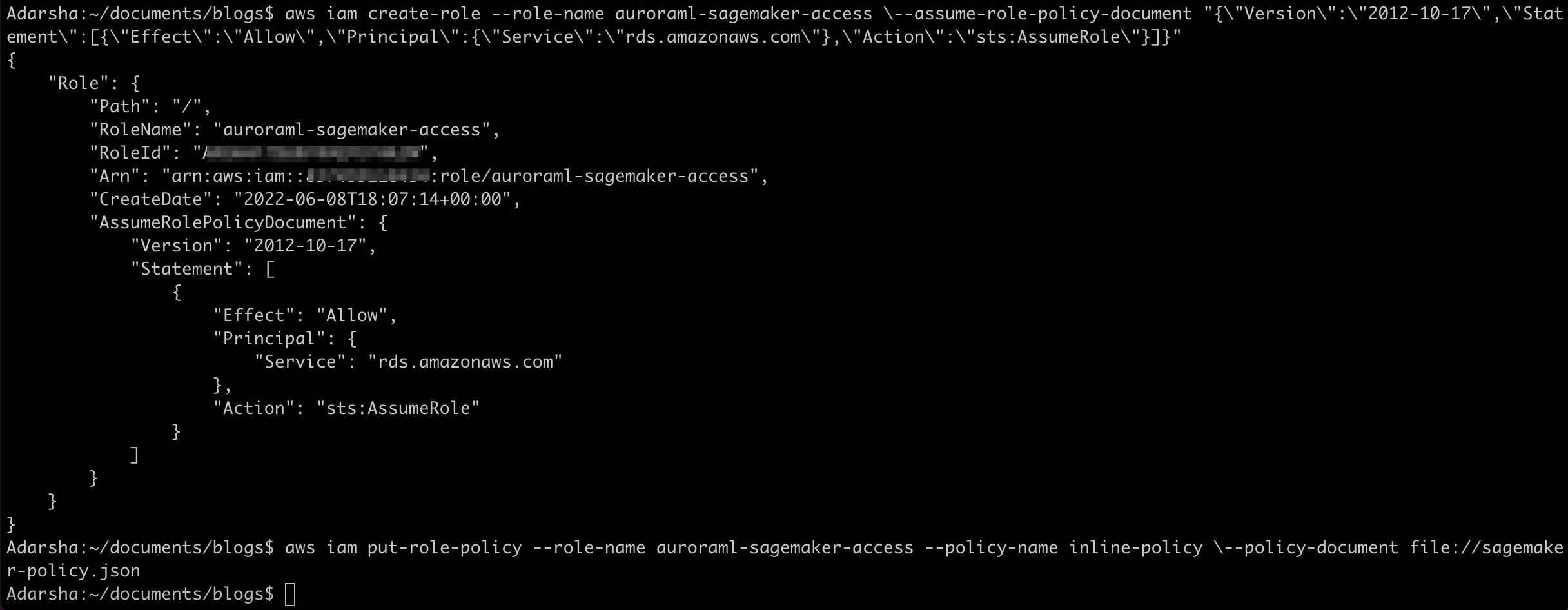
aws iam create-role \
--role-name auroraml-sagemaker-access \
--assume-role-policy-document "{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"rds.amazonaws.com\"},\"Action\":\"sts:AssumeRole\"}]}"
- Run the following command to attach the policy we created to the new role:
aws iam put-role-policy \
--role-name auroraml-sagemaker-access --policy-name inline-policy \
--policy-document file://sagemaker-policy.json
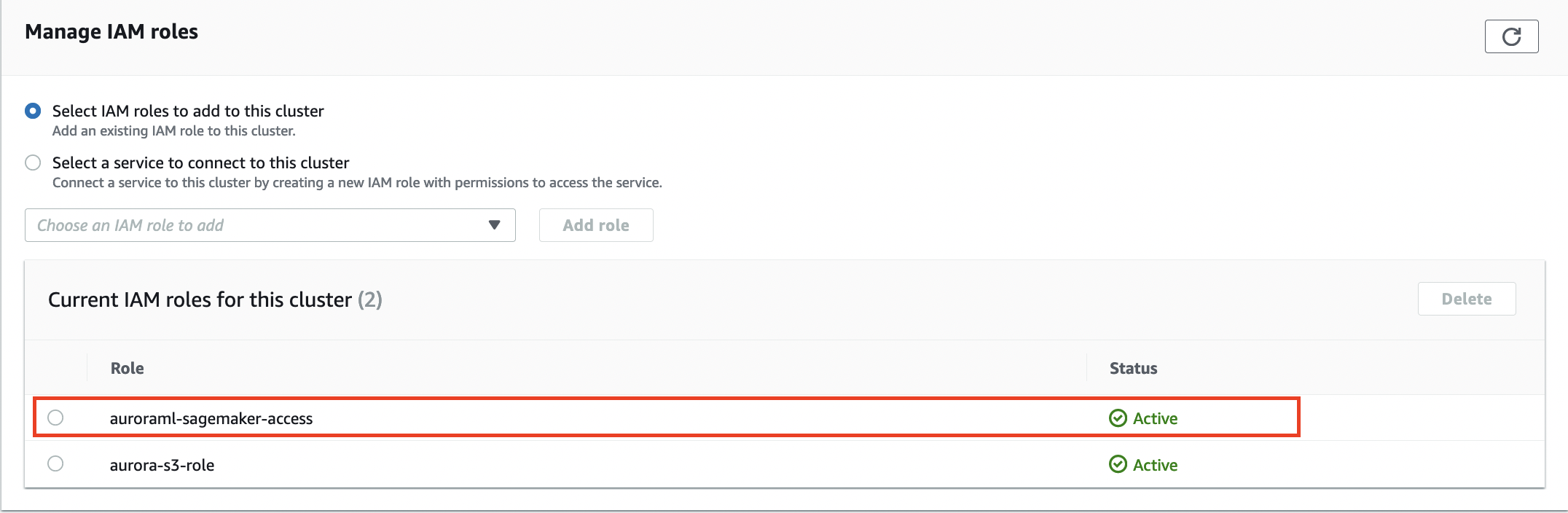
- Associate the IAM role with the Aurora DB cluster:
aws rds add-role-to-db-cluster \
--db-cluster-identifier database-aurora-ml \
--role-arn $(aws iam list-roles --query 'Roles[?RoleName==`auroraml-sagemaker-access`].Arn' --output text)
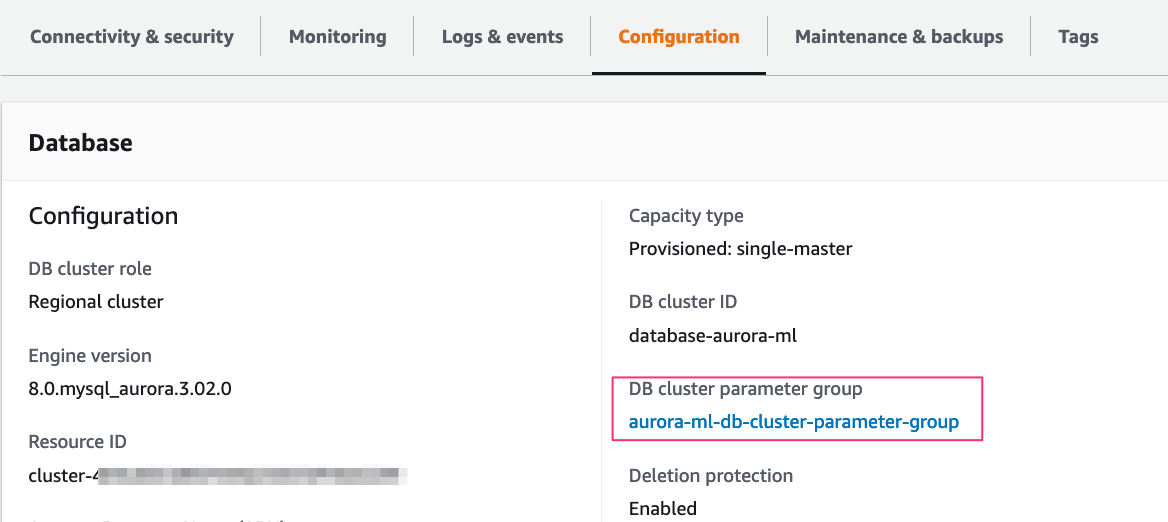
- Create a custom DB cluster parameter group to permit database users to access SageMaker Endpoint through aws_default_sagemaker_role parameter.
aws rds create-db-cluster-parameter-group \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group \
--db-parameter-group-family aurora-mysql8.0 \
--description "My Aurora ML cluster parameter group"
- Attach the custom DB cluster parameter group that we created
aurora-ml-db-cluster-parameter-group to the Aurora cluster:
aws rds modify-db-cluster \
--db-cluster-identifier database-aurora-ml \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group
- Verify the cluster is available and set the IAM role
auroraml-sagemaker-access ARN to the parameter aws_default_sagemaker_role in the custom DB cluster parameter group and apply it to the cluster.
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name aurora-ml-db-cluster-parameter-group \
--parameters "ParameterName=aws_default_sagemaker_role,ParameterValue=$(aws iam list-roles --query 'Roles[?RoleName==`auroraml-sagemaker-access`].Arn' --output text),ApplyMethod=pending-reboot"
A manual reboot of all nodes in the cluster is required if a custom cluster parameter group is attached for the first time. If it’s a single-node cluster, reboot the writer instance to apply the changes. The parameter change takes effect only after we manually reboot the DB instances in each associated DB cluster. Because we’re attaching the custom cluster parameter group aurora-ml-db-cluster-parameter-group, we perform a failover for multi-AZ cluster that reboots the writer and reader nodes.
- Fail over the cluster to apply the changes of the custom DB cluster parameter group:
aws rds failover-db-cluster --db-cluster-identifier database-aurora-ml
- Verify if the cluster parameter group is applied and showing in-sync status.
aws rds describe-db-clusters \
--db-cluster-identifier <DB cluster identifier> \
--query 'DBClusters[*].DBClusterMembers'
See the following example:
aws rds describe-db-clusters --db-cluster-identifier database-aurora-ml --query 'DBClusters[*].DBClusterMembers'
[
[
{
"DBInstanceIdentifier": "reader",
"IsClusterWriter": false,
"DBClusterParameterGroupStatus": "in-sync",
"PromotionTier": 1
},
{
"DBInstanceIdentifier": "database-1-instance-1",
"IsClusterWriter": true,
"DBClusterParameterGroupStatus": "in-sync",
"PromotionTier": 1
}
]
]
Create a SQL function in Aurora using the SageMaker endpoint
- Connect to the Aurora MySQL cluster and switch to the
mltest database we created earlier:
mysql> use mltest;
Database changed
- Create the SQL function using the following command using the SageMaker endpoint that you created in previous step:
CREATE FUNCTION `will_churn`(
state varchar(2048),
acc_length bigint(20),
area_code bigint(20),
phone varchar(1000),
int_plan varchar(2048),
vmail_plan varchar(2048),
vmail_msg bigint(20),
day_mins double,
day_calls bigint(20),
day_charge bigint(20),
eve_mins double,
eve_calls bigint(20),
eve_charge bigint(20),
night_mins double,
night_calls bigint(20),
night_charge bigint(20),
int_calls bigint(20),
int_charge bigint(20),
cust_service_calls bigint(20)
) RETURNS varchar(2048) CHARSET latin1
alias aws_sagemaker_invoke_endpoint
endpoint name '<SageMaker endpoint>';
Invoke the SageMaker endpoint from Aurora using a SQL query
Now that we have an integration function linking back to the SageMaker endpoint, the DB cluster can pass values to SageMaker and retrieve inferences. In the following example, we submit values from the churn table as function inputs to determine if a particular customer will churn. This is represented by the True or False result in the Will Churn? column.
mysql> SELECT will_churn('IN',65,415,'329-6603','no','no',0,129.1,137,21.95,228.5,83,
19.42,208.8,111,9.4,12.7,6,3.43,4) AS'Will Churn?';
+-------------+
| Will Churn? |
+-------------+
| False. |
+-------------+
1 row in set (0.06 sec)
mysql> SELECT c.state,c.acc_length,c.area_code, c.int_plan,c.phone, will_churn('c.state',c.acc_length,c.area_code,'c.int_plan','c.phone',
'c.vmail_plan',c.vmail_msg,c.day_mins,c.day_calls,c.day_charge,c.eve_mins,
c.eve_calls,c.eve_charge,c.night_mins,c.night_calls,c.night_charge,
c.int_mins,c.int_calls,c.int_charge,c.cust_service_calls) AS 'Will Churn?' from churn as c limit 5;
+-------+------------+-----------+----------+----------+-------------+
| state | acc_length | area_code | int_plan | phone | Will Churn? |
+-------+------------+-----------+----------+----------+-------------+
| OK | 112 | 415 | no | 327-1058 | False. |
| CO | 22 | 510 | no | 327-1319 | False. |
| AZ | 87 | 510 | no | 327-3053 | False. |
| UT | 103 | 510 | no | 327-3587 | True. |
| SD | 91 | 510 | no | 327-3850 | False. |
+-------+------------+-----------+----------+----------+-------------+
Clean up
The services involved in this solution incur costs. When you’re done using this solution, clean up the following resources:
Conclusion
In this post, we learned how to build a customer churn ML model with Autopilot and invoke a SageMaker endpoint from an Aurora cluster. Now we can get ML inferences using SQL from the SageMaker endpoint in real time. You could use these inferences about customer churn in customer retention campaigns in your business.
Stay tuned for Part 2 of this series, in which we discuss how to implement Aurora ML performance optimizations for access to model inferences on real-time data.
We welcome your feedback; leave your comments or questions in the comments section.
About the authors
 Adarsha Kuthuru is a Database Specialist Solutions Architect at Amazon Web Services. She works with customers to design scalable, highly available and secure solutions in the AWS Cloud. Outside of work, you can find her painting, reading or hiking in Pacific North West.
Adarsha Kuthuru is a Database Specialist Solutions Architect at Amazon Web Services. She works with customers to design scalable, highly available and secure solutions in the AWS Cloud. Outside of work, you can find her painting, reading or hiking in Pacific North West.
 Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers use machine learning to solve their business challenges with AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at the edge. She has created her own lab with a self-driving kit and prototype manufacturing production line, where she spends a lot of her free time.
Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers use machine learning to solve their business challenges with AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at the edge. She has created her own lab with a self-driving kit and prototype manufacturing production line, where she spends a lot of her free time.