Amazon Web Services ブログ
Amazon SageMaker Ground Truth — 高い精度のデータセットを構築し、ラベル付けのコストを最大70%削減
1959年、アーサー・サミュエルは機械学習を「明示的にプログラムされなくても新しいことを学べる能力をコンピュータに与える学問分野」と定義しました。しかし、機械仕掛けの神 (deus ex machina) など存在せず、学習プロセスにはアルゴリズム (「どのように学ぶか」) と学習用データセット (「何から学ぶか」) が必要です。
今日では、ほとんどの機械学習タスクは教師あり学習という技術を用いており、アルゴリズムはラベル付けされたデータセットからパターンや行動を学習します。ラベル付けされたデータセットにはデータサンプルに加え、それぞれに対する正しい答え、すなわち “ground truth” が含まれています。手元の問題に合わせて、ラベル付きの画像 (「これは犬」「これは猫」) を使ったり、ラベル付きのテキスト (「これはスパム」「これは違う」) を使ったりします。
幸運なことに、開発者とデータサイエンティストは (Amazon SageMaker のビルトインアルゴリズムにあるような) 莫大な種類の既成品アルゴリズムとサンプルデータセットを頼りにすることができます。深層学習は MNIST、CIFAR-10 や ImageNet などの画像データセットを普及させ、さらに機械翻訳やテキスト分類のようなタスクが利用できるようになりました。このようなサンプルデータセットは初心者と経験豊富な実践家の双方にものすごく便利なものですが、それでも多くの企業・組織では独自データセットでモデルを学習させる必要があります。医用画像や自動運転などについて考えてみて下さい。
このようなデータセットを構築するのは、特に大規模であるほど複雑な問題となります。1人の人間が千枚の画像あるいは文書をラベル付けするのにどれくらいの時間がかかるでしょう?恐らく「かなり長い時間」というのが答えです!では百万枚の画像や文書を持っていることを想像してみて下さい、何人の人が必要でしょうか?ほとんどの企業や組織ではここが論点になっていて、とにかくそれだけの人を集めることは不可能に近いはずです。
もうそんなことに悩む必要はありませんよ!本日 (2018/11/28) Amazon SageMaker Ground Truth を発表できて本当に嬉しく思います。これは Amazon SageMaker の新機能で、機械学習システムの学習に必要なデータセットの効率的・高精度なラベル付けをお客様が簡単に行えるようにするサービスです。
Amazon SageMaker Ground Truth のご紹介
Amazon SageMaker Ground Truth は以下のデータセットの構築をお手伝いします。
- テキスト分類
- 画像分類 (画像を特定のクラスに分類する)
- 物体検出 (画像内の物体の位置をバウンディングボックスとともに取得)
- セマンティック・セグメンテーション (ピクセル精度で画像内の物体の位置を取得)
- ユーザ定義のカスタムタスク
Amazon SageMaker Ground Truth は必要に応じてアクティブラーニングを使用し、インプットデータのラベル付けを自動化することもできます。アクティブラーニングは機械学習のテクニックで、人によりラベル付けされるべきデータと機械がラベル付けできるデータを特定する手法です。自動化されたデータのラベル付けには Amazon SageMaker の学習・推論のコストがかかりますが、人手で全データセットをラベル付けするのに比べて、コスト (最大70%) と時間を削減することができます。
手作業が必要な場合は、クラウドソーシングのマーケットプレイスである Amazon Mechanical Turk で50万人以上のワーカーの労働力、プライベートな労働力として独自のワーカー、あるいは AWS Marketplace に記載された精選されたサードパーティベンダーをお選び頂くことが可能です。
データセットをラベル付けするための大まかなステップについてみていきましょう。
- データを Amazon S3 に保存する
- ラベリングワークフォースの作成
- ラベリングジョブの作成
- 仕事に取り掛かる
- 結果を可視化する
例はないのかって?CBCL StreetScenes データセット内の画像をラベル付けする方法をお見せしましょう。このデータセットは3548個の以下のような画像を含んでいます。結果を簡潔に表示するため、はじめの10枚の画像のみを使い、車のみをアノテートします。

データを Amazon S3 に保存する
はじめのステップはデータセットのマニフェストファイルを作成することです。これはデータセットにある全ての画像を記述するシンプルな JSON ファイルです。私のはこのようなものです、なお各行がひとつのオブジェクトに対応していて、各行が独立した JSON ドキュメントになっていることに注意して下さい。
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00002.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00003.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00004.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00005.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00006.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00007.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00008.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00009.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00010.JPG"}そして、マニフェストファイルと対応する画像を Amazon S3 のバケットにコピーします。
ラベリングワークフォースの作成
Amazon SageMaker Ground Truth は3つの選択肢を与えてくれます。
- パブリックワークフォース (Amazon Mechanical Turk)
- プライベートワークフォース (内部リソース)
- ベンダーワークフォース (サードパーティリソース)
ひとつ目の選択肢が恐らく最もスケールする方法です。しかし、秘匿性・サービス保証・特殊スキルの要求されるジョブに関しては、下の2つの方が適しているかもしれません。
私の場合は自分だけが頼りなので、新しい Amazon Cognito グループで認証されたプライベートなチームを作成します。実際、ワーカーがデータセットにアクセスする前には認証が必要となります。
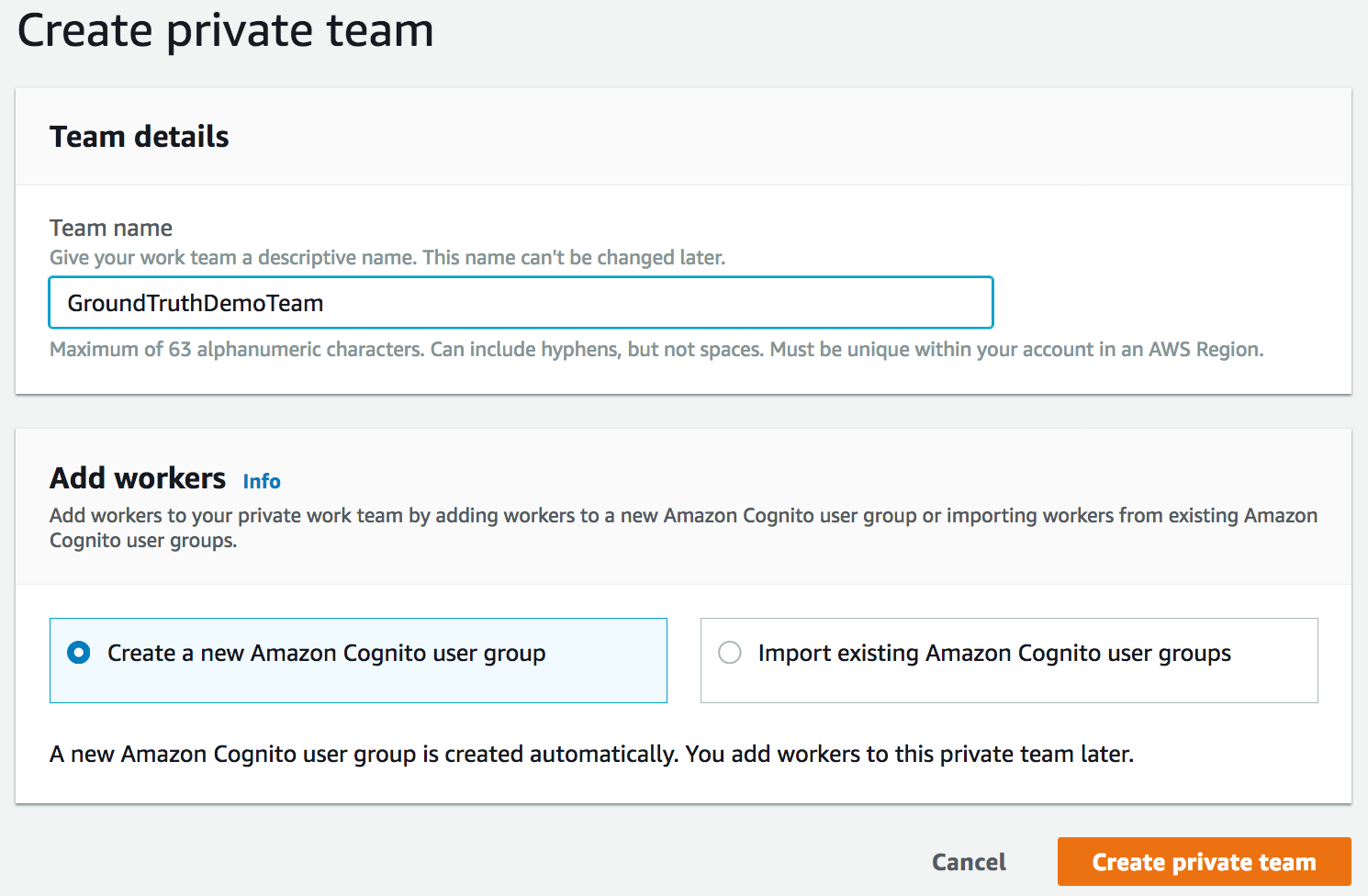
そして、自分の email アドレスを入力して自分をチームに追加します。数秒後、認証情報と URL の書かれた招待メールが届きます。この URL はラベリングワークフォースのダッシュボードからも確認できます。

リンクをクリックしてパスワードを変更すると、認証済みのワーカーとしてチームに登録されます。

1人チームの準備が完了しました。ラベリングジョブ自体を作成しましょう。
ラベリングジョブの作成
ご想像のとおり、マニフェストファイルとデータセットの場所を定義する必要があります。
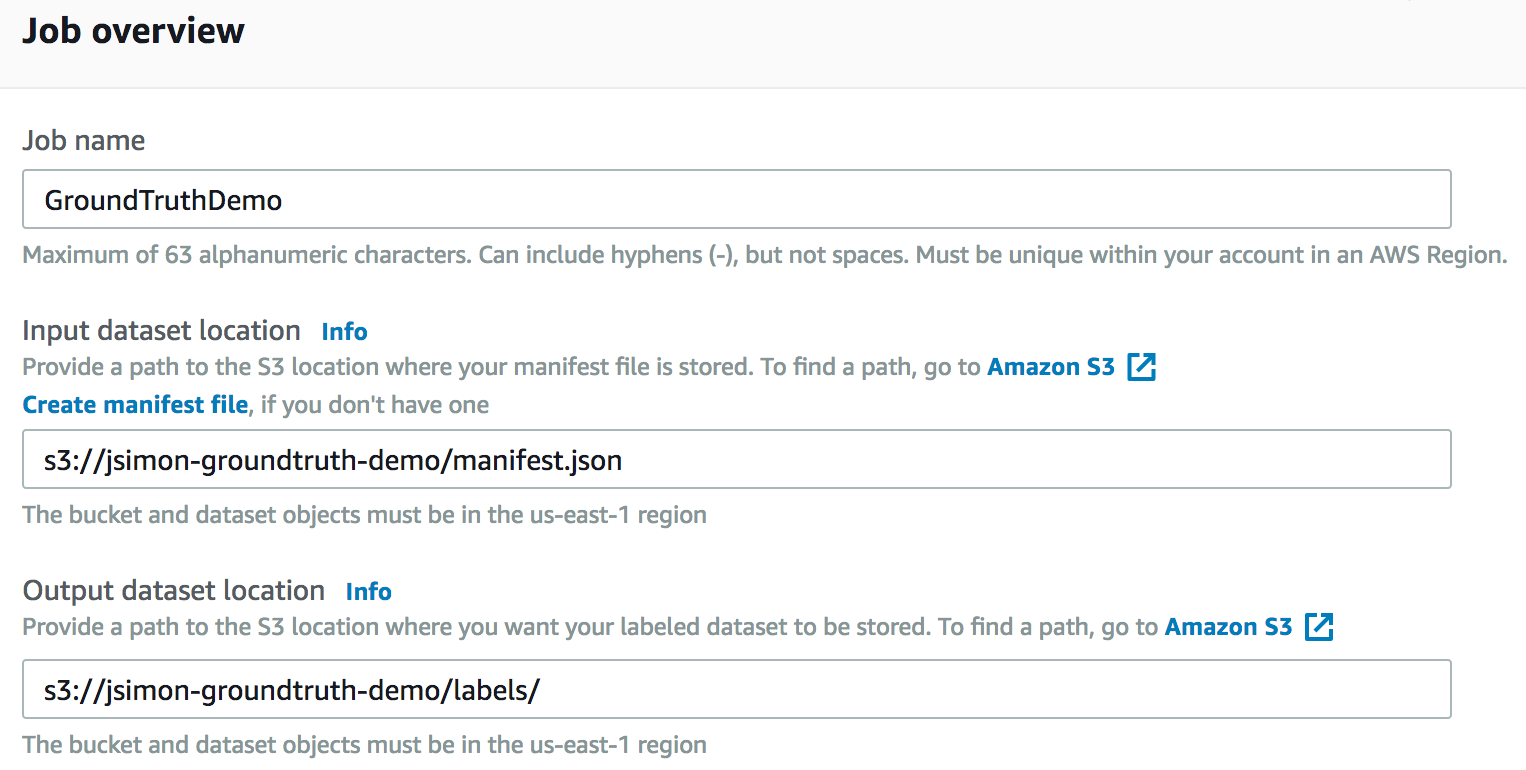
すると、全データセットを使うのか、その一部を使うのかを決めることができ、ファイルをフィルターするために SQL クエリを書くこともできます。今回は10枚しか画像がないのでフルデータセットを使いましょう。

次に、ラベリングジョブの種類を選びます。はじめに述べたように複数の選択肢があり、今回は画像にバウンディングボックスを付けようと思います。
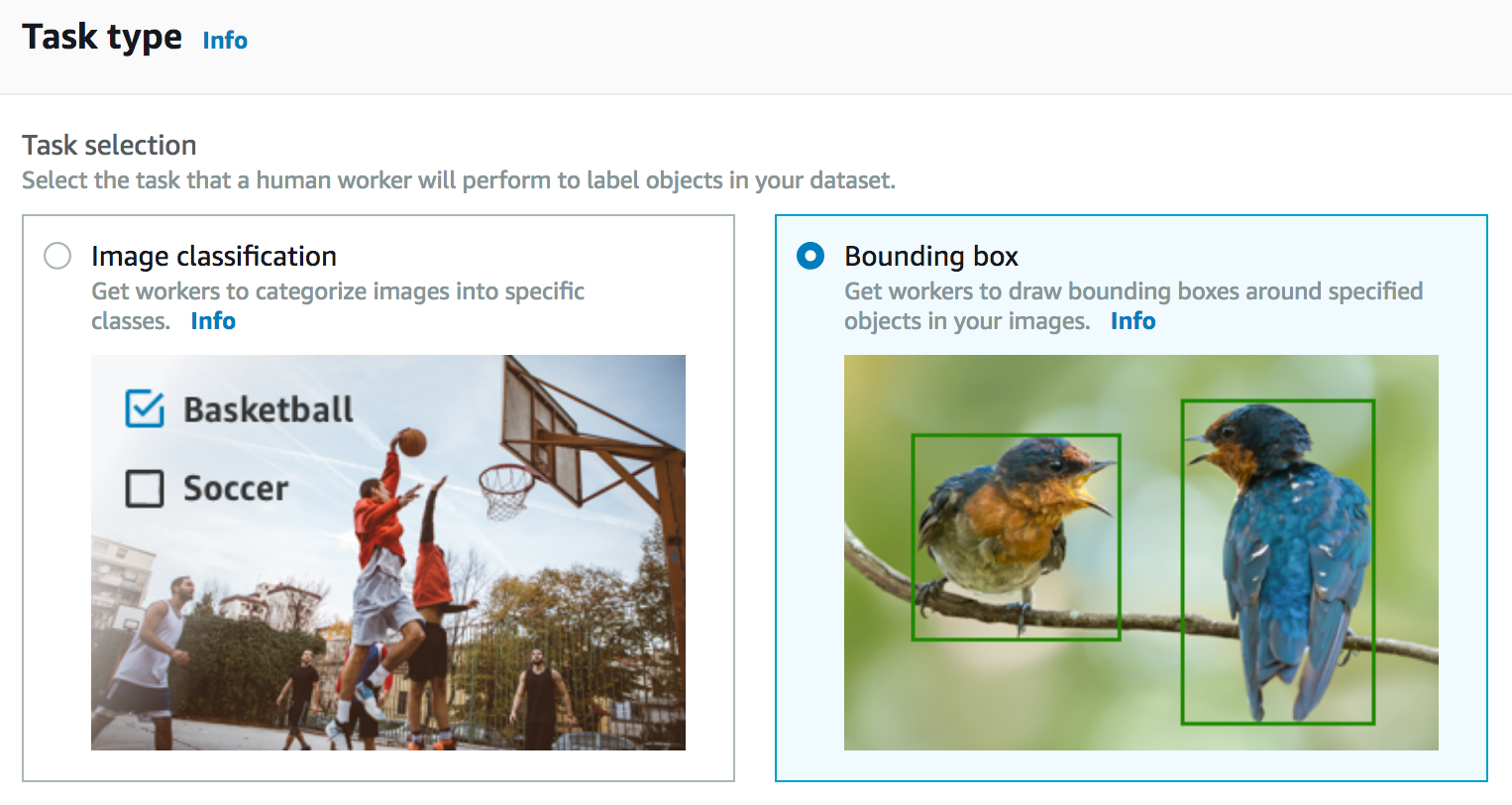
次に、ジョブをアサインしたいチームを選びます。ここでは自動データラベリングを選ぶこともできます。精度を高めるため、一つの画像を複数ワーカーにラベル付けしてもらうこともできます。

最後に、ワーカーに追加の指示を出して、特定タスクの詳細や例を出すことができます。

これで終わりです。ラベリングジョブは提出されました。あとはチーム (実際は…私ですが) が働く番です。

画像にラベルを付ける
メールで受け取った URL からログインすると、自分にアサインされたジョブの一覧が見えます。

“Start working” ボタンをクリックすると、はじめにとりかかる画像とともに、説明が表示されます。ツールボックスを使って四角形を書いたりズームイン・アウトなどができます。とても直感的ですが、思い通りに四角を書くには時間と注意が必要です。今やっと、なぜこれがこんなに時間のかかるプロセスなのか理解しました…そして今私の手元には、たった10枚しか画像がありません!

これは他の画像での拡大図です。7つ全部の車が見えますか?

10枚の画像が全て終わったら、十分な休憩をとって、ラベリングジョブが終わるのを待ちましょう。
結果の可視化
アノテートされた画像は AWS マネージメントコンソールから直接見ることができるので、変な間違いがないか確認するのに便利です。どれかの画像をクリックすれば適用されたラベルのリストを見ることもできます。
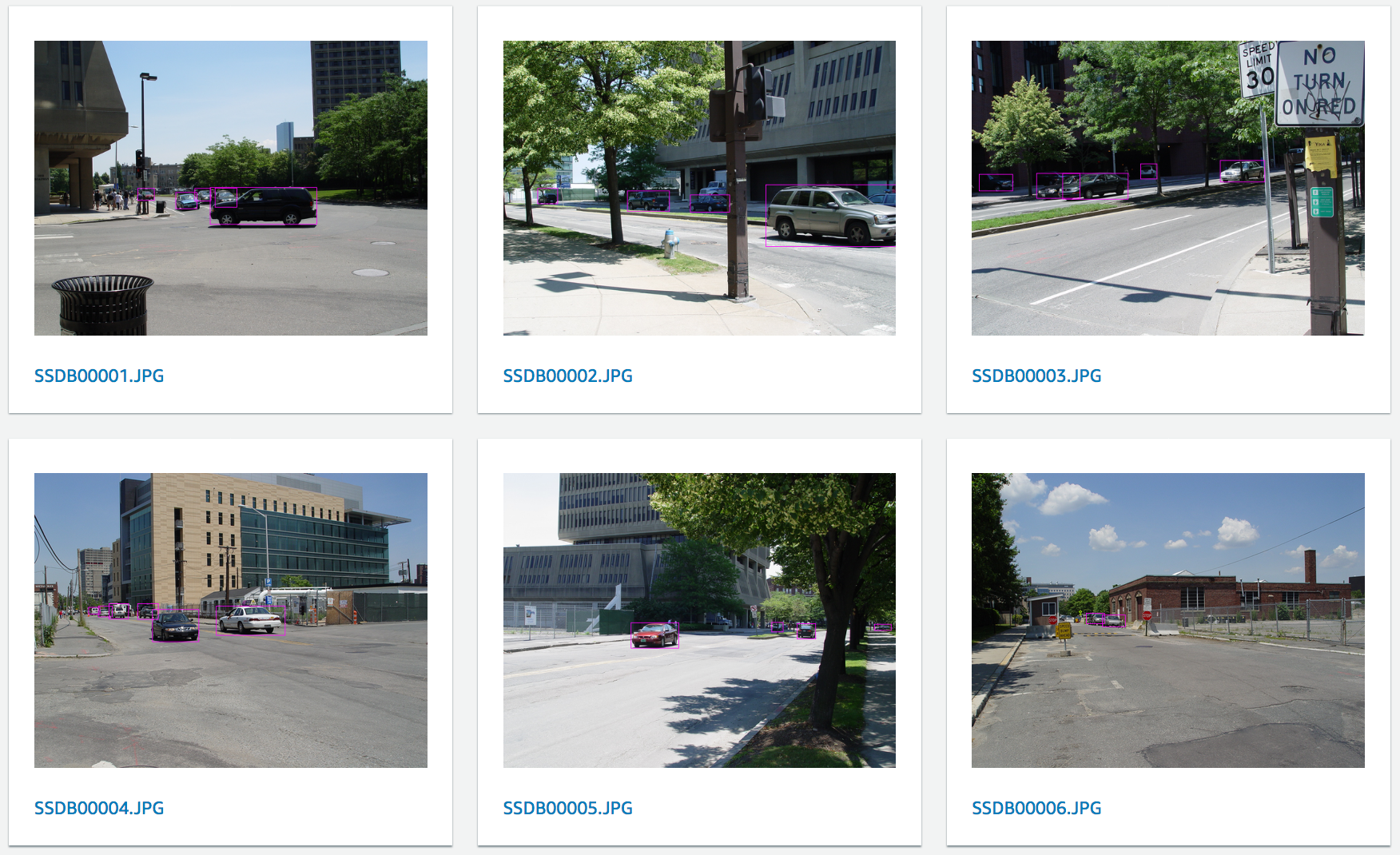
もちろん、目的はこの情報を使って機械学習モデルを学習させることです。バケットに保存されているマニフェストファイルを見るといくつか追記されています。例えば、先ほど5台の車をラベル付けした1枚目の画像に対するマニフェストの内容です。
{
"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG",
"GroundTruthDemo": {
"annotations": [
{"class_id": 0, "width": 54, "top": 482, "height": 39, "left": 337},
{"class_id": 0, "width": 69, "top": 495, "height": 53, "left": 461},
{"class_id": 0, "width": 52, "top": 482, "height": 41, "left": 523},
{"class_id": 0, "width": 71, "top": 481, "height": 62, "left": 589},
{"class_id": 0, "width": 347, "top": 479, "height": 120, "left": 573}
],
"image_size": [{"width": 1280, "depth": 3, "height": 960}
]
},
"GroundTruthDemo-metadata": {
"job-name": "labeling-job/groundtruthdemo",
"class-map": {"0": "Car"},
"human-annotated": "yes",
"objects": [
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94}
],
"creation-date": "2018-11-26T04:01:09.038134",
"type": "groundtruth/object-detection"
}
}ここに、たとえば Amazon SageMaker ビルトインの Single Shot multibox Detector (SSD) などの物体検出モデルの学習に必要な全ての情報が含まれています。ですがその話はまた別の機会に!
今すぐ使えます!
この投稿が有用であることを願います。我々はまだ Amazon SageMaker Ground Truth でできることをほんの少しかじっただけです。このサービスは今日から米国東部 (バージニア北部・オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド) と、それからアジアパシフィック (東京) でお使い頂けます。さあ、次はあなたの番です、使ってみてどう思うか教えて下さい!
— Julien;
翻訳は SA 針原・宇都宮が担当しました。原文はこちら。