Amazon Web Services ブログ
Amazon MSK Serverless が一般提供開始 – マネージド Kafka クラスターのキャパシティープランニングが不要に
2022 年 4 月 28 日(米国時間)、Amazon MSK Serverless の一般公開を開始し、容量プランニングとスケーリングを AWS にオフロードすることで、Apache Kafka クラスター管理のオペレーションオーバーヘッドをさらに削減できるようにいたします。
2019 年 5 月、お客様が Apache Kafka を使用してデータをストリーミングできるように、Amazon Managed Streaming for Apache Kafka をリリースしました。Apache Kafkaは、お客様がクリックストリームイベント、トランザクション、IoT イベントなどのストリーミングデータをキャプチャできるようにするオープンソースプラットフォームです。Apache Kafka は、ストリーミングデータを生成するアプリケーション (プロデューサー) とデータを消費するアプリケーション (コンシューマー) を切り離す一般的なソリューションです。Amazon MSK では、フルマネージド型の Apache Kafka クラスターを使用して、ストリーミングデータをリアルタイムで簡単に取り込み、処理できます。
Amazon MSK は、本番環境で Apache Kafka をセットアップ、スケーリング、管理するために必要な作業を減らします。Amazon MSK を使用すると、クラスターを数分で作成し、データの送信を開始できます。Apache Kafka は 1 つ以上のブローカーでクラスターとして実行されます。ブローカーは、高可用性を実現するために複数の AWS アベイラビリティーゾーンに分散された特定のコンピューティングおよびストレージ容量を持つインスタンスです。Apache Kafka は、ユーザー定義の一定期間、トピックに関するレコードを保存し、それらのトピックを分割してから、これらのパーティションを複数のブローカーにレプリケートします。データプロデューサーはトピックにレコードを書き込み、コンシューマーはトピックからレコードを読み取ります。
新しい Amazon MSK クラスターを作成するときは、ブローカーの数、インスタンスのサイズ、および各ブローカーが使用できるストレージを決定する必要があります。MSK クラスターのパフォーマンスは、これらのパラメーターによって異なります。これらの設定は、ワークロードがわかっている場合は簡単に指定できます。しかし、新しいワークロード用に Amazon MSK クラスターをどのように設定しますか? または、変動するデータトラフィックまたは予測不可能なデータトラフィックがあるアプリケーションの場合ですか?
Amazon MSK Serverless
Amazon MSK Serverless は、アプリケーションにオンデマンドストリーミング容量とストレージを提供するために必要なリソースを自動的にプロビジョニングおよび管理します。必要な容量がわからない場合や、アプリケーションが予測できないスループットや非常に変動するスループットを生成し、アイドル容量にお金を払いたくない場合に、新しい Apache Kafka ワークロードを開始するのに最適なソリューションです。また、クラスターのリソース使用率のプロビジョニング、スケーリング、管理を避けたい場合に便利です。
Amazon MSK Serverless には、プライベート接続など、すぐに使用できる多くの安全な機能が付属しています。これは、トラフィックが AWS のバックボーンである、 AWS Identity and Access Management (IAM) アクセスコントロールの管理課にあり、保存中および転送中もデータが暗号化され、セキュリティが維持されることを意味します。
Amazon MSK Serverless クラスターは、アプリケーション要件に基づいて容量を即座に拡大または縮小します。Apache Kafka クラスターが水平方向にスケーリングされる (つまり、ブローカーが追加される) 場合、追加された容量を利用するために、これらの新しいブローカーにパーティションを移動する必要もあります。Amazon MSK Serverless では、ブローカーのスケーリングやパーティションの移動を行う必要はありません。
それぞれの Amazon MSK Serverless クラスターは、最大 200 MBps の書き込みスループットと 400 MBps の読み取りスループットを提供します。また、パーティションごとに最大 5 MBps の書き込みスループットと 10 MBps の読み取りスループットも割り当てます。
Amazon MSK Serverless の料金はスループットに基づいています。詳細については、MSK の料金ページをご覧ください。
それでは、実際に機能しているところを見てみましょう。
あなたがモバイルゲームスタジオのアーキテクトであり、新しいゲームを開始しようとしていると想像してみてください。このゲームのマーケティングに投資しましたが、新しいプレーヤーがたくさんいることを期待しています。ゲームはクリックストリームデータをバックエンドアプリケーションに送信します。データはリアルタイムで分析され、プレイヤーの行動を予測します。こうした予測により、ゲームは現在のプレイヤーの行動に合ったリアルタイムのオファーを提供し、ゲームに長く留まるように促します。
ゲームはクリックストリームデータを Apache Kafka クラスターに送信します。Amazon MSK Serverless クラスターを使用しているので、新しいゲームの起動時にクラスターのスケーリングについて心配する必要はありません。クラスターの容量はスループットに合わせて調整されるからです。
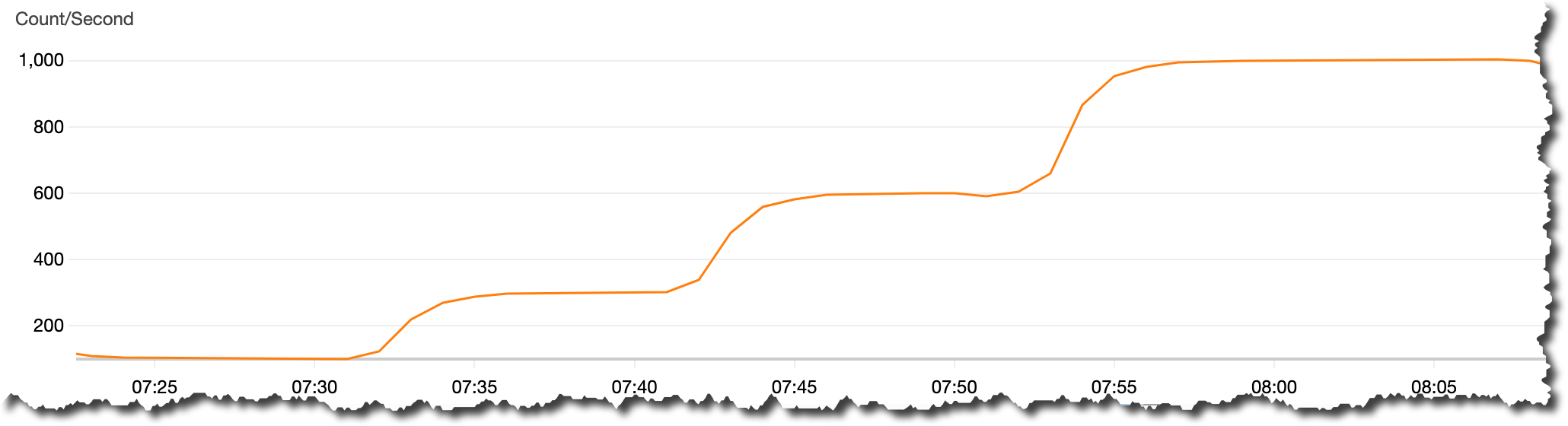
次の画像では、新しいゲームの起動日のグラフを見ることができます。クラスターが消費しているメトリクス MessagesInPerSec がオレンジ色で表示されます。また、起動前の基本数である 100 から始まり、まず 1 秒あたりのメッセージ数が増加していることがわかります。その後、ゲームがダウンロードされ、より多くのプレイヤーによってプレイされるにつれて、毎秒 300、600、1,000 メッセージに増加します。レコードの量は増え続けると確信できます。Amazon MSK Serverless は、アプリケーションのスループットがサービスの制限内である限り、すべてのレコードを取り込むことができます。
Amazon MSK Serverless の使用を開始する方法
Amazon MSK Serverless クラスターの作成は、サービスに容量設定を行う必要がないので、非常に簡単です。Amazon MSK コンソールページで新しいクラスターを作成できます。
[クイック作成] クラスター作成方法を選択します。この方法では、スタータークラスターを作成し、クラスターの名前を入力するためのベストプラクティス設定が提供されます。
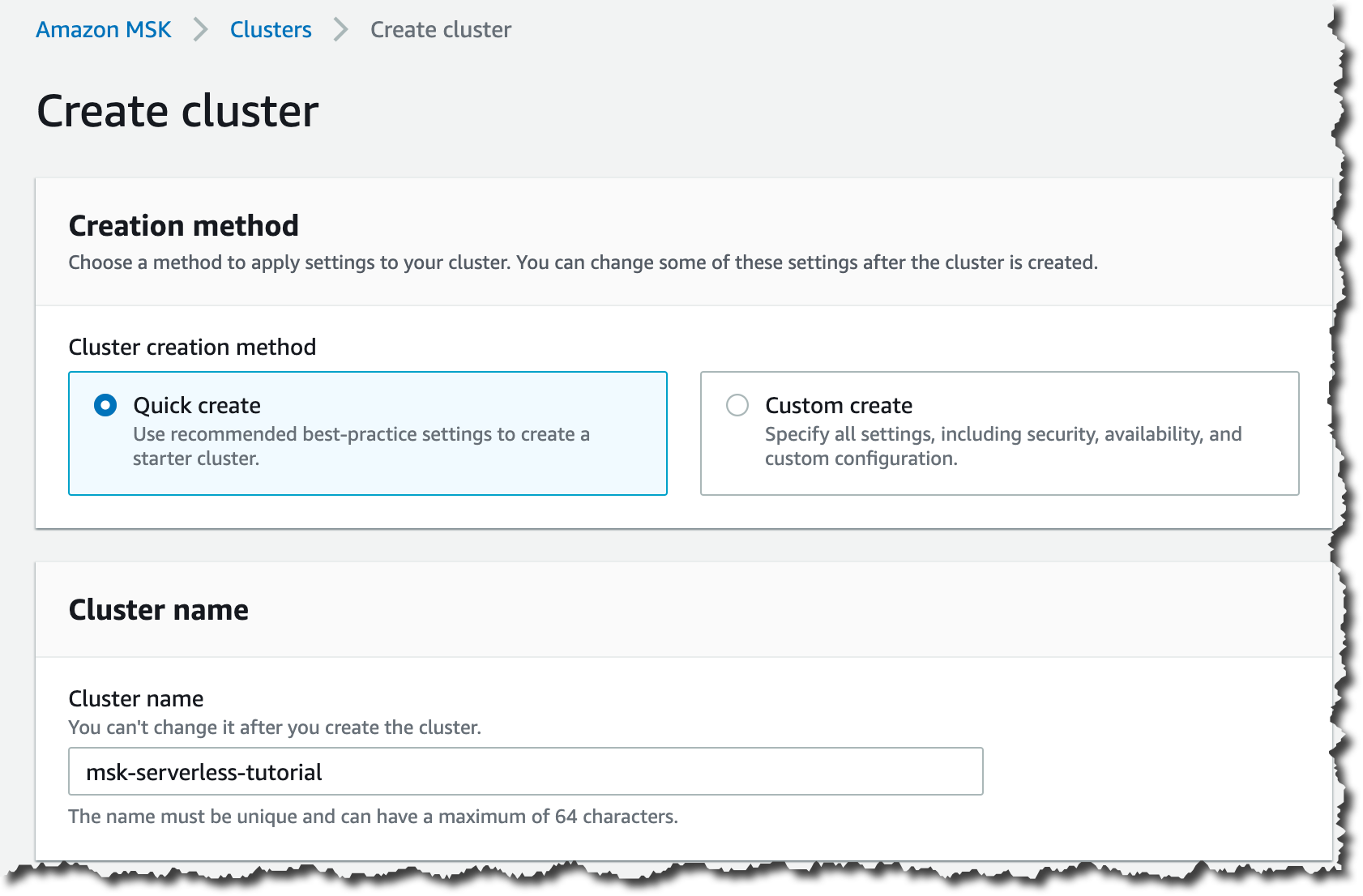
次に、[全般] クラスタープロパティで、クラスタータイプを選択します。Amazon MSK Serverless クラスターを作成するには、[サーバーレス] オプションを選択します。

最後に、デフォルトで設定されるすべてのクラスター設定が表示されます。これらの設定のほとんどは、クラスターの作成後は変更できません。これらの設定にデフォルトとは異なる値が必要な場合は、Custom create メソッドを使用してクラスターを作成する必要があります。デフォルト設定が適切であれば、クラスターを作成します。

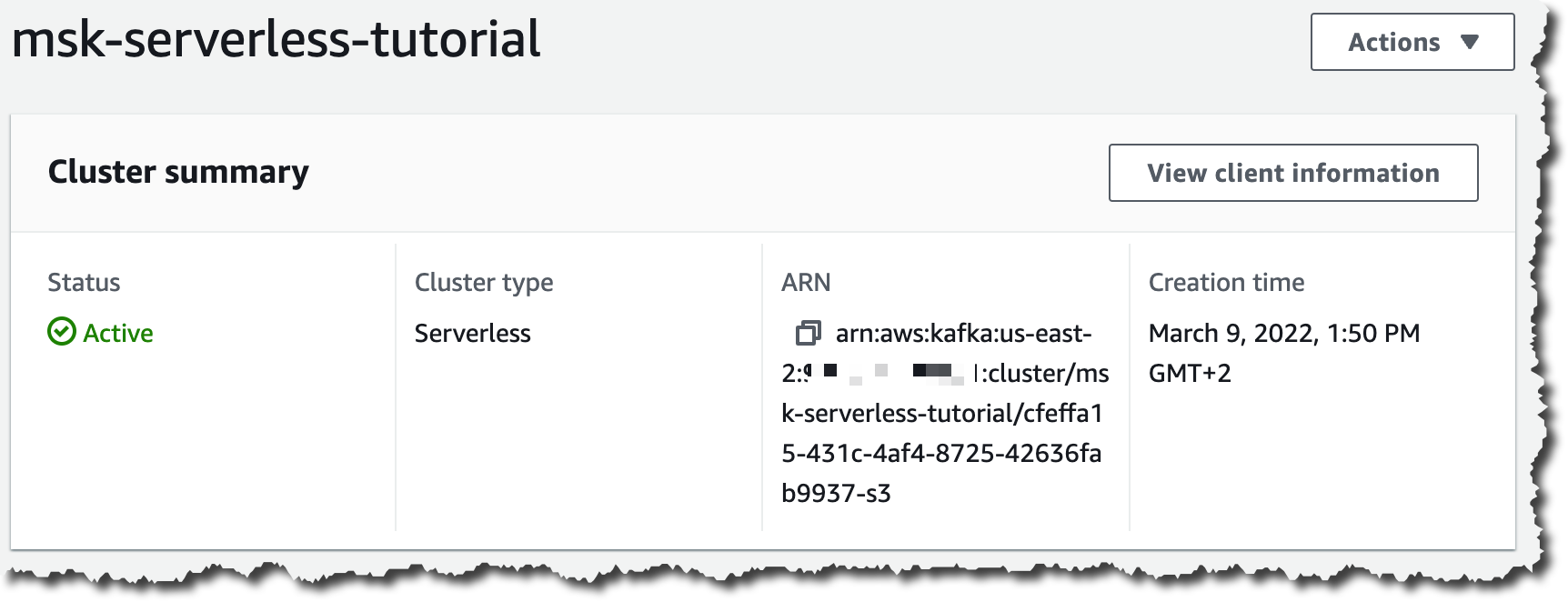
クラスターの作成には数分かかります。その後、[クラスターの概要] ページに [アクティブ] ステータスが表示されます。
これでクラスターができたので、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを使用してレコードの送受信を開始できます。そのための最初のステップは、新しい IAM ポリシーと IAM ロールを作成することです。インスタンスは、インスタンスからクラスターにアクセスするために IAM を使用して認証する必要があります。
Amazon MSK Serverless は IAM と統合され、Apache Kafka ワークロードへのきめ細かなアクセスコントロールを提供します。IAM ポリシーを使用して、Apache Kafka クライアントへの最小特権アクセスを許可できます。
IAM ポリシーを作成する
次の JSON を使用して新しい IAM ポリシーを作成します。このポリシーは、クラスターに接続し、トピックを作成し、データを送信し、トピックからデータを消費する許可を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:cluster/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:DescribeTopic",
"kafka-cluster:CreateTopic",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:topic/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/msk-serverless-tutorial"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": "arn:aws:kafka:<REGION>:<ACCOUNTID>:group/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/*"
}
]
}
リージョンとアカウント ID は必ずご自分のものに置き換えてください。また、クラスター、トピック、グループ ARN も置き換える必要があります。これらの ARN を取得するには、クラスターの概要ページに移動して、クラスター ARN を取得します。トピック ARN とグループ ARN は、クラスター ARN に基づいています。ここでは、クラスターとトピックの名前は msk-serverless-tutorial です。
"arn:aws:kafka:<REGION>:<ACCOUNTID>:cluster/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3"
"arn:aws:kafka:<REGION>:<ACCOUNTID>:topic/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/msk-serverless-tutorial"
"arn:aws:kafka:<REGION>:<ACCOUNTID>:group/msk-serverless-tutorial/cfeffa15-431c-4af4-8725-42636fab9937-s3/*"次に、ユースケース EC2 で新しいロールを作成し、このポリシーをロールにアタッチします。

新しい EC2 インスタンスを作成する
クラスターとロールができたので、新しい Amazon EC2 インスタンスを作成します。クラスターと同じ VPC、サブネット、セキュリティグループにインスタンスを追加します。その情報は、ネットワーク設定のクラスターのプロパティページにあります。また、インスタンスを設定するときに、前のステップで作成したロールを添付します。

準備ができたら、インスタンスを起動します。メッセージを生成して消費するために同じインスタンスを使用します。そのためには、インスタンスに Apache Kafka クライアントツールを設定する必要があります。Amazon MSK デベロッパーガイドに従って、インスタンスを準備します。
レコードの作成と消費
これですべての設定が完了したので、Amazon MSK Serverless を使用してレコードの送受信を開始できます。最初に行う必要があるのは、トピックを作成することです。EC2 インスタンスから、Apache Kafka ツールをインストールしたディレクトリに移動し、ブートストラップサーバーエンドポイントをエクスポートします。
cd kafka_2.13-3.1.0/bin/
export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098Amazon MSK Serverless を使用しているため、このサーバーにはアドレスが 1 つしかなく、クラスターページのクライアント情報で確認できます。

次のコマンドを実行して、msk-serverless-tutorial という名前のトピックを作成します。
./kafka-topics.sh --bootstrap-server $BS \
--command-config client.properties \
--create --topic msk-serverless-tutorial --partitions 6これでレコードの送信を開始できます。高いスループットでサービスが動作することを確認したい場合は、Apache Kafka プロデューサーパフォーマンステストツールを使用できます。このツールを使用すると、定義されたスループットと特定のサイズで、MSK クラスターに多数のメッセージを同時に送信できます。このパフォーマンステストツールを試して、1 秒あたりのメッセージ数とレコードサイズを変更し、クラスターの動作と容量の調整を確認します。
./kafka-topics.sh --bootstrap-server $BS \
--command-config client.properties \
--create --topic msk-serverless-tutorial --partitions 6最後に、メッセージを受信する場合は、新しいターミナルを開き、同じ EC2 インスタンスに接続し、Apache Kafka コンシューマーツールを使用してメッセージを受信します。
cd kafka_2.13-3.1.0/bin/
export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098
./kafka-console-consumer.sh \
--bootstrap-server $BS \
--consumer.config client.properties \
--topic msk-serverless-tutorial --from-beginningAmazon MSK Serverless クラスターのモニタリングページで、クラスターの動作を確認できます。

利用可能なリージョン
Amazon MSK Serverless は、現時点で米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (ストックホルム)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京) の各リージョンで使用可能です。
このサービスと価格の詳細については、Amazon MSK Serverless 機能ページをご覧ください。
– Marcia
原文はこちらです。