Amazon Web Services ブログ
新機能 – Amazon Comprehend Medical – ヘルスケア業界のお客様のための自然言語処理
私は胃腸科医と皮膚科医の息子で、解剖学的構造、手術手順、投薬名、またそれらの略語など、複雑な医学用語が飛び交う、専門外には理解できない会話を聞きながら育ちました。好奇心を抱いた子供にとってこの経験はとても魅惑的で、両親がある種の魔法使いのようなものなのか、またはとってもちんぷんかんぷんなことを言っているのか、と不思議に思っていました。
このような理由から、Amazon Comprehend の拡張版である、ヘルスケア業界のお客様向けの Amazon Comprehend Medical をご紹介できることは、とても嬉しく思います。
Amazon Comprehend の簡単な振り返り
Amazon Comprehend は、昨年の AWS re:Invent でローンチされたものです。簡単にいうと、言語検出、エンティティのカテゴリ分類、感情分析、キーフレーズ抽出などの、シンプルなリアルタイム API を提供する自然言語処理サービスです。さらに、テキストドキュメントを自動的に整理する、教師なし学習である「Topic modeling」もお使いいただけます。
FINRA 、LexixNexis、またはIsentiaでは、一般用途のテキストの理解に Amazon Comprehend が利用されています。しかし医療文書の特質が非常に特殊であるため、その独自のニーズに合わせた Amazon Comprehend のヘルスケアバージョンを作って欲しいという要求をいただいていました。
Amazon Comprehend Medical とは
Amazon Comprehend Medical は、Amazon Comprehend 上で動くもので、下記の特徴が追加されています。
* 生体組織、状態、手順、薬、略語など、医療用語の膨大な語彙における、エンティティの抽出とエンティティ特性についてのサポート。
* これらのカテゴリーやサブタイプに合わせて学習されたエンティティ抽出の API (detect_entities)。
* 詳細連絡先や医療登録番号等を見つけることができる、保護医療情報 (PHI) を抽出する API (detect_phi)。
注:Amazon Comprehend Medical は、すべての状況下において、正確に保護医療情報 (PHI) を識別できるわけではなく、HIPAA に基づく保護医療情報 (PHI) の匿名化の要求は満たしていません。Amazon Comprhend Medical による出力結果がお客様の用途に一致しているかどうかは、ご自身のレビューに責任を持ってください。
ここで、本サービスの使い方について説明します。まず、AWS コンソール上で、簡単な Python example を走らせてみましょう。
AWS コンソール上での Amazon Comprehend Medical の使い方
AWS コンソールを開き、分析したいテキストを貼り付け、「Analyze」ボタンをクリックしてください。

このドキュメントはただちに処理され、エンティティが抽出・ハイライトされます。例えば人の情報はオレンジ色、薬剤用語は赤色、生体組織は紫色、病状は緑色といった色分けでハイライトされます。
個人識別可能情報は正しくピックアップされています。これは、文書を交換したり出版したりする前に匿名化する必要のある研究者にとって、特に重要なものになります。また、「rash:発疹」や「sleeping trouble:睡眠障害」は、医師による病状診断と同じように、正しく検出されています(「Dx」は「diagnosis:診断」の略)。投薬名も同様に検出されています。
Amazon Comprehend Medical は、医学用語の単純な抽出の範疇を超えています。薬の投薬量や詳細の診療情報などの複雑な関係性を理解することができます。こちらが良い例になります。
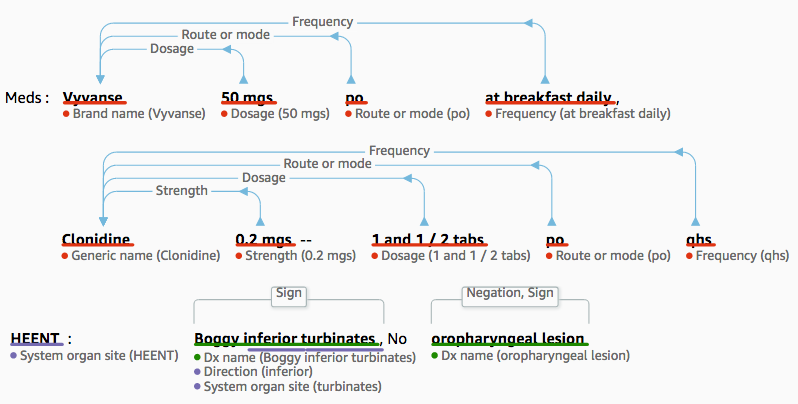
ここでわかるように、 Amazon Comprehend Medical では「po」と「qhs」のような略語の理解もできます。「po」は薬が経口投与であることを示し、「qhs」は「quaque hora somni (ラテン語)」に対応し、就寝前の意となります。
AWS SDK for Python によるAmazon Comprehend Medical の使い方
はじめに、boto3 SDKをインポートして、サービス用のクライアントを作りましょう。
import boto3
comprehend = boto3.client(service_name='comprehendmedical')次にテキストサンプルに対して detect_entity API を呼んで、検出されたエンティティを出力してみましょう。
text = "Pt is 40yo mother, software engineer HPI : Sleeping trouble on present
dosage of Clonidine. Severe Rash on face and leg, slightly itchy Meds : Vyvanse
50 mgs po at breakfast daily, Clonidine 0.2 mgs -- 1 and 1 / 2 tabs po qhs HEENT :
Boggy inferior turbinates, No oropharyngeal lesion Lungs : clear Heart : Regular
rhythm Skin : Papular mild erythematous eruption to hairline Follow-up as scheduled"
result = comprehend.detect_entities(Text=text)
entities = result['Entities']
for entity in entities:
print(entity)こちらの投薬エンティティを見てみましょう:ここでは、非常に重要な文脈を追加する、三個のネストされた属性(投薬量、経路、頻度)が含まれています。
{u'Id': 3,
u'Score': 0.9976208806037903,
u'BeginOffset': 145,
u'EndOffset': 152,
u'Category': u'MEDICATION',
u'Type': u'BRAND_NAME',
u'Text': u'Vyvanse',
u'Traits': [],
u'Attributes': [
{u'Id': 4,
u'Score': 0.9681360125541687, u'BeginOffset': 153, u'EndOffset': 159, u'Type': u'DOSAGE', u'Text': u'50 mgs', u'Traits': [] },
{u'Id': 5,
u'Score': 0.99924635887146, u'BeginOffset': 160, u'EndOffset': 162, u'Type': u'ROUTE_OR_MODE', u'Text': u'po', u'Traits': [] },
{u'Id': 6,
u'Score': 0.9738683700561523, u'BeginOffset': 163, u'EndOffset': 181, u'Type': u'FREQUENCY', u'Text': u'at breakfast daily', u'Traits': []
}]
}ここでは、別の例を示します。この病状のエンティティは、「negation:否定」という性質によって、病状が検出されなかったことを示しています。つまり、患者は口腔咽頭についての病変を持っていないことを示します。
{u'Category': u'MEDICAL_CONDITION',
u'Id': 16,
u'Score': 0.9825472235679626,
u'BeginOffset': 266, u'EndOffset': 286,
u'Type': u'DX_NAME',
u'Text': u'oropharyngeal lesion',
u'Traits': [
{u'Score': 0.9701067209243774, u'Name': u'NEGATION'},
{u'Score': 0.9053299427032471, u'Name': u'SIGN'} ]}最後の特徴として、detect_phi API を使った個人情報の抽出をご紹介します。
result = comprehend.detect_phi(Text=text) entities = result['Entities'] for entity in entities: print(entity)
いくつかの個人情報がこのテキストで示されていて、それらが正しく抽出されていることがわかります。
{u'Category': u'PERSONAL_IDENTIFIABLE_INFORMATION',
u'BeginOffset': 6, u'EndOffset': 10, u'Text': u'40yo',
u'Traits': [], u'Score': 0.997914731502533,
u'Type': u'AGE', u'Id': 0}
{u'Category': u'PERSONAL_IDENTIFIABLE_INFORMATION',
u'BeginOffset': 19, u'EndOffset': 36, u'Text': u'software engineer',
u'Traits': [],
u'Score': 0.8865673542022705,
u'Type': u'PROFESSION', u'Id': 1}ご覧の通り、Amazon Comprehend は、複雑な情報や関係性を抽出し、非常に簡単に扱うことができるようにします。
繰り返しになりますが、Amazon Comprehend Medical はプロフェッショナルな医療アドバイス、診断、治療などの代替にはならないことをご注意ください。ここで得られるどのような情報についても、決断の前に慎重に検討し、あなたの経験により判断してください。
今すぐご利用可能です
この投稿がお役に立てば幸いです。本日から、Amazon Comprehend Medical を使ったアプリケーション開発が、米国東部 (バージニア北部・オハイオ)、 米国西部 (オレゴン) 、 ヨーロッパ (アイルランド)の4リージョンでご利用可能になりました。
また、このサービスはでAWS 無料枠でご利用いただくことができます。サインアップしてから3ヶ月の間は、初めの25,000のテキストユニット(250万英字)は無料です。
あなたの最新の処方箋や健康診断で試してみてはいかがでしょうか?お試しの結果を、私たちにぜひフィードバックください。
– ジュリアン
翻訳は、Machine Learning SA 宇都宮が担当しました。原文は こちら。