AWS News Blog
Amazon Athena – Interactive SQL Queries for Data in Amazon S3
The amount of data that we all have to deal with grows every day (I still keep a floppy disk or two around in order to remind myself that 1.44 MB once seemed like a lot of storage). These days, many people routinely process and query data in structured or semi-structured files at petabyte scale. They want to do this at high speed and they don’t want to spend a whole lot of time preprocessing, scanning, loading, or indexing data. Instead, they simply want to point-and-shoot: identify the data, run queries that are often ad hoc and exploratory in nature, get the results, and act on the results, all in a matter of minutes.
Introducing Amazon Athena
 Today I would like to tell you about Amazon Athena.
Today I would like to tell you about Amazon Athena.
Athena is a new serverless query service that makes it easy to analyze large amounts of data stored in Amazon S3 using Standard SQL. You simply point Athena at some data stored in Amazon Simple Storage Service (Amazon S3), identify your fields, run your queries, and get results in seconds. You don’t have to build, manage, or tune a cluster or any other infrastructure, and you pay only for the queries that you run. Behind the scenes, Athena parallelizes your query, spreads it out across hundreds or thousands of cores, and delivers results in seconds.
Athena includes an interactive query editor to help get you going as quickly as possible. Your queries are expressed in standard ANSI SQL and can use JOINs, window functions, and other advanced features. Athena is based on the Presto distributed SQL engine and can query data in many different formats including JSON, CSV, log files, text with custom delimiters, Apache Parquet, and Apache ORC. You can run your queries from the AWS Management Console or from a SQL clients such as SQL Workbench, and you can use Amazon QuickSight to visualize your data. You can also download and use the Athena JDBC driver and run queries from your favorite Business Intelligence tool.
Each Athena table can be comprised of one or more S3 objects; each Athena database can contain one or more tables. Because Athena makes direct references to data stored in S3, you can take advantage of the scale, flexibility, data durability, and data protection options that it offers, including the use of AWS Identity and Access Management (IAM) policies to control access to data.
Athena in Action
I took Athena for a spin by opening it up in the AWS Management Console. The main screen shows the Athena Query Editor:
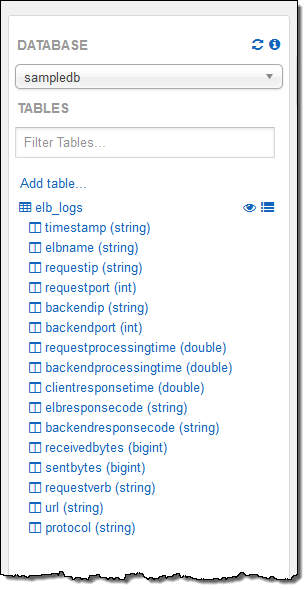
My account was already configured with a sample database and, within the database, a sample table named elb_logs. To get started, I entered a simple query and clicked on Run Query. It ran in less than a second and the results were displayed in the console, with the option to download them in CSV form:
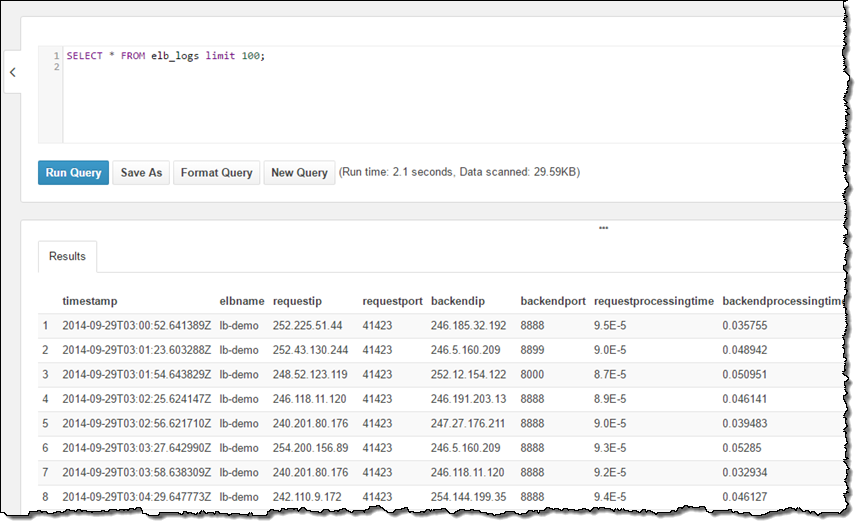
The sample table contained Elastic Load Balancing log files so I analyzed the HTTP status codes:
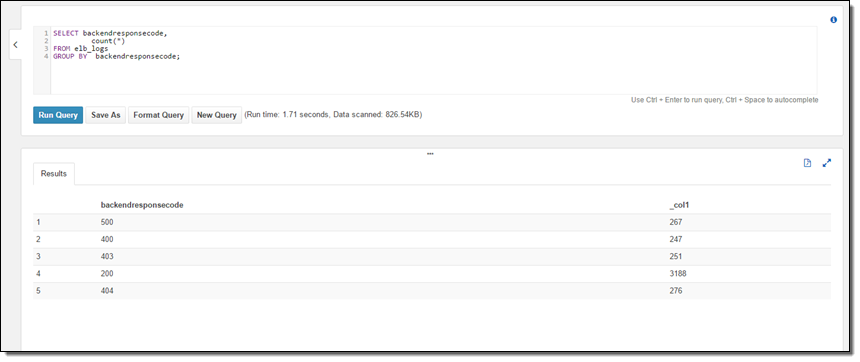
And the URLs:
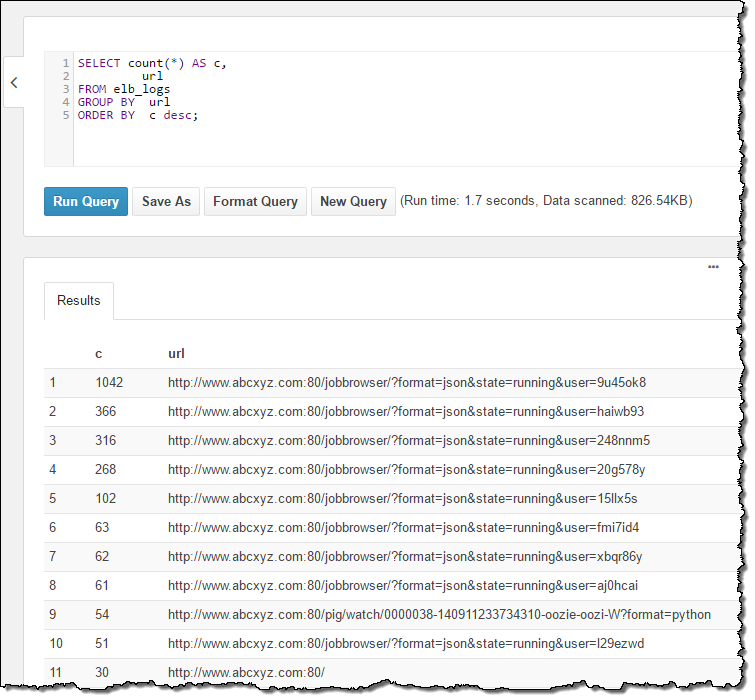
The table definition points to an S3 bucket, and encompasses all of the objects in the bucket. If new log files arrived during my interactive session, they would automatically be included in subsequent queries (I’ll talk more about table definitions in a minute).
As I was writing the queries I made use of the table description in the console. I simply double-clicked on the table and field names to insert them into the query:
I ended this part of my exploration by saving my query:
Next, I wanted to learn how to create my own database and to reference my own data. There are two ways to do this — using a DDL statement or through a wizard. My colleagues supplied me with some DDL, so I went ahead and used it:
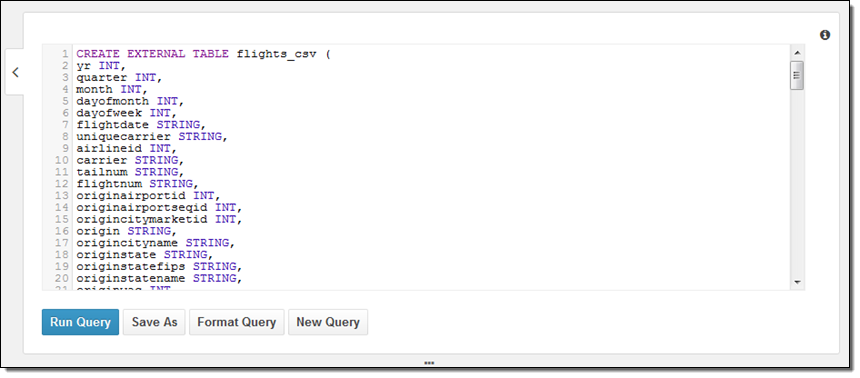
The most interesting part of the query is at the end; here’s what it looks like:
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://us-east-1.elasticmapreduce.samples/flights/cleaned/gzip/';Because the data is partitioned by year, I had to run one final query to set up the metadata for subsequent queries:
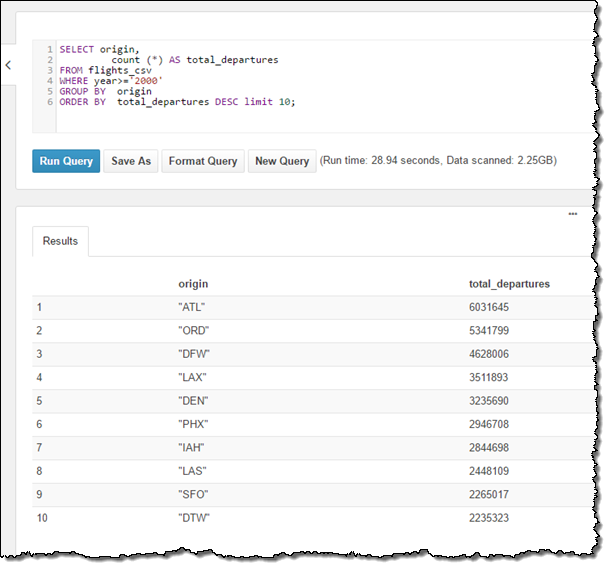
MSCK REPAIR TABLE flights_csv;Then I ran a simple query to tally up the 10 most popular departure cities, using data from 2000 onward:
I also had the option to create the table using Athena’s table wizard (accessible from the Catalog Manager). In this case I would start by naming the table and specifying its location:
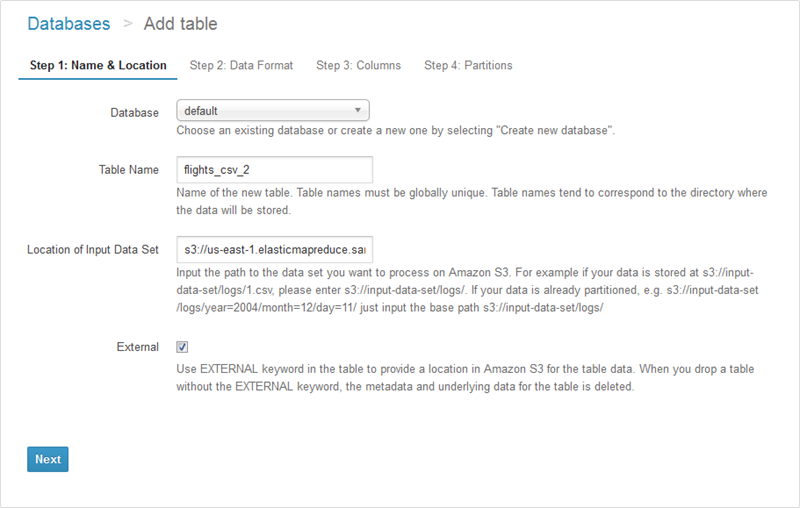
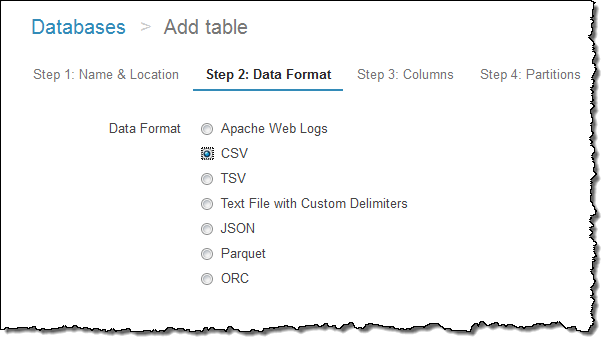
Then I would specify the format:
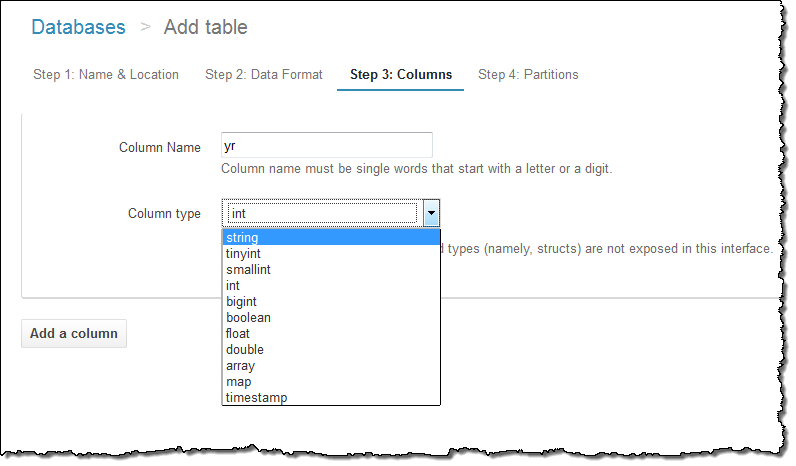
And the name and data type of each column:
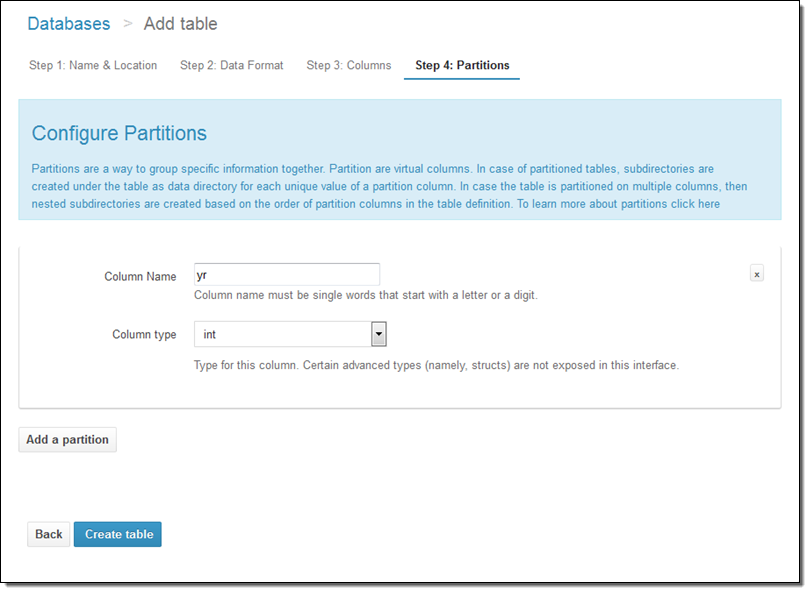
I can also set up the partition model:
Athena has lots of other cool features but space keeps me from showing off every last one of them. Let’s take quick looks at three: the Saved Queries, the History, and the catalog manager.
Earlier in this post I saved one of my queries. I can click on Saved Queries to see all of the queries that I have saved, along several that came with my account:
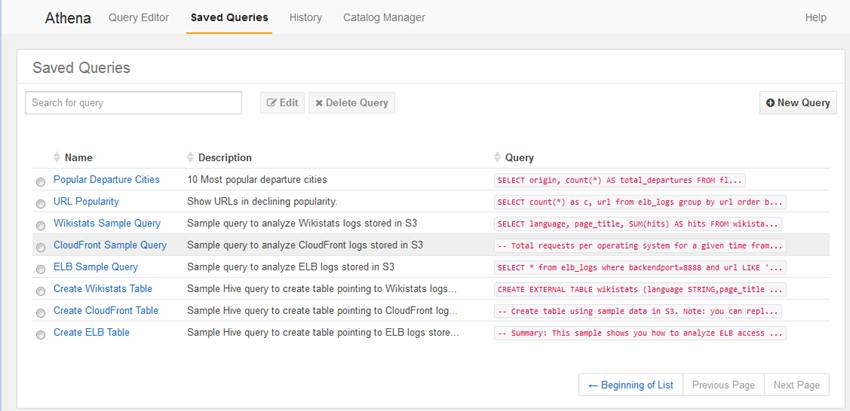
I can use them as-is, or edit them as desired.
I can click on History to see my previous queries and download the results that they generated:
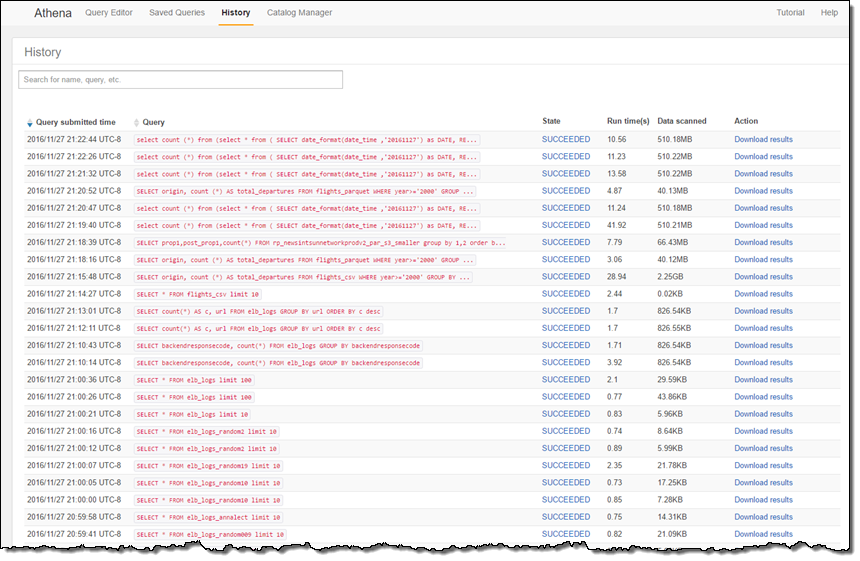
And I can use the catalog manager to see my existing databases, create new ones, and create new tables:
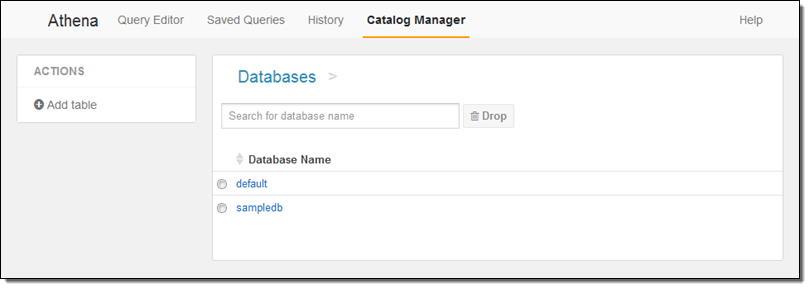
Although I have focused on the interactive aspects of Athena, keep in mind that you can also use our JDBC connectors in conjunction with your existing Business Intelligence tools.
Available Now
Amazon Athena is available now in the US East (N. Virginia) and US West (Oregon) Regions today and will become available in other regions in the coming months.
You pay only for the queries that you run; you are charged based on the amount of data scanned by each query (the console will display this information after each query). This means that you can realize significant cost savings by compressing, partitioning, or converting your data to a columnar format.
Ready to learn more? We have a webinar on December 14th. Register here.
— Jeff;