Amazon Web Services ブログ
Amazon Aurora MySQL 互換エディションでグローバルトランザクション ID (GTID) によるレプリケーションがサポートされるようになりました
Amazon Aurora MySQL 互換エディションは、ハイエンドな商用データベースの速さや信頼性と、オープンソースデータベースのシンプルさと高い費用対効果とを組み合わせたリレーショナルデータベースエンジンです。また Amazon Aurora with MySQL compatibility は、標準の MySQL Community Edition に比べ最大 5 倍のスループットを実現します。
本ブログ記事では、オンプレミスまたは Amazon EC2 上でホストされている MySQL DB を、新たにリリースされた GTID べースのレプリケーション機能を使用する Aurora MySQL に移行するのに役立つガイダンスについて解説します。
GTID ベースのレプリケーションとは?
グローバルトランザクション ID (GTID) とは、MySQL、または MySQL 互換エンジンを実行するデータベースサーバー上でコミットされた各トランザクションに作成され、関連付けられる固有の識別子です。この ID は元のサーバーと、さらにトランザクションの両方を個別に識別します。
フェイルオーバーやダウンタイム後、データベース管理者にとって最大の課題は、ひとつの変更もスキップされることなく、また、一切の競合が生成されることない方法でレプリケーションを復元することです。ワークロードが動的に、スケーラブルに、また複雑になるに従って、これらの再構成タスクもますます頻度が増えていきます。その結果として、バイナリログファイルの位置を特定するのに必要な管理的オーバーヘッドが増大し、それによって、復旧時間が長引きます。
これは GTID ベースのレプリケーションを使用することで、根本的に解決可能です。GTID の「絶対座標」を使用することにより、レプリケーションストリーム上の位置を自動的に追跡できるので、管理オーバーヘッドを減らし、最小限のオーバーヘッドでレプリケーションを実行できるようになります。
GTID ベースのレプリケーションではさらに、完ぺきな整合性も保証されます。その理由は、トランザクションがいったんサーバーにコミットされると、サーバーは既に処理された同じ GTID を持つトランザクションを自動的にスキップするためです。つまり、マスターにコミットされたトランザクションがレプリカに 1 度だけ適用され、ネットワークとディスクの使用量を最小限に抑えることにもなります。
ごく最近まで、GTID を使用できるのは Amazon RDS for MySQL に限られていました。今後は、Amazon Aurora MySQL 2.04 (以降) もまた GTID レプリケーションをサポートします。
Aurora MySQL で GTID ベースのレプリケーションを使用すべきタイミングは?
以下に示した 2 例は Aurora MySQL の主要シナリオで、GTID ベースのレプリケーションを使用できます。
- オンプレミスまたは GTID を使用する Amazon EC2 でホストされる MySQL データベースからの移行。
- GTID を使用する必要のある外部の MySQL ベースシステムへのアウトバウンドレプリケーション。
本ブログ記事では、オンプレミスの GTID を有効化した MySQL データベースを Aurora MySQL へ移行する方法についてご紹介します。
以下の図にはアーキテクチャの概要が示されています。

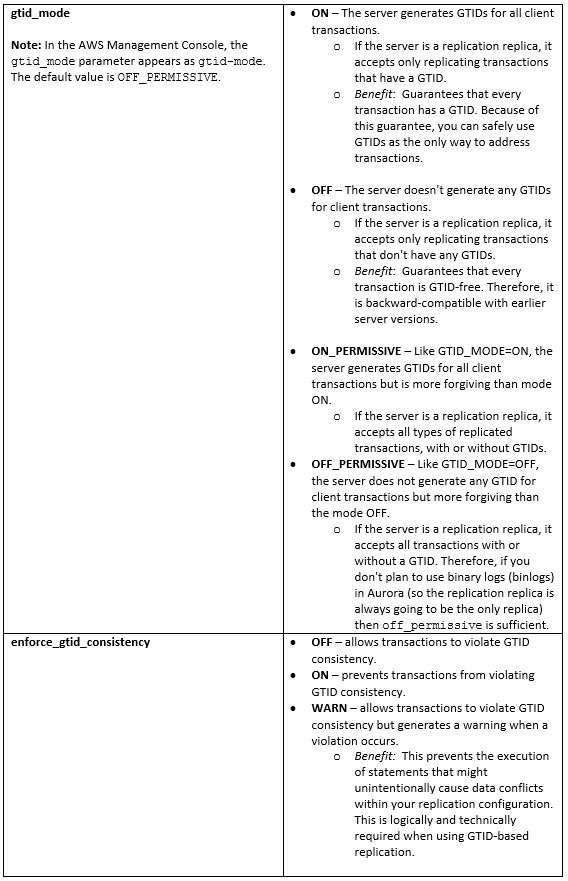
Aurora MySQL で GTID のパラメータを有効にするパラメータ
GTID ベースのレプリケーションでは、DB クラスタパラメータグループの以下のパラメータを使用します。DB クラスタパラメータグループは、Aurora DB クラスタの各 DB インスタンスに適用されるエンジン構成値のコンテナとして動作します。
GTID サポートを使用してデータベースを Aurora MySQL に移行する
以下のサンプルでは、GTID レプリケーションを使用して、外部の MySQL サーバーを Aurora MySQL へ移行する方法について解説します。
始める前に、AWS Direct Connect または VPN 接続を使用して、内部ネットワークを AWS クラウドまで拡張してください。この種のネットワーク拡張機能を使用することで、安全な環境で AWS ホストのリソースにシームレスに接続できるようになります。詳細については、AWS ホワイトペーパー Amazon Virtual Private Cloud Connectivity Options の Network-to-Amazon VPC Connectivity Options を参照してください。
パート 1: ご使用の外部の MySQL サーバーで GTID とバイナリログを有効にします
ご使用の外部の MySQL サーバーでバイナリログ (binlogs) と GTID が有効化されていない場合は、以下のステップを使用してこれらを有効化してください。
- 外部の MySQL サーバーの設定ファイル (通常 /etc/my.cnf) の [mysqld] セクションで、gtid-mode および enforce-gtid-consistency を有効化します。
- マスターでの変更の記録を開始するには、バイナリログを有効化します。詳細については、MySQL のドキュメントで、Replication with Global Transaction Identifiers および Setting the Replication Master Configuration を参照してください。外部の MySQL サーバーで GTID ベースのレプリケーションとバイナリログを有効化する方法について順を追って見ていきましょう。terminal/command shell で mysql サービスを停止します。
my.cnf ファイル (このファイルは通常 /etc/my.cnf にあります) を編集します。
/etc/my.cnf file の以下の関連エントリ。
注意: サーバー ID が 0 に設定されると、バイナリログが実行されますが、サーバー ID が 0 のマスターがレプリカからの接続を拒否します。そのため、MySQL のドキュメントに記載されているとおり、レプリケーショントポロジ内で固有の server-id を設定することが重要です。
次に mysql サービスを開始します。
- 外部の MySQL サーバーへ接続し、その際に、バイナリログと GTID が有効になっていることを確認してください。GTID が使用中の場合、Executed_Gtid_Set にはマスターで実行されたトランザクションの GTID のセットが表示されます。
- 外部の MySQL データベースのバックアップを作成します。MySQL データベースをエクスポートおよびインポートするために使用できる技法は多数あります。このブログ記事では MySQL のディストリビューションにバンドルされているツール (ネイティブツール) を使用します。しかし、より良いパフォーマンスを得るために、mydumper および myloader などのサードパーティー製ユーティリティを使用することも可能です。詳細については、mydumper project、AWS ホワイトペーパーの Amazon Aurora Migration Handbook および Best Practices for Migrating MySQL Databases to Amazon Aurora をご覧ください。データベースのバックアップを行う前に、最初にインスタンスへの書き込み操作を停止する必要があります。以下のコマンドは全テーブルをフラッシュし、読み取り専用モードで DB をロックします。
その後、外部の MySQL データベースのダンプを作成します。
データベースのバックアップを取得したあと、テーブルのロックを解除します。
- 次に、レプリケーションアカウントを作成します。セキュリティの理由で、このアカウントはレプリケーション以外では使用しないでください。
詳細については、MySQL ドキュメントの Creating a User for Replication をご覧ください。
- レプリケーションユーザーに REPLICATION SLAVE 特権を付与します。
パート 2: Aurora MySQL に初期データの読み込みを実行します
ここでは、Aurora MySQL DB クラスタを作成し、マスターの既存のデータセットを含むシンプルな初期データの読み込みを実行します。
- Aurora MySQL 2.04 クラスタを作成するか、Aurora DB クラスタを編集して既存の Aurora DB クラスタをアップグレードします。AWS マネジメントコンソール、AWS CLI、または RDS API を使用して、Aurora DB クラスタを作成できます。
- カスタムクラスタパラメータグループを作成し、gtid-mode および enforce_gtid_consistency を構成します。
• gtid-mode – ON または ON_PERMISSIVE または OFF_PERMISSIVE
• enforce_gtid_consistency – ON
注意: より複雑なレプリケーショントポロジーのために、Aurora MySQL クラスタで binlogs を有効化する予定がない限り、GTID モードは OFF_PERMISSIVE に設定するのが望ましいでしょう。この設定により、レプリケーションの送信元の GTID に関係なく外部のデータベースから受信レプリケーションを受信できるようになります。
次に、DB クラスタパラメータグループと Aurora MySQL クラスタとを関連付けます。パラメータグループの詳細については、Aurora ドキュメントで Working with DB Parameter Groups を参照してください。DB インスタンスのデフォルトパラメータグループを変更するときは、DB インスタンスを再起動します。詳細については、DB インスタンスの再起動を参照してください。
以下のコマンドを実行して、最近作成されたまたは変更された Aurora MySQL クラスタのバージョンを確認します。
Aurora MySQL クラスタにバックアップを読み込む前に、ダンプファイルのコピー先となる EC2 インスタンスを作成するといいでしょう。そして、その EC2 インスタンスから Aurora MySQL DB クラスタにデータを読み込みます。この方法では、ローカルコンピュータと Aurora との間のネットワークレイテンシーの影響を受けることはありません。このアプローチを使用することにより、ダンプファイルを圧縮できます。圧縮したファイルを EC2 インスタンスへコピーすることで、Amazon RDS へデータをコピーする際に生じるネットワークコストを抑えます。また、データはネットワークを介して送信されるため、データの安全性を確保するためにダンプファイルを暗号化することもできます。
より良いパフォーマンスを得るために、AWS ホワイトペーパー Best Practices for Migrating MySQL Databases to Amazon Aurora をご覧ください。MySQL のコマンドを使用して、Aurora MySQL クラスタのエンドポイントに接続します。
mysql のプロンプトが表示されたら、ソースコマンドを実行し、Aurora MySQL にデータを読み込むためデータベースのダンプファイル名を渡します。
パート 3: Aurora MySQL で GTID ベースのレプリケーションを使用し、変更内容を取得します
初期のデータ読み込みにはしばらく時間がかかることがあるため、レプリケーションは外部の MySQL サーバーで生じた変更点を Aurora MySQL DB クラスタへ取り込むのに役立ちます。これは、後に Aurora MySQL DB クラスタを使用するために、アプリケーションの切り替えを決定したとき、ダウンタイムを最小限に抑えるのに役立ちます。
GTID ベースのレプリケーションを使用し、変更内容を取得するには、次のステップを実行します。
- Aurora MySQL レプリカでレプリケーションを有効化する前に、Aurora MySQL クラスタのレプリカターゲットの手動スナップショットを作成するようお勧めします。こうすることで、万一問題が生じてレプリケーションを再確立しなければならなくなったとしても、Aurora MySQL レプリカターゲットに再度データをインポートすることなく、このスナップショットを復元できます。
- Aurora MySQL DB クラスタをレプリカとしてセットアップするには、マスターユーザーを使用してそれに接続し、rds_set_master_with_auto_position を使用して外部 MySQL サーバーへのレプリケーションを設定します。このストアドプロシージャが必要な変更を実行し、DB クラスタは外部マスターへ接続して、binlogs をリクエストできるようになります。さらに、グローバルトランザクション ID をベースに、レプリケーションも設定します。
注意: このストアドプロシージャは Amazon RDS MySQL で使用されると、追加パラメータを受け入れます。これは遅延レプリケーションがサポートされているためです。これに比べて、Aurora MySQL では遅延レプリケーションがサポートされていません。
- 続いて、ターゲットとなる Aurora MySQL クラスタのレプリケーションを開始します。
パート 4: Aurora MySQL レプリカでレプリケーションのステータスを確認します
次に Aurora MySQL レプリカが外部 MySQL マスターに接続可能で、GTID ベースのレプリケーションが想定通り動作することを確認します。
これを行うには、SHOW SLAVE STATUS\G; を実行し、次の 4 つの列を確認してください。次に示す数値になるはずです。
詳細については、Checking Replication Status、Slave_IO_State、Slave_SQL_Running_State を参照してください。
Slave_IO_Running: Yes と Slave_SQL_Running: Yes の値は、レプリケーションが想定通りに動作していることを意味します。ただし、定義別のレプリケーションは非同期プロセスです。つまり、データのレプリケーションに時間がかかる可能性があります。そのため、レプリケーションのずれは一定ではありません。この相違の大部分は、レプリカに適用されるマスターの書き込みボリューム、また、マスターと Aurora レプリカ間のネットワーク条件によるものです。
ご使用の Aurora クラスタと外部 MySQL サーバーが同期されていると、Seconds_Behind_Master は自然に 0 になります。これはレプリカが外部 MySQL マスターサーバーと同レベルで、すべてのバイナリログ記録が、Aurora MySQL レプリカに適用されていることを意味します。
パート 5: アプリケーションが Aurora エンドポイントを使用するように切り替えます
いよいよ、アプリケーションが Aurora クラスタエンドポイントを使用するよう切り替えるタイミングです。これを実行するには、次の 2 つの方法があります。
- オプション 1: ご使用のアプリケーションアーキテクチャ (Amazon Route 53 のドキュメントで説明されているように) で CNAME レコード を使用していない場合は、外部の MySQL サーバーをただ停止するのみです。次に、アプリケーションが Aurora クラスタエンドポイントをポイントするよう設定します。
- オプション 2: レプリケーションステータスを確認後、すべてのバイナリログが適用されていることを確認したら、外部の MySQL サーバーを読み取り専用ステートに設定します。続いて、アプリケーションが Aurora クラスタエンドポイントを参照するよう CNAME レコードを変更します (リーダーエンドポイントではなく)。このパターンを使用する場合は、CNAME レコードの TTL (time-to-live) 設定に十分注意してください (Route 53 のドキュメントにて詳述)。この設定値が高すぎると、この CNAME によってポイントされるホスト名が求めるより長くキャッシュされる可能性があります。一方、この設定値が低すぎると、クライアントアプリケーションは、この CNAME を繰り返し解決しなくてはならなくなり、クライアントアプリケーションに余分なオーバーヘッドがのしかかる可能性があります。ユースケースごとに状況は異なるものの、TTL は最初 5 秒から始めるのが良いでしょう。
まとめ
このブログ記事では、GTID ベースのレプリケーションと Amazon Aurora for MySQL のサポートの利点についてご紹介しました。Amazon Aurora MySQL データベース間のレプリケーションには多数のユースケースがあります。本ブログ記事では、GTID ベースのレプリケーションを使用して、外部の MySQL データベースを Aurora MySQL に移行する方法について解説しました。
著者について
 Vijay Karumajji はアマゾン ウェブ サービスのデータベースソリューションアーキテクトです。
Vijay Karumajji はアマゾン ウェブ サービスのデータベースソリューションアーキテクトです。