Amazon Web Services ブログ
Amazon Athena – Amazon S3上のデータに対話的にSQLクエリを
私達が扱わなければいけないデータの量は日々増え続けています(私は、未だに1,2枚のフロッピーディスクを持っていて、1.44MBというのが当時はとても大きいストレージだったことを思い出せるようにしています)。今日、多くの人々が構造化されたもしくは準構造化されたペタバイト規模のファイル群を、日常的に処理してクエリしています。彼らはこれを高速に実行したいと思いつつ、前処理やスキャン、ロード、もしくはインデックスを貼ることに多くの時間を使いたいとは思っていません。そうではなくて、彼らはすぐ使いたいのです: データを特定し、しばしばアドホックに調査クエリを実行して、結果を得て、そして結果に従って行動したいと思っていて、それらを数分の内に行いたいのです。
Amazon Athena紹介
本日、Amazon Athenaについて紹介したいと思います。

Athenaは新しいサーバレスクエリサービスで、Amazon S3に保存された膨大な量のデータを標準SQLを使って簡単に分析できます。シンプルにAmazon Simple Storage Service (S3)に保存したデータを指定し、フィールドを定義して、クエリを投げると、数秒で結果を得られます。皆さんは、クラスタや他のインフラを構築したり管理したりチューニングする必要はなく、実行したクエリに対してのみお金を払うだけでよいです。裏では、Athenaがクエリを並列化して何百、何千コアに分散してくれ、数秒で結果を届けてくれます。
Athenaには対話的なクエリエディタがあるので、可能な限り素早く始めることができます。クエリは標準のANSI SQLで表現でき、JOINやwindow関数、その他の発展的な機能が利用できます。Athenaは分散SQLエンジンのPrestoをベースにしていて、JSON、CSV、ログファイル、カスタム区切りのテキスト、Apache Parquet、Apache ORC等を含む様々なフォーマットにクエリが実行できます。AWS Management Consoleの他に、SQL Workbench等のSQLクライアントや、データの可視化のためにAmazon QuickSightを使うこともできます。また、Athena JDBCドライバをダウンロードして使うことで、お好きなビジネスインテリジェンスツールからクエリを実行することもできます。
Athenaの各テーブルは1つ以上のS3オブジェクトから構成され、Athenaのデータベースは1つ以上のテーブルを持ちます。AthenaはS3に保存されたデータを直接参照するので、S3が提供するスケール、柔軟性、データ耐久性、そしてAWS Identity and Access Management (IAM)ポリシーを使ったアクセス管理を含むデータ保護等の利点を享受できます。
Athenaの実際
AWS Management Consoleを開いて少しAthenaを試してみました。メインの画面ではAthenaのクエリエディタが見えます:
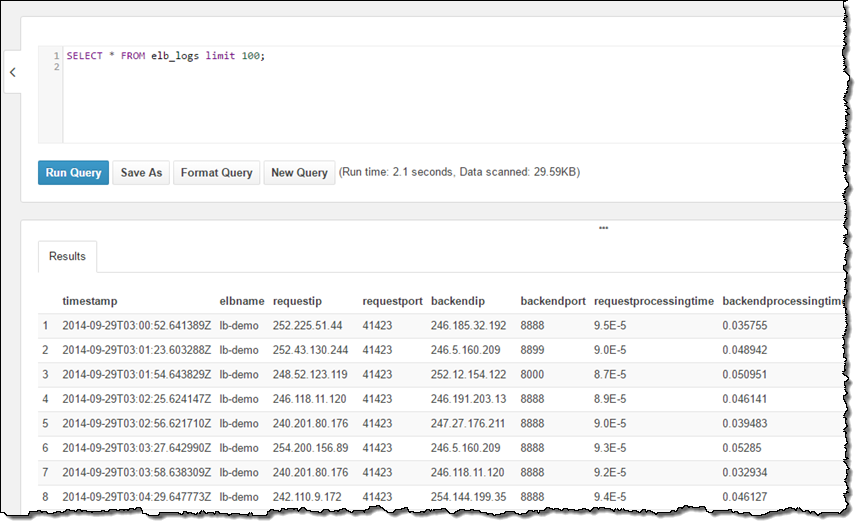
私のアカウントでは既にサンプルデータベースを設定してあって、そのデータベースにはelb_logsというサンプルテーブルがあります。まず始めに、単純なクエリを入力してRun Queryをクリックしてみました。1秒未満の実行でコンソールに結果が表示され、CSV形式でダンロードすることもできます:
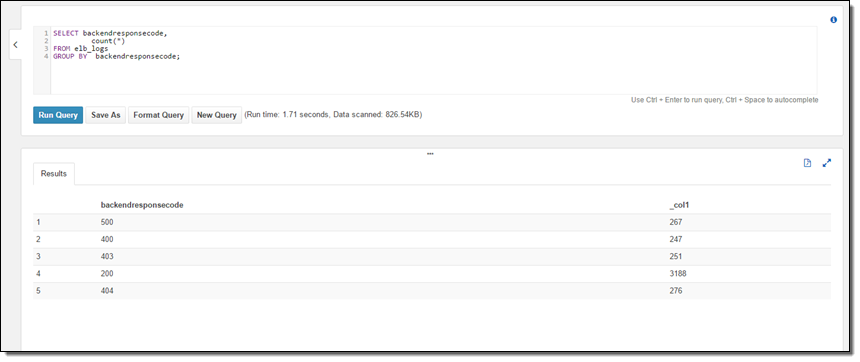
サンプルテーブルはElastic Load Balancingのログファイルなので、HTTPのステータスコードで分析してみます:
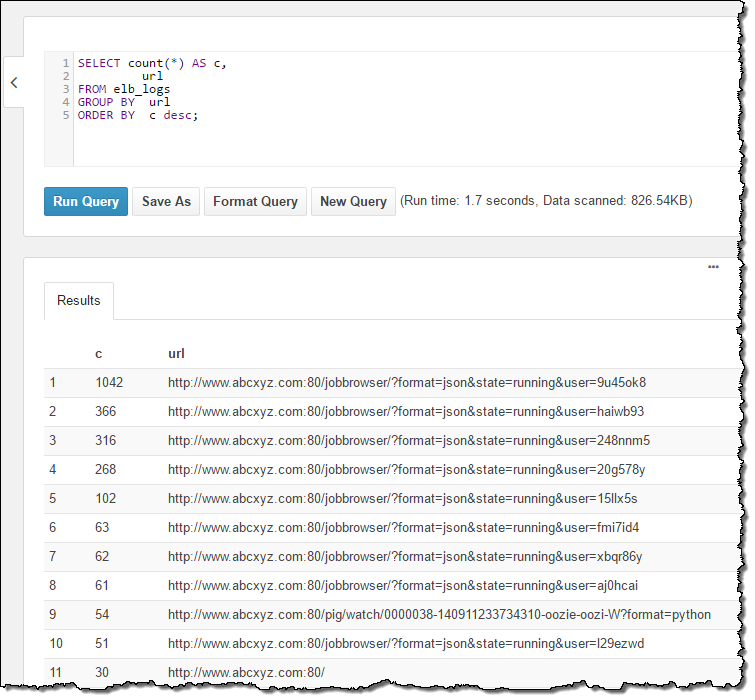
URLでもやってみます:
このテーブル定義はS3バケットを指定しているので、そのバケットの全てのオブジェクトが含まれています。私が対話的に操作している間にもし新しいログファイルがやってきたら、その後のクエリからは自動的にそれらも含まれるようになります(テーブル定義についてはもう少し後でお話します)。
クエリを書いている時に、コンソールのテーブル詳細を使いました。テーブルやフィールド名をダブルクリックするだけで、クエリに挿入されます:
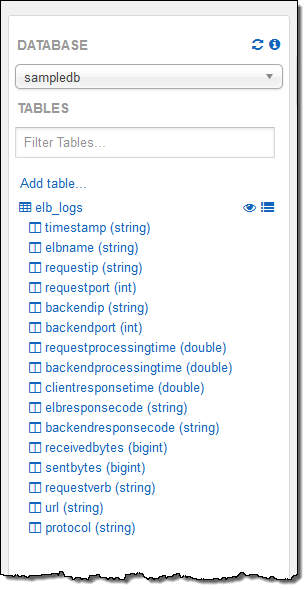
そして、クエリを保存してこの探索を終了します:
次に、どの様にしてデータベースを作成し、データを参照するかを学びたいと思います。これには2つの方法があります – DDL文を使うか、ウィザードを使うかです。同僚がいくつかのDDLをくれたので、先にそれを使って見たいと思います:
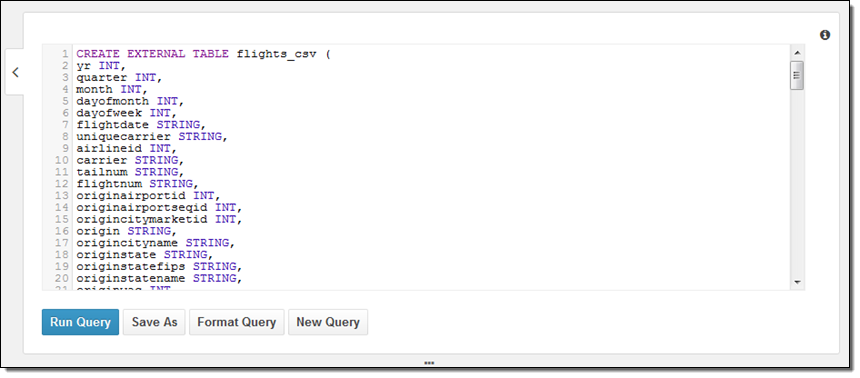
このクエリの一番おもしろい箇所は一番最後の部分です; こんな感じになっています:
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://us-east-1.elasticmapreduce.samples/flights/cleaned/gzip/';このデータは年毎にパーティションされているので、メタデータを設定するために最後に1つ以下のクエリを実行する必要がありました:
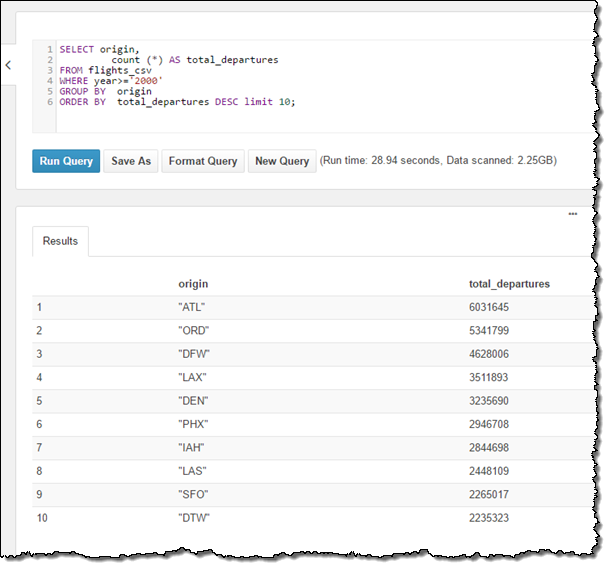
MSCK REPAIR TABLE flights_csv;そうしたら、簡単なクエリで、2000年以降のデータを使って、10個の最も人気がある出発都市を集計してみます:
他にも、Athenaのテーブルウィザード(Catalog Managerからアクセス可能)を使ってテーブルを作成することもできます。この場合、テーブルの名前をつけて、場所を指定するところから始まります:
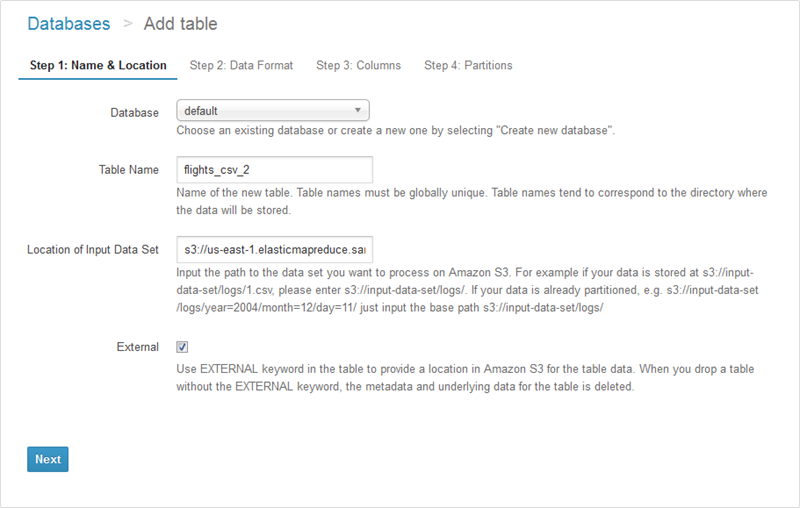
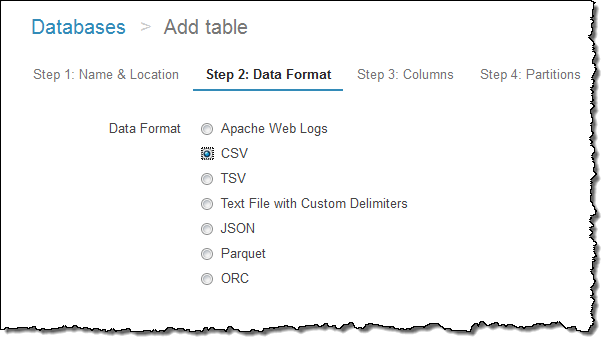
それから、フォーマットを指定します:
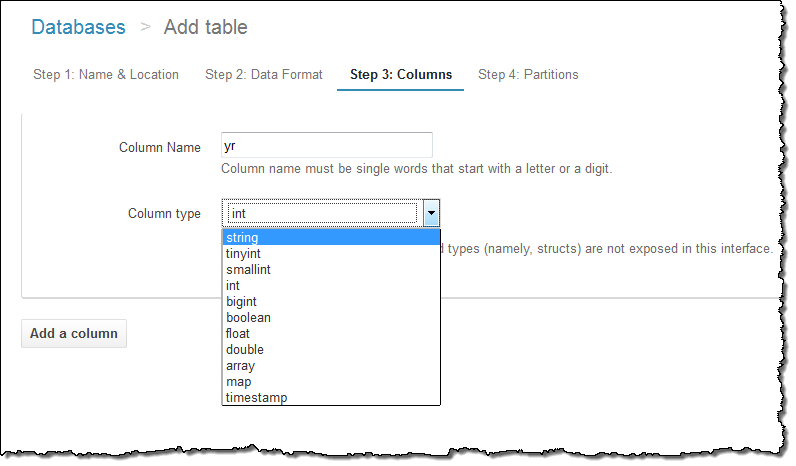
各列の名前と型を指定します:
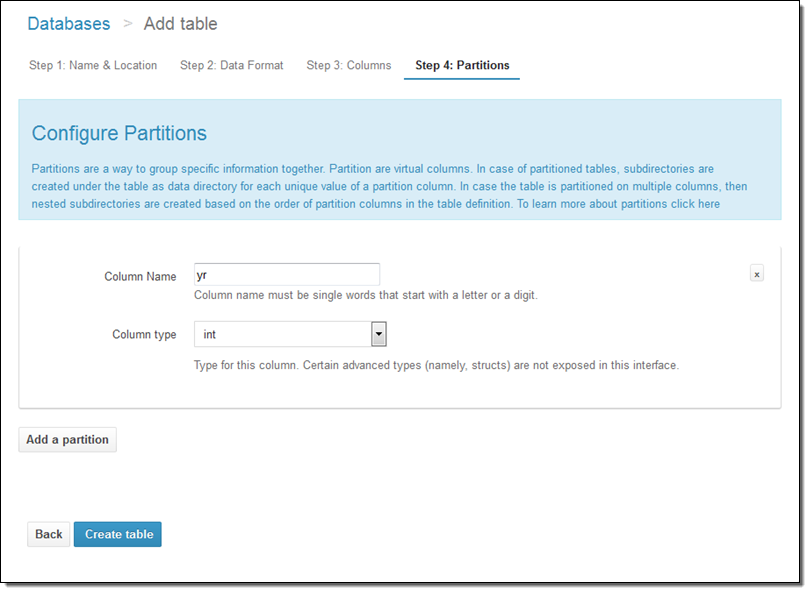
パーティションモデルも設定できます:
Athenaはこれ以外にもたくさんのかっこいい機能を持っていますが、スペースの関係で残りの全てをお見せできません。その中からあと3つだけクイックに見てみましょう: クエリの保存、履歴、そしてカタログマネージャです。
この記事の最初の方で、私はクエリを1つ保存しました。Saved Queriesをクリックすると、私のアカウントで保存されたいくつかのクエリに、私が保存したものも加えて全て表示されます:
これらをそのまま使うこともできますし、必要に応じて編集もできます。
Historyをクリックすると過去のクエリを見たり、生成された結果をダウンロードすることもできます:
そしてCatalog Managerを使って既存のデータベースを見たり、新しいものを作成したり、新しいテーブルを作成したりできます:
ここではAthenaの対話的な側面にフォーカスしてきましたが、JDBCコネクタを使って既存のビジネスインテリジェンスツールとも連携できることを覚えておいて下さい。
今から利用可能です
Amazon AthenaはUS East (Northern Virginia)とUS West (Oregon)で本日から利用可能となり、他のリージョンも数ヶ月のうちに利用可能となります。
実行したクエリに対してのみお金を支払うだけです; 各クエリでどれだけのデータがスキャンされたか(クエリ実行後にコンソールに表示されます)を基準に課金されます。これが意味する所として、圧縮やパーティション、またはデータを列指向のフォーマットに変換することで、格段にコストを抑えられることがお分かりかと思います。
— Jeff;
原文: Amazon Athena – Interactive SQL Queries for Data in Amazon S3 (翻訳: SA岩永)