Amazon Web Services ブログ
Amazon SageMaker BlazingText: 複数の CPU または GPU での Word2Vec の並列化
AWS は、Amazon SageMaker の最新組み込みアルゴリズムとして Amazon SageMaker BlazingText をリリースします。BlazingText は、Word2Vec 埋め込みを生成するための教師なし学習アルゴリズムです。大規模コーパスには単語の密なベクトル表現があります。Word2Vec の最高速実装である BlazingText が、以下を使用する Amazon SageMaker ユーザーにご利用いただけるようになりました。
- シングル CPU インスタンス (Mikolov によるオリジナルの C 実装および fastTextなど)
- 複数の GPU を備えたシングルインスタンス、P2 または P3
- マルチ CPU インスタンス (分散 CPU トレーニング)
単一の p3.2xlarge (Volta V100 GPU 1 個) インスタンス上の BlazingText は、単一の c4.2xlarge インスタンス上の fastText よりも 21 倍速く、20% 割安になる場合があります。 複数の CPU ノード全体における分散トレーニングでは、BlazingText は 8 個の c4.8xlarge インスタンス上で 1 秒間最大 5 千万単語のトレーニング速度を達成できます。これは 1 つの c4.8xlarge fastText CPU 実装よりも 11 倍の速さで、埋め込みの品質への影響も最低限です。
Word2Vec
メッシについて検索するときに、サッカーやバルセロナについての結果を検索エンジンに返させるにはどうすればよいでしょうか。より効率的に分類またはクラスタリングを実行できるように、単語間の関係を明示的に定義することなくマシンにテキストデータを理解させるにはどうすればよいでしょうか。その答は、単語の意味、意味的関係、および単語が使用されている異なるタイプの文脈をキャプチャする単語の表現の作成にあります。
Word2Vec は、教師なし学習の使用によって大規模コーパス内の単語の密なベクトル表現を生成するために用いられる人気のアルゴリズムです。結果として生成されるベクトルは、対応する単語間の意味的関係をキャプチャすることが証明されています。ベクトルは、センチメント分析、固有表現抽出、および機械翻訳などの多くのダウンストリーム NLP (自然言語処理) タスクのために幅広く利用されています。
次のセクションでは、実装の詳細について説明します。ご利用開始にあたってセクションに直接進んで、3 つの異なるアーキテクチャのためのアルゴリズムの使用方法の例を見ることもできます。
モデリング
Word2Vec は、単語の密なベクトル表現を学習するニューラルネットワーク実装です。単語表現の学習には、他のディープまたは反復ニューラルネットワークも提案されていますが、これらは Word2Vec と比べて相当長い時間がかかります。Word2Vec は、教師なしの方法によって、学習された密な埋め込みベクトル (モデルのパラメーターと見なされる) という観点で、単語を隣接語から直接予測しようとします。
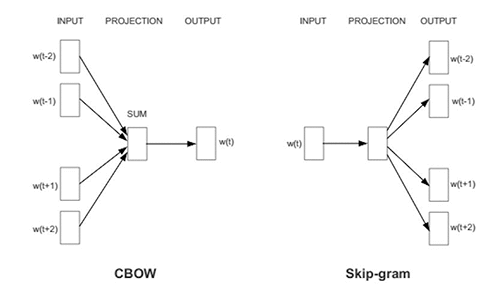
Word2Vec には、Contextual Bag-Of-Words (CBOW) および Skip-Gram with Negative Sampling (SGNS) という 2 つの独特なモデルアーキテクチャがあります。CBOW の目的は文脈を前提として単語を予測することですが、skip-gram は単語を前提として文脈を予測しようとします。実行してみると、skip-gram がより良いパフォーマンスを提供しますが、速度は遅くなります。
Word2Vec における最適化は、問題を反復的に解決する確率的勾配降下法 (SGD) を使用して行われます。Word2Vec は各ステップで、そのウィンドウから、またはランダムなネガティブサンプルから、単語のペア (入力単語とターゲット単語) を選びます。その後、選択した 2 つの単語に関して目的関数の勾配を計算し、勾配値に基づいて 2 つの単語の単語表現を更新します。それから、アルゴリズムは次の反復に進み、異なる単語ペアを選びます。
マルチコアおよびメニーコアアーキテクチャにおける分散
SGD の主な問題のひとつは、それが本質的にシーケンシャルであることです。ひとつの反復からの更新と、次の反復における計算には依存性があるため (同じ単語表現に接触する場合がある)、各反復は、完了するために前の反復からの更新を待たなければならない可能性があります。このため、ハードウェアの並列リソースを使用することができなくなります。
HogWild パラレル SGD
Hogwild は、異なるスレッドが異なる単語ペアを並行的に処理し、モデル更新フェーズで生じる可能性がある衝突を無視するスキームです。理論的に、これはシーケンシャル動作と比べればアルゴリズムの収束率を削減することができます。しかし、Hogwild アプローチは、スレッド全体の更新が同じ単語に対するものである可能性が低い場合にうまく機能することがわかっています。確かに、大規模な語彙サイズでの衝突は比較的まれで、通常収束には影響しません。
HogBatch パラレル SGD
Word2Vec 実装のほとんどは、シングルノード、マルチコア CPU アーキテクチャ用に最適化されています。しかし、これらはメモリ帯域幅集中型の Hogwild 更新でのベクトル対ベクトル演算に基づくもので、計算リソースを効率的に使用しません。
Shihao Ji らは、アルゴリズム内での様々なデータ構造の再利用を改善するために HogBatch というアイデアを導入しました。これは、ミニバッチとネガティブサンプル共有の使用を通じて行われます。これにより、行列乗算演算 (level 3 BLAS) を使用した問題の表現が可能になります。 BlazingText は CPU への Word2Vec のスケールアウトのために HogBatch を使用し、その計算をコンピューティングクラスター内のノード全体に分散することができます。
GPU における Word2Vec のスケーリング
マルチコアおよびメニーコアアーキテクチャの場合における Word2Vec に対する Hogwild/Hogbatch アプローチの成功のため、このアルゴリズムは GPU の利用に対する良い候補となります。GPU は、CPU より数倍もの並列処理を実現します。Amazon SageMaker BlazingText は、GPU を使用して Word2Vec を高速化するための効率的な並列処理手法を提供します。この実装は、GPU の並列処理機能を過剰に利用することで出力の精度を損なうことなく、CUDA マルチスレッディング性能を最適に活用するよう設計されています。多数のスレッドが同じ単語ベクトルの同時読み取りおよび書き込みを行わないように、並列処理レベルと同期化レベル間のトレードオフを管理するための慎重な検討が行われています。このため、トレーニングプロセスを迅速化しながらも良好な精度が維持されています。
BlazingText は、データ並列処理アプローチを使用することによって、複数の GPU を活用するための Word2Vec のスケールアウトも行います。これは GPU 全体のモデルウェイトの効率的な同期化を行います。GPU 実装の詳細については、BlazingText 論文を参照してください。
BlazingText のシングルインスタンスモードは HogWild (CBOW と skip-gram) および HogBatch (batch_skipgram) 両方をサポートするのに対し、分散 CPU モードは HogBatch skip-gram (batch_skipgram) をサポートします。
以下の表は、Amazon SageMaker BlazingText 向けの異なるアーキテクチャでサポートされるモードの概要です。
| ハードウェアタイプ/モード | CBOW | skip-gram | batch_skipgram |
| シングルインスタンス (CPU) | ✔ | ✔ | ✔ |
| 分散 (CPU) | ✔ | ||
| シングルインスタンス (1 個または複数の GPU) | ✔ | ✔ |
Amazon SageMaker での BlazingText パフォーマンス
AWS では、fastText CPU 実装に対して Amazon SageMaker BlazingText のベンチマークを行い (サブ単語埋め込みなし)、標準的な単語類似度テストセットであるWS-353で、スループット (100万単語/秒) と学習された埋め込みの精度を報告します。
ハードウェア: 実験はすべて Amazon SageMaker で行いました。BlazingText については、シングル GPU インスタンス (p3.2xlarge、p2.xlarge、p2.8xlarge、p2.16xlarge) およびシングル/マルチ CPU インスタンス (c4.2xlarge、c4.8xlarge) でのパフォーマンス数値を報告します。BlazingText は、GPU インスタンスでは CBOW および skip-gram モード、CPU インスタンスでは batch_skipgram モードを使用して実行されました。fastText は、シングル CPU インスタンスで CBOW および skip-gram を使用して実行しました。
なお、CBOW および skip-gram を使用したシングル CPU インスタンスでは BlazingText のパフォーマンスが fastText のものと互角であるため、ここではこれらの数値を報告しません。
コーパスのトレーニング: モデルは One Billion Word Benchmark データセットで訓練しました。
ハイパーパラメーター: すべての実験に関し、CBOW、skip-gram、および batch_skipgram モード (ネガティブサンプリング使用)、ならびに fastText デフォルトパラメーター設定 (ベクトルの次元 = 100、ウィンドウサイズ = 5、サンプリングしきい値 = 1e~4、初期学習率 = 0.05) を使用した結果を報告します。

One Billion Word ベンチマークデータセットでのスループット比較 (100万単語/秒)
このグラフからわかるように、同じタイプのハードウェアでは最も早いのが CBOW、次に batch_skipgram、skip-gram の順となっています。しかし、CBOW の精度は最良ではありません。これは以下の表を見れば明らかです。

BlazingText ベンチマーキング – トレーニングには One Billion Words Benchmark データセット、評価には WS-353 データセットを使用しました
BlazingText は複数の GPU と、複数の CPU インスタンス全体での分散計算を活用できるため、fastText よりも数倍速くなります。しかし、最良のインスタンス構成を選択するには、埋め込みの品質 (精度)、スループット、およびコスト間のバランスを取らなければなりません。上記のバブルチャートは、これらの側面をとらえたものです。
バブルチャート内の円はそれぞれ、異なるアルゴリズムモードとハードウェア構成での BlazingText または fasttext トレーニングジョブのパフォーマンスを表しています。円の半径は、スループットに正比例します。以下の表は、チャートにあるジョブ番号に対応する異なるジョブの詳細を示すものです。BlazingText は複数の GPU と、複数の CPU インスタンス全体での分散計算を活用できるため、fastText よりも数倍速くなります。しかし、最良のインスタンス構成を選択するには、埋め込みの品質 (精度)、スループット、およびコスト間のバランスを取らなければなりません。
| ジョブ番号 | 実装 | インスタンス | インスタンス数 | モード | 100万単語/秒でのスループット | 精度 | コスト (USD) |
| 1 | fastText | ml.c4.2xlarge | 1 | skip-gram | 1.05 | 0.658 | 1.24 |
| 2 | fastText | ml.c4.8xlarge | 1 | skip-gram | 3.49 | 0.658 | 1.67 |
| 3 | fasttext | ml.c4.2xlarge | 1 | CBOW | 3.62 | 0.6 | 0.41 |
| 4 | fasttext | ml.c4.8xlarge | 1 | CBOW | 12.36 | 0.599 | 0.63 |
| 5 | blazingtext | ml.p2.xlarge | 1 | skip-gram | 2.58 | 0.655 | 1.25 |
| 6 | blazingtext | ml.p2.8xlarge | 1 | skip-gram | 11.82 | 0.635 | 3.1 |
| 7 | blazingtext | ml.p2.16xlarge | 1 | skip-gram | 23.52 | 0.613 | 4.49 |
| 8 | blazingtext | ml.p3.2xlarge | 1 | skip-gram | 22.16 | 0.658 | 0.97 |
| 9 | blazingtext | ml.p2.xlarge | 1 | CBOW | 9.92 | 0.602 | 0.44 |
| 10 | blazingtext | ml.p2.8xlarge | 1 | CBOW | 44.93 | 0.576 | 1.69 |
| 11 | blazingtext | ml.p2.16xlarge | 1 | CBOW | 79.16 | 0.562 | 2.89 |
| 12 | blazingtext | ml.p3.2xlarge | 1 | CBOW | 32.65 | 0.601 | 0.82 |
| 13 | blazingtext | ml.c4.2xlarge | 1 | batch_skipgram | 2.65 | 0.647 | 0.53 |
| 14 | blazingtext | ml.c4.2xlarge | 2 | batch_skipgram | 4.1 | 0.637 | 0.74 |
| 15 | blazingtext | ml.c4.2xlarge | 4 | batch_skipgram | 7.15 | 0.632 | 0.95 |
| 16 | blazingtext | ml.c4.2xlarge | 8 | batch_skipgram | 12.54 | 0.621 | 1.36 |
| 17 | blazingtext | ml.c4.8xlarge | 1 | batch_skipgram | 9.96 | 0.641 | 0.77 |
| 18 | blazingtext | ml.c4.8xlarge | 2 | batch_skipgram | 15.6 | 0.637 | 1.15 |
| 19 | blazingtext | ml.c4.8xlarge | 4 | batch_skipgram | 28.26 | 0.63 | 1.75 |
| 20 | blazingtext | ml.c4.8xlarge | 8 | batch_skipgram | 52.41 | 0.628 | 2.9 |
パフォーマンスの注目点
表はトレードオフのより包括的な見解を示していますが、以下にその数点を紹介します。
- ジョブ 1 対ジョブ 8: p3.2xlarge (Volta GPU) インスタンス上の BlazingText は、精度およびコストの両方で最良のパフォーマンスを提供しています。これは fastText (c4.2xlarge 上) と比べてほぼ 21 倍速く、20% 割安になり、同じ精度を提供します。
- ジョブ 2 対ジョブ 17: CPU で batch_skipgram を使用する BlazingText は、FastText skipgram と比べて 2.5 倍速く、50% 割安になり、精度もわずかに下回るだけです。
- ジョブ 17~20: データセットサイズが非常に大きい場合 (> 50 GB) は、複数の CPU インスタンスで batch_skipgram モードの BlazingText を使用します。インスタンス数を増加させることによって速度がほとんど線形に加速され、精度の低下もわずかです。これらの低下は、ダウンストリーム NLP アプリケーションに応じて、許容可能な範囲内であるかもしれません。
ご利用開始にあたって
BlazingText はテキスト文書に基づいてモデルを訓練し、単語からベクトルへのマッピングを含むファイルを返します。他の Amazon SageMaker アルゴリズムと同様に、BlazingText もトレーニングデータ、および結果として生じるモデルアーティファクトの保存には Amazon Simple Storage Service (Amazon S3) を利用しています。Amazon SageMaker はトレーニング中、お客様に代わって Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを自動的に開始し、停止します。
モデルの訓練後は、Amazon S3 から結果の単語埋め込み辞書をダウンロードできます。他の Amazon SageMaker アルゴリズムとは異なり、このモデルをエンドポイントにデプロイすることはできません。この場合、推論が単なるベクトルルックアップだからです。Amazon SageMaker ワークフローの一般的な高レベルの概要については、Amazon SageMaker のドキュメントを参照してください。
データのフォーマット
BlazingText は、トークンがスペースで区切られ、各行に単一の文が含まれる、単一の前処理されたテキストファイルを期待します。複数のテキストファイルは単一のファイルに連結するようにしてください。BlazingText はテキストの前処理手順を一切実行しません。このため、コーパスに「apple」および「Apple」が含まれている場合、それらのために 2 つの異なるベクトルが生成されます。
トレーニングのセットアップ
トレーニングジョブを開始するには、低レベルの AWS SDK for Python (Boto3)、または AWS マネジメントコンソールのどちらかを使用できます。ハードウェア構成とハイパーパラメーターを指定したら、Amazon S3 にあるトレーニングデータの位置を指定する必要があります。BlazingText では、トレーニングデータが「train」チャネルに含まれている必要があります。
その他のリソース
詳細については、BlazingText ドキュメントを参照してください。または、Amazon SageMaker ノートブックインスタンスからのこの新しいアルゴリズムを使った実践ウォークスルーについては、BlazingText 例のノートブックを参照してください。このノートブックは、アルゴリズムを使用できる各種モードについて説明し、カスタマイズ可能なハイパーパラメーターをいくつか提供します。
今回のブログの投稿者について
 Saurabh Gupta は、AWS ディープラーニングの応用科学者です。Saurabh はカリフォルニア大学サンディエゴ校で AI と機械学習の修士号を取得しました。現在、Amazon SageMaker の自然言語処理アルゴリズムの構築に携わっています。
Saurabh Gupta は、AWS ディープラーニングの応用科学者です。Saurabh はカリフォルニア大学サンディエゴ校で AI と機械学習の修士号を取得しました。現在、Amazon SageMaker の自然言語処理アルゴリズムの構築に携わっています。
 Vineet Khare は AWS ディープラーニングのサイエンスマネージャーです。Vineet は、研究最先端の手法を使用して AWS のカスタマーのために人工知能および機械学習アプリケーションを構築することに焦点を当てています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。
Vineet Khare は AWS ディープラーニングのサイエンスマネージャーです。Vineet は、研究最先端の手法を使用して AWS のカスタマーのために人工知能および機械学習アプリケーションを構築することに焦点を当てています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。