Amazon Web Services ブログ
Amazon SageMaker での機械学習で、Amazon Pinpoint キャンペーンを加速
成功した多くのビジネスの中心には、顧客に対する深い理解があります。以前のブログ記事では、AWS データレイク戦略の一環として Amazon Redshift Spectrum を使用することで、全方向の顧客イニシアティブを強化する方法を説明しました。
このブログ記事では、敏捷性、コスト効率、そして AWS が顧客分析の実践を通じてどのように革新を起こすのかを実証するテーマを続けたいと考えています。みなさんの多くは、AI がどのようにして顧客イニシアティブを強化できるかを探っているでしょう。そこで、Amazon SageMaker と Amazon Pinpoint を活用したソリューションを通じて、ターゲットとするキャンペーンを機械学習 (ML) によってどのように推進できるかを実証します。
小売りの例を見てみましょう。消費者として、私たちには購入習慣の直感があります。私たちは、良い経験をした製品を再購入する傾向があります。あるいは、逆に、不満足な経験の結果として代替製品に移る可能性があります。三部作の一部である本を購入した場合、そのシリーズの次の本を購入する可能性が高くなります。スマートフォンを購入すると、近い将来にアクセサリーを購入する可能性が高くなります。
顧客の購買行動を知る能力があればどうなるでしょうか?次の購入がどうなるかを比較的高い確率で知ることができたら、どうすればいいでしょうか?私たちがこの予測能力を持っていれば、対処できる多くのことがあります。たとえば、在庫管理の効率を改善したり、マーケティングキャンペーンのパフォーマンスを向上させることができます。
このブログ記事では、Amazon SageMaker を使用してカスタムの長・短期記憶リカレントニューラルネットワーク (LSTM RNN) モデルを構築、トレーニング、使用して購入行動を予測し、予測を活用して Amazon Pinpoint によるキャンペーンを配信する方法を紹介します。 RNN は、特殊なタイプのニューラルネットワークであり、ML のアルゴリズムです。RNN は、通常、シークエンスデータと共に使用します。一般的なアプリケーションとしては、音声のテキストへの変換、言語の翻訳、¥感情分析などの自然言語処理 (NLP) の問題があります。このケースでは、少し創造的になり、UCI 機械学習リポジトリからダウンロードした 現実のオンライン小売データセット[i] の顧客取引履歴に RNN モデルを適用します。
課題
ソリューションに入る前に、こうしたプロジェクトをコンセプトから本番運用に移行する際の課題を理解してみましょう。標準的な ML プロセスを考えてみましょう。
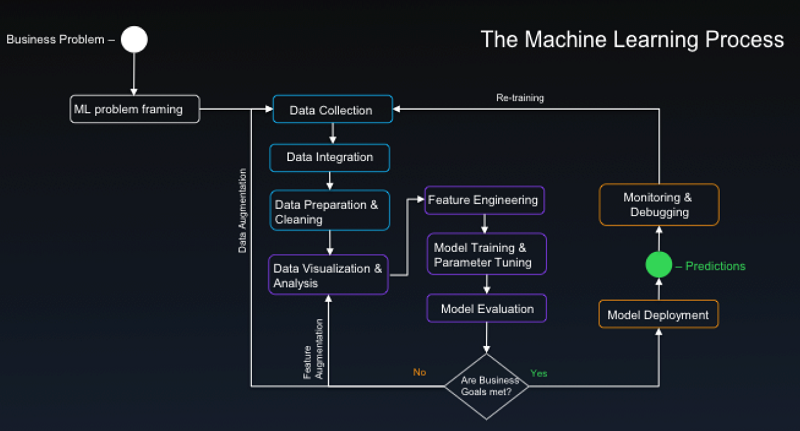
いくつかの重要な観察があります。
- このプロセスには、データエンジニアリングプロジェクトに共通のデータパイプラインが含まれているため、大規模なビッグデータの課題に直面します。このブログで紹介しているデータセットは小規模ですが、Amazon.com などの大手小売業者の類似データセットはビッグデータの規模であり、さまざまなフォーマットのバッチやストリームから集められています。モデルのパフォーマンスが向上するため ML プロジェクトには大量のデータが適していますが、データを大規模に活用するには適切なプラットフォームが必要です。AWS データレイク戦略は、運用の複雑さを最小限に抑え、コスト効率を最大化する、将来を見越したソリューションを提供することができます。AI イニシアチブだけでなく、他のデータエンジニアリングプロジェクトでも、引き続き基盤が実を結ぶことになります。
- 多様な活動をサポートする必要があります。多様な活動は、チームメンバーの役割やスキルセットに最も適した豊富な種類のツールの必要性につながります。データ処理、発見、大規模な機能エンジニアリングなどの活動には、Spark のようなツールが適しています。AWS では、Amazon EMR が Spark クラスターの管理を促進し、スポット料金によってコストを最小化しながら、伸縮自在なスケーリングのような機能を可能にします。プロトタイピングのためには Keras や Gluon などのフレームワークが好まれるかもしれませんが、開発の後期段階でのトレーニングやモデル提供のための主要エンジンとしては TensorFlow や MXNet が適しています。どのフレームワークが適切であるかは、ユースケースとチームのスキルセットによって異なります。Amazon SageMaker のように ML フレームワークに依存しないプラットフォームが理想的です。ネイティブの Amazon SageMaker アルゴリズムを利用するか、選択したフレームワーク上に構築された独自のスクリプトまたはコンテナを使用してカスタムモデルを作成するかを選択できます。
- このプロセスは非常に反復的です。したがって、反復間の時間を最小化することが、生産性にとって非常に重要です。各反復の大部分は、ハイパーパラメータのチューニングと呼ばれるプロセスです。これらのパラメータの最良の値は、モデル、データセット、目的ごとに一意であるため、実験によって発見する必要があります。時には、パラメータが多く、1 つのパラメータを変更するとリップル効果が生じることがあり、このプロセスが困難である場合があります。パラメータを調整するたびに、モデルが再学習および評価され、モデルの複雑さやデータサイズとともにトレーニング時間も増加します。ターンアラウンドタイムを最小限に抑えるために、しばしば GPU が活用され、サーバークラスターを使用して分散トレーニングを実行する方法もあります。これによって、待ち時間が数日ではなく数時間、数時間ではなく数分という違いになります。サービスとして GPU で分散トレーニングを提供できる Amazon SageMaker のようなプラットフォームを使用することで、使った分だけ支払う方式によって実質的な生産性向上とコスト効率化を実現できます。データ科学者および機械学習エンジニアは、希少で高価なリソースです。このプロセスのボトルネックを最小限に抑えることは、無駄がないチームを維持するために不可欠です。
- この絵は不完全です。同じ重要性のものが、この絵に描かれていません。分析実践の有効性は、ビジネスに還元する価値によって評価されます。モデルやエンドポイントを提供することは、意図したビジネス成果の帰結ではないかもしれません。Amazon SageMaker は、Auto Scaling API エンドポイントの ML モデルへのデプロイメントを自動化します。AWS プラットフォームの残りの部分は、幅広いサービスとの統合を通じて、エンドユーザが ML モデルを活用して対処可能にすることで、目標に向かってさらに一歩進んでいきます。こうした統合は、アプリケーションやストリームにリアルタイムの推論を提供したり、エンタープライズデータウェアハウス (EDW) やビジネスインテリジェンス (BI) のプラットフォームに予測分析をもたらす形で可能です。このブログ記事の後半では、Amazon Pinpoint が予測を使用してパフォーマンスが高いキャンペーンを提供する方法を紹介します。
予測的なキャンペーンのソリューション
次の図は、私が提示しようとしているソリューションの概念的なアーキテクチャを示しています。このソリューションは Amazon SageMaker を活用して、私が説明した ML プロセスを容易にします。それでは、アーキテクチャに描かれている 4 つのステップを見てみましょう。
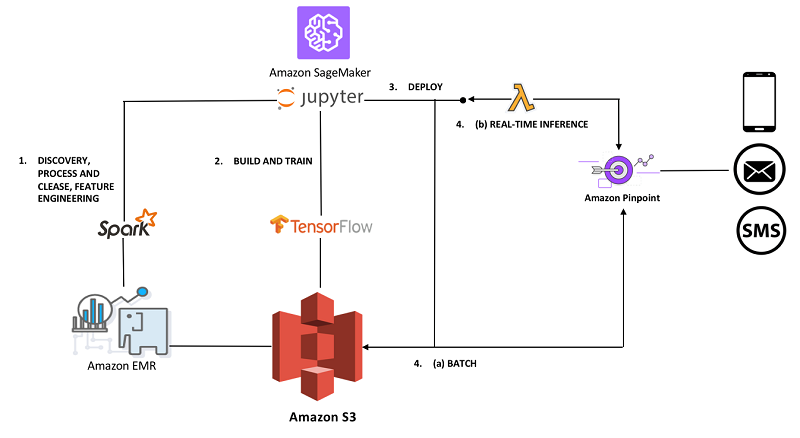
1. データエンジニアリング: データセットは、Amazon S3 データレイクに保存されます。このソリューションを構築するための第一歩は、Amazon SageMaker マネージドの Jupyter ノートブックのデプロイです。
この最初のノートブックは、Spark での実行を選択したデータのクレンジング、処理、発見、および機能エンジニアリングの作業をキャプチャします。Spark は、大規模なデータセットを処理する能力と、他の有用なユーティリティの中でもデータ検出のための SQL サポートの便利さから、これらのアクティビティのために私が選んだツールです。SageMaker ノートブックインスタンスは、外部 Amazon EMR クラスターに対して実行するように設定できます。スポット料金を通じて Amazon EMR で Spark を伸縮自在かつ経済的に拡張できる機能は、この探索段階で価値があります。多くの場合、この段階でパイプラインを最適化するために時間を費やすことは価値がありません。代わりに、クラスターを一時的にスケールアウトすることがチームを俊敏に保つ戦略です。
2. 構築およびトレーニング: TensorFlow でカスタムモデルを構築し、Amazon SageMaker の分散トレーニング機能を活用することを選択しました。このノートブックは、データセットの学習と検証の準備から、Amazon SageMaker でのカスタム TensorFlow モデルのトレーニングとデプロイメントまでの残りの ML プロセスを示しています。
次の図は、実装されている LSTM RNN モデルのアーキテクチャを示しています。

概念的には、 RNN をモデル化して一連の入力の条件付き確率を推定することができます。この場合、シーケンスは顧客ベースの注文履歴です。過去に購入したものが、将来購入する商品に影響します。以前購入した商品の履歴から、次に購入する可能性が高い商品を予測することができます。間違いなく、特定の状況ではこのアプローチを上回るモデルがあります。製品の推奨および評価を含む顧客データを保有している場合、これらの機能を活用する予測モデルが場合によってはより効果的になる可能性があります。多くのデータがある場合は、双方向性を備えた多層 RNN のような、より複雑なモデルが、より良い結果につながる可能性があります。予測能力を向上させるもう 1 つの方法は、ブースティングでアンサンブルを構築することです。そのアイデアを試すことは、みなさんに残しておきます!
この Python スクリプトは、前述の LSTM RNN モデルを、Amazon SageMaker のトレーニングおよびモデル提供と互換性のある方法で定義します。開発者は、ドキュメントに記載されているインターフェイスを実装するだけです。このインターフェイスは、Custom Estimator の TensorFlow インターフェイスに似ています。リモートトレーニングを実行するのは、SageMaker TensorFlow オブジェクトを作成し、fit メソッドを呼び出すだけです。分散トレーニングを実行するには、1 より大きい train_instance_count パラメータで TensorFlow オブジェクトをインスタンス化し、global_step の値が tf.train.get_or_create_global_step() であるアルゴリズムでトレーニング操作をインスタンス化する必要があります。 (これは、分散トレーニングを実行するための TensorFlow フレームワークの件です。)
私のノートブックを実行する人は、それぞれの実行ごとに異なる結果を観察するかもしれません。これは、ML アルゴリズムの非決定論的特質の結果として予想されますが、データセットが比較的小さく、モデルを再トレーニングするたびにデータセットでランダムな分割とシャッフルが発生することによっても増幅されます。
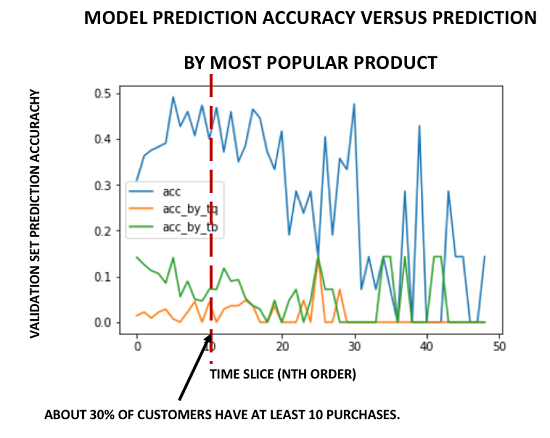
それにもかかわらず、今までの注文が 11 件未満である検証データセットの顧客が次に購入する 3648 のうち最も可能性の高い製品を予測するためには、20-50% の予測精度を獲得する必要があります。このモデルは、発注件数が 2 〜 50 件である注文履歴を持つ顧客に対してトレーニングを受けていますが、10 件以上の発注履歴を持つ顧客は比較的少ないです。このため、データセットの制約のため、このモデルを使用して予測を行うのは、注文数が 10 件以下の顧客だけとしました。下のグラフは、私がトレーニングを行ったモデルの予測精度を示しています (青色)。最も頻繁な購入 (緑色) および最も売れたユニット (オレンジ色) によって最も人気のある製品を予測するナイーブモデルの予測精度と比較しています。繰り返しになりますが、トレーニングと検証セットのランダムなシャッフルにより、さまざまな結果が観察されます。それでも、これらのケースでは 2 ~ 15% の範囲の精度が見込まれます。
3. デプロイ: Amazon SageMaker のモデルをトレーニングした後、モデルに対して Auto Scaling API エンドポイントを作成するには、単に deploy メソッドを呼び出すだけです。事前トレーニング済みのモデルの 1 つをデプロイする場合は、検証セットを使用して次の購入を予測することができます。私のケースでは、発注が 10 件以下の検証セットから、次に購入するものを予測しました。データセット全体からテストデータをサンプリングすることができます。ただし、正規化手法を適用しているにもかかわらず、過剰適合の兆候が見られたため、トレーニングセットのデータを使用しないようにしました。明確にするために、検証セットを使用して、注文履歴シーケンスで次の既知の購入の予測精度を測定することにより、モデルが正常に実行され一般化されるようにしました。今度は、このデータセットの顧客の次の未知の購入を予測する別の目的のために再度使用します。たとえば、9 件の注文の履歴がある顧客の 10 回目の購入を予測します。観察される予測の分布は以下のようになるはずです。
4. バッチおよびリアルタイム推論: 今すぐ、対処する時です。これらの予測を活用して、さまざまなキャンペーンの目標を推進することができます。たとえば、図のステップ 3 の製品の選択についてプロモーションを実行することができます。こうした予測を活用して、コンバージョン率の高いトラフィックを特別なイベントに誘導することができます。このセクションの上部にあるソリューションアーキテクチャ図で概念的に示されているように、こうした予測を Amazon Pinpoint に提供してマーケティングキャンペーンを推進する方法はいくつかあります。リアルタイムのモバイルプッシュが予測されたプロモーションを提供する適切な方法であるなら、ショッピングカートの状態が更新されたときに予測エンドポイントを呼び出す AWS Lambda 関数をトリガするシステムを設計して、エンドユーザーにモバイルプッシュを行うことができます。プロセスは次のようになります。

また、予測をバッチ処理し、マーケティングチームが Amazon Pinpoint にインポートしてキャンペーンを立ち上げることができるデータレイクでカタログ化することもできます。AWS マネジメントコンソールを使用してこれを行うことができます。このサンプルのエンドポイントファイルを使用して、試してみてください。このエンドポイントファイルには、私たちのモデルが次に「Rabbit Night Light」を購入すると予測する顧客の一群が含まれています。このファイルには、人口統計などの標準属性と、顧客に到達できるチャネルおよびアドレスが含まれています。さらに、カスタム属性を追加することもできます。このケースでは、予測される製品 ID のカスタム属性を追加しました。この属性は、コンテンツを動的にパーソナライズするためにキャンペーンのメッセージ本文内で利用することができます。たとえば、このカスタム属性を使用して、予測された製品の画像を動的に参照することができます。
このデータをインポートするための最初のステップは、セグメントを作成することです。セグメントは、Amazon S3 からエンドポイントファイルをインポートすることで作成できます。
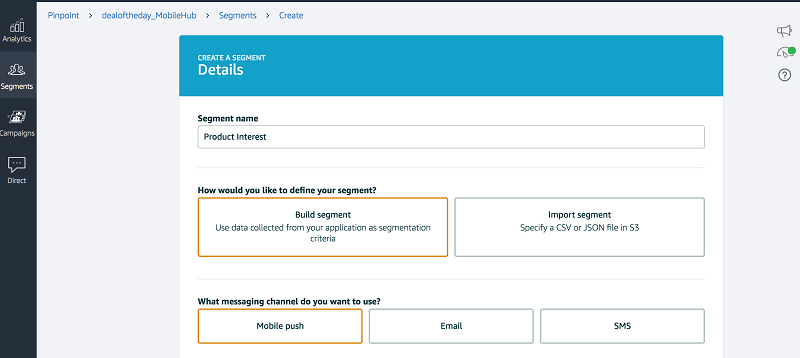
インポートジョブが「COMPLETED」状態になるのを待ちます。

セグメントを作成すると、キャンペーンを開始できます。
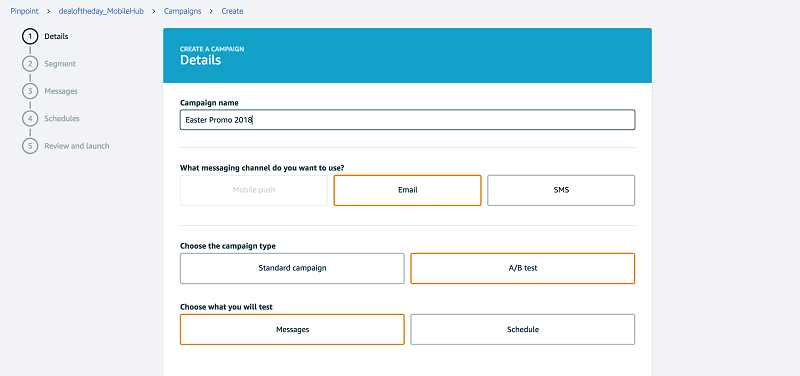
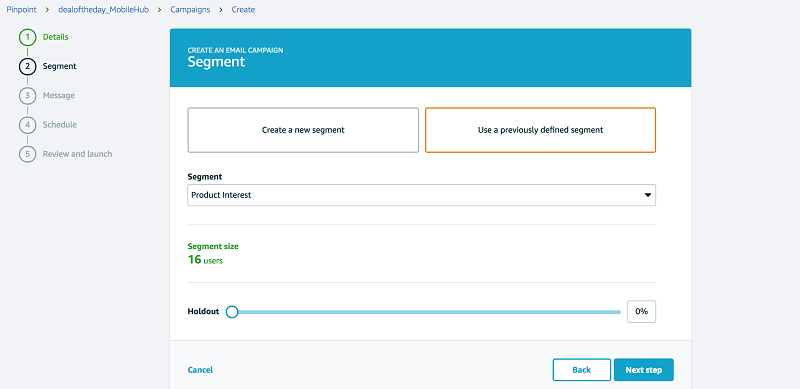
作成したばかりのセグメントを、キャンペーンのターゲットグループとして選択します。
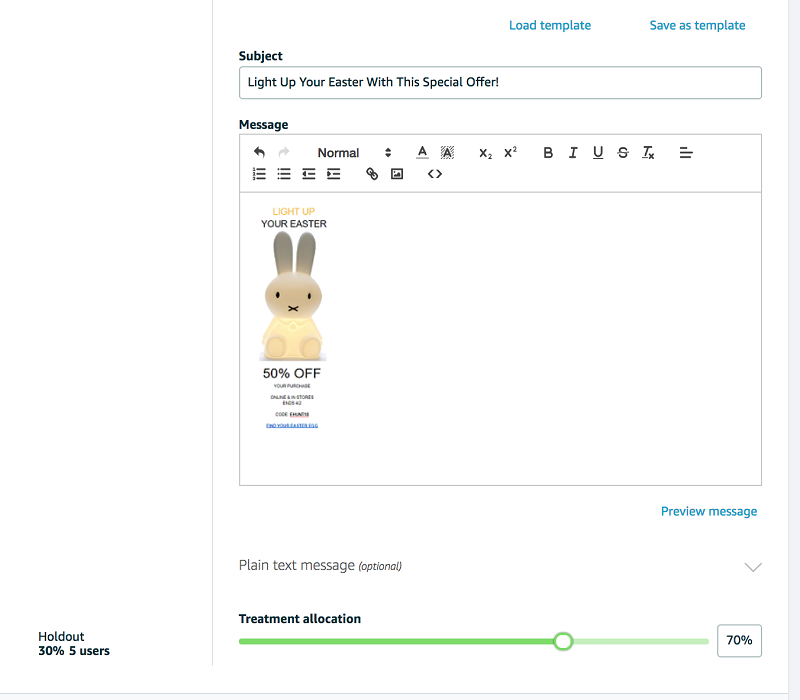
キャンペーンのメッセージを制作します。A/B テストでキャンペーンを開始する場合は、各処理グループごとにメッセージを制作する必要があります。
最後に、キャンペーンのスケジュールを設定します。
これで、キャンペーンを開始しました!ただし、まだ仕事は終わっていません。キャンペーンと予測モデルのパフォーマンスを個別に測定する戦略があることを確認してください。
- キャンペーンのパフォーマンスは、メッセージを制作して提示する方法によって影響を受ける可能性があります。Amazon Pinpoint の A/B テストを活用して、メッセージングのバリエーションのパフォーマンスを測定します。
- 検証セットは、モデルのパフォーマンスの良い尺度ではないかもしれません。 データセットに欠陥があるか、不十分である可能性があります。本番運用での実際のパフォーマンスをテストする戦略が必要です。1 つの戦略は、コントロールグループを維持することです。Amazon Pinpoint tは、セグメントにホールドアウト率を指定できるようにすることで、これを容易にすることができます。また、Amazon Pinpoint Amazon Kinesis の統合活用してキャンペーンイベントを取得することもできるので、キャンペーンやモデルのパフォーマンスを診断および測定するための追加データが利用できます。
- ML モデルの開発は反復的なプロセスです。本番運用でモデルのさまざまなバージョンを検証する戦略が必要です。Amazon SageMaker に組み込まれた A/B テスト機能を活用して、この作業を容易にすることができます。
- 最後になりましたが、重要なこととして、ビジネスに提供する価値を測定します。たとえば、e コマースのコンバージョン率に関する一般的な統計を考えてみましょう。インターネット上のさまざまなサイトでは、コンバージョン率が 1 〜 5% の範囲で、オープン率は 10 〜 60% の範囲であるとレポートされています。予測精度の高い予測モデルがあり、魅力的なパーソナライズされたコンテンツを作ることができたらどうでしょうか?競争優位性は重要です。Amazon Pinpoint の分析機能を使用して、キャンペーンのパフォーマンス、アプリの使用状況、収益の帰属などのメトリクスを追跡して提示することで、ビジネスに対する予測的なキャンペーンの効果を証明しましょう。
まとめ
このブログ記事では、Amazon SageMaker、Amazon Pinpoint、AWS データレイク戦略の助けを借りて、組織が AWS プラットフォームでデータサイエンスとマーケティングをどのように統合できるかを実証しました。オートメーション、サーバーレスのアーキテクチャ、使った分だけ支払う方式を通じてレベルを引き上げる結果を高速かつコスト効率よく提供する方法を示す予測的なキャンペーンのソリューションを使用しました。
実り多いキャンペーンを!
—————————
[i] データセット提供者からの引用要求: Daqing Chen、Sai Liang Sain、Kun Guo、Data mining for the online retail industry: A case study of RFM model-based customer segmentation using data mining, Journal of Database Marketing and Customer Strategy Management, Vol. 19, No. 3, pp. 197–208, 2012 (印刷前にオンラインで公開: 2012 年 8 月 27 日doi: 10.1057/dbm.2012.17).
今回のブログ投稿者について
 Dylan Tong は、AWS のエンタープライズソリューションアーキテクトです。 彼は、優れたアーキテクチャーを備えたソリューションの設計についてのリーダーシップと指導を通じて、顧客と協力して AWS プラットフォームでの成功を促進するために働いています。彼は、リーダーやイノベーターとともに働いて、データの管理と分析に関する専門知識の構築に自身のキャリアの大部分を費やしてきました。
Dylan Tong は、AWS のエンタープライズソリューションアーキテクトです。 彼は、優れたアーキテクチャーを備えたソリューションの設計についてのリーダーシップと指導を通じて、顧客と協力して AWS プラットフォームでの成功を促進するために働いています。彼は、リーダーやイノベーターとともに働いて、データの管理と分析に関する専門知識の構築に自身のキャリアの大部分を費やしてきました。